Как использовать инструмент «детальный анализ запроса» для поисковых фраз и seo?
Содержание:
Операторы для работы с Wordstat Yandex
1. Оператор кавычки
Поставив запрос в кавычки, мы фиксируем слова, которые есть в запросе. Например, если запрос «лыжные палки» взять в кавычки, то будет показано суммарное число запросов, которое включает следующие варианты:
Порядок слов и окончания могут изменяться.
2. Оператор восклицательный знак
Чтобы зафиксировать нужное нам окончание есть специальный оператор восклицательного знака. Для того чтобы воспользоваться им необходимо перед словом (или словами) поставить восклицательный знак. Таким образом, мы получим нужную словоформу. Например, «!лыжные !палки».
Оператор кавычек и восклицательного знака используются часто и являются самыми ходовыми и востребованными.
3. Оператор квадратные скобки
Оператор [] появился недавно. Он позволяет зафиксировать порядок слов. Многие вебмастера и оптимизаторы хотели его появления и спустя много лет Яндекс их услышал и реализовал. Например, «».
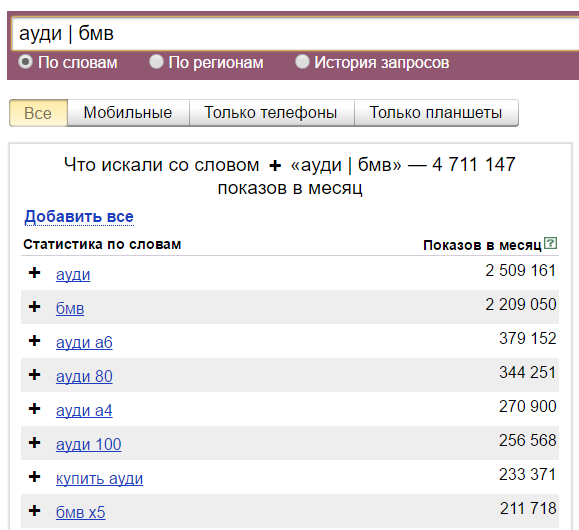
4. Оператор плюс (+)
Ставя плюс перед словом, оно становится обязательным. Это скорее относится к предлогам, поскольку они часто не учитываются. Например, для предлогов «как», «что», «когда», «куда» и т.п. это будет критичным. Например «+как заработать на сайте«. Будет обязательно учитывать слово «как». Если мы не поставим плюс, то будут учитываться частотности для запроса «заработать на сайте».
5. Оператор или (|)
Оператор или (|) полезен в тех случаях, когда слово может быть написано на английском или русском. Например, (биткоин|bitcoin).
Программы для упрощённой работы с Wordstat Yandex
Чтобы делать более быстро выгрузки данных из сервиса Яндекс Вордстат использует различные программы. Например, Кейколлектор.
Как правильно пользоваться Вордстатом
Сначала там нужно зарегистрироваться. Вот ссылка на сервис, вы можете и без регистрации вводить в нем слова, но вот результаты узнавать сможете только после регистрации. Иначе будет всплывать такая херня:

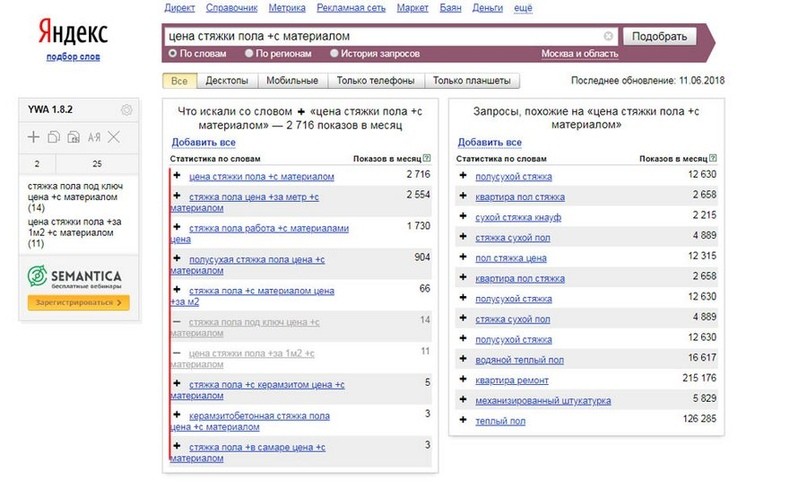
После того, как зарегаетесь, вводите там слово и жмите кнопку «Подобрать». Вы получите такие результаты:
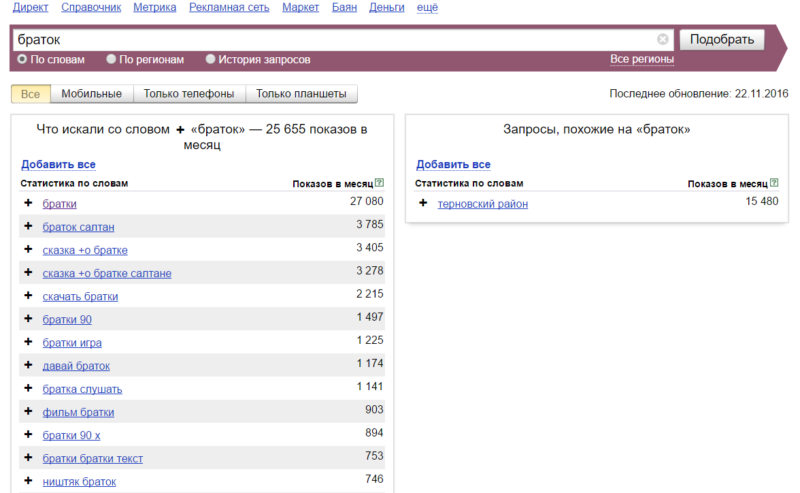
Как видите, мы ввели слово «браток», и в левой колонке будут запросы, в которых присутствует фраза «браток». Эти запросы вводят реальные пользователи. В правой колонке — похожие запросы. Цифры рядом с каждым запросом — это их частотность (то есть насколько часто пользователи их вводят). Но это не точная частотность, а приблизительная. То есть саму фразу «браток» именно в такой форме может вводили раз 20 всего (то есть точная частотность у нее 20 тогда), но вместе с фразами «братки», «братки 90», «давай браток» и другими у нее частотность 27 080. Точную же частотность мы научимся определять далее.
Давайте теперь смотреть остальные функции интерфейса:

