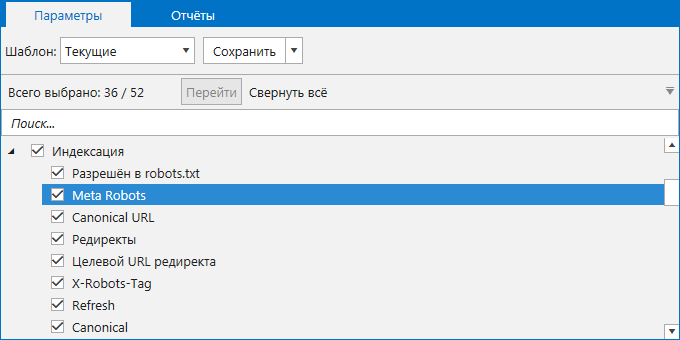
WordPress seo: создание файла robots.txt. использование тега meta robots. xml-карта сайта
Содержание:
Конфликтующие параметры и файлы robots.txt
Важно помнить, что мета-теги robots работают иначе, чем инструкции в файле robots.txt. Конфликтующие правила могут вызывать непредвиденное поведение
Например, поисковые системы не смогут увидеть ваши meta теги, если страница заблокирована через robots.txt.
Вам также следует позаботиться о том, чтобы не устанавливать конфликтующие значения в теге meta-robots в (например, использовать оба параметра index и noindex), особенно если вы устанавливаете разные правила для разных поисковых систем.
В случаях конфликта обычно выбирается наиболее ограничительная интерпретация значения. То есть «noindex» обычно бьет «index»).
На мой странице (не) обнаружен мета-тег, а страница (не) видна в поиске
Действительно, так бывает, что статью из Дзена не удаётся найти в поиске, хотя на ней нет зловредного мета-тега; или наоборот — тег есть, но и на статью есть переходы из поиска.
Всё дело в том, что поисковики работают с определённой задержкой, кроме того у них свои алгоритмы, определяющие, отвечает ли статья на поисковый запрос и насколько она релевантна ему.
Статья, которая отлично чувствуют себя в Дзене, собирает сотни тысяч и миллионы показов, поисковику может показаться неинтересной, и тогда он не будет показывать ссылку на неё на первых страницах поиска.
Кроме того, индексирование может занимать продолжительное время, это значит, что после появления (или удаления мета-тега), должно пройти какое-то время, прежде чем изменение будет учтено поисковыми системами.
Зачем нужен ?
Тег <noindex> очень важен, если вы хотите, чтобы часть текста, со всеми анкорами ссылок и т.д., не индексировалась и не попала в поисковую базу Yandex.
Например, у вас на странице может быть служебная информация, или блок текста с сайта, который используется как негативный пример. Вы не хотите, чтобы поисковик связал ваш сайт с данным текстом или индексировал служебную информацию и сохранил у себя в базе. Для этого данный блок обрамляется тегом <noindex>.
К сожалению, такого инструмента для Google не существует
Вполне возможно, что Google или консорциум W3C в будущем обратят внимание на данный тег или придумают свой, и веб-мастера получат в свой инструментарий еще один полезный инструмент
Тег и как его применять
Тег — это структурная единица HTML разметки, а все что внутри, называют содержанием элемента.
Что такое тег <noindex>?
<noindex> — тег, который используется для закрытия определенных участков текста. Контент внутри будет недоступен для индексации поисковыми системами, такими как Yandex и Rambler. То есть, с его помощью, мы запрещаем боту сканировать часть контента. Эту конструкцию правильно использовать внутри <body></body> в таком виде:
<noindex>нас не увидят</noindex>
Важно помнить: не стандартизирован компанией Google и не относится к официальной разметке HTML. Поэтому, будет вызывать ошибки в коде
Так как Google этот тег не знает, то и скрыть контент от индексации не сможет.
Валидность HTML сохраняется с использованием специальной конструкции:
<!--noindex-->Мы спрятались 0_0<!--/noindex-->
Когда использовать?
