Иерархическая модель данных
Содержание:
Ограничения типа данных hierarchyid
Тип данных hierarchyid имеет следующие ограничения.
-
Столбец типа hierarchyid не принимает древовидную структуру автоматически. Приложение должно создать и назначить значения hierarchyid таким образом, чтобы они отражали требуемые связи между строками. Некоторые приложения могут содержать столбец типа hierarchyid , указывающий местоположение в иерархии, определенной в другой таблице.
-
Параллельными процессами создания и присвоения значений hierarchyid управляет само приложение. Нет никакой гарантии, что значения hierarchyid уникальны, если приложение не использует ограничение уникального ключа или не обеспечивает уникальность своей логикой.
-
Иерархические связи, представленные значениями типа hierarchyid , не обеспечиваются и не проверяются, как связи по внешнему ключу. Можно, а иногда и удобно иметь иерархическую связь, в которой у A есть потомок B и когда A удаляется, у B остается связь с несуществующей записью. Если это неприемлемо, приложение должно запросить потомков, прежде чем удалять родителей.
Ниже описаны подходы к индексированию иерархических данных:
Есть два подхода к индексированию иерархических данных:
-
В глубину
В индексе преимущественно в глубину строки поддерева хранятся рядом друг с другом. Например, записи всех сотрудников, в цепи подчиненности которых есть данный руководитель, хранятся рядом с записью руководителя.
В индексе преимущественно в глубину все узлы поддерева узла хранятся вместе. Поэтому индекс преимущественно в глубину эффективен для обработки запросов по поддеревьям. Например, «найти все файлы в этой папке и ее подкаталогах».
-
В ширину
Если используется индексирование в ширину, строки одного уровня иерархии хранятся вместе. Например, записи всех сотрудников, напрямую подчиненных одному и тому же руководителю, хранятся рядом друг с другом.
В индексе преимущественно в ширину все прямые потомки узла хранятся в одном месте. Поэтому индекс преимущественно в ширину эффективен для запросов по прямым потомкам. Например: «найти всех прямых подчиненных этого начальника».
Выбор стратегии индексирования (в глубину, в ширину или обе) и ключа кластеризации зависит от того, какие из вышеуказанных типов запросов обрабатываются чаще и какие операции более важны (SELECT или DML). Пример использования стратегий индексирования см. в разделе Tutorial: Using the hierarchyid Data Type.
Создание индексов
Для организации данных в ширину можно использовать метод GetLevel(). В следующем примере создаются оба типа индекса: преимущественно в глубину и преимущественно в ширину.
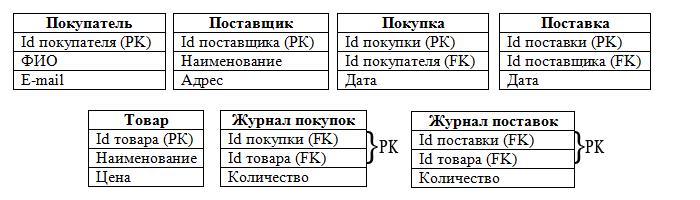
Примеры иерархических данных, представленных в виде реляционных таблиц
Организация может хранить информацию о сотрудниках в таблице, содержащей атрибуты / столбцы, такие как номер сотрудника, имя, фамилия и номер отдела. Организация предоставляет каждому сотруднику компьютерное оборудование по мере необходимости, но компьютерное оборудование может использоваться только тем сотрудником, за которым оно закреплено. Организация может хранить информацию о компьютерном оборудовании в отдельной таблице, которая включает серийный номер каждой детали, тип и сотрудника, который ее использует. Таблицы могут выглядеть так:
|
|
В этой модели таблица данных представляет «родительскую» часть иерархии, а таблица представляет «дочернюю» часть иерархии. В отличие от древовидной структуры, обычно встречающейся в алгоритмах компьютерного программного обеспечения, в этой модели дети указывают на родителей. Как показано, каждый служащий может владеть несколькими единицами компьютерного оборудования, но у каждой отдельной единицы компьютерного оборудования может быть только один служащий-владелец.
