Архив интернета
Содержание:
Основная цель проекта
Целью проекта является сохранение информации, которая когда-либо попадала в Интернет. Помимо обычных веб-страниц здесь можно найти: видео, аудио, различный софт, текстовые и графически материалы. Доступ ко всему содержимому полностью свободный.
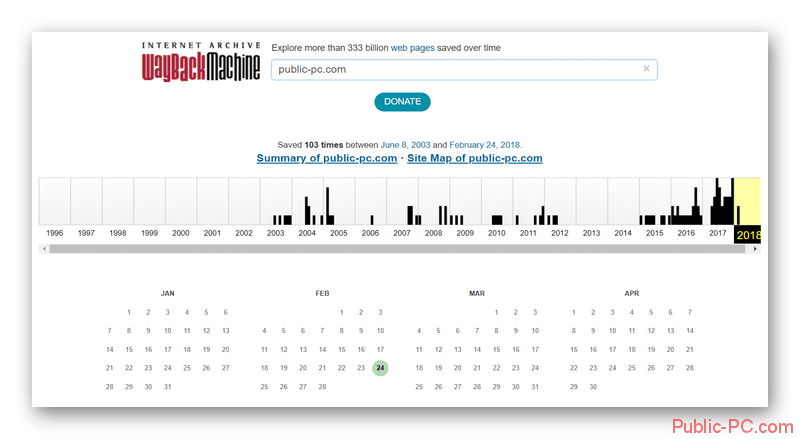
Начиная с 1996 года архив регулярно пополняется новыми страницами, плюс делается несколько копий уже существующих страниц, которые были обновлены. Здесь можно посмотреть, как выглядел тот или иной сайт день назад или 10 лет назад.
Справляться с таким объёмом информации сервису позволяют специальные роботы (по сути мини-программы), регулярно сканирующие интернет (процесс называется индексация). Однако стоит понимать, что роботы не способны мониторить каждую страницу в сети постоянно, поэтому кое-где могут встречаться «пробелы». Чаще всего такое бывает, когда при последнем посещении робота страница была недоступна, например, при технических работах на сайте. В таком случае информация будет обновлена только во время следующего сканирования. Каждому сайту отводится тот или иной приоритет сканирования, крупные и/или перспективные ресурсы сканируются чаще, чем их более скромные аналоги.
Доступ к информации, хранящейся в архивах, осуществляется при помощи сервиса The Wayback Machine. Работает по аналогично схеме с поисковыми системами – вы вводите название интересующего ресурса и смотрите варианты, выданные системой. Дополнительно здесь можно настраивать определённые фильтры, например, даты, показывающие состояние страниц на тот или иной период.
В Архиве Интернета можно проследить развитие не только сайтов, работающих на данный момент, но и ресурсов, которые по каким-либо причинам уже перестали функционировать или были присоединены к другим проектам.
Вся информация может быть найдена на сайте archive.org. Дополнительно всю информацию можно подразделять на категории.
Использование Интернет-Архива
После перехода на сайт Архива обратите внимание поисковую строку, расположенную в верхней части вкладки (она называется «Wayback Machine»). С её помощью можно найти и проследить историю развития практически любого сайта

После того, как вы вбили в поиск URL искомого ресурса, сервис выдаст на временной шкале копии его главных страниц, которые были сделаны за всё время существования проекта. Для того, чтобы просмотреть, как выглядел сайт в то или иное время, выберите нужную дату. Не стоит забывать, что «слепки» страниц делаются не каждый день, поэтому проследить развитие ресурса по дням, да и по месяцам будет проблематично. Дата, для которой уже сделана копия, подсвечена цветом.
У некоторых доменных имён может быть длинная история. Например, изначально это имя использовало какое-нибудь туристическое агентство, но по какой-то причине оно забросило свой сайт, а спустя несколько лет это же имя использует какой-нибудь блог или сервис.
Проект Internet Archive очень важен как в глобальном понимании для сохранения истории развития интернета и веба, так и для веб-разработчиков и просто любопытных пользователей. Вебмастерам этот сервис даёт возможность просмотреть историю того доменного имени, которое будет использоваться для будущего сайта.
Что такое веб-архив?
Для того, чтобы узнать, что такое веб-архив, стоит вспомнить события, произошедшие более 20 лет назад. В 1996 году по инициативе американского программиста, Брюстера Кайла, был создан сайт archiveorg. Благодаря этому ресурсу, любой пользователь может найти сохранённые копии сайтов разных лет.

