Что такое grep и с чем его едят
Содержание:
Команда grep без опций и аргумента.
Если не указано имени файла, то команда обрабатывает стандартный ввод, например строки, набранные на клавиатуре:
$ grep коту меня есть кошка,(Enter)вернее это кот,(Enter)вернее это кот,который умеет(Enter)который умеетловить мышей.(Enter)(Ctrl+c)
В скобках показано, когда я нажимал клавишу Enter, чтобы перейти на новую строку. Одновременно, при нажатии Enter, программа выводила строки, содержащие ОБРАЗЕЦ (кот), отсюда и удвоение этих строк. Видно, что команда реагировала просто на сочетание букв, а не на слово «кот», иначе строка со словом «который» не попала бы в вывод.
Тут мы подошли к очень важному определению строки. Строкой команда grep (как и все остальные команды Юникс) считает все символы, находящиеся между двумя символами новой строки
Эти невидимые на экране символы возникают в тексте каждый раз, когда пользователь нажимает клавишу Enter. В Юниксовидных системах символ новой строки обозначается обратным слэшем с буквой n (n). Таким образом, строка может быть любого размера, начиная с одного символа и до многомегабайтного текста. И команда grep честно выведет эту строку, при условии, что она содержит ОБРАЗЕЦ.
Difference between grep, egrep fgrep, pgrep, zgrep
Various grep switches were historically included in different binaries. On modern Linux systems, you will find these switches available in the base grep command, but it’s common to see distributions support the other commands as well.
From the man page for grep:
egrep is the equivalent of grep -E
This switch will interpret a pattern as an . There’s a ton of different things you can do with this, but here’s an example of what it looks like to use a regular expression with grep.
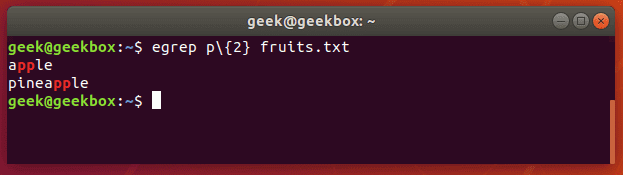
Let’s search a text document for strings that contain two consecutive ‘p’ letters:
$ egrep p\{2} fruits.txt
or
$ grep -E p\{2} fruits.txt
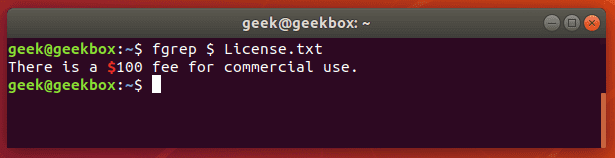
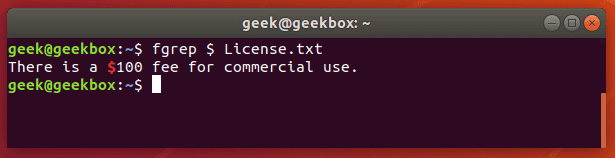
fgrep is the equivalent of grep -F
This switch will interpret a pattern as a list of fixed strings, and try to match any of them. It’s useful when you need to search for regular expression characters. This means you don’t have to escape special characters like you would with regular grep.
pgrep is a command to search for the name of a running process on your system and return its respective process IDs. For example, you could use it to find the process ID of the SSH daemon:
$ pgrep sshd
This is similar in function to just piping the output of the ‘ps’ command to grep.
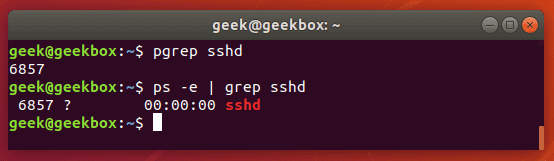
You could use this information to kill a running process or troubleshoot issues with the services running on your system.
You can use zgrep to search compressed files for a pattern. It allows you to search the files inside of a compressed archive without having to first decompress that archive, basically saving you an extra step or two.
