Sql и nosql: инь и ян в мире баз данных
Содержание:
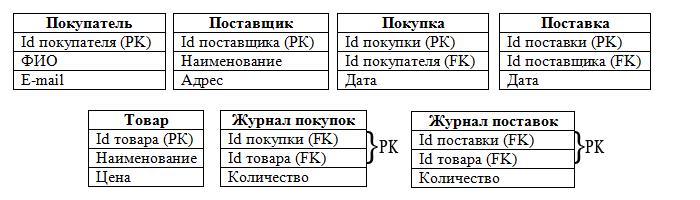
Структуры простейших БД
Если в базе отсутствует информация, ее называют пустой. Она является полноценной БД потому, что содержит сведения о своей структуре. Это определяет способы занесения данных, а также их изменения в базе.
Структура двумерных таблиц, например, образована набором полей. Методом внесения строк и столбцов может создаваться уже другая база данных. Таким образом, изменяется сама структура.
Программные системы управления базами данных, а точнее их поля, могут определять групповые характеристики информации, вносимой в ячейки, относящиеся к каждому из полей. Их свойства могут различаться следующим образом: имя, размер, тип и формат поля, подпись, маска ввода, значение по умолчанию, пустая строка и многое другое. Типы данных делятся на числовой, денежный, счетчик, текстовый, дата/время, логический, место для подставок, гиперссылка и т. д.

Сколько стоит бесплатный сыр
Стоимость владения
Для баз данных, как и для любого софта, существует понятие полной стоимости владения (Total Cost of Ownership, TCO).
Приобретая программный продукт, мы вкладываем деньги не только в лицензии — для того чтобы получить какой-то эффект от приобретения и заставить ПО реально работать, необходимо затратить деньги и на множество сопутствующих вещей.
Вообще говоря, ТСО — это схема для вычисления всех затрат, связанных с ПО. Таких схем существует несколько, и компании-производители программного обеспечения постоянно соревнуются в снижении этого показателя (причем обычно выигрывает тот, кто измеряет).
Традиционно считается, что ТСО состоит из трех частей:
стоимость аппаратного обеспечения;
стоимость программного обеспечения;
стоимость персонала, необходимого для обслуживания ПО.
Посчитали — прослезились…
Прежде всего, конечно, стоит обратиться к стоимости персонала. Хорошо известно, что для нормального функционирования системы на той же Oracle нужен профессиональный администратор базы данных. Конечно, пока система внедряется, эту работу обычно выполняют разработчики, но потом без администратора не обойтись. Сколько нужно платить толковому администратору, можете выяснить сами.
Затем — hardware. 1 Гбайт оперативной памяти для системы, основанной, скажем, на Firebird и обслуживающей 30–50 пользователей, вполне достаточно, тогда как для Oracle потребуется куда больше.
И несколько слов о стоимости программного обеспечения. Да, сама СУБД бесплатна, но стоит посмотреть, есть ли для нее все необходимые драйверы, инструменты администратора и разработчика, и главное, сколько они стоят!
И рос он не по годам, а по часам
С ограничением размера базы данных, прямо скажем, загвоздка. Сейчас часто нужно хранить в базах данных фотографии и видеоматериалы, а для данных такого рода 4 Гбайт недостаточно. Поэтому, если в вашем проекте предусмотрено хранение мультимедии, нужна СУБД без ограничений на размер базы данных.
Вход бесплатно, выход — нет
Все новые «коммерческие бесплатные» базы данных рассчитаны на то, чтобы через «попробовать» молодые разработчики и целые компании становились адептами этих СУБД или просто клиентами, покупая и используя в своей работе их базы данных.
Немаловажен и другой вопрос — как долго будут поддерживаться бесплатные версии СУБД? Например, компания Borland, выпустив в 2000 году InterBase 6 Open Edition, которую стали использовать миллионы разработчиков, выпустила только два небольших апдейта, после чего вернулась к коммерческой модели, прекратив поддержку Open Edition. И если бы не появление Firebird, то выбравшие Inter-Base 6 Open Source разработчики должны были бы либо купить лицензии новых версий InterBase, либо переходить на другие СУБД.
