Что такое база данных в информатике
Содержание:
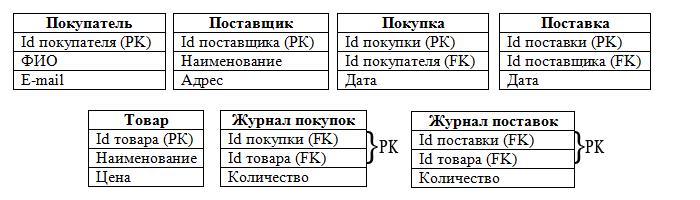
Как хранится информация в БД
В основе всей структуры хранения лежат три понятия:
- База данных;
- Таблица;
- Запись.
База данных
База данных — это высокоуровневное понятие, которое означает объединение совокупности данных, хранимых для выполнения одной цели.
Если мы делаем современный сайт, то все его данные будут храниться внутри одной базы данных. Для сайта онлайн-дневника наблюдений за погодой тоже понадобится создать отдельную базу данных.
Таблица
По отношению к базе данных таблица является вложенным объеком. То есть одна БД может содержать в себе множество таблиц.
Аналогией из реального мира может быть шкаф (база данных) внутри которого лежит множество коробок (таблиц).
Таблицы нужны для хранения данных одного типа, например, списка городов, пользователей сайта, или библиотечного каталога.
Таблицу можно представить как обычный лист в Excel-таблице, то есть совокупность строк и столбцов.
Наверняка каждый хоть раз имел дело с электронными таблицами (MS Excel).
Заполняя такую таблицу, пользователь определяет столбцы, у каждого из которых есть заголовок. В строках хранится информация.
В БД точно также: создавая новую таблицу, необходимо описать, из каких столбцов она состоит, и дать им имена.
Запись
Запись — это строка электронной таблицы.
Это неделимая сущность, которая хранится в таблице. Когда мы сохраняем данные веб-формы с сайта, то на самом деле добавляем новую запись в какую-то из таблиц базы данных. Запись состоит из полей (столбцов) и их значений. Но значения не могут быть какими угодно.
Определяя столбец, программист должен указать тип данных, который будет храниться в этом столбце: текстовый, числовой, логический, файловый и т.д. Это нужно для того, чтобы в будущем в базу не были записаны данные неверного типа.
Соберем всё вместе, чтобы понять, как будет выглядеть ведение дневника погоды при участии базы данных.
- Создадим для сайта новую БД и дадим ей название «weather_diary».
- Создадим в БД новую таблицу с именем «weather_log» и определим там следующие столбцы:
- Город (тип: текст);
- День (тип: дата);
- Температура (тип: число);
- Облачность (тип: число; от 0 (нет облачности) до 4 (полная облачность));
- Были ли осадки (тип: истина или ложь);
- Комментарий (тип: текст).
- При сохранении формы будем добавлять в таблицу weather_log новую запись, и заполнять в ней все поля информацией из полей формы.
Теперь можно быть уверенными, что наблюдения наших пользователей не пропадут, и к ним всегда можно будет получить доступ.
Реляционная база данных
Английское слово „relation“ можно перевести как связь, отношение.
А определение «реляционные базы данных» означает, что таблицы в этой БД могут вступать в отношения и находиться в связи между собой.
Что это за связи?
Например, одна таблица может ссылаться на другую таблицу. Это часто требуется, чтобы сократить объём и избежать дублирования информации.
В сценарии с дневником погоды пользователь вводит название своего города. Это название сохраняется вместе с погодными данными.
Но можно поступить иначе:
- Создать новую таблицу с именем „cities“.
- Все города в России известны, поэтому их все можно добавить в одну таблицу.
- Переделать форму, изменив поле ввода города с текстового на поле типа «select», чтобы пользователь не вписывал город, а выбирал его из списка.
- При сохранении погодной записи, в поле для города поставить ссылку на соответствующую запись из таблицы городов.
Так мы решим сразу две задачи:
- Сократим объём хранимой информации, так как погодные записи больше не будут содержать название города;
- Избежим дублирования: все пользователи будут выбирать один из заранее определённых городов, что исключит опечатки.