$ zgrep apple fruits.txt.gz
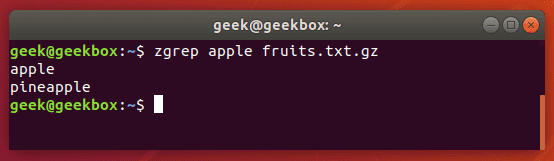
zgrep also works on tar files, but only seems to go as far as telling you whether or not it was able to find a match.
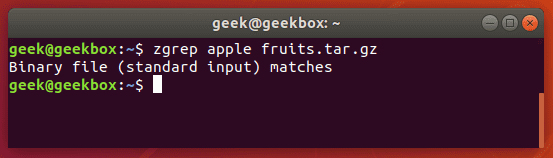
We mention this because files compressed with gzip are very commonly tar archives.
БАЗОВЫЕ РЕГУЛЯРНЫЕ ВЫРАЖЕНИЯ
Все регулярные выражения состоят из двух типов символов: стандартных текстовых символов, называемых литералами, и специальных символов, называемых метасимволами. В предыдущих примерах поиск осуществлялся по литералам (точное совпадение по буквам), но дальше будет куда интересней. Добро пожаловать в мир регулярных выражений !
Знак каретки и доллара имеют в регулярном выражении особый смысл. Их называют «якорями» (anchor). Якоря – это специальные символы, которые указывают местонахождение в строке необходимого совпадения. Когда поиск доходит до якоря, он проверяет, есть ли соответствие, и если есть – продолжает идти по шаблону, не прибавляя ничего к результату.
GIST | Якорь каретка используют чтобы указать, что регулярное выражение необходимо проверить именно с начала строки:
--color=always '^J'
George Washington, 1789-1797 John Adams, 1797-1801 Thomas Jefferson, 1801-1809
John Adams, 1797-1801
GIST | Аналогично якорь доллар стоит использовать в конце шаблона, чтобы указать, что совпадение действительно только если искомая строка символов находится в конце текстовой строки и никак иначе:
--color=always '9$'
George Washington, 1789-1797 John Adams, 1797-1801 Thomas Jefferson, 1801-1809
Thomas Jefferson, 1801-1809
GIST | Любой символ. Символ точка используется в регулярных выражениях для того, чтобы обозначить, что в указанном месте может находиться абсолютно любой символ:
--color=always '0.$'
George Washington, 1789-1797 John Adams, 1797-1801 Thomas Jefferson, 1801-1809
John Adams, 1797-1801 Thomas Jefferson, 1801-1809
GIST | Экранирование. Если нужно найти именно символ точка, тогда экранирование в помощь. Знак экранирования (как правило это обратный слеш), предшествующий символу вроде точки, превращает метасимвол в литерал:
--color=always '\.'
George Washington. 1789-1797 John Adams, 1797-1801 Thomas Jefferson, 1801-1809
George Washington. 1789-1797
GIST | Классы символов. В регулярных выражениях можно использовать диапазоны и классы символов. Для этого при составлении шаблона используются квадратные скобки. Поместив группу символов (включая символы, которые в противном случае были бы истолкованы как метасимволы) в квадратные скобки, можно указать, что в данной позиции может находиться любой из взятых в скобки символов:
--color=always '0'
George Washington, 1789-1797 John Adams, 1797-1801 Thomas Jefferson, 1801-1809
John Adams, 1797-1801 Thomas Jefferson, 1801-1809
GIST | Диапазон. Это два символа, разделенные дефисом, например, 0-9 (десятичные цифры) или 0-9a-fA-F (шестнадцатеричные цифры):
--color=always ''
George Washington, ??? John Adams, 1797-1801 Thomas Jefferson, 1801-1809
John Adams, 1797-1801 Thomas Jefferson, 1801-1809
GIST | Отрицание. Если первым символом выражения в квадратных скобках является каретка, то остальные символы принимаются как набор символов, которые не должны присутствовать в заданной позиции регулярного выражения:
--color=always '$'
George Washington, 1789-1797 John Adams, 1797-1801 Thomas Jefferson, 1801-1809
John Adams, 1797-1801 Thomas Jefferson, 1801-1809
GIST | Классы символов POSIX. Существует некий набор уже заранее заготовленных классов символов, которые Вы можете использовать в регулярных выражениях. Их там с десяток, достаточно быстро просмотреть мануал чтобы понять назначение каждого. Например отфильтруем только шестнадцатеричные цифры:
--color=always '^]*$'
4.2 42 42abc
42 42abc
GIST | Повторение (0 или больше раз). Одним из наиболее часто используемых метасимволов является символ звёздочка, что означает «повторить предыдущий символ или выражение ноль или больше раз»:
--color=always '^*$'
George Washington, ??? John Adams, 1797-1801 Thomas Jefferson, 1801-1809
George Washington, ???