Рассмотрим следующую структуру:
| EmpNo | Обозначение | Отчеты |
|---|---|---|
| 10 | Директор | |
| 20 | Старший менеджер | 10 |
| 30 | Машинистка | 20 |
| 40 | Программист | 20 |
В этом «дочерний» тот же тип, что и «родитель». В иерархии указано, что EmpNo 10 является начальником из 20, а 30 и 40 каждый отчет до 20 представлен столбцом «ReportsTo». В терминах реляционных баз данных столбец ReportsTo — это внешний ключ, ссылающийся на столбец EmpNo. Если бы «дочерний» тип данных был другим, он находился бы в другой таблице, но по-прежнему существовал бы внешний ключ, ссылающийся на столбец EmpNo таблицы сотрудников.
Эта простая модель, широко известная как модель списка смежности, была представлена д-ром Эдгаром Ф. Коддом после того, как появились первые критические замечания о том, что реляционная модель не может моделировать иерархические данные. Однако эта модель является лишь частным случаем общего списка смежности для графа.
Принцип построения иерархической модели
Иерархическая модель данных строится по следующему принципу:
- для каждого узла древовидной структуры ставится в соответствие некий сегмент;
- под сегментом понимаются поля данных с присвоенным каждому полю именем и выстроенные в один линейный кортеж;
- еще одно соответствие: один входной и несколько выходных сегментов для каждого исходного поля;
- для каждого структурного элемента существует одно и только одно место в системе иерархии;
- древовидная структура начинается с корневого элемента;
- у каждого подчиненного узла только один предок, но у каждого исходного может быть несколько потомков.
История
Иерархическая структура была разработана IBM в 1960-х годах и использовалась в ранних СУБД для мэйнфреймов . Отношения записей образуют древовидную модель. Эта структура проста, но негибка, поскольку отношения ограничиваются отношениями «один ко многим». Система IBM Information Management (IMS) и RDM Mobile являются примерами иерархической системы баз данных с несколькими иерархий над теми же данными. RDM Mobile — это недавно разработанная встроенная база данных для мобильной компьютерной системы.
Иерархическая модель данных потеряли тракция Кодда «s реляционную модель стала стандартом де — факто используется практически во всех системах управления базами данных господствующих. Реализация иерархической модели в реляционной базе данных впервые обсуждалась в опубликованной форме в 1992 году (см. Также модель вложенных множеств ). Схемы иерархической организации данных вновь появились с появлением XML в конце 1990-х (см. Также базу данных XML ). Иерархическая структура сегодня используется в основном для хранения географической информации и файловых систем.
В настоящее время иерархические базы данных по-прежнему широко используются, особенно в приложениях, требующих очень высокой производительности и доступности, таких как банковское дело и телекоммуникации. Одна из наиболее широко используемых коммерческих иерархических баз данных — IMS. Другой пример использования иерархических баз данных реестра Windows в Microsoft Windows операционных систем.
3.1.1.Структура данных.
Экземпляр сегмента образуется из конкретных значений полей данных. Тип сегмента — это поименованная совокупность входящих в него типов полей данных. В иерархической модели данных вершине графа соответствует тип сегмента или просто сегмент, а дугам — типы связей предок — потомок. В иерархических структуpax сегмент — потомок должен иметь в точности одного предка.
Иерархическая БД состоит из упорядоченного набора деревьев. Среди операторов манипулирования данными можно выделить операторы поиска данных, операторы поиска данных с возможностью модификации, операторы модификации данных.
Обобщенное описание структуры
Термин «древовидная» для описания структуры упоминается в этой статье уже далеко не единожды. Пора рассказать, откуда он произошел. Все потому что иерархическая база данных — это такая БД, которая использует тип данных «дерево». Рассмотрим подробнее, что он из себя представляет.
Это составной тип: в каждый из элементов (узлов) вкладывается несколько последующих (один или более). А начинается все с одного корневого элемента. Суть в том, что каждый из кусочков типа «дерево», является подтипом, тоже «деревом». Много-много разветвленных, и все также упорядоченных структур.
Элементарные типы могут быть простыми и составными, но по существу это всегда записи. Но в простом записи присутствует один тип данных, а в составном — целая их совокупность.
Иерархической модели свойственен принцип потомков, когда каждый предыдущий сегмент является предком для последующего. Кроме того, потомок по отношению к вышестоящему типу является типом подчиненным, в то время как равнозначные один другому записи считаются близнецами.