Связи между таблицами в БД бывают разных видов.
В примере выше использовалась связь типа «один-ко-многим», так как одному городу может соответствовать множество погодных записей, но не наоборот!
Бывают связи и других типов: «один-к-одному» и «многие-ко-многим», но они используются значительно реже.
Объектно-ориентированные субд
Появление объектно-ориентированных СУБД вызвано потребностями программистов на ОО-языках, которым были необходимы средства для хранения объектов, не помещавшихся в оперативной памяти компьютера. Также важна была задача сохранения состояния объектов между повторными запусками прикладной программы. Поэтому, большинство ООСУБД представляют собой библиотеку, процедуры управления данными которой включаются в прикладную программу. Примеры реализации ООСУБД как выделеного сервера базы данных крайне редки.
Сразу же необходимо заметить, что общепринятого определения «объектно-ориентированной модели данных» не существует. Сейчас можно говорить лишь о неком «объектном» подходе к логическому представлению данных и о различных объектно-ориентированных способах его реализации.
Структура
Структура объектной модели описываются с помощью трех ключевых понятий:
инкапсуляция — каждый объект обладает некоторым внутренним состоянием (хранит внутри себя запись данных), а также набором методов — процедур, с помощью которых (и только таким образом) можно получить доступ к данным, определяющим внутреннее состояние объекта, или изменить их. Таким образом, объекты можно рассматривать как самостоятельные сущности, отделенные от внешнего мира;
наследование — подразумевает возможность создавать из классов объектов новые классы объекты, которые наследуют структуру и методы своих предков, добавляя к ним черты, отражающие их собственную индивидуальность. Наследование может быть простым (один предок) и множественным (несколько предков);
полиморфизм — различные объекты могут по разному реагировать на одинаковые внешние события в зависимости от того, как реализованы их методы.
Целостность данных
Для поддержания целостности объектно-ориентированный подход предлагает использовать следующие средства:
автоматическое поддержание отношений наследования возможность объявить некоторые поля данных и методы объекта как «скрытые», не видимые для других объектов; такие поля и методы используются только методами самого объекта создание процедур контроля целостности внутри объекта
Средства манипулирования данными
К сожалению, в объектно-ориентированном программировании отсутствуют общие средства манипулирования данными, такие как реляционная алгебра или реляционное счисление. Работа с данными ведется с помощью одного из объектно-ориентированных языков программирования общего назначения, обычно это SmallTalk, C++ или Java.
В объектно-ориентированных базах данных, в отличие от реляционных, хранятся не записи, а объекты. ОО-подход представляет более совершенные средства для отображения реального мира, чем реляционная модель, естественное представление данных. В реляционной модели все отношения принадлежат одному уровню, именно это осложняет преобразование иерархических связей модели «сущность-связь» в реляционную модель. ОО-модель можно рассматривать послойно, на разных уровнях абстракции. Имеется возможность определения новых типов данных и операций с ними.
В то же время, ОО-модели присущ и ряд недостатков:
осутствуют мощные непроцедурные средства извлечения объектов из базы. Все запросы приходится писать на процедурных языках, проблема их оптимизации возлагается на программиста;
вместо чисто декларативных ограничений целостности (типа явного объявления первичных и внешних ключей реляционных таблиц с помощью ключевых слов PRIMARY KEY и REFERENCES) или полудекларативных триггеров для обеспечения внутренней целостности приходится писать процедурный код.
Очевидно, что оба эти недостатка связаны с отсутствием развитых средств манипулирования данными. Эта задача решается двумя способами — расширение ОО-языков в сторону управления данными (стандарт ODMG), либо добавление объектных свойств в реляционные СУБД (SQL-3, а также так называемые объектно-реляционных СУБД).
Популярные системы управления реляционными базами данных
Синтаксис SQL может немного отличаться в зависимости от того, какую СУБД вы используете.
MySQL
Основными преимуществами MySQL являются то, что он прост в использовании, недорого, надежен (существует с 1995 года) и имеет большое сообщество разработчиков, которые могут помочь ответить на вопросы.