Обратите внимание, что многие «бесплатные» СУБД не открывают своих кодов, поэтому ситуация очень напоминает мышеловку: бегите сюда, мыши, кушайте сыр, мышеловка скоро захлопнется!
День открытых данных 2021. Онлайн
1-6 марта приглашаем на мероприятия, приуроченные к Международному Дню открытых данных 2021.
Это крупнейшее ежегодное международное событие, которое помогает продвигать концепцию открытых данных среди органов государственной власти, бизнес-корпораций, некоммерческих организаций и гражданского общества. Организатором Дня открытых данных в России выступает АНО «Информационная культура».
Рассказываем, какие мероприятия мы приготовили для участников в этом году.
Накануне Дня открытых данных, с 1 по 5 марта, проведем серию практических онлайн мастер-классов по работе с открытыми данными.
О языке SQL
SQL — это язык программирования для разработки баз данных. Можно сказать, что это основа всего. Когда только компьютеры появились в продаже, некоторые организации начали переводить базу клиентов в электронный вид. И, естественно, программ таких не было, чтобы создавать базы данных.
Тогда на помощь приходил язык программирования SQL. Вообще, он разрабатывался еще в 1986 году, но массово его начали применять только с 2008 года. Создавать и работать с базами данных на чистом языке SQL довольно-таки неудобно. Весь этот процесс происходит через командную строку, выводится база там же.
Для упрощения создания баз данных появились программы, которые имеют графический интерфейс и практически сами создают запросы на SQL языке. То есть пользователь ничего руками не пишет, лишь создает при помощи функции Drag and drop. Но хочется отметить, что изучение этого языка просто необходимо при разработке больших баз данных. Вы должны понимать, как все это работает, как делаются запросы и прочее.

Типы баз данных
Есть много разных типов баз данных. Лучшая база данных для конкретной организации зависит от того, как организация намеревается использовать данные.
- Реляционные базы данных. Реляционные базы данных стали доминирующими в 1980-х годах. Элементы в реляционной базе данных организованы как набор таблиц со столбцами и строками. Технология реляционных баз данных обеспечивает наиболее эффективный и гибкий способ доступа к структурированной информации.
- Объектно-ориентированные базы данных. Информация в объектно-ориентированной базе данных представлена в виде объектов, как в объектно-ориентированном программировании.
- Распределенные базы данных. Распределенная база данных состоит из двух или более файлов, расположенных на разных сайтах. База данных может храниться на нескольких компьютерах, находиться в одном физическом месте или разбросана по разным сетям.
- Хранилища данных. Централизованное хранилище данных, хранилище данных — это тип базы данных, специально разработанный для быстрого запроса и анализа.
- Базы данных NoSQL. NoSQL, или нереляционная база данных, позволяет хранить и обрабатывать неструктурированные и полуструктурированные данные (в отличие от реляционной базы данных, которая определяет, как должны быть составлены все данные, вставленные в базу данных). Базы данных NoSQL становились популярными по мере того, как веб-приложения становились все более распространенными и сложными.
- Графовые базы данных. База данных графов хранит данные в терминах сущностей и отношений между сущностями.
- Базы данных OLTP. База данных OLTP — это быстрая аналитическая база данных, предназначенная для большого количества транзакций, выполняемых несколькими пользователями.
Это лишь некоторые из нескольких десятков типов баз данных, используемых сегодня. Другие, менее распространенные базы данных предназначены для очень конкретных научных, финансовых или других функций. Помимо различных типов баз данных, изменения в подходах к разработке технологий и значительные достижения, такие как облачные технологии и автоматизация, продвигают базы данных в совершенно новых направлениях. Некоторые из последних баз данных включают:
- Базы данных с открытым исходным кодом (OpenSource). Система баз данных с открытым исходным кодом — это система с открытым исходным кодом; такие базы данных могут быть базами данных SQL или NoSQL.
- Облачные базы данных (Cloud Database). Облачная база данных — это набор структурированных или неструктурированных данных, который хранится на частной, общедоступной или гибридной платформе облачных вычислений. Существует два типа моделей облачных баз данных: традиционные и база данных как услуга (DBaaS). В случае DBaaS административные задачи и обслуживание выполняются поставщиком услуг.
- Многомодельная база данных. Мультимодельные базы данных объединяют различные типы моделей баз данных в единую интегрированную серверную часть. Это означает, что они могут поддерживать различные типы данных.