В чём преимущества
Базы данных и их системы управления заточены на работу с большим объёмом данных и от лица большого числа пользователей. Сейчас вы поймёте.
Скорость — ещё одно преимущество базы данных. База данных устроена так, что она легко и быстро находит, записывает, переписывает и снова находит данные. Всё потому, что СУБД всегда знает, что где лежит и по какому критерию искать. Там не будет случайных данных в случайном месте.
Скорость важна ещё и потому, что СУБД обычно обслуживает сразу много потоков: одновременно ей могут пользоваться десятки и сотни тысяч человек, поэтому ей некогда копаться. В хорошо сделанных БД всё молниеносно.
Сложность. Базы данных нужны в числе прочего для хранения сложно структурированных данных. Мы привыкли думать, что база данных — это такая таблица, где есть строки и столбцы. Но база данных при правильной организации может намного больше:
- Связывать одну единицу данных с множеством других. Например, если один человек совершил много заказов со множеством товаров внутри каждого, база данных способна хранить и обрабатывать такие связи.
- База может хранить дерево данных — вроде того, о котором мы писали недавно. Попробуй в реальной жизни похранить дерево!
- В базах могут жить ссылки на другие фрагменты и отделы базы.
Базу можно представить как таблицу, но лишь в самом упрощённом виде. Для более сложных задач базу можно представить как очень сложное дерево, или огромный склад упорядоченных коробок, или даже как огромный завод по фасовке данных.
Недостатки
Однако те же особенности рассматриваемых СУБД, которые стали их основными достоинствами, определяют также и их недостатки. К примеру, громоздкость и сложность логических связей — опытному специалисту при работе с ранее неизвестной базой будет трудно разобраться, а простой пользователь и вовсе в ней «заблудится». Эта сложность понимания приводит к тому, что на самом деле не так много СУБД построены на иерархической модели. Примером иерархической базы данных является, кроме уже описанного продукта компании «АйБиЭм», «Ока» и МИРИС (производство России), а также Data Edge и Team-UP (от зарубежных корпораций).
Иерархическая база данных, структура иерархических данных
Когда речь идёт о хранении иерархических данных, каждый объект хранит информацию в виде определенной сущности, и у каждой сущности могут быть родительские и дочерние элементы, а у дочерних, в свою очередь, тоже могут быть дочерние элементы. Таким образом, можно сказать, что это данные, которые подлежат строгой иерархии (представьте себе своеобразное дерево).
Простой пример иерархических данных — документ в формате XML либо файловая система компьютера.
Нельзя не упомянуть и то, что базы данных этого вида оптимизированы под чтение информации. При такой структуре данные можно быстро выбирать из нужной области, отдавая запрашиваемую информацию пользователям. Например, компьютер легко работает с конкретной папкой либо файлом, которые, по сути, можно назвать объектами структуры иерархических данных. Но когда нужно перебрать всю информацию, это может занять время (если вернуться к вышеописанному примеру, то проверка антивирусом всех уголков нашего компьютера выполняется не так быстро, как хотелось бы).
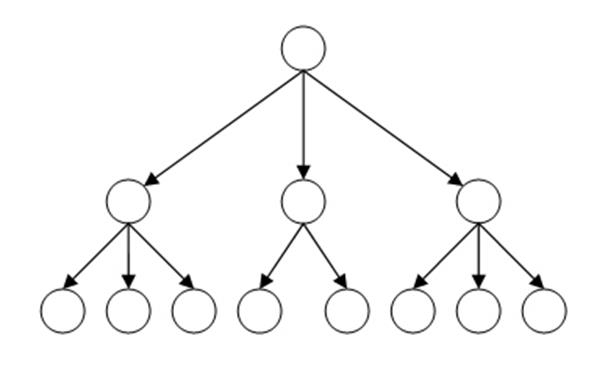
На рисунке представлена классическая структура иерархической базы данных. Вверху находится родитель (его ещё называют корневым элементом), ниже размещены дочерние элементы. Элементы с данными, находящиеся на одном уровне, можно назвать братьями либо соседними элементами. БД данной категории бывают с разным количеством уровней и разной степени вложенности.
Основные свойства типа hierarchyid
Значение типа данных hierarchyid представляет позицию в древовидной иерархии. Значения hierarchyid обладают следующими свойствами.