Разработка с открытым исходным кодом задерживается с тех пор, как Oracle взяла под свой контроль MySQL, и он не включает некоторые дополнительные функции, к которым могут быть привыкли разработчики.
PostgreSQL
PostgreSQL имеет многие из преимуществ MySQL.
Он прост в использовании, недорог, надежен и имеет большое сообщество разработчиков. Он также предоставляет некоторые дополнительные функции, такие как поддержка внешнего ключа, не требуя сложной настройки.
БД Oracle
Большинство ведущих банков мира используют приложения Oracle, потому что Oracle предлагает мощное сочетание технологий и комплексных, предварительно интегрированных бизнес-приложений, включая основные функции, созданные специально для банков.
SQL Server
Microsoft владеет SQL Server. Как и в Oracle DB, исходный код кода очень близок.
Крупные корпоративные приложения в основном используют SQL Server.
Microsoft предлагает бесплатную версию начального уровня под названием Express, но она может стать очень дорогой при масштабировании приложения.
SQLite
Одним из наиболее значительных преимуществ этого является то, что все данные могут храниться локально без необходимости подключения вашей базы данных к серверу.
SQLite – популярный выбор для баз данных в мобильных телефонах, КПК, MP3-плеерах, телевизионных приставках и других электронных устройствах. Курсы SQL на Codecademy используют SQLite.
Система управления базами данных (СУБД)
|
Система управления базами данных (СУБД) — комплекс языковых и программных средств, предназначенных для создания, ведения и использования базы данных многими пользователями. |
В зависимости от вида используемой модели данных различаются иерархические, сетевые и реляционные СУБД.
Наибольшее распространение на персональных компьютерах получили так называемые полнофункциональные реляционные СУБД. Они выполняют одновременно как функцию системных средств, так и функцию пользовательского инструмента для создания приложений. Примером СУБД такого типа является Microsoft Access.
Полноценная информационная система на компьютере состоит из трех частей:
СУБД + база данных + приложения.
Основные действия, которые пользователь может выполнять с помощью СУБД:
-
создание структуры базы данных;
-
заполнение базы данных информацией;
-
изменение (редактирование) структуры и содержания базы данных;
-
поиск информации в БД;
- сортировка данных.
Система основных понятий

Вопросы и задания
-
а) Для чего предназначены базы данных? Выберите верный ответ:
-
для выполнения вычислений на компьютере;
-
для осуществления хранения, поиска и сортировки данных;
- для принятия управляющих решений.
б) Какие существуют варианты классификации БД?
в) Почему реляционный вид БД является наиболее распространенным?
г) Что такое запись в реляционной БД?
д) Что такое поле, тип поля; какие бывают типы полей?
е) Что такое главный ключ записи?
-
-
Определите главный ключ и типы полей в следующих отношениях:
АВТОБУСЫ (НОМЕР МАРШРУТА, НАЧАЛЬНАЯ ОСТАНОВКА, КОНЕЧНАЯ ОСТАНОВКА)
КИНО (КИНОТЕАТР, СЕАНС, ФИЛЬМ, РОССИЙСКИЙ, ДЛИТЕЛЬНОСТЬ)
УРОКИ (ДЕНЬ НЕДЕЛИ, НОМЕР УРОКА, КЛАСС, ПРЕДМЕТ, ПРЕПОДАВАТЕЛЬ)
- Опишите структуру записей (имена полей, типы полей, главные ключи) для баз данных: РЕЙСЫ САМОЛЕТОВ, ШКОЛЫ ГОРОДА, СТРАНЫ МИРА.
Виды нереляционных баз данных
Базы NoSQL делятся на четыре основные категории (в зависимости от решаемых с их помощью задач).
Ключ-значение
Такую базу можно представить как огромную таблицу. В каждой её ячейке хранятся данные произвольного типа, а каждому значению присвоен уникальный ключ, по которому это значение можно найти.
Такая СУБД не поддерживает связи между объектами, выполняет лишь операции поиска значений по ключу, добавления и удаления записи.