Различают базовые регулярные выражения BRE (basic regular expressions) и расширенные ERE (extended regular expressions). В BRE распознаются следующие метасимволы и все другие символы расцениваются как литералы. В ERE добавлены ещё такие метасимволы и связанные с ними функции. Ну а чтобы всех окончательно запутать в «grep» придумали такую штуку – символы в BRE обрабатываются как метасимволы, если они экранированы обратным слешем, в то время как в ERE постановка перед любыми метасимволами обратного слеша приводит к тому, что они трактуются как литералы.
ОПЦИИ
Начнём с того, что «grep» умеет не только фильтровать стандартный ввод , но и осуществлять поиск по файлам. По умолчанию «grep» будет искать только в файлах, находящихся в текущем каталоге, однако при помощи очень полезной опции можно сказать команде «grep» искать рекурсивно начиная с заданной директории.
GIST | По умолчанию команда «grep» чувствительна к регистру. Следующий пример показывает как можно искать и при этом не учитывать регистр, например «Adams» и «adams» одно и то же:
--ignore-case 'adams'
George Washington, 1789-1797 John Adams, 1797-1801 Thomas Jefferson, 1801-1809
John Adams, 1797-1801
GIST | Поиск наоборот (иногда говорят инвертный поиск), то есть будут выведены все строки, кроме имеющих вхождение указанного шаблона:
--invert-match 'Adams'
George Washington, 1789-1797 John Adams, 1797-1801 Thomas Jefferson, 1801-1809
George Washington, 1789-1797 Thomas Jefferson, 1801-1809
GIST | Опции конечно же можно и нужно комбинировать друг с другом. Например поиск наоборот с выводом порядковых номеров строк с вхождениями:
--line-number --invert-match 'Adams'
George Washington, 1789-1797 John Adams, 1797-1801 Thomas Jefferson, 1801-1809
1:George Washington, 1789-1797 3:Thomas Jefferson, 1801-1809
GIST | Раскраска. Иногда удобно, когда искомое нами слово подсвечивается цветом. Все это уже есть в «grep», остается только включить:
--line-number --color=always 'Adams'
George Washington, 1789-1797 John Adams, 1797-1801 Thomas Jefferson, 1801-1809
2:John Adams, 1797-1801
GIST | Мы хотим выбрать все ошибки из лог файла, но знаем что в следующей сточке после ошибки может содержаться полезная информация, тогда удобно вывести несколько строк из контекста. По умолчанию «grep» выводит лишь строку, в которой было найдено совпадение, но есть несколько опций, позволяющих заставить «grep» выводить больше. Для вывода нескольких строк (в нашем случае двух) после вхождения:
--color=always -A2 'Adams'
George Washington, 1789-1797 John Adams, 1797-1801 Thomas Jefferson, 1801-1809 James Madison, 1809-1817 James Monroe, 1817-1825
John Adams, 1797-1801 Thomas Jefferson, 1801-1809 James Madison, 1809-1817
GIST | Аналогично для дополнительного вывода нескольких строк перед вхождением:
--color=always -B2 'James'
George Washington, 1789-1797 John Adams, 1797-1801 Thomas Jefferson, 1801-1809 James Madison, 1809-1817 James Monroe, 1817-1825
John Adams, 1797-1801 Thomas Jefferson, 1801-1809 James Madison, 1809-1817 James Monroe, 1817-1825
GIST | Однако чаще всего требуется выводить симметричный контекст, для этого есть ещё более сокращённая запись. Выведем по две строки как сверху так и снизу от вхождения:
--color=always -C2 'James'