-
Исключительная компактность
Среднее число бит, необходимое для представления узла в древовидной структуре с n узлами, зависит от среднего количества потомков у узла. Для структур с низкой степенью ветвления (0-7) объем занимаемой памяти равен примерно 6*logA n бит, где A — среднее ветвление. Для представления узла в иерархии организации, насчитывающей 100 000 человек со средним уровнем ветвления 6, необходимо около 38 бит. Эта величина округляется до 40 бит (5 байт), которые необходимы для хранения.
-
Сравнение проводится в порядке приоритета глубины
Если заданы два значения hierarchyid — a и b, a<b означает, что значение a появляется раньше значения b, если проходить по дереву с приоритетным направлением в глубину. Индексы для типов данных hierarchyid располагаются в порядке приоритета глубины, а узлы, встречающиеся рядом при проходе по дереву с приоритетным направлением глубины, хранятся рядом друг с другом. Например, потомки некоторой записи хранятся рядом с этой записью.
-
Поддержка произвольных вставок и удалений
С помощью метода GetDescendant можно в любой момент создать одноуровневый элемент, расположенный справа от заданного узла, слева от заданного узла или между любыми двумя другими одноуровневыми элементами. Свойство сравнения сохраняется, если произвольное число узлов вставляется в иерархию или удаляется из нее. Большинство операций вставки и удаления сохраняют свойство компактности. Однако операции вставки между двумя узлами приводят к созданию значений hierarchyid, обладающих менее компактным представлением.
Поля реляционной базы данных:
Поиск информации в базе данных Доменная система имен будет завершен и начнется поиск компьютера в сети по его IP-адресу. Вообще, на связи между объектами в сетевых моделях не накладывается никаких ограничений. Сетевой базой данных фактически является Всемирная паутина глобальной компьютерной сети Интернет.
Организация данных в СУБД иерархического типа определяется в терминах: элемент, агрегат, запись (группа), групповое отношение, база данных. Обычно каждому элементу при описании базы данных присваивается уникальное имя. По этому имени к нему обращаются при обработке. Использование записей позволяет за одно обращение к базе получить некоторую логически связанную совокупность данных. Для групповых отношений в иерархической модели обеспечивается автоматический режим включения и фиксированное членство.
Поиск информации в такой иерархической распределенной базе данных ведется следующим образом. Сетевая база данных является обобщением иерархической за счет допущения объектов, имеющих более одного предка. Также, трудно представить не-иерархические данные при использовании этой модели. Иерархической базой данных является Каталог папок Windows, с которым можно работать, запустив Проводник.
Виды баз данных
Как известно, различают четыре вида посторения БД:
- Реляционные — табличные СУБД, где информация представлена в виде строк-столбцов. По этому принципу строятся базы данных в «Аксесе», к примеру.
- Объектно-ориентированные — тесно связаны с ООП (программированием, в котором идет работа с объектами), и это их главный плюс, но, учитывая их небольшую производительность, они пока значительно уступают в распространенности реляционным.
- Гибридные — СУБД, вмещающие в себе сразу два указанных выше вида.
- Иерархические — объект внимания данной статьи. Это БД, характеризирующиеся древообразной структурой.
Наиболее известным примером иерархической базы данных является продукт, созданный компанией IBM («АйБиЭм»), под названием Information Management System (переводится как «Информационная система управления»), сокращенно IMS. Первая версия IMS вышла еще в прошлом, двадцатом веке, в шестьдесят восьмом году. Она используется для хранения и контроля данных и поныне.
Недостатки
К основным недостаткам иерархических моделей следует отнести: неэффективность, медленный доступ к сегментам данных нижних уровней иерархии, четкая ориентация на определенные типы запросов и др. Также недостатком иерархической модели является ее громоздкость для обработки информации с достаточно сложными логическими связями, а также сложность понимания для обычного пользователя. Иерархические СУБД быстро прошли пик популярности, которая обусловливалась их ранним появлением на рынке. Затем их недостатки сделали их неконкурентоспособными, и в настоящее время иерархическая модель представляет исключительно исторический интерес.
Управляющая часть иерархической модели
В рамках иерархической модели выделяют языковые средства описания данных (ЯОД) и средства манипулирования данными (ЯМД). Каждая физическая база описывается набором операторов, обусловливающих как её логическую структуру, так и структуру хранения БД. При этом способ доступа устанавливает способ организации взаимосвязи физических записей.