- База данных Документов / JSON. Базы данных документов, разработанные для хранения, извлечения и управления документально-ориентированной информацией, представляют собой современный способ хранения данных в формате JSON, а не в строках и столбцах.
- Автономные базы данных. Новейший и самый революционный тип базы данных, автономные базы данных (также известные как автономные базы данных) являются облачными и используют машинное обучение для автоматизации настройки базы данных, обеспечения безопасности, резервного копирования, обновления и других рутинных задач управления, традиционно выполняемых администраторами баз данных.
Аудит действий
- default log — встроенное логирование;
- extensions: pgaudit — если вам не хватает дефолтного логирования, можно воспользоваться отдельными настройками, которые решают часть задач.
Дополнение к докладу в видео:*
Как это повлияет на производительность СУБД?
postgresql.conf
| log_destination = ‘stderr’ logging_collector = on log_truncate_on_rotation = on log_rotation_age = 1d log_rotation_size = 10MB log_min_messages = debug5 log_min_error_statement = debug5 log_min_duration_statement = 0 debug_print_parse = on |
debug_print_rewritten = on debug_print_plan = on debug_pretty_print = on log_checkpoints = on log_connections = on log_disconnections = on log_duration = on log_hostname = on log_lock_waits = on log_replication_commands = on log_temp_files = 0 log_timezone = ‘Europe/Moscow’ |
Результаты тестирования:
| Без логирования | С логированием | |
| Итоговое время наполнения БД | 43,74 сек | 53,23 сек |
| ОЗУ | 24% | 40% |
| CPU | 72% | 91% |
| Тест 1 (50 коннектов) | ||
| Кол-во транзакций за 10 мин | 74169 | 32445 |
| Транзакций/сек | 123 | 54 |
| Средняя задержка | 405 мс | 925 мс |
| Тест 2 (150 коннектов при 100 возможных) | ||
| Кол-во транзакций за 10 мин | 81727 | 31429 |
| Транзакций/сек | 136 | 52 |
| Средняя задержка | 550 мс | 1432 мс |
| Про размеры | ||
| Размер БД | 2251 МБ | 2262 МБ |
| Размер логов БД | 0 Мб | 4587 Мб |
- Скорость сильно не меняется: без логирования — 43,74 сек, с логированием — 53,23 сек.
- Производительность по ОЗУ и CPU будет проседать, так как нужно сформировать файл с аудитом. Это также заметно на продуктиве.
- данных много;
- аудит нужен не только через syslog в SIEM, но и в файлы: вдруг с syslog что-то произойдет, должен быть близко к базе файл, в котором сохранятся данные;
- для аудита нужна отдельная полка, чтобы не просесть по I/O дисков, так как он занимает много места;
- бывает, что сотрудникам ИБ нужны везде ГОСТы, они требуют гостовую идентификацию.
Индексы и индексация таблиц
Представьте себе, что ваш приятель загадал число между 1 и 1000 и просит вас угадать его за минимальное число попыток, сообщая лишь о том, в большую или меньшую сторону вы ошиблись. Как вы поступите? Очевидно, предложите при первой попытке версию 500 (то есть начнете с середины). Если он ответит: «меньше», — предложите 250. Если «больше» — 750. Так, разбивая интервалы пополам, вы уложитесь в 10 попыток (ведь 210 > 103). Если бы приятель загадал число в пределах миллиарда, то количество попыток уложилось бы в 30 (230 > 109).
Угадывая число, вы проводили поиск примерно так, как ведут его системы баз данных, использующие индексы. Понятное дело, их работа гораздо сложнее, но главная идея именно в этом — за небольшое число попыток найти нужное значение из миллиардов возможных. Поля, по которым вам часто придется делать в базе поиск, фильтрацию или связывание таблиц между собой, есть смысл проиндексировать, то есть создать специальный связанный с таблицей объект, содержащий информацию, необходимую для вышеописанного быстрого поиска.