George Washington, 1789-1797 John Adams, 1797-1801 Thomas Jefferson, 1801-1809 James Madison, 1809-1817 James Monroe, 1817-1825 John Quincy Adams, 1825-1829 Andrew Jackson, 1829-1837 Martin Van Buren, 1837-1841
John Adams, 1797-1801 Thomas Jefferson, 1801-1809 James Madison, 1809-1817 James Monroe, 1817-1825 John Quincy Adams, 1825-1829 Andrew Jackson, 1829-1837
GIST | Когда Вы ищете , то по умолчанию «grep» будет выводить также, , и тому подобные комбинации. Найдём только те строки, которые выключают именно всё слово целиком:
--word-regexp --color=always 'John'
John Fitzgerald Kennedy, 1961-1963 Lyndon Baines Johnson, 1963-1969
John Fitzgerald Kennedy, 1961-1963
GIST | Ну и напоследок если Вы просто хотите знать количество строк с совпадениями одним единственным числом, но при этом не выводить больше ничего:
--count --color=always 'John'
John Fitzgerald Kennedy, 1961-1963 Lyndon Baines Johnson, 1963-1969 Richard Milhous Nixon, 1969-1974
2
Стоит отметить, что у большинства опций есть двойник, например можно привести к более короткому виду и т.д.
Команда grep и регулярные выражения
Регулярные выражения (Regular Expressions) это система синтаксического разбора текстовых фрагментов по формализованному шаблону, основанная на системе записи ОБРАЗЦОВ для поиска. Проще говоря, регулярное выражение — тот же, уже привычный нам ОБРАЗЕЦ для поиска, только составленный по определенным правилам. Как математические формулы составляются при помощи набора операторов (плюс, минус, степень, корень и прочее), так и регулярные выражения конструируются при помощи различных операторов (?, *, +, {n} и прочие).
Тема регулярных выражений настолько обширна, что требует для своего освещения отдельной статьи; в данной статье мы не будем ее подробно разбирать. Скажу лишь, что существует несколько версий синтаксиса регулярных выражений: Базовый (basic) BRE, Расширенный (extended) ERE и регулярные выражения языка Perl.
—basic-regexp
Рассматривает ОБРАЗЕЦ как базовое регулярное выражение. Эта опция используется по умолчанию.
—extended-regexp
Рассматривает ОБРАЗЕЦ как расширенное регулярное выражение.
—perl-regexp
Рассматривает ОБРАЗЕЦ как регулярное выражение языка Perl.
Опция -F
—fixed-strings
Рассматривает ОБРАЗЕЦ как список «фиксированных выражений» (fixed strings — термин из области регулярных выражений), разделенных символами новой строки. Будет искать соответствия любому из них.
Кроме того, существуют две альтернативные команды EGREP и FGREP. Обе они соответствуют опциям -E и -F соответственно.
Опции —help и —version (-V) общеизвестны, и я не буду на них останавливаться.
Синтаксис
Рассмотрим синтаксис.
grep шаблон
Или так:
Команда | grep шаблон
Здесь под параметрами понимаются аргументы, с помощью которых настраивается поиск и вывод на экран. Например нужно найти слово «линукс», и не учитывать регистр при поиске. Тогда нужно использовать опцию «-i».
Шаблон — это выражение или строка.
Имя файла — где искать.
Основные параметры:
—help. Вывести справочную информацию.
-i. Не учитывать регистр при поиске.
-V. Узнать текущую версию.
-v. Инвертированный поиск.
-s. Не выводить на экран сообщения об ошибкам. Например сообщение о несуществующих файлах.
-r. Поиск в каталогах, подкаталогах или рекурсивный grep.
-w. Искать как слово с пробелами.
-с. Опция считает количество вхождений (счетчик).
-e. Регулярные выражения.