Со временем библиотека Web archive расширилась и к 2016 году включала в себя 502 миллиарда копий веб-страниц. Это является одним из лучших примеров коллаборации с целью принести обществу пользу. Для того, чтобы посмотреть в реальном времени сайты, которые функционировали некоторое время назад, достаточно зайти в архив и найти его в системе.
Основной целью, которую преследовал Кайл, было сохранение исторические ценности интернет-пространства. Web archive может использовать каждый пользователь, при этом бесплатно. Для работы веб-архива по сохранению интернет-ресурсов может быть только одно препятствие. Если в настройках сайта нет запрета на сохранение информации с ресурса, такой сайт сможет войти в базу веб-архива.
Как происходит пополнение веб-архива? Для этого было создано программное обеспечение, посещающее и сохраняющее сайта с определённой частотой. Так же есть возможность делать сохранения ресурсов вручную. Например, при посещении сайта можно сохранить страницу о курсах СЕО для начинающих или любую другую часть ресурса. Это поможет сохранить информацию с течением времени.
Сохраненная копия страницы в поисковых системах Яндекс и Google
Для сохранения копий страниц понадобятся дополнительные сервисы. Поисковые системы сохраняют последние версии страниц, которые были проиндексированы поисковым роботом.
Для этого в строке поиска Яндекс вводим адрес сайта с оператором site: или url: в зависимости от того, что хотим проверить конкретную страницу или ресурс целиком. Нажимаем на стрелочку рядом с URL и выбираем «Сохраненная копия».

Откроется последняя версия страницы, которая есть у ПС. Можно посмотреть только текст, выбрав одноименную вкладку.
Посмотреть сохраненную копию конкретной страницы в Google можно с помощью оператора cache. Например, вводим cache:trinet.ru и получаем:

Вы так же можете посмотреть текстовую версию страницы.
Найти сохраненную версию страницы можно и через выдачу Google. Необходимо:
- использовать оператор site:, либо указать сразу необходимый URL
- найти страницу в выдаче
- нажать на стрелочку рядом с URL
- выбрать «Сохраненная копия»

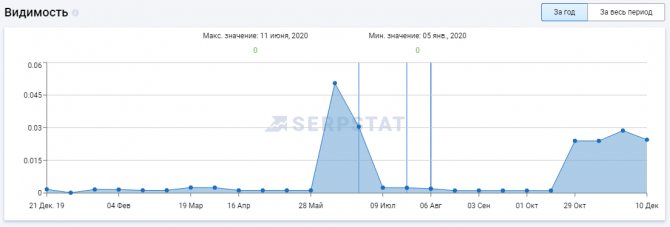
Платформа Serpstat
С помощью этого инструмента можно посмотреть изменения видимости сайта в поисковой выдаче за год или за все время, что сайт находится в базе Serpstat.
Сервис Keys.so
Используя этот сервис можно посмотреть, сколько страниц находится в выдаче, в ТОП – 1, ТОП – 3 и т.д. Можно регулировать параметры на графике и выгружать полную статистику в Excel.

Зачем нужен web archive и как его можно использовать
Веб-архивирование нужно для того, чтобы можно было восстановить важную утерянную информацию с сайта, которая может не сохраниться из-за технических проблем или повреждения вирусом.

Например, владелец сайта создал его и наполнил описанием продукции, полезными статьями и изображениями по тематике. Через время веб-ресурс был обновлен и тексты заменены на новые. А еще через время понадобились именно старые тексты. В таких случаях и нужен открытый интернет-архив, в котором можно найти десятки сохраненных версий сайта на разные даты.
Предназначение веб-архивов:
- Возможность восстановления собственного контента в случае повреждения или удаления старых текстов и изображений.
- Просмотр старых файлов на других работающих веб-сайтах.
- Анализ изменений наполнения онлайн-ресурсов (собственных и конкурентных).