Как это делается практически? Поясню на примерах. Допустим, вас часто просят отобрать информацию о товарах российского производства. Чтобы по колонке COUNTRY_ID таблицы GOODS фильтрация производилась быстрее, создадим по ней индекс с именем IDX_GOODS_COUNTRY:
Если в будущем вы передумаете использовать созданный индекс, то без труда его сможете удалить:
Расширение mssql для Visual Studio Code
Расширение mssql для Visual Studio Code – это официальное расширение от компании Microsoft, которое предназначено для работы с SQL Server в Visual Studio Code.

Расширение mssql поддерживает подключения к SQL Server и продвинутые возможности для создания, редактирования и выполнения SQL запросов в Visual Studio Code.
Основные особенности
Инструмент бесплатный
Интегрирован в Visual Studio Code
Кроссплатформенность (поддержка Windows, Linux, macOS)
Ориентация на разработку T-SQL кода
Продвинутый SQL редактор (технология IntelliSense, фрагменты SQL кода)
Встроенная возможность выгрузки данных в формат Excel, JSON, CSV
Недостатки
Отсутствует функционал для администрирования баз данных и SQL сервера
Отсутствует конструктор таблиц
Нет функционала для работы со свойствами объектов
Отсутствует возможность управления безопасностью
Отсутствует возможность импорта и экспорта DACPAC
Инструмент нельзя использовать без Visual Studio Code
Мне нравится3Не нравится
PhpMyAdmin
Access, конечно, программа хорошая, но если нужна база данных для сайта, она не справится. Тогда на помощь приходит PhpMyAdmin. Это очень полезная программа для создания баз данных. Установка на компьютер занимает некоторое время, да и при инсталляции легко что-то сделать не так, и не будет работать. Поэтому при установке этой программы для создания баз данных нужно четко следовать инструкции. Но плюсом еще PhpMyAdmin является то, что к ней можно получить доступ и через интернет в виде сайта! Например, у вас есть сайт, который работает на WordPress. У него будет база данных. И если у вас сайт на каком-нибудь хорошем хостинге, то, вероятнее всего, работа с базами данных будет осуществляться через PhpMyAdmin, и к нему можно будет получить доступ через панель управления хостинга.
Некоторые подробности проекта
Основной целью рассматриваемого проекта «Росатом» заявляет
замещение иностранных ИТ-продуктов решениями отечественного производства — в
соответствии с отдельным пунктом протокола заседания Совета по планированию
текущей и проектной деятельности госкорпорации от 11 сентября 2019 г.
Из тендерной документации следует, что в периметре
взаимодействия с системой находятся 242 организации атомной отрасли, включая
филиалы госкорпорации.
В продуктивной среде с системой взаимодействует одна база
данных, в тестовой — шесть. Общее количество пользователей по состоянию на 29
мая 2020 г. заявлено на уровне 1039 единиц. Из них со стороны предприятий —
997, казначейства «Росатома» — 34, службы поддержки пользователей и технических
записей — восемь. Основными банками взаимодействия для системы выступают ВТБ, Газпромбанк
и Сбербанк.
Максимальный размер баз данных заявлен на уровне 14 ТБ. Объем
исходящих платежей — не менее 5 тыс. операций в день.
Как перевести четверть клиентов на самообслуживание? Опыт банка «Открытие»
ИТ в банках

На данный момент система использует сервер приложений JBoss и
СУБД Oracle 11.2.0.2 Enterprise Edition. Два сервера отчетов системы функционируют
на базе Oracle Application Server Forms and Reports Services
11gпод
управлением операционной системы Microsoft Windows Server 2016. «СУБД Oracle
11.2.0.2 используется до момента перевода на импортонезависимую СУБД», —
резюмирует заказчик.
«SQL учебник» от SchoolSW3.com
- Длительность: неизвестно
- Сертификат: да
- Формат обучения: текстовый курс
Описание курса
Полноценный онлайн-учебник с тренировочными заданиями, в котором рассматриваются все аспекты работы с SQL. Благодаря ему вы сможете последовательно познакомиться со спецификой работы с СУБД, после чего сможете самостоятельно составлять простейшие запросы. Главным недостатком данного курса является отсутствие внятной навигации по материалу, из-за чего обучение становится значительно сложнее.
Плюсы:
- Большой объём образовательного материала;
- Предоставление сертификата.