Примеры
Найдем все файлы в текущей директории где встречается слово «linux».
grep linux ./*

Здесь:
- linux — слово которое нужно искать;
- точка — текущая директория;
- звездочка — искать во всех файлах.
Чтобы начать поиск без учета регистра необходимо добавить аргумент «-i». В нашем примере получится так:
grep -i linux ./*

Поиск в конкретном документе. Для примера найдем в документе «test» слово «хороший». Для этого с помощью утилиты «cd» зайдем в текущую директорию, где лежит файл «test». В моем случаи он находится в домашнем каталоге, я ввожу просто «cd».
grep хороший test

Здесь:
- хороший — слово которое нужно найти;
- test — файл, где искать.
Рекурсивный поиск. Чтобы найти определенный текст в определенной директории, используют рекурсивный поиск. Для этого необходимо использовать параметр «-r». Найдем слово «vseprolinux» в домашнем каталоге root и его подкаталогах.
grep -r vseprolinux /etc/root

Найдем три слова сразу в одной строке «все про Линукс». Для этого будем использовать вертикальную черту и введет «grep» три раза.
grep «все» test | grep «про» | grep «Линукс»

Команда grep может сообщить сколько раз встречается слово. Нам поможет опция -с. Посчитаем сколько раз встречается слово «site» в документе «file».
grep -c site file

Как видно на скриншоте выше, в файле «file» три раза встречается слово «site». Однако команда также считает выражение «mysite» за «site». Как сделать чтобы mysite не попал под счетчик? Добавим опцию «-w.»
grep -cw site file

Регулярные выражения.
Регулярные выражение в утилите «grep» — это мощная функция, которая расширяет возможности поиска. Чтобы активировать эту функцию или режим, используется аргумент «-e».
Символы в выражениях:
- $ — конец строки;
- ^ — начало строки;
- [] — указывается диапазон значений или конкретные через запятую.
Найдем цифры 1-5 в документе «file».
grep file
В скобках написано диапазон значений от одного до пяти, также можно написать конкретные значения через запятую, так:
Альтернативы
Первой функцией расширенных регулярных выражений, которую мы обсудим, называется альтернативы, которая является возможностью, позволяющей искать соответствующие вхождения из набора выражений. Как выражения в квадратных скобках позволяют единичному символу соответствовать из указанного набора символов, альтернативы позволяют соответствия из набора строк или других регулярных выражений.
Для демонстрации мы будем использовать grep в паре с echo. Для начала давайте попробуем проверить простое старое соответствие строки:
echo "AAA" | grep AAA AAA echo "BBB" | grep AAA

Весьма простой пример, в котором мы передавали по трубе вывод от echo в grep и смотрели на результат. Когда случалось совпадение, то оно печаталось в стандартный вывод; когда совпадений не встречается, то не выводится никакой результат.
Сейчас мы добавим альтернативы, выраженные с помощью метасимвола вертикальная черта:
echo "AAA" | grep -E 'AAA|BBB' AAA echo "BBB" | grep -E 'AAA|BBB' BBB echo "CCC" | grep -E 'AAA|BBB'
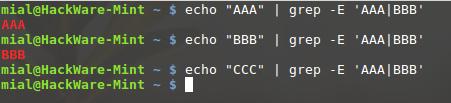
Здесь мы видим регулярное выражение ‘AAA|BBB’, которое означает «соответствие или строке AAA или строке BBB»