В блоке 1 — переключение между типом устройств. Я лично не использую. Я свои сайты делаю удобными для всех типов устройств.В блоке 2 — очень полезный переключатель. С его помощью можно посмотреть, во-первых, региональность запроса (в каком регионе его вводят чаще, в каком — реже). Можно серьезно залипнуть на этом инструменте. А во-вторых, тут можно посмотреть «Историю запроса» — и это действительно иногда очень нужно бывает для определения сезонности запроса и для отслеживания тренда.В блоке 3 — дата, когда последний раз Яндекс обновлял статистику по запросам. В большинстве случаев нам это не нужно.В блоке 4 — выбираем регион/регионы.
По регионам
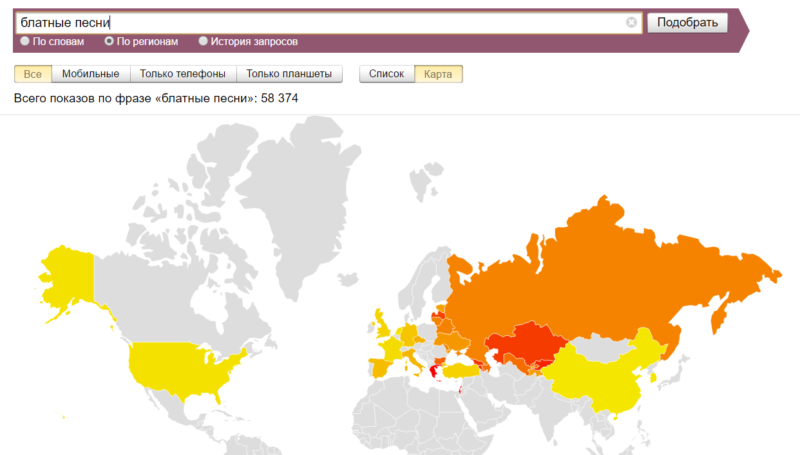
Можно посмотреть, что где ищут. Забавная штука. Тут, например, можно выяснить, что блатные песни в среднем на душу населения больше всего ищут вовсе на в РФ, а в Греции и таки в Израиле:
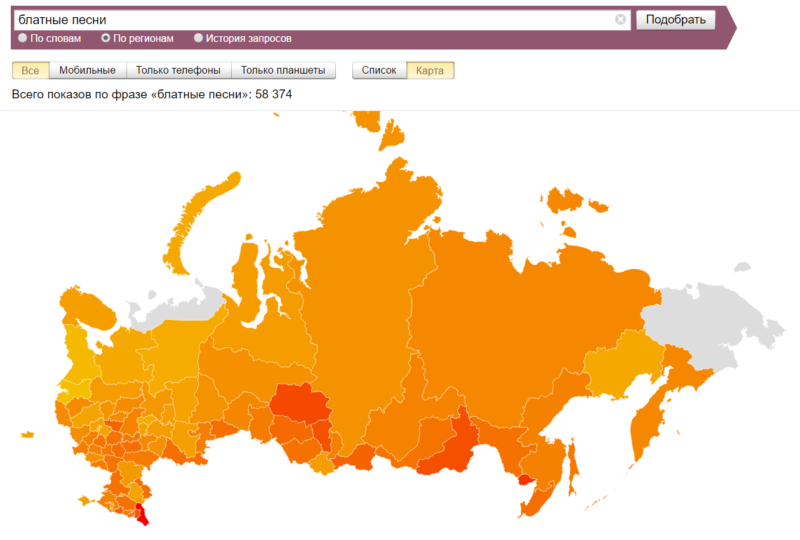
А если вы нажмете на Россию, то увидите, что блатняк востребован в общем-то везде, но особенно — в Дагестане:
История запроса
В истории запроса можно определять сезонные запросы и тренды, как я уже говорил. Например, мы можем лишь завидовать тем вебмастерам, кто успел написать статьи про Трампа, потому что сейчас (конец 2016) у них начался рост трафика:

Но самое профессиональное начинается, когда вы работаете с операторами.
Базовые операторы
Два базовых оператора — восклицательное слово и кавычки. Это азы азов.
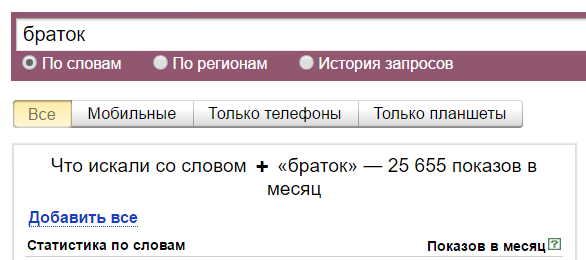
Смотрите, без них у нас 25 655 показов. Это показы всех фраз со словом «браток».
С кавычками же всего 832. Кавычки фиксируют фразу. Это значит, что 832 показа — у фраз «браток», «братка», «братку», вместе взятых, то есть у этой фразы с разным порядком слов и окончаниями, но без добавления к этой фразе других слов. То есть сюда не включаются показы фраз «мы братки», «завалили братка» и так далее.
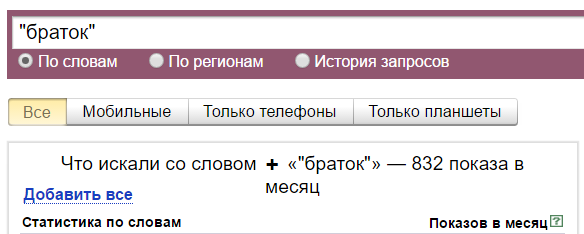
С восклицательным знаком — 7409 показов. Он фиксирует словоформу. То есть сюда включаются показы фраз «браток», «ништяк браток», «держись браток» и других с таким же окончанием. А показы фраз «позвонить братку», «скачать песню про братка» и так далее — не включаются.
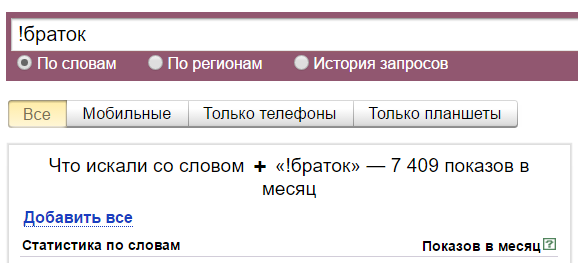
А тут мы имеем всего 152 показа. Это потому, что с восклицательным знаком и кавычками учитываются показы только этой фразы и только в этой форме. Но с разным порядком слов в фразе. То есть если мы введем «ништяк браток», то Вордстат нам покажет сумму показов «ништяк браток» и «браток ништяк».
Вспомогательные операторы
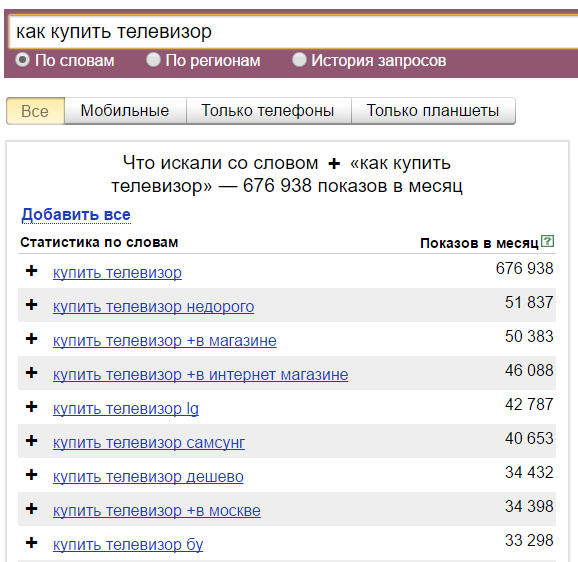
Плюс. Символ «+» принудительно учитывает стоп-слова. По умолчанию Вордстат не учитывает предлоги, и по запросу «как купить телевизор» покажет вам в основном коммерческие запросы:
Если вам важна частица «как», то зафиксируйте её плюсом и Wordstat даст уже такие данные:
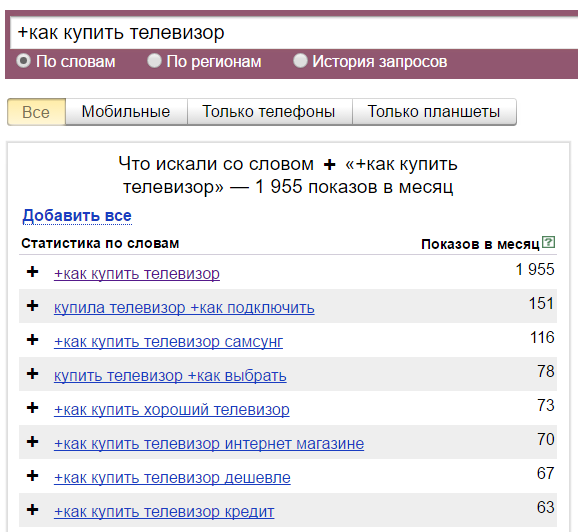
Оператор «ИЛИ». Прямой слэш «|» — если две фразы разделить этим оператором, он покажет все вариации с этими двумя фразами.
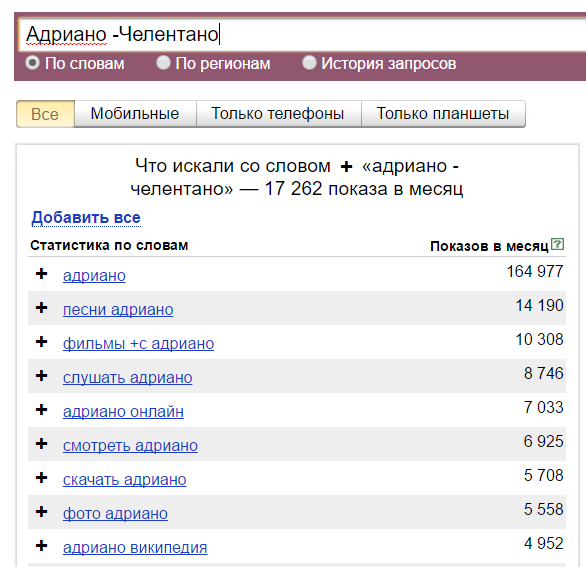
Минус. Символ «-» исключает конкретное слово из запроса. Пример: «купить машину в Москве -бу». Будут показаны запросы без употребления слова «бу».
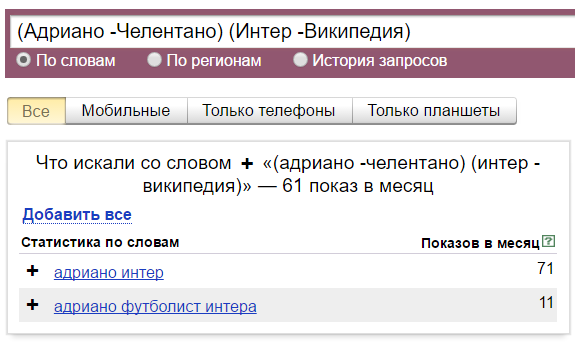
Круглые скобки «()» — группирует использование нескольких операторов.
Квадратные скобки «[]» — фиксирует последовательность слов в поисковой фразе. Этот оператор ввели не так давно. То есть мы получаем возможность узнать, с каким порядком слов фразу вводят чаще всего:
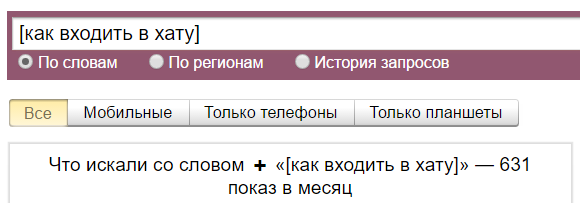
Как видим, с неправильным порядком фразу почти никто не вводит:
Как анализировать результаты?
Общий принцип, как проверить количество запросов в Яндексе, мы осветили. Теперь давайте поговорим о частотности запросов. Это важный пункт в построении алгоритма в подборе семантического ядра и продвижении сайта.
Итак, запросы в поисковых системах делать на 3 группы: высоко- (ВЧ), средне- (СЧ) и низкочастотные (НЧ). Статистика по запросам Яндекс отображает все запросы. Как разобраться, где какой и что лучше использовать для продвижения? Нет строгой классификации по частотности.
Многие неправильно трактуют полученные результаты на Вордстате. И иногда путают запросы с низкой частотой или вовсе пустышки с высокочастотниками. А все потому, что игнорируют использование операторов.
Чтобы проверить количество запросов в Яндексе на то, сколько раз вводили запрашиваемую фразу, а не просто поисковую выдачу, нужно использовать описанные выше !, «». А при необходимости и другие инструменты. Тем самым отсеивая «мусор».
Существует также дополнительное разделение на высоко- (ВК), средне- (СК) и низкоконкурентные (НК). Лучшим сочетанием принято считать высокочастотный и одновременно низко- или среднеконкурентный запрос.
Также помните о том, что проверить статистику запросов в Яндексе – это только половина дела. Для оптимального и результативного продвижения в статьях, которые планируются публиковаться на вашем ресурсе, нужно использовать все виды ключевых запросов независимо от частотности. Конечно, «пустышки» никому не нужны, но наличие в текстах ВЧ, СЧ, НЧ обязательно. А ключевые фразы с «хвостами» поднимут вас в выдаче.
В статье мы рассмотрели, как узнать количество запросов с помощью Вордстата. Однако помните, что термины высококонкурентный, среднеконкурентный и низкоконкурентный не имеют четких количественных значений. Для каждой темы могут разниться в зависимости от специфики, сезонности и популярности сферы, в которой они применяются. А продвижение сайта еще определяется и конкретной ситуацией на рынке.
Знания, как проверить количество запросов по ключевым словам – это только одна из важнейших составляющих процесса оптимизации. Мало найти нужные слова и фразы, необходимо их грамотно использовать. Что для этого нужно?
Пользователи и посетители вашего ресурса, которые попали на сайт по поисковым фразам, должны увидеть полезную и интересную информацию и, главное, ту, на которую рассчитывают. Только так вы можете их завлечь, и они захотят вернуться к вам. И доверить это лучше профессионалам!
Вот и все, что необходимо знать для грамотного подбора семантики и эффективной раскрутки. Удачи!
Запросы Яндекса в реальном времени. Что ищут в Яндексе прямо сейчас?
Раньше были запросы Яндекса по регионам, отображаемые на карте. Спустя несколько лет, всё поменялось, и карта по регионам больше недоступна. Остались запросы Яндекса в “прямом эфире”, которые можно посмотреть на главной странице сайта компании, по адресу: https://yandex.ru/company