Определены следующие способы доступа:
- иерархически последовательный;
- иерархически индексно-последовательный;
- иерархически прямой;
- иерархически индексно-прямой;
- индексный.
Помимо задания имени БД и способа доступа описания должны содержать определения типов сегментов, составляющих БД, в соответствии с иерархией, начиная с корневого сегмента. Каждая физическая БД содержит только один корневой сегмент, но в системе может быть несколько физических БД.
Среди операторов манипулирования данными можно выделить операторы поиска данных, операторы поиска данных с возможностью модификации, операторы модификации данных. Набор операций манипулирования данными в иерархической БД невелик, но вполне достаточен.
Как хранится информация в БД
В основе всей структуры хранения лежат три понятия:
- База данных;
- Таблица;
- Запись.
База данных
База данных — это высокоуровневное понятие, которое означает объединение совокупности данных, хранимых для выполнения одной цели.
Если мы делаем современный сайт, то все его данные будут храниться внутри одной базы данных. Для сайта онлайн-дневника наблюдений за погодой тоже понадобится создать отдельную базу данных.
Таблица
По отношению к базе данных таблица является вложенным объеком. То есть одна БД может содержать в себе множество таблиц.
Аналогией из реального мира может быть шкаф (база данных) внутри которого лежит множество коробок (таблиц).
Таблицы нужны для хранения данных одного типа, например, списка городов, пользователей сайта, или библиотечного каталога.
Таблицу можно представить как обычный лист в Excel-таблице, то есть совокупность строк и столбцов.
Наверняка каждый хоть раз имел дело с электронными таблицами (MS Excel).
Заполняя такую таблицу, пользователь определяет столбцы, у каждого из которых есть заголовок. В строках хранится информация.
В БД точно также: создавая новую таблицу, необходимо описать, из каких столбцов она состоит, и дать им имена.
Запись
Запись — это строка электронной таблицы.
Это неделимая сущность, которая хранится в таблице. Когда мы сохраняем данные веб-формы с сайта, то на самом деле добавляем новую запись в какую-то из таблиц базы данных. Запись состоит из полей (столбцов) и их значений. Но значения не могут быть какими угодно.
Определяя столбец, программист должен указать тип данных, который будет храниться в этом столбце: текстовый, числовой, логический, файловый и т.д. Это нужно для того, чтобы в будущем в базу не были записаны данные неверного типа.
Соберем всё вместе, чтобы понять, как будет выглядеть ведение дневника погоды при участии базы данных.
- Создадим для сайта новую БД и дадим ей название «weather_diary».
- Создадим в БД новую таблицу с именем «weather_log» и определим там следующие столбцы:
- Город (тип: текст);
- День (тип: дата);
- Температура (тип: число);
- Облачность (тип: число; от 0 (нет облачности) до 4 (полная облачность));
- Были ли осадки (тип: истина или ложь);
- Комментарий (тип: текст).
- При сохранении формы будем добавлять в таблицу weather_log новую запись, и заполнять в ней все поля информацией из полей формы.
Теперь можно быть уверенными, что наблюдения наших пользователей не пропадут, и к ним всегда можно будет получить доступ.
Реляционная база данных
Английское слово „relation“ можно перевести как связь, отношение.
А определение «реляционные базы данных» означает, что таблицы в этой БД могут вступать в отношения и находиться в связи между собой.
Что это за связи?
Например, одна таблица может ссылаться на другую таблицу. Это часто требуется, чтобы сократить объём и избежать дублирования информации.
В сценарии с дневником погоды пользователь вводит название своего города. Это название сохраняется вместе с погодными данными.
Но можно поступить иначе:
- Создать новую таблицу с именем „cities“.
- Все города в России известны, поэтому их все можно добавить в одну таблицу.
- Переделать форму, изменив поле ввода города с текстового на поле типа «select», чтобы пользователь не вписывал город, а выбирал его из списка.
- При сохранении погодной записи, в поле для города поставить ссылку на соответствующую запись из таблицы городов.
Так мы решим сразу две задачи:
- Сократим объём хранимой информации, так как погодные записи больше не будут содержать название города;
- Избежим дублирования: все пользователи будут выбирать один из заранее определённых городов, что исключит опечатки.