Например:
| key | value |
|---|---|
| user1 | {Кузнецов В., отдел маркетинга} |
| user2 | {name:Лена, position:секретарь} |
| user3 | {ООО «Вектор»} |
| user4 | {Трофимова Таня, отд.2, дизайнер} |
| user5 | {Галина Николаевна, гл. бух.} |
| user6 | {65,84,236} |
Базы «ключ-значение» часто используют для кэширования данных и организации очередей.
Их достоинства — быстрый поиск и простое масштабирование.
Их недостаток — нельзя производить операции со значениями. Например — сортировать их или анализировать.
Одна из самых популярных — Redis. Её используют Uber, Slack, Stack Overflow, сайты гостиниц и туристические, социальная сеть Twitter.
Документоориентированные СУБД
В таких данные хранятся в виде иерархических структур (документов) с произвольным набором полей и их значений. Документы объединяются в коллекции.
Если провести аналогию с реляционными СУБД, то коллекциям соответствуют таблицы, а документам — строки в них.
Например, фрагмент документа с информацией о фильмах:
Документоориентированные базы используют в системах управления содержимым (CMS) — для хранения каталогов и пользовательских профилей.
Одна из самых популярных — MongoDB (там можно создавать процедуры на JavaScript).
Колоночные
Эти базы отличаются от реляционных лишь способом хранения данных на накопителе.
Если реляционная база создаёт для каждой таблицы по файлу, то в колоночной отдельный файл создаётся для каждого столбца таблицы.
Например, если реляционная таблица выглядит так:
| name | color | property |
|---|---|---|
| волк | серый | зубастый |
| коза | белая | рогатая |
| капуста | зелёная |
То те же записи колоночной базы будут выглядеть примерно так:
| name | волк | коза | капуста |
| color | серый | белая | зелёная |
| property | зубастый | рогатая |
Что это даёт? Представьте, что вам нужны только названия объектов, а их свойства вас не интересуют.
При выполнении запроса в реляционной таблице просматривается каждая запись и из неё выбираются нужные данные. В колоночной базе с диска будет считана только одна колонка с названиями. Это сокращает время выполнения запроса, причём намного.
Колоночные базы применяются в различных каталогах и архивах данных, работа с которыми основана на подобных выборках.
Одна из самых популярных СУБД такого типа — Apache Cassandra.
Графовые
В некоторых предметных областях данные удобно представлять в виде графов. Для их хранения лучше всего подходят графовые базы.
Вершины (или узлы графа) — это объекты (сущности), а рёбра графа — взаимосвязи между ними.

Проблемы использования баз данных
Сегодняшние крупные корпоративные базы данных часто поддерживают очень сложные запросы и, как ожидается, дадут почти мгновенные ответы на эти запросы. В результате администраторы баз данных постоянно вынуждены использовать самые разные методы для повышения производительности. Вот некоторые общие проблемы, с которыми они сталкиваются:
Управление лавинообразно растущими объемами данных. Стремительный рост количества данных, поступающих от датчиков, подключенных компьютеров и десятков других источников, заставляет администраторов баз данных изо всех сил пытаться управлять и организовывать этот сложный массив данных своих компаний.
Обеспечение безопасности данных. В наши дни утечки данных происходят повсеместно, и хакеры становятся все изобретательнее
Как никогда важно, чтобы данные были в безопасности, но при этом были легко доступны для пользователей. Идти в ногу со спросом
В сегодняшней быстро меняющейся деловой среде компаниям необходим доступ в режиме реального времени к своим данным, чтобы поддерживать своевременное принятие решений и использовать новые возможности.
Управление и обслуживание базы данных и инфраструктуры. Администраторы баз данных должны постоянно следить за базой данных на предмет проблем и выполнять профилактическое обслуживание, а также применять обновления программного обеспечения и исправления. По мере того, как базы данных становятся более сложными, а объемы данных растут, компании сталкиваются с расходами на привлечение дополнительных специалистов для отслеживания и настройки своих баз данных.
Снятие ограничений на масштабируемость. Чтобы выжить, бизнесу необходимо расти, и вместе с ним должно расти и управление данными. Но администраторам баз данных очень сложно предсказать, какой объем ресурсов потребуется компании, особенно для локальных баз данных.