На тот случай, когда мы не хотим затрагивать основной контент страницы, а только скрыть определенные служебные участки текста. Тогда на помощь приходить тег который не разрешит поисковикам добавить выбранный участок в индексную базу.
“А смысл нам что-то скрывать?” — спросите вы.
А поисковый робот ответит: “Берегите уникальность своего контента и это вернется вам высокими позициями в выдаче”.
Поисковые системы любят сайты с уникальным наполнением и за это благодарят их высокими позициями в выдаче. На ранжирование влияет ряд негативных факторов:
- выдержки из законодательства;
- цитирование чужих авторов;
- служебный контент на вашем ресурсе;
- периодически дублирующий текст;
- сохранить контент от переспама ключевыми словами для Yandex и Rambler.
X-robots-tag
While the meta robots tag allows you to control indexing behavior at the page level, the x-robots-tag can be included as part of the HTTP header to control indexing of a page as a whole, as well as very specific elements of a page.
While you can use the x-robots-tag to execute all of the same indexation directives as meta robots, the x-robots-tag directive offers significantly more flexibility and functionality that the meta robots tag does not. Specifically, the x-robots permits the use of regular expressions, executing crawl directives on non-HTML files, and applying parameters at a global level.

To use the x-robots-tag, you’ll need to have access to either your website’s header .php, .htaccess, or server access file. From there, add your specific server configuration’s x-robots-tag markup, including any parameters. This article provides some great examples of what x-robots-tag markup looks like if you’re using any of these three configurations.
Here are a few use cases for why you might employ the x-robots-tag:
-
Controlling the indexation of content not written in HTML (like flash or video)
-
Blocking indexation of a particular element of a page (like an image or video), but not of the entire page itself
-
Controlling indexation if you don’t have access to a page’s HTML (specifically, to the <head> section) or if your site uses a global header that cannot be changed
-
Adding rules to whether or not a page should be indexed (ex. If a user has commented over 20 times, index their profile page)
Распространенные ошибки
Мы рассмотрели разные способы закрытия от индексации, но сложности встречаются у каждого пути. Давайте рассмотрим самые популярные из них.
Неправильные способы закрытия от индексации:
- пользоваться тегом <noindex> и забыть, что только Yandex его распознает, а для Google контент будет полностью проиндексирован.
- пытаться удалить сайт из index с помощью Disallow в robots.txt. Да, к вам поисковый робот больше не зайдет, но и из поиска никуда не денется. Для полного удаления из index, воспользуйтесь Google Search Console.
- пытаться удалить страницу сайта из index с помощью robots.txt + мета-тега robots. Мы закрыли страницу от сканирования роботами, но она уже находится в index. При следующем сканировании они не смогут зайти на ресурс и увидеть мета-тег, чтобы убрать его из index. По итогу она так и останется видимой для поисковой системы.
Как этого избежать?
После прочтения данной статьи:
Определите что именно вам нужно скрыть
Это может быть директория, документ или часть контента.
Четко под свои задачи, выберите нужный способ решения.
Перечитайте о нем более детально в этой статье и возьмите во внимание нюансы использования и внедрения.
Common Meta Robots Mistakes
It’s not uncommon for mistakes to be made when instructing search engines how to crawl and index a web page, with the most common being:
Meta Robots Directives on a Page Blocked By Robots.txt
If a page is disallowed in your robots.txt file, search engine bots will be unable to crawl the page and take note of any directives that are placed in meta robots tags or in an x-robots-tag.
Make sure that any pages that are instructing user-agents in this way can be crawled.
If a page has never been indexed, a robots.txt disallow rule should be sufficient to prevent this from showing in search results, but it is still recommended that a meta robots tag is added.
Adding Robots Directives to the Robots.txt File
While never officially supported by Google, it used to be possible to add a noindex directive to your site’s robots.txt file and for this to take effect.
This is no longer the case and was confirmed to no longer be effective by Google in .
Removing Pages With a Noindex Directive From Sitemaps
If you are trying to remove a page from the index using a noindex directive, leave the page in your site’s sitemap until this has happened.
Removing the page before it has been deindexed can cause delays in this happening.