Обратите внимание, что поскольку это расширенная функция, мы добавили к grep опцию -E (хотя вместо этого можно было использовать просто программу egrep, но это не рекомендуется – команда egrep теперь является устаревшей). Ещё мы заключили регулярное выражение в кавычки, для предотвращения интерпретации Башем вертикальной черты в качестве оператора pipe (труба)
Альтернативы не ограничены двумя вариантами выбора:
echo "AAA" | grep -E 'AAA|BBB|CCC' AAA
Для комбинирования альтернатив с другими элементами регулярных выражений, мы можем использовать () для разделения альтернатив:
grep -Eh '^(bz|gz|zip)' dirlist*.txt
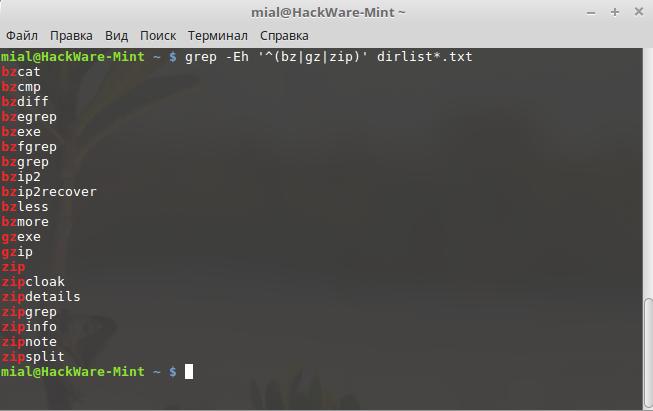
Это выражение будет соответствовать именам файлов в нашем списке, которые начинаются либо с «bz», «gz» или «zip». Если мы уберём скобки из нашего регулярного выражения:
grep -Eh '^bz|gz|zip' dirlist*.txt

то его значение измениться, теперь оно будет соответствовать любому имени файла, начинающемуся с «bz» или содержащему «gz» или содержащему «zip».
Поиск рекурсивно
Вы можете использовать ключ -r с grep для рекурсивного поиска по всем файлам в каталоге и его подкаталогах по указанному шаблону.
$ grep -r pattern /directory/to/search
Если вы не укажете каталог, grep будет просто искать ваш текущий рабочий каталог. На приведенном ниже снимке экрана grep обнаружил два файла, соответствующих нашему шаблону, и возвращает их имена файлов и каталог, в котором они находятся.

Найти вкладку
Как мы упоминали ранее в объяснении того, как искать строку, вы можете заключить текст в кавычки, если он содержит пробелы. Тот же метод будет работать для вкладок, но мы сейчас объясним, как поместить вкладку в вашу команду grep.
Поставьте пробел или несколько пробелов внутри кавычек, чтобы grep искал этот символ.
$ grep " " sample.txt
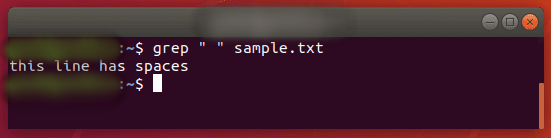
Существует несколько различных способов поиска вкладки с помощью grep, но большинство методов являются экспериментальными или могут быть несовместимыми в разных дистрибутивах.
Самый простой способ — просто найти сам символ табуляции, который вы можете создать, нажав Ctrl + V на клавиатуре, после чего нажмите Tab.
Обычно нажатие клавиши tab в окне терминала говорит терминалу, что вы хотите автоматически завершить команду, но предварительное нажатие комбинации ctrl + v приведет к тому, что символ табуляции будет записан так, как вы обычно ожидаете в текстовом редакторе. ,
$ grep " " sample.txt
Опции — расширения GNU
Опции
-A —after-context=ЧИСЛО_СТРОК
-B —before-context=ЧИСЛО_СТРОК
-C —context=ЧИСЛО_СТРОК
С этими тремя опциями мы уже познакомились в четвертой Хитрости, они позволяют посмотреть соседние строки. -A: количество строк после совпадения с ОБРАЗЦОМ,
-B: количество строк перед совпадением, и -C: количество строк вокруг совпадения.
Опция —colour
Выделяет найденные строки цветом. Значения КОГДА могут быть: never (никогда), always (всегда), или auto. Пример:
grep -o 'английскими' --color grep-ru.txt английскими
Опция -D ДЕЙСТВИЕ
—devices=ДЕЙСТВИЕ
Если исследуемый файл является файлом устройства, FIFO (именованным каналом) или сокетом, то следует применять эту опцию. ДЕЙСТВИЙ всего два: read (прочесть), и skip (пропустить). Если вы указываете ДЕЙСТВИЕ read (используется по умолчанию), то программа попытается прочесть специальный файл, как если бы он был обычным файлом; если указываете ДЕЙСТВИЕ skip, то файлы устройств, FIFO и сокеты будут молча проигнорированы.