Сохранение авторского контента — это важная функция. Намного проще корректировать уже имеющиеся тексты, чем писать новые с нуля. Можно сделать рерайт (переписывание текста другим словами с сохранением смысла и структуры). Особенности использования резервных копий приведены в Табл. 1.
Табл. 1. Для каких целей можно использовать более ранний контент

[править] Примеры
Роскомнаха банит архивы интернета (Блюстители)
- web.archive.org — старейший веб-архив, сохраняющий копии сайтов с 1996 года в автоматическом режиме в определённые промежутки времени. Имеет юридический статус библиотеки, является некоммерческой организацией. Сайт обладает несколькими зеркалами. На 25 июня 2015 года был внесён в реестр запрещённых сайтов и заблокирован на территории РФ за страницу «Одиночный Джихад» (а ещё ранее — за страницу с видеороликом «Звон мечей» террористической группировки ИГИЛ, запрещённой в РФ). В начале июля доступ к сайту был возозбновлён в связи с переносом материала в отдельный архив, доступный для закачки. Позже снова заблокирован, но по состоянию на 2020 год уже удалён из реестра.
- peeep.us — совмещенный с сокращателем ссылок сайт, позволяющий сохранять страницы самим пользователям. Создаёт зеркало страницы на фиксированный момент времени, который отображается вверху жёлтой полосой, с сокращённым URL-адресом. В отличие от веб-архива, щёлкая по ссылкам, открываются веб-страницы на текущий момент времени, а не в архиве. В отличие от archive.is, может сохранять страницы, для просмотра которые видны только сохраняющему, но не остальным людям. Не сохраняет картинки и фреймы. На 25 июня 2015 года был внесён в реестр запрещённых сайтов и заблокирован на территории РФ, позднее вообще перестал открываться. На июль 2015 года на месте сайта выдаётся ошибка 404. Был разблокирован в начале сентября 2015 года.
- archive.is — сайт, аналогичный peeep.us. Отличается тем, что сохраняет не только основной html-файл страницы, но также и все картинки, стили, фреймы и фонты. Также умеет сохранять страницы с Web2.0-сайтов, например с twitter.com.
Также в роли веб-архивов выступают кеши поисковых систем, но в отличие от первых, они ненадёжны, поскольку могут быстро удаляться. Наибольший срок хранения страниц замечен за Яндексом.
В викисреде
Роль веб-архивов могут выполнять отдельные разделы сайтов, которые сами по себе ими не являются:
Копипаста Луркоморья — сборник заинтересовавших пользователей Луркоморья текстов со страниц Интернета или взятые из книжных источников.
Архивы Викиреальности — сохраняет заслуживающие внимание страницы и творчество, связанное с викисредой. Для архивов выделено специальное пространство имён.
Авторские проекты в Традиции (например, творчество АПЭ, Погребного и т. п.) — сборник творчества различных авторов, которое (в большинстве своём) ранее где-то выкладывалось.
Как добавить современную версию сайта в веб-архив Wayback Machineи выполнить другие действия
Онлайн-платформа по веб-архивированию сайтов предоставляет множество возможностей разработчикам и владельцам ресурсов (Табл. 2).
Табл. 2. Как работать с веб-архивом
| Возможности | Особенности выполнения |
| Сохранение нужной версии сайта на платформе интернет-архива | Нужно самостоятельно инициировать сохранение. В разделе платформы «Save Page Now» нужно забить домен онлайн-ресурса и нажать «Save page». Такую процедуру рекомендуется повторять каждый раз, когда в контент были внесены исправления или дополнения |
| Запрет на добавление интернет-ресурса в память веб-архива | Для запрета добавления нужно прописать это в файле robots.txt. В панелях хостеров есть корневой каталог, в котором предусмотрена возможность редактирования файлов. При введении кода User-agent: ia_archiverDisallow: /User-agent: ia_archiver-web.archive.orgDisallow: / файл будет скрыт от копирования. При введении такого кода из веб-архива удаляется и текущая версия сайта и не осуществляется системное копирование (до тех пор, пока в файле robots.txt есть такие настройки или пока не закончится срок регистрации домена) |
| Восстановление веб-сайта из интернет-архива | Если сайт был поврежден вирусами или есть другие технические проблемы, из-за которых контент был нарушен, можно восстановить файлы из онлайн-хранилища. Для этого применяются специальные сервисы. Есть платные и бесплатные варианты, которые выбираются с учетом количества страниц для восстановления |