Accidentally Blocking Search Engines From Crawling an Entire Site
Sadly, it’s not uncommon for robots directives that are used in a staging environment to accidentally be left in place when the site moves to a live server, and the results can be disastrous.
Before moving any site from a staging platform to a live environment, double-check that any robots directives that are in place are correct.
You can use the Semrush Site Audit Tool before migrating to a live platform to find any pages that are being blocked either with meta robots tags or the x-robots-tag.
By taking the time to understand the different directives and how to use them, you can prevent technical SEO mistakes. Having sufficient control over how your pages are crawled and indexed can help to keep unwanted pages out of the SERPs, prevent search engines from following unnecessary links, and give you control over how your site’s snippets are displayed, among other things. Get started setting up your robots meta tags and x-robots-tags to ensure that your site is running smoothly!
Run a Technical Site Audit
with the Semrush Site Audit Tool
Try for Free →
Try for Free →
How to Set Up Robots Meta Tags and X‑Robots-Tag
Setting up robots meta tags is, generally, easier than the x-robots-tag, but the implementation of both methods of controlling how search engines crawl and index your site can differ depending on your CMS and/or server type.
Here’s how yo use meta robots tags and the x-robots-tag on common setups:
Using Robots Meta Tags in HTML Code
If you can edit your page’s HTML code, simply add your robots meta tags straight into the <head> section of the page.
If you want search engines not to index the page but want links to be followed, as an example, use:
Using Robots Meta Tags on WordPress
If you’re using Yoast SEO, open up the ‘advanced’ tab in the block below the page editor.
You can set the «noindex» directive by setting the «Allow search engines to show this page in search results?» dropdown to no or prevent links from being followed by setting the «Should search engines follow links on this page?» to no.
For any other directives, you will need to implement these in the «Meta robots advanced» field.
If you’re using RankMath, you can select the robots directives that you wish apply straight from the Advanced tag of the meta box:
Image courtesy of RankMath
Using Robots Meta Tags on Shopify
If you need to implement robots meta tags on Shopify, you’ll need to do this by editing the <head> section of your theme.liquid layout file.
To set the directives for a specific page, add the below code to this file:
This code will instruct search engines, not to index /page-name/ but to follow all of the links on the page.
You will need to make separate entries to set the directives across different pages.
Using X-Robots-Tag on an Apache Server
To use the x-robots-tag on an Apache web server, add the following to your site’s .htaccess file or httpd.config file.
The example above sets the file type of .pdf and instructs search engines not to index the file but to follow any links on it.
Using X-Robots-Tag on an Nginx Server
If you’re running an Nginx server, add the below to your site’s .conf file:
This will apply a noindex attribute and follow any links on a .pdf file.
Что такое тег Noindex
Noindex — это тег, в который вы заключаете часть кода, и этот код по идее не должен индексироваться Яндексом. Тег ноиндекс был предложен именно Яндексом, и по сей день учитывается только системами Yandex и Rambler. Вот как он выглядит:
<noindex>скрываемый текст</noindex>
Noindex – парный тег, и его необходимо закрывать.
Noindex не чувствителен к вложенности.
Целесообразность использования тега
Лично я смысла в его использовании не вижу. Потому что Google этот тег игнорирует. Да и зачем скрывать что-то? Надо делать сайты для людей!
Раньше сеошники скрывали в него часть текста, чтобы не было переспама. Но лично я предпочитаю в целях борьбы с переспамом просто снижать количество ключей в наиболее важных зонах документа.
Если же вы все-таки решили пользоваться этим тегом, то гляньте видео от ТопЭксперт:
Meta name robots index и follow
Чтобы одновременно можно было переходить индексировать страницу и переходить по ссылкам следует записать:
<meta name=»robots» content=»index, follow»>
Чтобы не заносить в базу данных поисковой машины картинки пишут:
<meta name=»robots» content=»noimageindex»>
Meta name robots content noarchive
Поисковые машины Google и Yandex для каждого сканируемого сайта, делают и сохраняют его снимок. Архивированный вариант хранится в кэше, что дает возможность поисковику отображать эту страницу по специальной ссылке в результатах поиска, когда она по каким-то техническим причинам недоступна. Веб-страница, хранимая в кэше, отображается такой, какой она была в тот момент, когда ее сохранил поисковый робот. О том, что пользователь просматривает кэшированную страницу говорит сообщение в верхней части сайта. Можно обратиться к кэш-версии страницы, нажав на кнопку «сохранено в кэше», в результатах поиска.