Опция -d ДЕЙСТВИЕ
—directories=ДЕЙСТВИЕ
Если входной файл является директорией, то используйте эту опцию. ДЕЙСТВИЕ read (прочесть) попытается прочесть директорию как обычный файл (некоторые ОС и файловые системы запрещают это; тогда появятся соответствующие сообщения, либо директории молча пропустят). Если ДЕЙСТВИЕ skip (пропустить), то директории будут молча проигнорированы. Если ДЕЙСТВИЕ recurse (рекурсивно), то grep будет просматривать все файлы и субдиректории внутри заданного каталога рекурсивно. Это эквивалент опции -r, с которой мы уже познакомились.
—with-filename
Выдает имя файла для каждого совпадения с ОБРАЗЦОМ. Мы успешно делали это без всяких опций в Хитрости второй.
—no-filename
Подавляет вывод имен файлов, когда задано несколько файлов для исследования.
Опция -I
Обрабатывает бинарные файлы как не содержащие совпадений с ОБРАЗЦОМ; эквивалент опции —binary-files=without-match.
Опция —include=ОБРАЗЕЦ_имени_файла
При рекурсивном исследовании директорий обследовать только файлы, содержащие в своем имени ОБРАЗЕЦ_имени_файла.
Опция -m ЧИСЛО_СТРОК
—max-count=ЧИСЛО_СТРОК
Прекратить обработку файла после того, как количество совпадений с ОБРАЗЦОМ достигнет ЧИСЛА_СТРОК:
grep -m 2 'kot' kot.txt kot kotoroe
Опция -y
Синоним опции -i (не различать верхний и нижний регистр символов).
Опции -U и -u применяются только под MS-DOS и MS-Windows, тут нечего о них говорить.
Опция —mmap
Использует системный вызов mmap вместо системного вызова read. Может дать лучшую производительность, а может привести к ошибкам. Это для продвинутых пользователей.
Опция -Z
—null
Если в выводе программы имена файлов (например при опции -l), то опция -Z после каждого имени файла выводит нулевой байт вместо символа новой строки (как обычно происходит). Это делает вывод однозначным, даже если имена файлов содержат символы новой строки. Эта опция может быть использована совместно с такими командами как: find -print0, perl -0, sort -z, xargs -0 для обработки файловых имен, составленных необычно, даже содержащих символы новой строки.
(Хотел бы я знать, как можно включить символ новой строки в имя файла. Если кто знает, не поленитесь — сообщите мне.)
Опция -z
—null-data
Рассматривает ввод как набор строк, каждая из которых заканчивается не символом новой строки, а нулевым байтом. Как и предыдущая опция, используется совместно с вышеперечисленными командами для обработки экзотических имен файлов.
Linux поиск по содержимому файлов командой locate
Поиск, производимый командой locate весьма быстр. Однако учитывайте тот факт, что системная база данных может быть не живой на момент осуществления операции. Механизм сканирования файловой системы, время его проведения и вобщем наличие такого инструмента может разниться в различных дистрибутивах Linux. Команда locate может быть полезна лишь при поиске файла по его имени. Однако для проверки текстового содержимого документов на вступление искомых данных нужно использовать другой инструмент.