Решение всех этих проблем может занять много времени и может помешать администраторам баз данных выполнять более стратегические функции.
Проблемы модели
Преимущество реляционных хранилищ состоит в том, что они способны обеспечить наилучшее соотношение устойчивости, производительности, гибкости, совместимости и масштабируемости. Реляционные БД предоставляют лёгкий доступ к составляемым отчётам и обеспечивают высокую надёжность и целостность информации из-за отсутствия избыточных данных. Но сейчас, когда всё большее количество приложений работает с высокой нагрузкой, увеличивается значение фактора масштабируемости.
Реляционные БД легко масштабируются, только когда они расположены на одном сервере. Если потребуется увеличить количество серверов и разделить нагрузку между ними, то возрастёт сложность хранилищ, что значительно снизит возможность использовать их как платформу для мощных распределённых систем. Поэтому приходится применять другие типы БД, которые обладают лучшей масштабируемостью и отказываться от возможностей, предоставляемых реляционными хранилищами.
Реляционная БД — это совокупность связей, которые способны структурировать данные, что даёт возможность рационального хранения и эффективного использования информационных материалов.
Иерархическая база данных, структура иерархических данных
Когда речь идёт о хранении иерархических данных, каждый объект хранит информацию в виде определенной сущности, и у каждой сущности могут быть родительские и дочерние элементы, а у дочерних, в свою очередь, тоже могут быть дочерние элементы. Таким образом, можно сказать, что это данные, которые подлежат строгой иерархии (представьте себе своеобразное дерево).
Простой пример иерархических данных — документ в формате XML либо файловая система компьютера.
Нельзя не упомянуть и то, что базы данных этого вида оптимизированы под чтение информации. При такой структуре данные можно быстро выбирать из нужной области, отдавая запрашиваемую информацию пользователям. Например, компьютер легко работает с конкретной папкой либо файлом, которые, по сути, можно назвать объектами структуры иерархических данных. Но когда нужно перебрать всю информацию, это может занять время (если вернуться к вышеописанному примеру, то проверка антивирусом всех уголков нашего компьютера выполняется не так быстро, как хотелось бы).
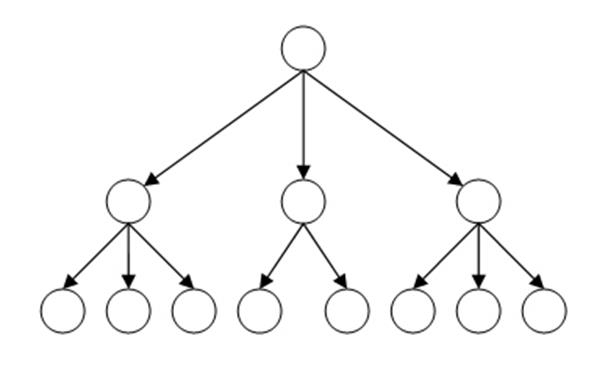
На рисунке представлена классическая структура иерархической базы данных. Вверху находится родитель (его ещё называют корневым элементом), ниже размещены дочерние элементы. Элементы с данными, находящиеся на одном уровне, можно назвать братьями либо соседними элементами. БД данной категории бывают с разным количеством уровней и разной степени вложенности.
Разграничения доступа на примерах Access и MySQL
Защита базы данных на уровне пользователя аналогична способам разграничения прав пользователей локальных сетей. В Access создают несколько рабочих групп, разделенных по интересам. Работа доступна одновременно с одной из баз данных. Можно параллельно работать в разных системах Access, если открыть их в отдельных окнах.
Файл рабочей группы создается автоматически. Он содержит информацию об учетной записи каждой группы или отдельного пользователя. Сохранение данных о правах доступа ведется по каждой учетке отдельно.
Рабочая группа состоит из двух групп:
- администратор;
- пользователи.
В случае необходимости возможно создание более двух групп пользователей данных. Один и тот же человек может состоять одновременно в разных группах. Каждому из сотрудников можно присвоить разные пароли.
Администратор получает максимальное число привилегий, группа пользователей работает в соответствии с их уровнем доступа.
Формы и отчеты Access можно защитить двумя способами:
1. Чтобы исключить случайное повреждение пользователем приложения, исключается использование режима Конструктора.