Кстати! Находил интересный кейс, как написали парсер фраз из прямого эфира, чтобы найти самые популярные фразы. Уверен, эта информация может быть полезна. В результате собирали фразы в течение 7 дней, и получилось 414 Гб информации на сервере.
Далее, специалисты удалили дублирующие фразы, и по факту получили чуть больше 15 млн. фраз. Так это было…
- количество потоков парсинга – 10
- скорость получения ключевых слов – около 10 тыс в секунду
- запись велась в 70 текстовых файлов (7 дней по 10 потоков):
- размер файлов от 1.6 гб до 8.8 гб
- количество ключевых фраз, полученных за время парсинга – 4 460 619 547
- количество ключевых фраз после удаления дублей – 15 068 199
Самыми частотными словами выборки, за исключением союзов и предлогов стали следующие слова (указана частота употребления, раз):
- купить 382468
- фото 290786
- скачать 253934
- отзывы 172763
- видео 170758
- ru 153455
- онлайн 147839
- смотреть 146245
- игры 110075
Можно сделать вывод, что в поиске Яндекса, большой топ запросов со словом купить. А также, связанные с просмотром фильмов, скачиванием информации, а также игры.
Этот эксперимент проводился очень давно.
Статистика ключевых слов в Яндекс Вордстат по регионам
Очень полезный раздел для всех, кто продвигается в конкретном регион или ищет данные с точной ГЕО- привязкой.
По умолчанию «Поиск по словам» позволяет получить данные по всем регионам. Если вам нужно провести анализ поисковой фразы с учётом региона, прямо под поисковой строкой (справа), кликаем «Все регионы»:

Откроется окно выбора региона. Скорее всего, вы будете искать данные о частотности по какому-то российскому региону, поэтому, раскрываем регион Россия:

…и далее выбираем округ:

Допустим, нас интересует Москва. Раскрываем «Центр», выбираем «Москва и область» и область, кликаем «Москва»:

Не забываем кликнуть «Выбрать» (вверху страницы), чтобы сохранить настройки поиска:

Теперь Wordstat Yandex будет учитывать популярность той или иной поисковой фразы только у тех пользователей, которые пользуются поиском из Москвы (обратите внимание — без учёта Щербинки, Зеленограда и Троицка).
Вы также, можете получить данные по частотности выбранной фразы в виде рейтинга-списка. Чтобы сделать это, достаточно отметить чекбокс «По регионам»:

Видим, что фраза “москва что посмотреть” наиболее популярна у пользователей ЦФО, если быть точнее — у пользователей из Москвы и Московской области:
Удобно, что все данные по популярности фразы можно посмотреть, как отдельно для списка конкретных городов, так и для списка регионов:

Кроме суммарного количества показов, здесь также есть метрика «Региональная популярность»:

Данная метрика представляет из себя affinity index – позволяющая судить об уровне интереса поисковой фразы в конкретном регионе
Необходимо обратить внимание на процентное значение, если % превышает 100, то можно говорить о повышенном интересе к запросу в выбранном регионе (относительно иных запросов), если менее 100% — о пониженном.. Данные по частотности поисковой фразы, с учётом регионов, доступны не только в виде списка, но и на интерактивной карте, что очень удобно
Особенно если вы цените наглядное представление:
Данные по частотности поисковой фразы, с учётом регионов, доступны не только в виде списка, но и на интерактивной карте, что очень удобно. Особенно если вы цените наглядное представление:
Каждый регион кликабелен:

Россия детальнее:
Кейс №4
Допустим, перед нами стоит задача быстро собрать теги для категории «Смартфоны» и у нас нет времени чистить огромное облако запросов данной категории от мусора. Чаще всего тегами являются 2 типа интентов – характеристика объекта (белый смартфон, мощный смартфон) и по назначению объекта (смартфон для пожилых, смартфон для девушки). С помощью Вордстата мы можем легко собрать теги 2-го типа – по назначению, так как все такие запросы содержат предлоги. Исходя из этого мы делаем следующую регулярку:
смартфоны (+до|+с|+на) -скачать -игры -интернет -мтс -фото
Так же указываем базовые стоп слова, чтобы не собирать мусор.
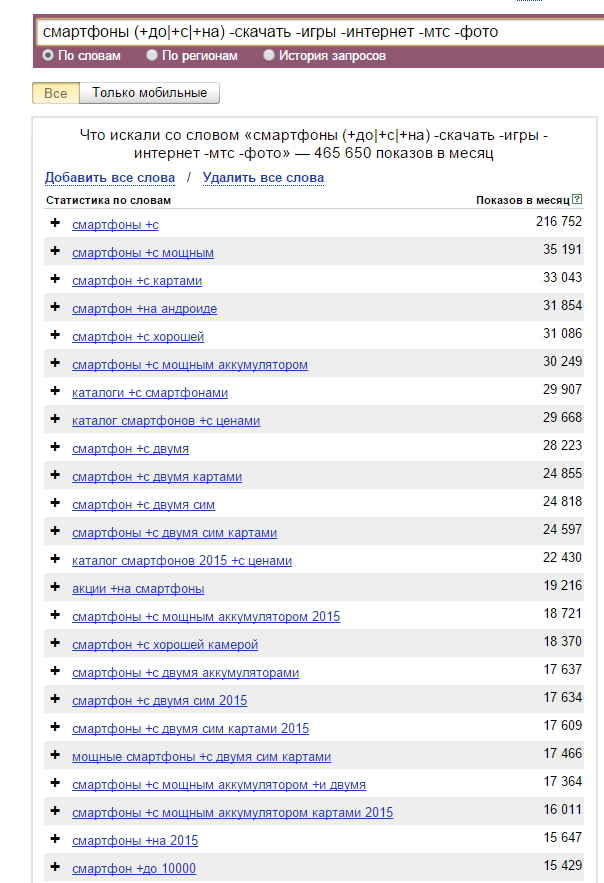
Сразу видны будущие теги – смартфоны на андроиде, с мощным аккумулятором, с хорошей камерой и т.д. Естественно у каждого могут быть индивидуальные проблемы и текущие кейсы не подойдут для решения вашей задачи, но включив логику, вы всегда можете видоизменить наши примеры под ваши нужды.
Все приведенные выше примеры работают в нашем парсере Wordstat – можете сами в этом убедиться. 🙂