Данная команда, как правило, работает быстрее и может с легкостью производить поиск (в широком смысле — стремление добиться чего-либо, найти что-либо; действия субъекта, направленные на получение нового или утерянного (забытого): новой информации (поиск информации), данных,) по всей файловой системы. Linux имеет специальную команду grep, какая принимает шаблон для поиска и имя файла (именованная область данных на носителе информации). В случае нахождения совпадений, они будут выведены в терминал. В всеобщем виде выражение можно составить как «grep шаблон_поиска имя_файла». Чтобы отыскать файлы с помощью команды locate, просто используйте следующий синтаксис:
К образцу, чтобы возвращать только файлы, содержащие сам запрос, вместо того чтобы вводить каждый файл, который содержит запрос в ведущих к нему каталогах, можно утилизировать флаг –b (чтоб искать только basename, базовое имя файла):
Команды find и locate – отличные инструменты для поиска файлов в UNIX‐подобных операционных системах. Любая из этих утилит имеет свои преимущества. Мы рассмотрели использование команд для поиска и фильтрации вывода бригад в операционной системе Linux. При правильном применении эта утилита станет мощным инструментом в ваших руках. Несмотря на то, что команды find и locate сами по себе очень мощны, их действие возможно расширить, комбинируя их с другими командами. Научившись работать с find и locate, попробуйте чистить их результаты при помощи команд wc, sort и grep.
Популярные теги
ubuntu
linux
ubuntu_18_04
settings
debian
setup
ubuntu_16_04
error
macos
redhat
mint
problems
windows
install
server
android
bash
ubuntu_18_10
hardware
update
desktop
wifi
files
убунту
docker
web
rhel
kali
network
security
windows_10
nvidia
ustanovka
python
software
apt
ubuntu_20_04
filesystem
stretch
issues
kde
manjaro
password
shell
apache2
partition
mysql
wine
program
video_card
disk
package-management
apt-get
drivers
virtualbox
performance
vpn
video
gnome
keyboard
terminal
kubuntu
usb
nginx
sound
driver
games
wi_fi
macbook
kernel
installation
display
delete
scripting
user
command-line
disk_space
freebsd
dual_boot
ubuntu_17_10
cron
fedora
lubuntu
oshibka
chrome
boot
for
ssh
mail
os
centos
zorin_os
установка
firewall
git
zorin
bluetooth
hotkeys
kvm
live_usb
Синтаксис
grep ШАБЛОН
Ниже предоставлены основные опции утилиты.
-b — показывать номер блока перед строкой-c — Отключает стандартный способ вывода результата и вместо этого отображает только число обозначающее количество найденых строк.-h — не выводить имя файла в результатах поиска внутри файлов Linux-i — не учитывать регистр-l — отобразить только имена файлов, в которых найден шаблон-n — показывать номер строки в файле-s — не показывать сообщения об ошибках-v — инвертировать поиск, выдавать все строки кроме тех, что содержат шаблон-w — Ведет поиск по цельным словам. Например при обычном поиске строки ‘wood’ grep может найти слово ‘hollywood’. А если используется данный ключ то будут найдены только строки где есть слово ‘wood’-e — использовать регулярные выражения при поиске-An — показать вхождение и n строк до него-Bn — показать вхождение и n строк после него-Cn — показать n строк до и после вхождения-o — показать только совпадающие (непустые) части совпадающей строки, каждая из которых находится в отдельной строке.-P — Интерпретировать шаблон как регулярное выражение Perl. Это экспериментально, и grep -P может предупредить о невыполненных функции.-r — Производит поиск рекурсивно по всем поддиректориям.
COLOPHON top
This page is part of the GNU grep (regular expression file search
tool) project. Information about the project can be found at
⟨https://www.gnu.org/software/grep/⟩. If you have a bug report
for this manual page, send it to bug-grep@gnu.org. This page was
obtained from the project's upstream Git repository
⟨git://git.savannah.gnu.org/grep.git⟩ on 2021-04-01. (At that
time, the date of the most recent commit that was found in the
repository was 2021-01-31.) If you discover any rendering
problems in this HTML version of the page, or you believe there
is a better or more up-to-date source for the page, or you have
corrections or improvements to the information in this COLOPHON
(which is not part of the original manual page), send a mail to
man-pages@man7.org
GNU grep 3.6.18-70517-dirty 2019-12-29 GREP(1)
Pages that refer to this page:
gawk(1),
look(1),
pmchart(1),
pmdiff(1),
pmie(1),
pmie_check(1),
pmlogctl(1),
pmlogger_check(1),
pmrep(1),
pmsnap(1),
sed(1),
regex(3),
regex(7),
bridge(8),
ip(8),
tc(8)