Минусы:
Объектно-ориентированные субд
Появление объектно-ориентированных СУБД вызвано потребностями программистов на ОО-языках, которым были необходимы средства для хранения объектов, не помещавшихся в оперативной памяти компьютера. Также важна была задача сохранения состояния объектов между повторными запусками прикладной программы. Поэтому, большинство ООСУБД представляют собой библиотеку, процедуры управления данными которой включаются в прикладную программу. Примеры реализации ООСУБД как выделеного сервера базы данных крайне редки.
Сразу же необходимо заметить, что общепринятого определения «объектно-ориентированной модели данных» не существует. Сейчас можно говорить лишь о неком «объектном» подходе к логическому представлению данных и о различных объектно-ориентированных способах его реализации.
Структура
Структура объектной модели описываются с помощью трех ключевых понятий:
инкапсуляция — каждый объект обладает некоторым внутренним состоянием (хранит внутри себя запись данных), а также набором методов — процедур, с помощью которых (и только таким образом) можно получить доступ к данным, определяющим внутреннее состояние объекта, или изменить их. Таким образом, объекты можно рассматривать как самостоятельные сущности, отделенные от внешнего мира;
наследование — подразумевает возможность создавать из классов объектов новые классы объекты, которые наследуют структуру и методы своих предков, добавляя к ним черты, отражающие их собственную индивидуальность. Наследование может быть простым (один предок) и множественным (несколько предков);
полиморфизм — различные объекты могут по разному реагировать на одинаковые внешние события в зависимости от того, как реализованы их методы.
Целостность данных
Для поддержания целостности объектно-ориентированный подход предлагает использовать следующие средства:
автоматическое поддержание отношений наследования возможность объявить некоторые поля данных и методы объекта как «скрытые», не видимые для других объектов; такие поля и методы используются только методами самого объекта создание процедур контроля целостности внутри объекта
Средства манипулирования данными
К сожалению, в объектно-ориентированном программировании отсутствуют общие средства манипулирования данными, такие как реляционная алгебра или реляционное счисление. Работа с данными ведется с помощью одного из объектно-ориентированных языков программирования общего назначения, обычно это SmallTalk, C++ или Java.
В объектно-ориентированных базах данных, в отличие от реляционных, хранятся не записи, а объекты. ОО-подход представляет более совершенные средства для отображения реального мира, чем реляционная модель, естественное представление данных. В реляционной модели все отношения принадлежат одному уровню, именно это осложняет преобразование иерархических связей модели «сущность-связь» в реляционную модель. ОО-модель можно рассматривать послойно, на разных уровнях абстракции. Имеется возможность определения новых типов данных и операций с ними.
В то же время, ОО-модели присущ и ряд недостатков:
осутствуют мощные непроцедурные средства извлечения объектов из базы. Все запросы приходится писать на процедурных языках, проблема их оптимизации возлагается на программиста;
вместо чисто декларативных ограничений целостности (типа явного объявления первичных и внешних ключей реляционных таблиц с помощью ключевых слов PRIMARY KEY и REFERENCES) или полудекларативных триггеров для обеспечения внутренней целостности приходится писать процедурный код.
Очевидно, что оба эти недостатка связаны с отсутствием развитых средств манипулирования данными. Эта задача решается двумя способами — расширение ОО-языков в сторону управления данными (стандарт ODMG), либо добавление объектных свойств в реляционные СУБД (SQL-3, а также так называемые объектно-реляционных СУБД).
Какие задачи решаем?
Наша услуга сокращает эксплуатационные затраты, в которые среди прочего входят зарплаты администраторов БД (например, в Московском регионе зарплата Oracle DBA в месяц может доходить до 200 т.р.), а также снижает риски, связанные с инфраструктурой, на которой развернуты БД. Ее можно использовать для запуска новых или обновления существующих бизнес-приложений, таких как корпоративная система электронной почты, системы CRM и HRM, бухгалтерское, складское, финансовое и аналитическое ПО.
Она сводит к минимуму риск недоступности бизнес-приложений из-за ошибок в работе баз данных, снижает вероятность потери данных из-за несвоевременного резервного копирования, дает возможность обеспечить высокую доступность БД в условиях отсутствия или недостаточности собственных ресурсов/экспертизы. Кроме того, можно повысить отказоустойчивость критичных бизнес-систем за счет использования технологии кластеризации баз данных, получить достаточную производительность при нехватке вычислительных ресурсов и пропускной способности собственного оборудования или реализовать план аварийного восстановления (DRP). Сервис удобно также применять для резервного копирования и проверки консистентности резервных копий данных.