Для чего нужен парсинг частотности
Оценка объема трафика по определенным ключевым словам
Частотность в Яндекс.Вордстат отображает количество показов по выбранному ключевому слову за месяц в определенном регионе. С помощью этих данных можно примерно рассчитать потенциальный объем трафика, который можно получать в поисковой выдаче на разных позициях.
Сделать это можно так:
1. Соберите целевую семантику (список ключевиков, по которым вам нужно получать поисковой трафик). Собрать семантику можно с помощью медиапланера от Click.ru.
2. Спарсите частотность ключевых слов. Для примера мы возьмем ключевик «купить Samsung Galaxy в Москве» и проверим его частотность непосредственно в Вордстате. Итого, по данному запросу – 11757 показов в месяц.
3. Найдите в интернете средние значения CTR для каждой из позиций первой страницы поисковой выдачи.
Если ваш сайт добавлен в Яндекс.Вебмастер и работает как минимум несколько месяцев, данные по CTR будут доступны в отчете «Поисковые запросы» → «Все запросы и группы».
К примеру, CTR для второй позиции – 18%. Теперь мы можем посчитать примерный уровень трафика, который можем получить. Формула для расчета:
(Частотность * CTR)/100
Подставляем в формулу наши данные: (11 757 * 18)/100 = 2116.
Конечно, нет гарантии, что мы получим точно такое количество посещений, но для примерной оценки потенциала запроса такие расчеты будут очень полезными.
Еще одна причина для сбора частотности ключей – фильтрация запросов с околонулевой частотностью
Фразы, по которым нет показов (или показов совсем мало – от 1 до 10), лучше убрать из семантического ядра и не тратить время на оптимизацию страниц под такие запросы.
По ним практически не будет трафика, а если запускать контекстную рекламу, объявления получат статус «мало показов» и не будут показываться.
Обратите внимание! Иногда семантику с низкой частотностью не нужно исключать из ядра. Это касается узкоспециализированных тематик, например дорогого медицинского или производственного оборудования
Там ключевые запросы с указанием точной спецификации оборудования могут иметь всего пару запросов в месяц, но приводить максимально целевую и горячую аудиторию.
На что ориентироваться
В зависимости от ниши и типа сайта нижний порог частотности, по которому нужно отсекать бесперспективные запросы, отличается. Для ориентира можете использовать следующие данные:
|
Ниша |
Отсеиваем запросы с частотностью |
|
Узкие тематики |
|
|
Масс-маркет |
до 5 |
|
Информационные ресурсы |
до 30–35 |
При удалении низкочастотных фраз будьте внимательны: НЧ-запросы приводят качественный трафик, поэтому удаляйте фразы аккуратно, оставляя целевые.
Зачем нужен Вордстат?
Инструмент незаменим в таких случаях:
предстоит писать SEO-оптимизированные тексты, для которых важно определить состав ключевых фраз и частотность употребления;
необходимо составить структуру для новой страницы или для всего сайта;
нужно уточнить, какие слова в Вордстат вводят представители целевой аудитории, обращаясь к поисковой системе для решения проблемы, и как именно они формулируют мысли;
требуется выяснить, какие дополнительные интересы имеются у представителей целевой аудитории, чтобы грамотно составить ассортимент товаров и выкладывать максимально полезный контент.
Сезонность в Яндекс Вордстат — история поисковых фраз
Интересный раздел, позволяющий познакомиться с динамикой частности выбранной ключевой фразы.
Анализируя данные за несколько лет, вы можете выделить определенную закономерность и понять — существует ли сезонный фактор на интересующий вас товар (или услугу, либо иное явление).
Например, вот история для фразы “москва экскурсии”:
Можно сгруппировать данные по месяцам / неделям, либо — по типу устройства:
История показов по фразе «экскурсии москва». График содержит относительное и абсолютное значение. Можно включить / выключить только абсолютное или только относительное значение. Сам график показов интерактивный:
Здесь же, подробная статистика по датам:
Вы можете смотреть цифры в абсолютных значениях (самый точный вариант):
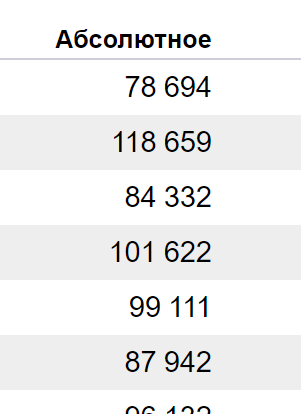
…либо — относительных (в таком случае, учитывается суммарный показ фразы на странице результатов поиска):

Зачем нужна статистика?
Cтатистика игрока World of Tanks имеет для танкистов очень большое значение. Это неудивительно, именно соревновательный элемент является первостепенным после прокачки большинства танков. Наш сервис позволит Вам оценить множество показателей, начиная от винрейта и заканчивая временем, проведенным в игре.
В любой многопользовательской игре каждый хочет быть лучшим, а статистика позволяет увидеть, насколько результаты одного танкиста отличаются от другого.
- С помощью мода XVM можно проверить стату в WoT прямо в сражении. И не только свою, но и врагов, а также союзников. В итоге игрок более грамотно оценивает общий расклад сил команды, видя, насколько скиллованны игроки.
- Сервисы расширенной статистики в WoT — это обязательный инструмент каждого рекрутера, занимающегося поиском новых игроков для своего клана.
- Существует и клановая статистика сообществ в World of Tanks, благодаря ей оценивается целиком весь клан.
- Оценка своих достижений — наблюдать, как показатели растут со дня на день довольно приятно.
Из чего состоит стата?
Перед тем, как перейти к описанию разнообразных рейтингов и калькуляторов эффективности в WoT, следует пройтись по фундаментальным данным, с помощью которых эти рейтинги и составляются.