2. Скрытие некоторых полей таблицы от пользователей.
Таким образом появляется возможность контролировать использование секретных данных сотрудниками и ограничить доступ к ним посторонних. Расширить права пользователя или группы могут лишь админ и владелец информации (создатель). Имеется возможность передачи базы данных и прав на нее другому владельцу.
Одним из вариантов внедрения безопасной системы авторизации и регистрации является MySQL. Управление сервером происходит через Интернет с помощью РhpMyAdmin. Первый уровень защиты – это вход в БД через логин и пароль. Далее СУБД MySQL разграничивает права доступа. Доступ ограничивается как к системе управления, так и к каждому компоненту БД (таблица, строка, запись и т.п.). Владельцы БД имеют возможность шифровать информацию.
Представления о преимуществах и недостатках
Аппаратная составляющая вышла на уровень гарантированной надежности, скорости и эффективности. Дело стало за малым: программная составляющая должна обеспечить свой уровень компетенции.
Одни авторы относят к преимуществам:
- контроль, избыточность, непротиворечивость данных;
- совместное использование, обеспечение их целостности;
- безопасность, стандарты, эффективность;
- компромисс при противоречивых требованиях;
- доступность, производительность работы;
- простота сопровождения, параллельная работа;
- службы резервного копирования и восстановления.
Другие смотрят на преимущества иначе:
- эффективное использование памяти и отличные показатели временных затрат на выполнение операций;
- эффективное манипулирование данными;
- одни и те же модели можно использовать для решения многих задач;
- простота моделирования и физическая реализация;
- высокая эффективность обработки.

Недостатки определяют обычно так:
- сложность, размер, стоимость;
- затраты на аппаратное обеспечение (финансы);
- затраты на преобразование (вычислительные и временные);
- серьезные последствия при выходе системы из строя;
- в контексте сетевых БД: сложность физической реализации, жесткость связи между элементами данных, ограничения на удобство манипуляции данными;
- иерархические БД: громоздкость, сложность физической реализации для больших древовидных структур;
- реляционные БД: отсутствие стандартных средств идентификации каждой записи.
Фактически области применения обуславливают различные объекты базы данных, что формирует отличия в критериях оценки преимуществ и недостатков. То что не имеет значения в одной области применения, крайне актуально в другой. Одна и та же база данных может стать причиной успеха или испортить все дело.
Какие реляционные БД популярны в веб-разработке
MySQL
Это открытая СУБД, купленная Oracle в придачу к Sun Microsystems. С ней работают более половины (55,6%) всех разработчиков (по опроса, который в 2020 году провёл сайт StackOverflow.com среди 65 тысяч респондентов).
Главные её преимущества — бесплатность и высокая скорость работы с данными. MySQL создавалась для обработки огромных массивов информации в промышленных масштабах, но благодаря доступности и быстродействию оккупировала Всемирную паутину, заслужив звание «СУБД всея интернета». И сегодня MySQL всё ещё самая удобная СУБД для работы с интернет-страницами и веб-приложениями.
MySQL пользуется мощной поддержкой у создателей языков программирования: практически во всех популярных языках есть интерфейс для работы с ней.
SQLite
Эта СУБД использует большую часть стандартного языка SQL.
Главное преимущество SQlight — встраиваемость. Это объясняется тем, что SQlight не приложение типа «клиент-сервер» (в отличие от других реляционных СУБД), а библиотека, которую подключают непосредственно к программе.
И она тоже весьма популярна: достаточно сказать, что SQLite есть в каждом смартфоне. Например, в смартфонах на Android там хранятся контакты и медиа, а в iOS её используют многие приложения.
PostgreSQL
Её можно назвать самой продвинутой. Это не просто реляционная, а объектно-реляционная свободная СУБД.
PostgreSQL поддерживает не только типы данных, которые есть в других реляционных СУБД. Помимо числовых, текстовых, булевых и других стандартных типов, в ней можно хранить и обрабатывать геометрические и денежные данные, сетевые адреса, JSON, XML, массивы, а также создавать собственные типы данных.