Для разных приложений у нас типовые конфигурации:
Распространенные варианты использования DBaaS — создание тестовых сред для функционального и нагрузочного тестирования, разовые проекты со сжатыми сроками, решение проблемы эпизодических «пиковых нагрузок», например, формирование аналитической или финансовой отчетности.
MongoDB
Самая популярная NoSQL система управления базами данных. Лучше всего подходит для динамических запросов и определения индексов. Гибкая структура, которую можно модифицировать и расширять. Поддерживает Linux, OSX и Windows, но размер БД ограничен 2,5 ГБ в 32-битных системах. Использует платформы хранения MMAPv1 и WiredTiger.
- Разработчик: MongoDB Inc. в 2007
- Написана на C++
Особенности
- Высокая производительность.
- Автоматическая фрагментация.
- Работа на нескольких серверах.
- Поддержка репликации Master-Slave.
- Данные хранятся в форме документов JSON.
- Возможность индексировать все поля в документе.
- Поддержка поиска по регулярным выражениям.
Взаимодействие интерфейса и данных
Во фреймворке большое внимание уделено взаимодействию записей (объектов) между собой. При изменении записи на форме она автоматически обновляется в списке
При изменении записи на форме она автоматически обновляется в списке.
Если же запись одновременно редактируется с разных компьютеров, то у пользователя появляется предупреждение.
В интерфейсе фреймворка также реализован механизм сортировки строк зависимых записей (если это предусмотрено моделью и модулем backend).
Приведенные примеры элементов интерфейса лишь малая часть из того, что заложено во фреймворке. Более детальное описание всех элементов и принципов работы интерфейса — тема для отдельных статей. Так же стоит повториться, что приводимые примеры интерфейсов не навязываются, а лишь предлагаются как основа и могут настраиваться по усмотрению разработчика.
«Интерактивный тренажер по SQL» от Stepik

- Длительность: 36 академических часов
- Сертификат: да
- Формат обучения: текстовый курс
Описание курса
Курс предназначен для изучения работы с SQL при выполнении практических заданий. Уроки разбиты на несколько шагов, каждый из которых рассматривает отдельный теоретический аспект взаимодействия с СУБД. С течением времени сложность материала будет возрастать из-за чего начать работу с программой может даже новичок.
Курс направлен на обучение пользователя созданию баз данных с последующим направлением запросов к ним с использованием SQL. Материал подойдет аналитикам, программистам и маркетологам. В результате вы сможете разрабатывать реляционные БД и работать с SQL-запросами.
Плюсы:
- Большое количество материала;
- Подробный разбор каждого аспекта;
- Наличие практических заданий.
Минусы:
Navicat for SQL Server – это графический инструмент для разработки и администрирования баз данных в Microsoft SQL Server.
С помощью данного инструмента можно создавать, редактировать и удалять любые объекты базы данных, разрабатывать и выполнять SQL запросы и инструкции, а также просматривать данные в таблицах, включая двоичные и шестнадцатеричные данные.
Основные особенности
Кроссплатформенность (поддержка Windows, Linux, macOS)
Продвинутый SQL редактор (автозавершение кода, фрагменты кода)
Дизайнер объектов
Возможность сравнения и синхронизации данных в базах данных
Встроенная возможность проектирования и моделирования данных
Визуализация данных с помощью диаграмм и графиков
Встроенный импорт и экспорт данных в формат Excel, XML, JSON, TXT, DBF, CSV
Темный режим темы
Недостатки
Инструмент платный
Мне нравитсяНе нравится
RAWGraphs
RAWGraphs
Сильные стороны бесплатной версии
- Диаграммы в RAWGraphs очень просто создавать, для работы с системой не нужно даже регистрировать учётную запись.
- Система поддерживает различные форматы входных данных — TSV, CSV, DSV, JSON и Excel-файлы(.xls, .xlsx).
- По сведениям RAWGraphs обработка данных производится исключительно средствами браузера. Платформа не занимается серверной обработкой или хранением данных. Никто из тех, кто не имеет отношения к данным, не сможет их просматривать, модифицировать или копировать.