Если вы не желаете, чтобы в поисковых системах была подобная ссылка, можно дописать в head такой тег:
<meta name=»robots» content=»noarchive»>
Для того чтобы кнопка «Сохранено в кэше» не выводилась в определенной поисковой системе можно написать:
<meta name=»имя_робота» content=»noarchive»>

Такая запись убирает только ссылку «Сохранено» на архивированную страницу, поисковая система и дальше будет индексировать сайт и отображать его фрагмент.
Для чего нужен атрибут rel nofollow
<a href =”http://website.ru” rel=”nofollow”>скрытая ссылка</a>
Зеленые вебмастера, которые впервые узнали о рел нофоллоу, сразу думают: «Отлично! Теперь я всем ссылкам его пропишу и вес не будет утекать никуда».
На самом деле поисковик вполне себе переходит по ссылкам с этим атрибутом и они вполне себе забирают ссылочный вес у ваших страниц. То есть смысла в этом атрибуте, как и в noindex, нет. Ссылки закрывать эффективно только через Ajax, да и это я думаю не навсегда
Но, если же вы все-таки решили сконцентрировать внимание на этой точке, которая в лучшем случае даст вам микроскопический рост, то вот еще один видос от ТопЭксперт:
Атрибуты¶
- Задаёт кодировку документа.
- Устанавливает значение атрибута, заданного с помощью или .
- Предназначен для конвертирования метатега в заголовок HTTP.
- Имя метатега, также косвенно устанавливает его предназначение.
charset
Указывает кодировку документа. Атрибут введён в HTML5 и предназначен для сокращения формы , которая задавала кодировку в предыдущих версиях HTML и XHTML.
Синтаксис
Значения
Название кодировки, например UTF-8.
Значение по умолчанию
Нет.
content
устанавливает значение атрибута, заданного с помощью или . Атрибут может содержать более одного значения, в этом случае они разделяются запятыми или точкой с запятой.
Некоторые значения атрибута для , предназначенных для поисковых роботов, приведены в табл. 1.
| Значение | Описание |
|---|---|
| Разрешает роботу индексировать данную страницу. | |
| Запрещает роботу индексировать текущую страницу. Она не попадает в базу поисковика и её невозможно будет найти через поисковую систему. | |
| Разрешает роботу переходить по ссылкам на данной странице. | |
| Запрещает роботу переходить по ссылкам на данной странице. При этом всем ссылкам не передаётся ТИЦ (тематический индекс цитирования) и PagePank. | |
| Запрещает роботу кэшировать данную страницу. |
Допустимые значения атрибута для , которые предназначены для управления просмотром сайта на мобильных устройствах, приведены в табл. 2.
| Значение | Допустимые значения | Описание |
|---|---|---|
| device-width или целое положительное число | Устанавливает ширину области просмотра в пикселях. | |
| device-height или целое положительное число | Устанавливает высоту области просмотра в пикселях. | |
| Число от 0.0 до 10.0 | Устанавливает соотношение между шириной устройства (device-width в портретном режиме или device-height в ландшафтном режиме) и размером области просмотра. | |
| Число от 0.0 до 10.0 | Задаёт максимальное значение масштаба. Должно быть больше или равно minimum-scale, в противном случае игнорируется. | |
| Число от 0.0 до 10.0 | Задаёт минимальное значение масштаба. Должно быть меньше или равно maximum-scale, в противном случае игнорируется. | |
| yes или no | Если указано no, то пользователь не сможет масштабировать веб-страницу. По умолчанию используется yes. |
Синтаксис
Значения
Строка символов, которую надо взять в одинарные или двойные кавычки.