Связи между таблицами в БД бывают разных видов.
В примере выше использовалась связь типа «один-ко-многим», так как одному городу может соответствовать множество погодных записей, но не наоборот!
Бывают связи и других типов: «один-к-одному» и «многие-ко-многим», но они используются значительно реже.
Пример модели
Рассмотрим следующую модель данных предприятия (смотреть рисунок ниже): предприятие состоит из отделов, в которых работают сотрудники. В каждом отделе может работать несколько сотрудников, но сотрудник не может работать более чем в одном отделе.
Поэтому, для информационной системы управления персоналом необходимо создать групповое отношение, состоящее из родительской записи ОТДЕЛ (НАИМЕНОВАНИЕ_ОТДЕЛА, ЧИСЛО_РАБОТНИКОВ) и дочерней записи СОТРУДНИК (ФАМИЛИЯ, ДОЛЖНОСТЬ, ОКЛАД). Это отношение показано на рис. (а) (Для простоты полагается, что имеются только две дочерние записи).
Для автоматизации учета контрактов с заказчиками необходимо создание еще одной иерархической структуры : заказчик — контракты с ним — сотрудники, задействованные в работе над контрактом. Это дерево будет включать записи ЗАКАЗЧИК(НАИМЕНОВАНИЕ_ЗАКАЗЧИКА, АДРЕС), КОНТРАКТ(НОМЕР, ДАТА,СУММА), ИСПОЛНИТЕЛЬ (ФАМИЛИЯ, ДОЛЖНОСТЬ, НАИМЕНОВАНИЕ_ОТДЕЛА) (рис. (b)).
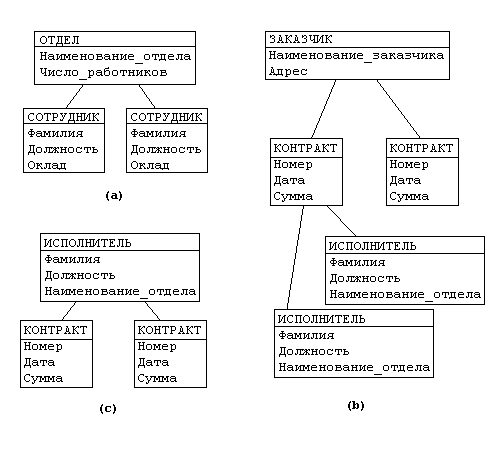
Из этого примера видны недостатки иерархических БД:
- Частично дублируется информация между записями СОТРУДНИК и ИСПОЛНИТЕЛЬ (такие записи называют парными), причем в иерархической модели данных не предусмотрена поддержка соответствия между парными записями.
- Иерархическая модель реализует отношение между исходной и дочерней записью по схеме 1:N, то есть одной родительской записи может соответствовать любое число дочерних. Допустим теперь, что исполнитель может принимать участие более чем в одном контракте (т.е. возникает связь типа M:N). В этом случае в базу данных необходимо ввести еще одно групповое отношение, в котором ИСПОЛНИТЕЛЬ будет являться исходной записью, а КОНТРАКТ — дочерней (рис. (c)). Таким образом, мы опять вынуждены дублировать информацию.
Язык манипулирования данными в сетевой модели
Все операции
манипулирования данными в сетевой модели делятся на навигационные операции
и операции модификации.
Навигационные
операции осуществляют перемещение по БД путем прохождения по связям, которые
поддерживаются в схеме БД. В этом случае результатом является новый единичный
объект, который получает статус текущего объекта.
Операции
модификации осуществляют как добавление новых экземпляров отдельных типов записей,
так и экземпляров новых наборов, удаление экземпляров записей и наборов, модификацию
отдельных составляющих внутри конкретных экземпляров записей. Средства модификации
данных сведены в табл. 3.1:
Таблица
3.1. Операторы манипулирования данными в сетевой модели
|
Операция |
Назначение |
||
|
READY |
Обеспечение |
||
|
FINISH |
Окончание работы |
||
|
FIND |
Группа операций, |
||
|
GET |
Передача найденного |
||
|
STORE |
Помещение в |
||
|
CONNECT |
Включение текущей |
||
|
DISCONNECT |
Исключение текущей |
||
|
MODIFY |
Обновление текущей |
||
|
ERASE |
Удаление экземпляра |
||
В рабочей
области пользователя хранятся шаблоны записей, программные переменные и три
типа указателей текущего состояния:
- текущая запись процесса
(код или ключ последней записи, с которой работала данная программа); - текущая запись типа
записи (для каждого типа записи ключ последней записи, с которой работала
программа); - текущая запись типа
набор (для каждого набора с владельцем Т1 и членом Т2 указывается, Т1 или
Т2 были последней обрабатываемой записью).