- RAWGraphs — это система, поддающаяся расширению. Например, добавлять в неё новые диаграммы можно, обладая базовыми знаниями D3.js.
Слабые стороны бесплатной версии
- Диаграммы, создаваемые в RAWGraphs, иногда выглядят слишком простыми. У пользователей системы есть не особенно много механизмов для подстройки их под свои нужды.
- Визуализации данных не являются интерактивными.
6 принципов эффективной визуализации данных
Перевод
Ключевые принципы создания полезных и информативных графиков
Визуализация данных является важным этапом в процессе постижения науки о данных. Здесь вы представляете свои результаты и сообщаете о них в графическом формате, который является интуитивно понятным и лёгким для понимания.
Визуализация данных требует большой работы, большой труд по очистке и анализу уходит на перегонку и превращение грязных данных в красивые графики и диаграммы. Но даже с подготовленными данными всё равно приходится придерживаться определённых принципов или методологий, чтобы создать полезную, информативную графику.
Тем не менее при написании этой статьи я черпал вдохновение в книге Эдварда Тафта «Beautiful Evidence», которая содержит шесть принципов, посвящённых тому, как сделать графики данных полезными. Именно эти принципы отделяют полезные графики от бесполезных.
Эта статья также в значительной степени вдохновлена книгой Роджера Д. Пенга «Exploratory Data Analysis in R» Она доступна бесплатно на Bookdown, и вы можете прочитать её, чтобы узнать больше о EDA.
Давайте ближе познакомимся с этими принципами.Пример визуализации данных на Our World in Data
Запросы
Это основной рабочий инструмент для каждой системы управления базами данных. С помощью запросов выполняются многочисленные функции. Наиболее распространенной является возможность извлечения конкретных сведений из таблиц. Запросы дают возможность предоставить нужные данные в отдельной структурированной форме, чтобы не просматривать все, включая ненужные сведения. Это своеобразный фильтр для каждой базы данных.
Запросы работают по принципу выборки и изменения. В последних предусматривается возможность редактирования предоставленной информации. При внесении изменений нужно понимать, что они будут сохранены в основной базе данных. Запрос на выборку дает возможность обычного просмотра или копирования информации.
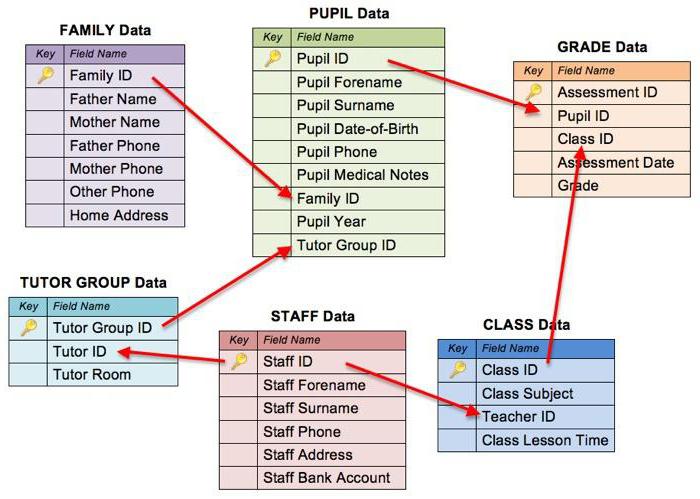
Microsoft Access
Система управления базами данных от Microsoft, которая сочетает в себе реляционное ядро БД Microsoft Jet с графическим интерфейсом пользователя и инструментами разработки ПО.
Идеально подходит для начала работы с данными, но производительность не рассчитана на большие проекты. В MS Access можно использовать C, C#, C++, Java, VBA и Visual Rudimental.NET. Access хранит все таблицы БД, запросы, формы, отчёты, макросы и модули в базе данных Access Jet в виде одного файла.
Разработчик: Microsoft Corporation
Особенности
- Можно использовать VBA для создания многофункциональных решений с расширенными возможностями управления данными и пользовательским контролем.
- Импорт и экспорт в форматы Excel, Outlook, ASCII, dBase, Paradox, FoxPro, SQL Server и Oracle.
- Формат базы данных Jet.