Значение по умолчанию
Нет.
http-equiv
Браузеры преобразовывают значение атрибута , заданное с помощью , в формат заголовка ответа HTTP и обрабатывают их, как будто они прибыли непосредственно от сервера.
Синтаксис
Значения
Любой подходящий идентификатор. Ниже приведены некоторые допустимые значения атрибута .
- Тип кодировки документа.
Устанавливает дату и время, после которой информация в документе будет считаться устаревшей.
Способ кэширования документа.
- Загружает другой документ в текущее окно браузера.
Значение по умолчанию
Нет.
name
Устанавливает идентификатор метатега для пары «». Одновременно использовать атрибуты и не допускается.
Синтаксис
Значения
Любой подходящий идентификатор. Ниже приведены некоторые допустимые значения атрибута .
- Имя автора документа.
- Описание текущего документа.
- Список ключевых слов, встречающихся на странице.
- Управляет просмотром сайта на мобильных устройствах.
Значение по умолчанию
Нет.
Мета-теги. Виды, задачи и шаблоны для оптимизаторов
В контейнер заголовка также могут быть добавлены тэги, содержащие кодировку, ключевые слова web-страницы, а также код для подключения файлов каскадных таблиц стилей CSS, языка программирования JavaScript, VBScript и т.д.
Пример простейшей HTML странички, содержащей только основные тэги:
Результат работы указанного кода изображен на рисунке.
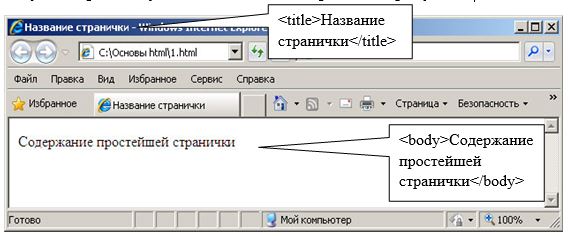
Как видно из примера текст «Содержание простейшей странички» отображается обычным текстом. Для того чтобы произвести форматирование этого текста, необходимо использовать специальные тэги. Пример использования тэгов форматирования представлен на рисунке.
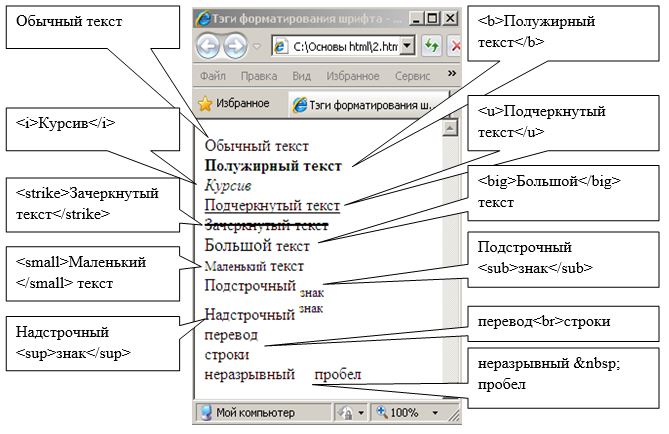
Для изменения шрифта, его цвета и размера используется тэг <font> с параметрами “face”, “color” и “size”. Например для того чтобы задать шрифт “arial” красного цвета и 14 размера необходимо написать следующий код:
Для выделения абзаца в тексте используется тэг <p>, в контейнер которого как правило помещается каждый абзац текста. Для создания заголовка используются тэги <h1>, <h2>, <h3>, <h4>, <h5>, <h6>.