Возможности использования веб-архивов
Возможности сохраненной истории
Теперь каждый знает, что такое веб-архив, какие сайты предоставляют услуги сохранения копий проектов. Но многие до сих пор не понимают, как использовать представленную информацию. Возможности архивных данных выражаются в следующем:
- Выбор доменного имени. Не секрет, что многие веб-мастера используют уже прокачанные домены. Стоит понимать, что опытные юзеры отслеживают не только целевые параметры, но и историю предыдущего использования. Каждый пользователь сети желает знать, что приобретает: имелись ли ранее запреты или санкции, не попадал ли проект под фильтры.
- Восстановление сайта из архивов. Иногда случается беда, которая ставит под угрозу существование собственного проекта. Отсутствие своевременных бэкапов в профиле хостинга и случайная ошибка может привести к трагедии. Если подобное произошло, не стоит расстраиваться, ведь можно воспользоваться веб-архивом. О процессе восстановления поговорим ниже.
- Поиск уникального контента. Ежедневно на просторах интернета умирают сайты, которые наполнены контентом. Это случается с особым постоянством, из-за чего теряется огромный поток информации. Со временем такие страницы выпадают из индекса, и находчивый веб-мастер может позаимствовать информацию на личный проект. Конечно, существует проблема с поиском, но это вторичная забота.
Мы рассмотрели основные возможности, которые предоставляют веб-архивы, самое время перейти к более подробному изучению отдельных элементов.
Восстанавливаем сайт из веб-архива
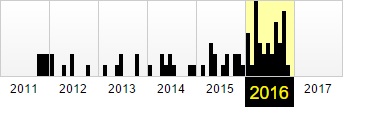 Фиксация в веб-архиве за 2011–2016 годы
Фиксация в веб-архиве за 2011–2016 годы
Никто не застрахован от проблем с сайтами. Большинство их них решается с использованием бэкапов. Но что делать, если сохраненной копии на сервере хостинга нет? Воспользоваться веб-архивом. Для этого следует:
- Зайти на специализированный ресурс, о которых мы говорили ранее.
- Внести собственное доменное имя в строку поиска и открыть проект в новом окне.
- Выбрать наиболее удачный снимок, который располагается ближе к проблемной дате и имеет полноценный вид.
- Исправить внутренние ссылки на прямые. Для этого используем ссылку «http://web.archive.org/web/любой_порядковый_номер_id_/Название сайта».
- Скопировать потерянную информацию или данные дизайна, которые будут применены для восстановления.
Заметим, что процесс несколько утомительный, с учетом скорости работы архива. Поэтому рекомендуем владельцам больших веб-ресурсов чаще выполнять бэкапы, что сохранит время и нервы.
Ищем уникальный контент для собственного сайта
 Уникальный контент из веб-архива
Уникальный контент из веб-архива
Некоторые веб-мастера используют интересный способ получения нового, никому не нужного контента. Ежедневно сотни сайтов уходят в небытие, а вместе с ними теряется информация. Чтобы стать владельцем контента, нужно выполнить следующее:
- Внести URLв строку поиска.
- На сайте аукциона доменных имен скачать файлы с именем ru.
- Открыть полученные файлы с использованием excel и начать отбор по параметру наличия проектной информации.
- Найденные в списке проекты ввести на странице поиска веб-архива.
- Открыть снимок и получить доступ к информационному потоку.
Рекомендуем отслеживать контент на наличие плагиата, это позволит найти действительно достойные тексты. А на этом все! Теперь каждый знает о возможностях и методах использования веб-архива. Используйте знание с умом и выгодой.
История создания архива интернета
Wayback Machine является одним из двух главных проектов archive.org. Этот некоммерческий сервис был создан в 1996 году Брюстером Кейлом. Машина времени сайтов имеет четкую цель: сбор и хранение копий ресурсов вместе со всем контентом для возможности свободного просмотра несуществующих или неподдерживающихся страниц в будущем. С 1999-го робот стал фиксировать еще и аудио, видео, иллюстрации, программное обеспечение.
База современного архива собиралась в течение 20 лет, у нее не существует аналогов. Статистика впечатляет: на сегодняшний день в сервисе находится 279 миллиардов страниц, 11 миллионов книг и статей, 100 тысяч программ и миллион картинок.
А знаете ли вы? Веб-архив сайтов часто имеет проблемы на законодательном уровне из-за нарушения авторских прав. По требованию правообладателей библиотека удаляет материалы из публичного доступа.
Как посмотреть сайт в прошлом
Есть несколько сервисов, в которых можно посмотреть, как менялось визуальное оформление страниц сайта, его структуру страниц и контент, положение в поисковой выдаче и какие изменения вносились в регистрационные данные за время существования ресурса.
Сервис Веб-архив
При его использовании сначала заходим на сайт https://web.archive.org/ и после вводим адрес страницы.