Процент побед — это основной показатель, демонстрирующий успешность танкиста на поле боя. Так как вероятность победить равна 49.9%, вклад игрока в сражение и его умение играть может привести к победе. Таким образом, умелые танкисты могут похвастаться статистикой от 51% и выше.
Урон за бой — в рейтинг эффективности в WoT входят и эти данные, объективно показывающие вклад в сражение. Но учтите, этот показатель является совсем необязательным для легких танков, задача которых состоит в обнаружении противника. А вот для ТТ и ПТ-САУ урон за бой — это критически важный показатель.
Выживаемость — спорные данные, так как до момента своей смерти игрок может нанести огромное количество урона и уничтожить многих врагов. Но все же выживаемость отлично показывает склонность танкиста идти в самоубийственную атаку. Если же вы любитель ЛТ, то именно выживаемость является очень важным показателем, наравне с обнаруженными за бой врагами.
Точность (процент попаданий) — в КПД входит информация о проценте попаданий
Критически важно иметь хорошую точность на арте, во вторую очередь на остальных классах.
Соотношение убил/убит — в бою сталкиваются 30 машин, по 15 с каждой стороны. Один уничтоженный танк — это минус ствол и уже полноценный вклад в достижение победы, все, что было сделано поверх говорит об эффективности танкиста, поэтому соотношение, равное, например, 1.50 является хорошим показателем.
Средний уровень боев — показывает на каких уровнях чаще всего сражается игрок.
Это далеко не вся информация, доступная в нашем сервисе, описаны лишь самые главные данные.
Проверка частотности: 80 lvl
Переходим к более сложным тонкостям сбора статистики по запросам из Яндекса.
Пример #1
Начнем с оператора » » и сформулируем одно правило его использования: если во фразе, заключенной в кавычки, присутствуют одинаковые предлоги или слова, то одно из них заменяется на существующее слово во вложенном запросе. Для примера рассмотрим запрос «автомобиль в кредит москва».
Если добавить в данное ключевое слово еще один предлог «в» перед словом «москва», то получим следующие данные.
Таким образом повторяющиеся предлоги «в» были объединены, и к запросам добавилось еще одно слово. Для разных запросов это слова «купить», «бу», «новый», «залог», подержанные». «оформить».
Этот прием — невероятный инструмент для информационный сайтов, основной целью которых является рост трафика. Он позволяет выбрать из тематики весь диапазон запросов, которые включают в себя заданное количество слов, например, все запросы по тематике из 5 слов. Как правило, очень расширенные запросы из 5-7 слов бывают менее конкурентными, соответственно привлечь трафик и занять высокие позиции по ним легче. А если эти запросы не уступают в показах высокочастотным запросам? Выборка наиболее высокочастотных и наименее конкурентных запросов позволит вам быстро добиться результата. Давайте рассмотрим пример.
В данном запросе мы просим WordStat показать диапазон запросов, который включает в себя 7 слов, обязательно содержащих слова «инструкция по применения». 5 слов «инструкция» объединяются, остается одно, 4 слова заменяются на новые вложенные запросы. Смотрим один из сотен вложенных запросов, частотность запроса из 7 слов — 8090 показов в месяц. Для сравнению запрос «купить автомобиль в москве» имеет 647 показов в месяц. Разрыв шаблона еще не произошел? Тогда идем дальше.
Пример #2
Сейчас пойдет в бой более сложный оператор () и |, с его помощью мы соберем пул запросов, из которого в дальнейшем сможем сделать теговые страницы. Возьмем для примера запрос «купить автомобиль bmw». Данную марку авто, ее серии могут искать по самым разным запросам: «купить машину бмв», «купить bmw икс 6», «купить автомобиль бмв 5» и т.п. Для того чтобы получить пул запросов без повторений, используем регулярное выражение:
купить (автомобиль|машина) (бмв|bmw) -пробегом -фото -не -заводится -скачать -бу -какая
Добавим в него сразу ряд нерелевантных минус-слов, которые не подходят для нашего бизнеса. Получаем следующие данные, которые впоследствие проще структурировать.
Данная выборка поможет вам проще собрать данные для теговых страниц и кластеризации данных.
Обратите внимание, нельзя в одном выражении использовать операторы » » и ( ) |. Логика работы одного оператора нарушает логику работы другого
Пример #3
рыбалка (+с|+на) -игра -бесплатная -скачать -русские -охота
Минус-слова, конечно же, нужно добавить, но в данном случае это просто пример. Получаем вот такой результат:
Пример #4
Совместное использование операторов поможет вам разграничить похожие по написанию, но разные по смыслу запросы. Например, запрос «купить тур в москвУ» подразумевает экскурсионную поезду в Москву.
Запрос «купить тур в москвЕ» подразумевает учет геопозиции пользователя для покупки тура из Москвы.
Пример #5
Еще один пример регулярного выражения, которое поможет вам собрать запросы для теговых страниц или фильтров каталога в нише купальников.
Даже если данные примеры не относятся к вашей нише, надеемся они помогут вам улучшить свои навыки работы с WordStat. Если у вас возникли вопросы, вы нашли ошибки, либо хотите дополнить статью, пожалуйста, пишите в комментарии, мы с радостью ответим вам!
Yandex Wordstat Assistant
Расширение устанавливается в 3 простых шага:
1) Скачайте актуальную версию расширения для браузера, в котором работаете с Яндекс Wordstat: Google Chrome, Mozilla Firefox, Opera или Яндекс Браузер.
Для всех браузеров алгоритм одинаковый. Мы покажем, как устанавливать и пользоваться возможностями Wordstat Assistant, на примере Google Chrome.
2) Нажмите кнопку для установки:

3) Подтвердите, что собираетесь установить расширение:
На этом всё готово, остается проверить, установилось ли расширение.
Если всё корректно, вы увидите:
Значок с таким уведомлением – теперь он всегда будет отображаться в вашем браузере.

Если такого значка нет, попробуйте перезапустить браузер.
Панель управления Wordstat Assistant в левой области страницы Яндекс Wordstat – в неё будут попадать все ключевые фразы, которые вы добавите.

На случай, если панель не появится, обновите страницу или также перезапустите браузер.
Знак «+» напротив каждого результата и в левой, и в правой колонке – нужен, чтобы добавлять фразы в список.
Чтобы его увидеть, введите нужную фразу, как обычно в Вордстате, например:

Рассмотрим все функции по порядку.
1) Добавление и удаление фраз из списка
Можно добавить в список отдельную ключевую фразу, нажав на плюс, или все фразы из таблицы (именно с той страницы, на которой вы находитесь, а не из всей выдачи), нажав ссылку «Добавить все»:

Например, мы хотим добавить все похожие фразы из левой колонки с первой страницы. Жмем «Добавить все», в окне подтверждения – «Добавить»:
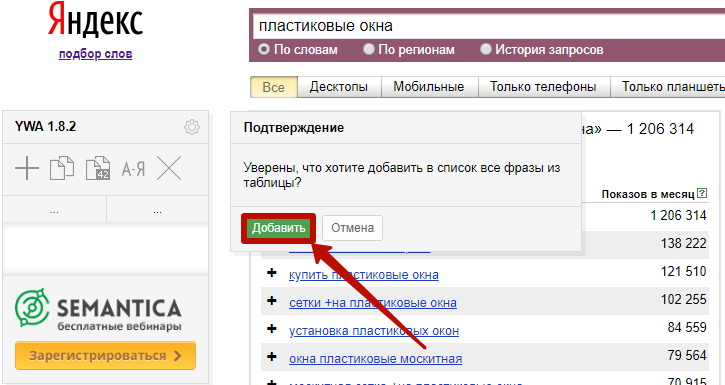
Выглядит это так, в скобках указана частотность для каждого запроса:
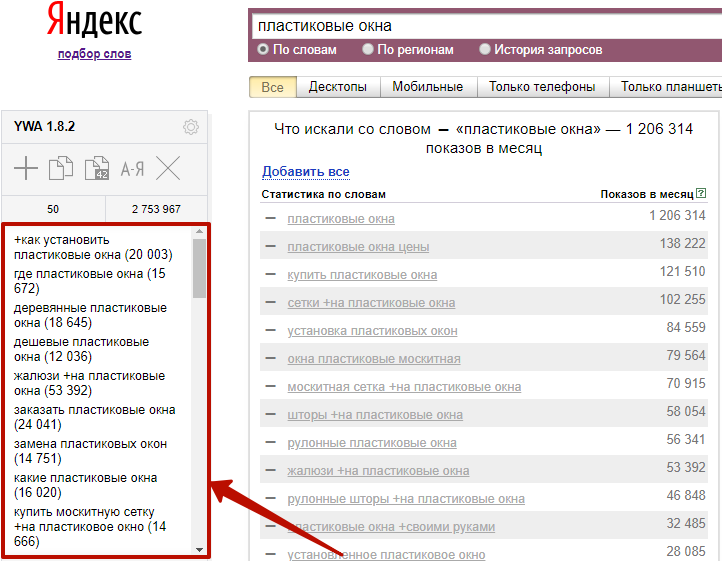
Над списком отображается общее количество фраз, которые вы добавили, и суммарная частотность по ним:
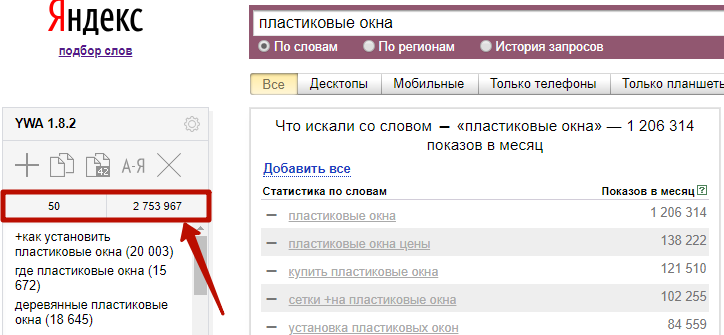
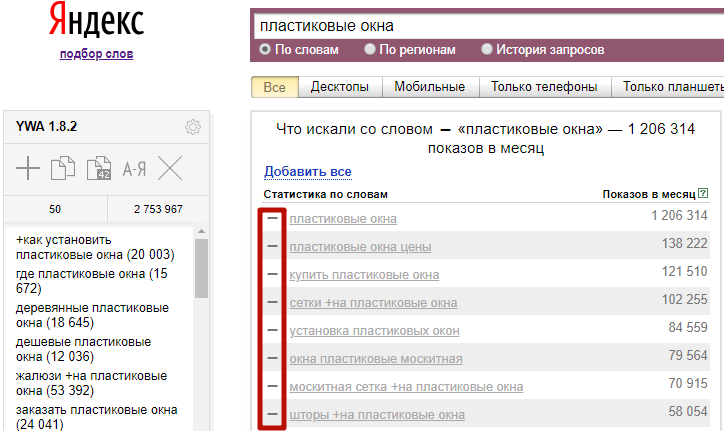
В результатах поиска Yandex Wordstat фразы, которые вы выбрали, становятся серого цвета, со знаком минус вместо плюса.
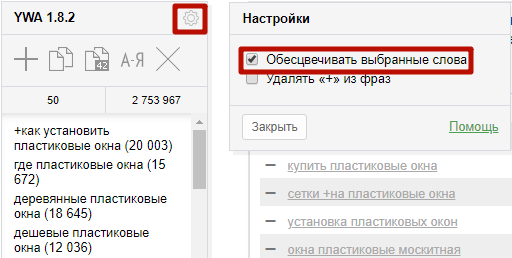
Эти опции при необходимости можно отключить здесь:
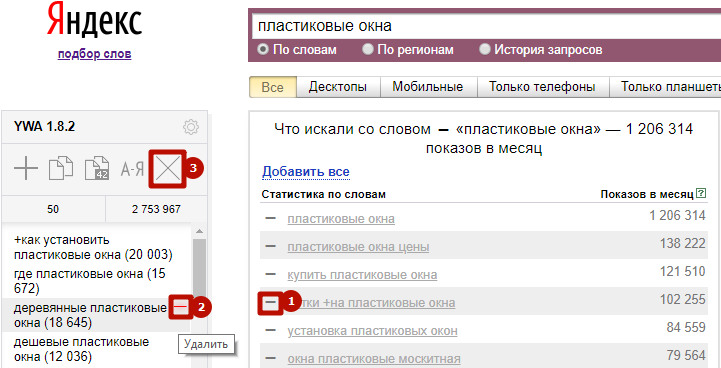
По знаку «–» фразу можно в любой момент удалить из результатов поиска Яндекс Wordstat (1). Либо можно удалить прямо её из панели управления: для этого наведите на фразу курсор и кликните по минусу рядом с ней (2). Чтобы очистить весь список, нажмите крестик вверху панели управления (3).
При попытке добавить такой же ключ, какой уже есть в списке, Wordstat Assistant выдает сообщение:
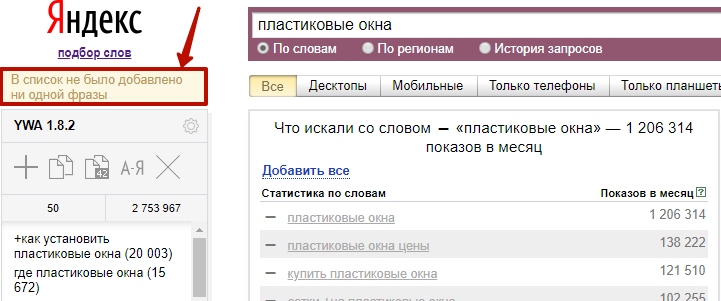
2) Добавление собственных ключей
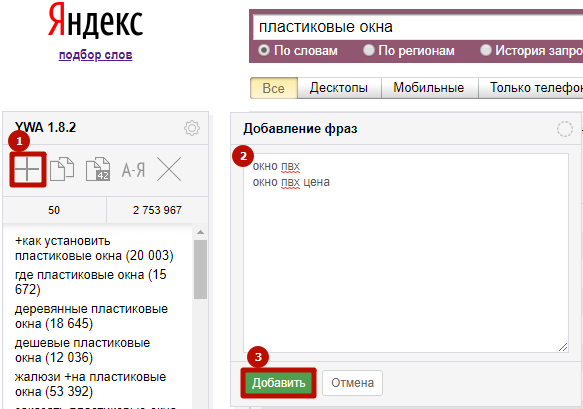
Для этого нажмите плюс на панели управления, введите запрос или список запросов, как на скриншоте:
Для добавленных вручную фраз вместо частотности показывается знак вопроса:
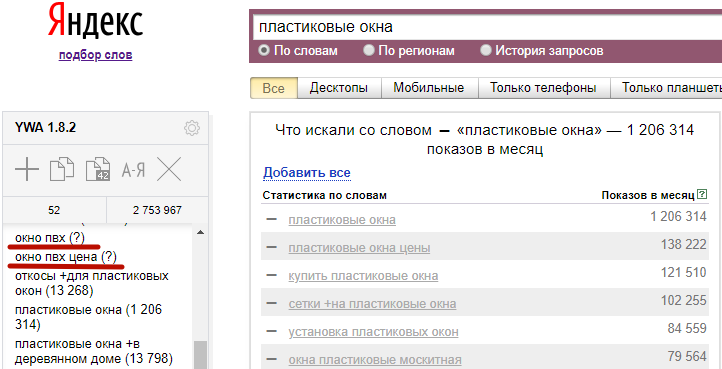
Если ваша фраза совпадает с фразой из результатов поиска Wordstat, последняя выделяется серым цветом. Но частотность при этом остается неизвестной (?), а не перетягивается из данных Wordstat.

3) Сортировка списка ключевых фраз
Её можно выполнять с помощью этой кнопки:
Она меняет свой вид в зависимости от того, по какому признаку вы сортируете фразы:
По возрастанию и убыванию частотности:

По алфавиту:
По порядку добавления (вновь добавленные в конец / в начало списка):
4) Копирование данных из Вордстата
Можно скопировать просто список фраз (1), либо список фраз вместе с фразами значения частотности (2), чтобы работать с ними дальше в любом формате – например, txt или Excel:
Чтобы автоматически удалить знак «+» из всех фраз, задайте эту настройку:
Если вы закроете вкладку с Wordstat или браузер, ничего не потеряется. Список сохранится под тем аккаунтом, в котором вы его сформировали.
Как работать с Вордстатом
Сервис подбора слов помогает просматривать обобщенную статистику по запросам, а также оценивать частотность в зависимости от различных факторов. В Wordstat также есть набор операторов, с помощью которых можно узнать реальное число запросов для определенной формы слова или фразы.
Фильтры
Чтобы посмотреть статистику в срезе по устройствам, используйте фильтр. Он доступен в каждом разделе. Wordstat разделяет мобильные устройства на телефоны и планшеты.
Для просмотра данных по разным регионам, нажмите «Все регионы». Откроется окно, где можно уточнить регион показов.
Переключитесь на вкладку «По регионам», чтобы узнать число показов страниц по запросам из конкретного города, страны или региона, а также по все регионам вместе. Здесь можно посмотреть статистику на карте, если удобно. Также можно применить фильтры по устройствам, чтобы сузить поиск.
Здесь доступны два столбца с цифрами:
- «показов в месяц» — количество показов из региона за месяц;
- «региональная популярность» — доля, которую занимает регион в показах по данному слову, деленная на долю всех показов результатов поиска в этом регионе.
100% — это среднее значение. Если оно меньше 100%, то интерес пользователей к этому слову понижен, и наоборот.
Яндекс уточняет, что региональная популярность — это affinity index в отчетах Яндекс.Метрики.
Следующий раздел в интерфейсе — «История запросов». В первую очередь он помогает подобрать слова для бизнесов, где ярко выражена сезонность и не получается собрать семантику на основе статистики за месяц. В «Истории запросов» показывается динамика показов за два года.
Статистику можно смотреть в абсолютных или относительных значениях. Для получения относительного значения абсолютная цифра нормируется на количество показов результатов поиска Яндекса за соответствующий месяц.
Операторы
Операторы в Wordstat помогают уточнить запросы и получить более детальную статистику по ним. Их можно применить только во вкладках «По словам» и «По регионам». Рассмотрим основные операторы, которые пригодятся специалисту на начальном этапе работе.
-
Кавычки фиксируют количество слов в запросе. Это помогает посмотреть, сколько раз пользователи вводили эту фразу. Система учитывает разный порядок слов и разные окончания. Повторяющиеся слова считаются за одно слово.
- Восклицательный знак нужен, чтобы посмотреть статистику по конкретной форме слова. Он ставится перед словом, которое не должно видоизменяться.
- С помощью оператора «Плюс» можно включать в запрос предлоги или другие служебные слова.
- «Минус» исключает слова из запроса.
- Если заключить ключевую фразу в квадратные скобки, система выдаст число запросов для фразы с сохранением порядка слов. При этом учитываются разные словоформы и предлоги.
Посмотрим на примеры использования. Если нужно узнать точное количество запросов исключительно по заданной фразе без дополнительных слов и без учета словоформ, нужно использовать два оператора: кавычки и восклицательный знак.
Чтобы исключить запросы, не совпадающие с тематикой продвижения, используйте оператор минус вместе с восклицательным знаком. Как в известном примере, вы не будете показывать рекламу бильярдного кия пользователям, которые интересуются покупкой машины Kia и ошиблись в правописании.
Полезные инструменты проверки количества запросов и ключевых слов
Key Collector
Самый популярный сервис сбора ключевых слов и формирования семантического ядра. Распространяется на платной основе. Им пользуются профессионалы в области поисковой оптимизации.

Для первичной настройки программы требуется проделать следующее:
- Добавьте в Key Collector до 10 аккаунтов Яндекс.
- Добавьте в программу сервис анти-капчи. Настройки — Анти-капчи.
- Проведите настройку Вордстат. Настройки — Парсинг — Yandex.Wordstat.
Key Collector позволяет парсить десятки страниц и эффективно выгружать очищенные запросы в неограниченном количестве. Для работы сервиса парсинг производится в Яндекс.Директ.
Также доступен сбор статистики для Google Ads и социальных сетей. Для этого проведите настройки согласно инструкции на сайте разработчика.
Когда парсинг завершён, и вы работаете со списком слов, воспользуйтесь функцией фильтрации. Она помогает очистить выборку от неподходящих фраз и даже оставить только некоторые словоформы, удалив часть того или иного слова.
Также фильтрация помогает удалить повторяющиеся слова — для этого предусмотрена отдельная функция. Затем вы можете удалить специальные и нежелательные символы, такие как цифры и латинские буквы. Более того, если вам знакомы регулярные выражения, это окажется плюсом, так как они поддерживаются программой.
Один из важных этапов сбора семантического ядра — удаление стоп-слов. Эта функция реализована в Key Collector. Например, вы можете удалить лишние прилагательные, описывающие второстепенные свойства продукта: самый, лучший, красивый. Сюда относятся и свойства цены: недорогой, бесплатный, купить.
Slovoeb
Данное приложение позволяет проводить парсинг ключевых слов и сбор частотности определённых запросов. Это бесплатное приложение, которое анализирует выдачу через Яндекс.Директ. Чтобы начать работу, так же, как и в случае с Key Collector, настройте Яндекс аккаунты и анти-капчу.
Функционал программы повторяет концепцию Key Collector, так как является предтечей последнего, и содержит урезанный функционал. Если вам интересно профессионально заниматься SEO, приобретите Key Collector. В случае грамотного использования вложения окупятся весьма быстро.

Ahrefs
Сервис Ahrefs предлагает инструмент Keywords Explorer для анализа ключевых слов. Он поддерживает поиск по 3 миллиардам ключевиков, более 100 стран, статистику кликов, анализ SERP и целый ряд полезных функций для фильтрации слов.
Добавьте через запятую интересующие вас запросы, выберите регион и запустите анализ. Или используйте сквозную аналитику Calltouch.
Сквозная аналитика
от 990 рублей в месяц
- Автоматически собирайте данные с рекламных площадок, сервисов и CRM в удобные отчеты
- Анализируйте воронку продаж от показов до ROI
- Настройте интеграции c CRM и другими сервисами: более 50 готовых решений
- Оптимизируйте свой маркетинг с помощью подробных отчетов: дашборды, графики, диаграммы
- Кастомизируйте таблицы, добавляйте свои метрики. Стройте отчеты моментально за любые периоды
Узнать подробнее
Keyword Tool
Это маркетинговый инструмент, который помогает в поиске ключевых слов и работает с функцией автозаполнения Google. Он генерирует сотни ключевых слов, одинаковых по значению, но отличающихся по форме. С помощью функции автозаполнения пользователи быстрее могут найти информацию в поисковике на основании предложенных системой слов. Keyword Tool оценивает подсказки, выдаваемые поисковиком, и структурирует их в удобном для пользователя виде.

Онлайн парсеры
Подобные сервисы появились относительно недавно. Их преимущество – не нужно скачивать и устанавливать локально программные комплексы. Это экономит время, но сказывается на точности выборки КС. Причина – онлайн-парсеры не работают напрямую с базами данных Wordstat, а периодически скачивают их. Недостаток – не все запросы попадают в информационное поле сервиса.
Букварикс онлайн версия
Первым онлайн-сервисом с расширенными возможностями для SEO-оптимизаторов стал «Букварикс». До недавнего времени его использование было полностью бесплатным. Но с вводом нового функционала появилась платная подписка. Ее преимущества – фильтрация по частотности, количеству символов и слов. Есть ограничения для незарегистрированных пользователей. Но эта процедура бесплатная, возможна авторизация через социальные сети.
Особенности работы с «Букварикс»:
- максимальное количество поисковых фраз – 300 для платной версии;
- возможность скачивания отчета в формате .csv;
- группировка словоформ;
- дополнительные инструменты – анализ доменов, нормализатор, дубликатор и комбинатор слов.
Сервис значительно уступает по возможностям аналогичным программам, но прост в использовании. Рекомендован для начинающих оптимизаторов.