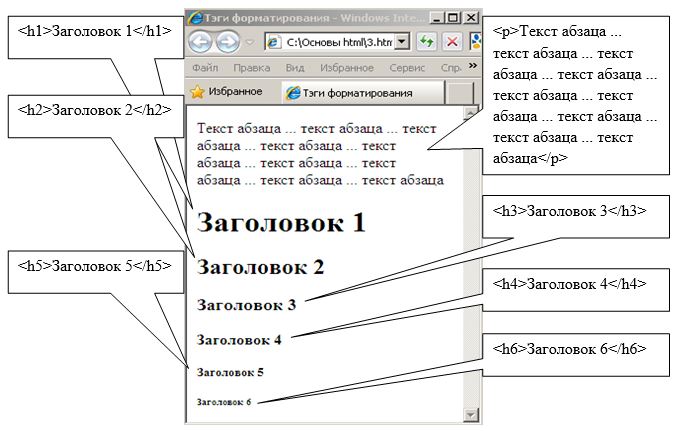
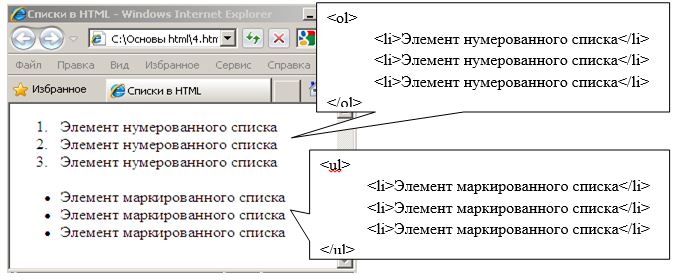
Для формирования списков в теле документа используются контейнеры <ol></ol>, <ul></ul> и <li></li>. Причем тэг <ol> формирует нурмерованный список, тэг <ul> — маркированный список, а в тэгах <li> помещаются элементы списка. Пример кода отображения списков, представленный в виде нумерованного и маркированного списков представлен на рисунке.
Для связи двух и более Web-страниц между собой используются гиперссылки, для создания которых используется тэг <a>. Причем в тэгах гиперссылок используются дополнительные атрибуты, позволяющие либо перейти к другой web-странице, либо переместиться внутри данной страницы. Второй способ желательно использовать в большом документе, имеющем несколько смысловых разделов.
Пример использования гиперссылок представлен на рисунке.
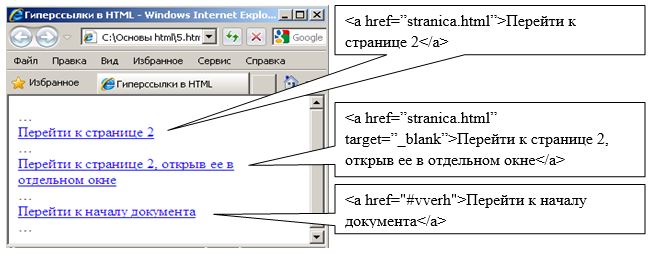
При указании URL адреса другой страницы необходимо указывать либо полный абсолютный путь к странице «полный путь/папка/страница» либо относительный (относительно данной страницы) «папка/страница». Параметр “target” позволяет открыть web-страницу в новом или существующем окне браузера.
Для вставки изображения на web-страницу используется тэг <img> с параметрами src (путь к изображению), width (ширина изображения), height (высота изображения), border (рамка вокруг рисунка). Пример кода вставки изображения:
Часто при создании Web-страниц необходимым является задание фонового цвета или фонового изображения. Для этого используются атрибуты тэга <body> «bgcolor» или «background-image». Пример вставки фонового цвета:
Пример вставки фонового изображения:
Указанные атрибуты могут быть использованы не только для тэга <body>, но и для тэгов таблицы, области и других, которые будут рассмотрены в следующих темах.
Noindex
Тег noindex используется, чтобы запретить индексацию какой-то определенной части текста. Следует помнить, что ссылки и изображения этот тег от поисковиков не закрывает. Если все-таки попытаться закрыть этим тегом анкор со ссылкой, то под индексацию не попадет только анкор (словосочетание), а сама ссылка однозначно попадает в индекс.
Noindex запрещает индексацию части кода, находящуюся между открывающим и закрывающим тегами. Вот пример:
Естественно, его не стоит путать с мета-тегом ноиндекс, который прописывается вначале страницы, они имеют различные задачи. Если взять мета-тег <meta name=»robots» content=»noindex,nofollow»> , то он запрещает индексирование всей страницы и переход по ссылкам. Этот запрет можно также прописать в файле robots.txt и такие страницы поисковыми роботами не будут учтены.