График ниже показывает количество сохранений: первое было в 1998 году.

Дни, в которые были сохранения, отмечены кружком. При клике на время во всплывающем окне, открывается сохраненная версия. Показано ниже:

Как выгрузить сайт из ВебАрхива, расскажем дальше.
Сервис Whois History
Для его использования заходим на сайт http://whoishistory.ru/ и вводим данные в поиске по доменам и IP, либо по домену:

Сервис покажет информацию по данным Whois, где собраны сведения от всех регистраторов доменных имен. Посмотреть можно возраст домена, кто владелец, какие изменения вносились в регистрационные данные и т.д.

Как пользоваться веб архивом
Если вы хотите выполнить поиск в архиве веб-страниц, введите в адресную строку вашего браузера адрес web.archive.org.ru, после чего в поле поиска укажите адрес интересуемого сайта. Например, введите адрес домашней страницы Яндекса http://yandex.ru и нажмите клавишу «Enter».

Сохраненные копии главной страницы Яндекс на сайте web.archive.org
Зелеными кружочками обозначены даты когда была проиндексирована страница, нажав на него вы перейдете на архивную копию сайта. Для того чтобы выбрать архивную дату, достаточно кликнуть по временной диаграмме по разделу с годом и выбрать доступные в этом году месяц и число. Так же если вы нажмете на ссылку «Summary of yandex.ru» то увидите, какой контент был проиндексирован и сохранен в архиве для конкретного сайта с 1 января 1996 года ( это дата начала работы веб архива).

Какой контент сохраняет веб-архив интернета
Нажав на выбранную дату, вам откроется архивная копия страницы, такая как она выглядела на веб-сайте в прошлом. Давайте посмотрим на Яндекс в молодости, ниже приведен снимок главной страницы Яндекса на 8 февраля 1999 года.

Веб архив копия сайта Яндекс на 08.02.1999
Вполне возможно, что в архивном варианте страниц, хранящемся на веб-сайте Archive.org, будут отсутствовать некоторые иллюстрации, и возможны ошибки форматирования текста. Это результатом того, что механизм архивирования веб-сайтов, пытается, прежде всего, сохранить текстовый контент web-сайтов. Помните об еще одном ограничении онлайн-архива. При поиске конкретного контента, размещенного на определенной архивной странице, лучше всего вводить ее точный адрес, а не главный адрес данного веб-сайта.
Возвращаясь к нашему примеру: вы получили доступ к архивному контенту, размещенному на главной странице Яндекса, при нажатии на ссылки в архивной версии могут как загружаться так и не загружаться другие страницы сайта. Так в нашем варианте страница «последние 20 запросов» была найдена, а вот страница «Реклама на yandex.ru» не нашлась.
Подводя итоги можно сказать, что web.archive.org поистине уникальный и грандиозный проект. Он действительно является машиной времени для интернета, позволяя найти удаленные сайты и их архивные версии . Как использовать предоставляемые возможности решать только вам, но использовать их можно и нужно обязательно !
archive.md
Адреса данного Архива Интернета:
На главной странице говорящие за себя поля:
- Архивировать страницу, которая сейчас онлайн
- Искать сохранённые страницы