На рис. 3.7
представлена концептуальная модель торгово-посреднической организации.
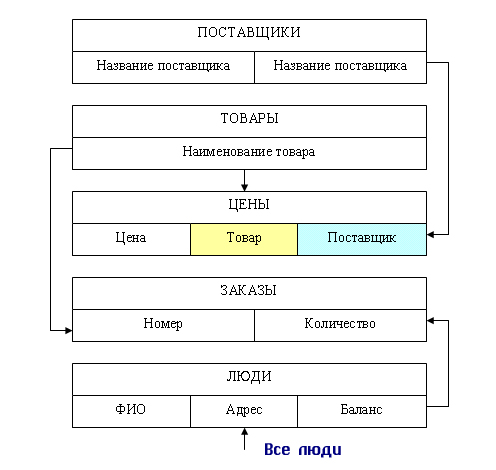
Рис.
3.7. Схема БД «Торговая фирма»
При необходимости
возможно описание элементов данных, которые не принадлежат непосредственно данной
записи, но при ее обработке часто используются. Для этого используется тип VIRTUAL
с обязательным указанием источника данного элемента данных.
RECORD Цены
02 Цена TYPE
REAL
02 Товар VIRTUAL
SOURCE IS Товары.НаименованиеТовара
OF OWNER OF
Товар-Цены SET
Наиболее
интересна операция поиска (FIND), так как именно она отражает суть навигационных
методов, применяемых в сетевой модели. Всего существует семь типов операций
поиска:
- По ключу (запись должна
быть описана через CALC USING …):FIND <Имя записи>
RECORD BY CALC KEY <Имя параметра> - Последовательный просмотр
записей данного типа:FIND DUPLICATE <Имя
записи> RECORD BY CALC KEY - Найти владельца текущего
экземпляра набора:FIND OWNER OF CURRENT
<Имя набора> SET - Последовательный просмотр
записей—членов текущего экземпляра набора:FIND (FIRST | NEXT) <Имя
записи> RECORD IN CURRENT <Имя набора> SET - Просмотр записей—членов
экземпляра набора, специфицированных рядом нолей:FIND <Имя
записи> RECORD IN CURRENT <Имя набора> SET USING <Список полей> - Сделать текущей записью
процесса текущий экземпляр набора:FIND CURRENT OF <Имя
набора> SET - Установить текущую
запись процесса:FIND CURRENT OF <Имя
записи> RECORD
Например,
алгоритм и программа печати заказов, сделанных Петровым, будут выглядеть так:
ФИО = "Петров" FIND Люди RECORD BY CALC KEY FIND FIRST Заказы RECORD IN CURRENT Люди-Заказы SET WHILE NOT FAIL DO FIND OWNER OF CURRENT Товары-Заказы SET GET Товары PRINT НаимТовара FIND NEXT Заказы RECORD IN CURRENT Люди-Заказы SET END
к алгоритмизации
алгоритмы, струкутуры данных и программирование
СУБД
ЯиМП
3GL
4GL
5GL
технологии прогр.
Знаете ли Вы, что в 1965 году два американца Пензиас (эмигрант из Германии) и Вильсон заявили, что они открыли излучение космоса. Через несколько лет им дали Нобелевскую премию, как-будто никто не знал работ Э. Регенера, измерившего температуру космического пространства с помощью запуска болометра в стратосферу в 1933 г.? Подробнее читайте в FAQ по эфирной физике.
НОВОСТИ ФОРУМАРыцари теории эфира |
Операторы поиска данных
Синтаксис:
GET UNIQUE <имя
сегмента> WHERE <список поиска>;
список поиска
состоит из последовательности условий вида:
<имя сегмента>.<имя
поля>ОС <constant или имя другого поля данного сегмента или имя переменной>:
ОС — операция
сравнения;
условия могут
быть соединены логическими операциями И и ИЛИ {& , V}.