Валидный noindex
Некоторые HTML-редакторы noindex не воспринимают, поскольку он не является валидным. К примеру, в WordPress визуальный редактор его попросту удаляет. Но валидность тегу все же придать можно:
Если в HTML-редакторе прописать тег в такой форме, то он будет абсолютно валиден и можно не бояться, что он исчезнет. Тег noindex воспринимает только поисковый бот Яндекса, робот Гугла на него абсолютно не реагирует.
Некоторые оптимизаторы допускают ошибку, когда советуют закрыть все ссылки такими тегами noindex и nofollow, но об этом будет рассказано ниже. Что касается работы тега ноиндекс, то она безотказна. Абсолютно вся заключенная в этих тегах информация в индекс не попадает. Но некоторые вебмастера утверждают, что иногда все же текст внутри этих тегов индексируется ботами – да, действительно такое случается.
А это все потому, что Yandex изначально индексирует полностью весь html-код страницы, даже находящийся внутри noindex, но затем происходит фильтрация. Поэтому вначале действительно проиндексирована вся страница, но через некоторое время html-код срабатывает и тест, заключенный в этот тег «вылетает» из индексации.
Можно даже не соблюдать вложенность тега noindex – он все равно сработает (об этом рассказывается в справочной Яндекса). Не забывайте, используя, открывающий <noindex> в конце исключаемого текста поставить закрывающий </noindex>, а то весь текст, идущий после тега не проиндексируется.
Директива max-image-preview:large
С версии WP 5.7 WordPress по умолчанию добавляет директиву max-image-preview:large в мета-тег на все страницы.
<meta name="robots" content="max-image-preview:large" />
Чтобы отключить эту директиву, можно использовать следующий код:
remove_filter( 'wp_robots', 'wp_robots_max_image_preview_large' );
max-image-preview:
Эта директива определяет максимальный размер изображений, которые могут показываться в результатах поиска для этой страницы.
Если не указать директиву max-image-preview, будет возможен предварительный просмотр изображения размером, заданным по умолчанию.
Допустимые значения для :
- none
- Нет изображения для предварительного просмотра.
- standard
- Может быть показано изображение для предварительного просмотра по умолчанию.
- large
- Может быть показано более крупное изображение, вплоть до максимальной ширины области просмотра.
Это распространяется на все виды результатов поиска (веб-поиск Google, Google Картинки, рекомендации и данные, предоставляемые Ассистентом). Ограничение не применяется в тех случаях, когда издатель предоставил отдельное разрешение на использование контента, например добавил структурированные данные или заключил лицензионное соглашение с компанией Google. В частности, структурированные данные могут определять каноническую и AMP-версию статьи.
Если вы не хотите, чтобы ваши канонические страницы и их AMP-версии были представлены в Google Поиске и рекомендациях в виде увеличенных значков, укажите в директиве значение или .
Тег и атрибут rel=“nofollow”
Давайте взглянем на тот случай, когда такая комбинация нецелесообразна.
Зачем использовать тег <noindex> и атрибут rel=”nofollow” вместе?
В случае, когда мы хотим скрыть от индексации и сделать текст внутри ссылки невидимым для таких поисковых систем как Yandex и Rambler(подробнее о разных поисковиках читайте выше). Google же прочитает название ссылки, но не внесет ее в свой index благодаря атрибуту rel=”nofollow”.
Вместе это выглядит так:
<noindex><a href="http://mysite.com/" rel="nofollow">название ссылки</a></noindex>
Мы видим, как ссылку с атрибутом rel=”nofollow” обернули в тег <noindex>. Это верный способ написания кода.
Как использовать noindex и nofollow в meta robots
Посмотрим на возможные значения атрибута content:
- noindex, nofollow – запрещена к индексации вся страница и переходы по ссылкам на ней; кстати, идентичной будет значение при записи: <meta name =”robots” content=”none”/>
- noindex, follow – страница не индексируется, но поисковик может переходить по ссылкам;
- index, nofollow – страница индексируется, но переход по ссылкам запрещен;
- index, follow – разрешены к индексированию как страница, так и ссылки на ней;
- noarchive – работает как в yandex, так и в google – не показывает страницу на сохраненную копию;
- noyaca – работает только в Яндексе, если сайт зарегистрирован в каталоге YACA – запрещает использовать описание в результатах поиска, которое берется из Яндекс.Каталога; выглядит так: <meta name =”robots” content=”noyaca”/>
- noodp – работает и в Яндексе, и в Google – запрещает использовать в результатах описания, которые взяты из Каталога ДМОЗ (разумеется, если сайт там зарегистрирован).