Для поиска по сохранённым страницам можно как указывать конкретный URL, так и домены, например:
- microsoft.com покажет снимки с хоста microsoft.com
- *.microsoft.com покажет снимки с хоста microsoft.com и всех его субдоменов (например, www.microsoft.com)
- покажет архив данного url (поиск чувствителен к регистру)
- поиск архивных url начинающихся с http://twitter.com/burg
Данный сервис сохраняет следующие части страницы:
- Текстовое содержимое веб страницы
- Изображения
- Содержимое фреймов
- Контент и изображения загруженные или сгенерированные с помощью Javascript на сайтах Web 2.0
- Скриншоты размером 1024×768 пикселей.
Не сохраняются следующие части веб-страниц:
- Flash и загружаемый им контент
- Видео и звуки
- RSS и другие XML-страницы сохраняются ненадёжно. Большинство из них не сохраняются, или сохраняются как пустые страницы.
Архивируемая страница и все изображения должны быть менее 50 Мегабайт.
Для каждой архивированной страницы создаётся ссылка вида http://archive.is/XXXXX, где XXXXX это уникальный идентификатор страницы. Также к любой сохранённой странице можно получить доступ следующим образом:
- http://archive.is/2013/http://www.google.de/ — самый новый снимок в 2013 году.
- http://archive.is/201301/http://www.google.de/ — самый новый снимок в январе 2013.
- http://archive.is/20130101/http://www.google.de/ — самый новый снимок в течение дня 1 января 2013.
Дату можно продолжить далее, указав часы, минуты и секунды:
- http://archive.is/2013010103/http://www.google.de/
- http://archive.is/201301010313/http://www.google.de/
- http://archive.is/20130101031355/http://www.google.de/
Для улучшения читаемости, год, месяц, день, часы, минуты и секунды могут быть разделены точками, тире или двоеточиями:
- http://archive.is/2013-04-17/http://blog.bo.lt/
- http://archive.is/2013.04.17-12:08:20/http://blog.bo.lt/
Также возможно обратиться ко всем снимкам указанного URL:
http://archive.is/http://www.google.de/
Все сохранённые страницы домена:
http://archive.is/www.google.de
Все сохранённые страницы всех субдоменов
http://archive.is/*.google.de
Чтобы обратиться к самой последней версии страницы в архиве или к самой старой, поддерживаются адреса вида:
- http://archive.is/newest/http://reddit.com/
- http://archive.is/oldest/http://reddit.com/
Чтобы обратиться к определённой части длинной страницы имеется две опции:
В доменах поддерживаются национальные символы:
- http://archive.is/www.maroñas.com.uy
- http://archive.is/*.测试
Обратите внимание, что при создании архивной копии страницы архивируемому сайту отправляется IP адрес человека, создающего снимок страницы. Это делается через заголовок X-Forwarded-For для правильного определения вашего региона и показа соответствующего содержимого.
Что такое веб-архив и зачем он нужен?
 Веб-архив — история миллионов сайтов
Веб-архив — история миллионов сайтов
Веб-архив — это специализированный сайт, который предназначен для сбора информации о различных интернет-ресурсах. Робот осуществляет сохранение копии проектов в автоматическом и ручном режиме, все зависит лишь от площадки и системы сбора данных.
На текущий момент имеется несколько десятков сайтов со схожей механикой и задачами. Некоторые из них считаются частными, другие — открытыми для общественности некоммерческими проектами. Также ресурсы отличаются друг от друга частотой посещения, полнотой сохраняемой информации и возможностями использования полученной истории.
Как отмечают некоторые эксперты, страницы хранения информационных потоков считаются важной составляющей Web 2.0. То есть, частью идеологии развития сети интернет, которая находится в постоянной эволюции
Механика сбора весьма посредственная, но более продвинутых способов или аналогов не имеется. С использованием веб-архива можно решить несколько проблем: отслеживание информации во времени, восстановление утраченного сайта, поиск информации.
Как использовать веб-архив?

Форма для поиска информации на Peeep.us Как уже отмечалось выше, веб-архив — это сайт, который предоставляет определенного рода услуги по поиску в истории. Чтобы использовать проект, необходимо:
- Зайти на специализированный ресурс (к примеру, web.archive.org).
- В специальное поле внести информацию к поиску. Это может быть доменное имя или ключевое слово.
- Получить соответствующие результаты. Это будет один или несколько сайтов, к каждому из которых имеется фиксированная дата обхода.
- Нажатием по дате перейти на соответствующий ресурс и использовать информацию в личных целях.
О специализированных сайтах для поиска исторического фиксирования проектов поговорим далее, поэтому оставайтесь с нами.
Как найти уникальный контент из веб-архива для вашего сайта?
Статьи, расположенные на заброшенных ресурсах, обычно не представляют никакой ценности для их бывших владельцев. А ведь в мир иной ежедневно уходят десятки сайтов. И среди кучи хлама, выброшенного на помойку истории, можно найти настоящие самородки — приличные тексты, которые достанутся вам бесплатно.
Поисковики хорошо относятся к любому актуальному и уникальному контенту — можно не бояться попасть в их немилость только из-за того, что статьи взяты из веб-архива чужого сайта.
Итак, последовательность действий следующая:
- Найдите подходящие вам блоги. Для этого следует зайти на Reg.ru и скачать оттуда список недавно освободившихся доменов.
- Посетите архив интернета с целью поиска сохраненных копий.
- Проверьте понравившиеся тексты через антиплагиат (контент может быть уже скопирован на другие сайты).
- Опубликуйте уникальные статьи на своем ресурсе.
При разумном подходе такой способ пополнения сайта контентом можно поставить на поток. Поиски материалов на мертвых блогах оправданы экономией времени на написание текстов и денег, которые бы вам пришлось заплатить авторам.
Хроника событий
АЗАПИ, по данным Роскомсвободы, действует в интересах издателя ООО «Аудиокнига», и началось все с аудиокниг по серии романов Глуховского «Метро 2033», к которым позже добавилось произведение Дарьи Донцовой «Третий глаз алмаз». Иск по этому делу (номер дела 3-0335/2019) был подан 13 марта 2019 г, а Мосгорсуд рассмотрел его 13 мая 2019 г., притом в экстренном порядке, и вынес вердикт в пользу истца. Решение вступило в силу 15 июня 2019 г.
По решению суда, «Интернет архиву» и другим ответчикам («ДейтаВебГлобал Групп» и ООО «ТК Мароснет») было запрещено «создавать технические условия, обеспечивающие размещение» аудиокниг на веб-ресурсах, перечисленных в иске
Важно отметить, что представители «Интернет архива» участия в заседании не принимали, а о решении суда американская организация извещена не была