Поговорим чуть больше о noodp
Иногда Гугл может добавлять в сниппет описание из DMOZ. Именно для этого и используется атрибут noodp. Кстати, его можно использовать вместе с тегом nofollow. Выглядит это так:
<meta name=“robots” content=”noodp, nofollow”/>
Чего нужно опасаться при использовании
Из-за невнимательности (особенно у новичков) могут случаться конфликты между тегами: в таком случае главным будет положительное значение (разрешающее индексацию). Например тут:
<meta name =”robots” content=”all”/> <meta name =”robots” content=”noindex, nofollow”/>
Тут выбрано будет первое значение, так как там оно положительно.
Alt атрибуты изображения
Атрибут alt изображения добавляется к тегу изображения img для описания его содержимого. Альтернативные атрибуты важны с точки зрения внутренней оптимизации сайта по двум причинам:
- Альтернативный текст показывается посетителям, если какое-либо конкретное изображение не может быть загружено (или если отображение картинок отключено).
- Атрибуты Alt обеспечивают контекст для роботов, потому что поисковые системы не могут «видеть» изображения.
На e-commerce сайтах изображения часто имеют решающее влияние на то, как посетитель взаимодействует со страницей
Поисковики так же прямо заявляют о важности этого тега
Например, Google в своих гайдах для вебмастеров пишет, что помощь поисковым системам в понимании того, что находится на картинках, и как они сочетаются с остальным контентом, помогает соотносить страницу сайта с подходящими поисковыми запросами.
Даже Мюллер писал у себя в Твиттере, что продуманное альтернативное описание изображения необычайно важно, если вы хотите занять высокое место в Google Картинках. Однако не забывайте о релевантности
Не только alt-текст, заголовки и подписи должны соответствовать изображению, но и сама картинка должна размещаться в тематическом контенте
Однако не забывайте о релевантности. Не только alt-текст, заголовки и подписи должны соответствовать изображению, но и сама картинка должна размещаться в тематическом контенте.
Оптимизация alt тега img для изображений
- Сделайте всё возможное, чтобы оптимизировать свои самые важные изображения (картинки товаров, инфографику, инструкции), которые могут получить хорошие позиции в поиске Google Images.
- Добавьте alt-текст на страницах, где не так много другого контента (кроме картинок).
- Делайте тег alt для изображений понятным и достаточно информативным, разумно используйте ключевые слова и убедитесь, что они естественным образом вписываются в содержание страниц.
Что такое nofollow
Атрибут, вставляющийся перед ссылками и запрещающий по ним переходить.
Вес страницы — это своего рода уровень авторитетности сайтов, один из факторов, учитываемых при ранжировании страниц в поисковых запросах. Чтобы не передавать вес страницы другим сайтам по размещенным на них ссылкам, данные ссылки оборачивают в тег nofollow.
Какой контент помечается этим атрибутом?
Ссылки. Но не все ссылки, а те, что могут как-то негативно повлиять на вес ресурса. Это касается автоматических ссылок, появляющихся в тех или иных участках сайта. Атрибут nofollow стоило бы приписывать любым внешним ссылкам, за которые вы не можете ручаться. Добавленные на ресурс другими пользователями через секцию комментариев или в графу профиля БИО.
Как прописывать тег?
С таким тегом индексирование страницы разрешается, но запрещается переход по всем ссылкам:
<meta name="robots" content="nofollow"/>
Как и в случае с <noindex>, правило можно задать для конкретного поискового робота:
<meta name="googlebot" content="nofollow"/>
Если мы говорим о конкретных ссылках, то переход на них можно запретить прямо внутри разметки.
<a href=“page.html” rel=“nofollow”>Гиперссылка</a>