Россию могут навсегда оставить без Архива интернета
Второй иск был подан 21 июня 2019 г. (номер дела – 3-0634/2019, ответчик – «Интернет архив»). В нем истец (ООО «Аудиокнига», как и в первом случае) требовал заблокировать сайт archive.org в России на постоянной основе. Заседание по иску состоялось 16 августа 2019 г., однако рассмотрение дела было отложено по причине отсутствия у АЗАПИ доказательств того, что «Третий глаз алмаз» действительно был записан в форме аудиокниги обществом «Аудиокнига», и что у него (общества) есть права на эту книгу.
Рассмотрение было назначено на 12 сентября 2019 г, и существует еще одна причина переноса – по информации Роскомсвободы, на решение Мосгорсуда по первому иску была подана жалоба, дата рассмотрения которой на 23 августа 2019 г. оставалась неизвестной. По обоим делам американскую организацию в российском суде представляют юристы Роскомсвободы и Центра цифровых прав адвокат Саркис Дарбинян и Екатерина Абашина.
Как архивировать фото, видео и Истории
Чтобы добавить какой-либо медиафайл в Архив, пользователь должен:
- Открыть публикацию на своей странице – нажать три точки сверху.
- В выпадающем меню: «Архивировать».
После, можно посмотреть архивированные фото перейдя в соответствующий раздел. Найти архив с заранее архивированными фото в Инстаграме проще по датам и снимку, который был добавлен.
С помощью такой функции, в памяти учетной записи сохраняются фотографии сроком более одного года. Вернуть архивированные фото в Инстаграме возможно в любой момент, когда пользователь захочет разнообразить Ленту.
В настройках Истории доступно два параметра: сохранять в Архив и на смартфона. Но все публикации, которые ранее не были отмечены как архивируемые, добавлены в раздел не будут. Их нельзя восстановить или найти в Архиве Инстаграма.
В Архив можно добавить:
- фотографии. Публикации из Ленты с описанием, геолокацией и комментариями;
- Stories. Любые записи: начиная от целого набора коротких видео и заканчивая изображениями;
- видео. Вне зависимости от продолжительности и качества;
- карусели. Фото и видео альбомы, которые были добавлены на страницу.
При архивировании сохраняются лайки и комментарии. Но информация из статистики будет утеряна. Восстанавливая архивированные фото в Инстаграме, информация о количестве ранее просмотревших удаляется.
Как скачать все изменения страницы из веб-архива
Если вас интересует не весь сайт, а определённая страница, но при этом вам нужно проследить все изменения на ней, то в этом случае используйте программу Waybackpack.
К примеру для скачивания всех копий главной страницы сайта suip.biz, начиная с даты (—to-date 2017), эти страницы должны быть помещены в папку (-d /home/mial/test), при этом программа должна следовать HTTP редиректам (—follow-redirects):
waybackpack suip.biz -d ./suip.biz-copy --to-date 2017 --follow-redirects

Структура директорий:
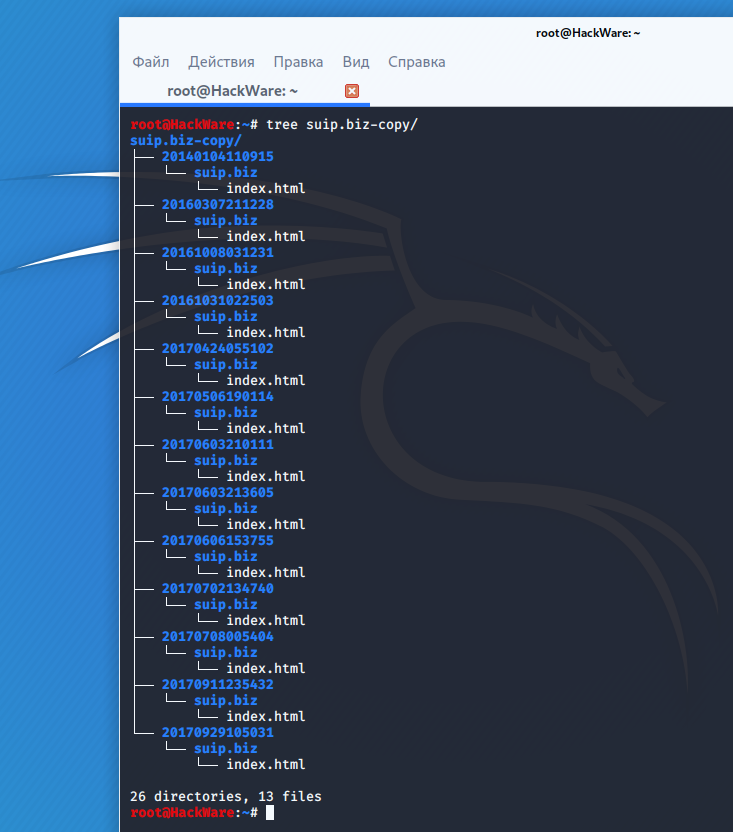
Чтобы для указанного сайта (hackware.ru) вывести список всех доступных копий в веб-архиве (—list):
waybackpack hackware.ru --list