Назначение:
Получить
единственное значение.
Пример:
Найти типовую
модель стоимостью не более $600, которая существует не менее чем в 10 экземплярах.
GET UNIQUE ТИПОВЫЕ
МОДЕЛИ
WHERE Типовые
модели.Стоимость <= $600
AND Типовые модели,Количество
на складе >= 10
Данная команда
всегда ищет с начала БД и останавливается, найдя первый экземпляр сегмента,
удовлетворяющий условиям поиска.
Синтаксис:
GET NEXT <имя
сегмента> WHERE <список аргументов поиска>
Назначение:
Получить
следующий экземпляр сегмента для тех же условии.
Пример:
Напечатать
полный список заказов стоимостью не менее $500.
GET UNIQUE ИНДИВИДУАЛЬНЫЕ
МОДЕЛИ
WHERE Индивидуальные
модели.Стоимость >- $500
WHILE NOT EAIL
(пока не конец поиска) DO
PRINT № заказа.
Стоимость, Количество
GET NEXT ИНДИВИДУАЛЬНЫЕ
МОДЕЛИ
END
Синтаксис:
GET NEXT <имя
сегмента> WITHIN PARENT
Назначение:
Получить
следующий для того же исходного.
Пример:
Получить
перечень винчестеров, имеющихся на складе номер 1, в количестве не менее 10
с объемом 10 Гбайт.
GET UNIQUE СКЛАД
WHERE Склад.Номер = 1
GET NEXT ИЗДЕЛИЕ
WITHIN PARENT
WHERE Изделие.Наименование
= «Винчестер»
GET NEXT ХАРАКТЕРИСТИКИ
WITHIN PARENT
WHERE ХАРАКТЕРИСТИКИ.Параметр
= 10 AND
ХАРАКТЕРИСТИКИ.Единицы
Измерения = Гб AND
ХАРАКТЕРИСТИКИ.Величина
> 10
While Not Fail
(пока поиск не завершен) DO
Get Next Within
Parent
end
История
Одна из первых новаторских работ по моделированию информационных систем была сделана Янгом и Кентом (1958), которые отстаивали «точный и абстрактный способ определения информационных и временных характеристик проблемы обработки данных ». Они хотели создать «нотацию, которая позволит аналитику организовать проблему вокруг любого устройства ». Их работа была первой попыткой создать абстрактную спецификацию и инвариантную основу для разработки различных альтернативных реализаций с использованием различных аппаратных компонентов. Следующий шаг в моделировании ИБ был сделан CODASYL , консорциумом ИТ-индустрии, образованным в 1959 году, который, по сути, стремился к тому же, что и Янг и Кент: разработка «надлежащей структуры для машинно-независимого языка определения проблем на системном уровне. обработки данных ». Это привело к развитию специальной информационной алгебры ИБ .
В 1960-х годах моделирование данных приобрело большее значение с появлением концепции информационной системы управления (MIS). По словам Леондеса (2002), «в это время информационная система предоставляла данные и информацию для целей управления. Система баз данных первого поколения , получившая название Integrated Data Store (IDS), была разработана Чарльзом Бахманом из General Electric. Две известные базы данных модели, сетевая модель данных и иерархическая модель данных , были предложены в течение этого периода времени «. К концу 1960-х Эдгар Ф. Кодд разработал свои теории организации данных и предложил реляционную модель для управления базами данных, основанную на логике предикатов первого порядка .
В 1970-х годах моделирование отношений сущностей возникло как новый тип концептуального моделирования данных, первоначально предложенный в 1976 году Питером Ченом . Модели сущностных отношений использовались на первом этапе проектирования информационной системы во время анализа требований для описания информационных потребностей или типа информации, которая должна храниться в базе данных . Этот метод может описывать любую онтологию , т. Е. Обзор и классификацию концепций и их взаимосвязей для определенной области интересов .
В 1970 — е годы GM Nijssen разработала «Natural Language Information Analysis Method» метод (Niam), и разработали это в 1980 — х годах в сотрудничестве с Терри Halpin в объектно-Роль моделирования (ORM). Однако именно докторская диссертация Терри Халпина в 1989 году создала формальную основу, на которой основано объектно-ролевое моделирование.
Билл Кент в своей книге 1978 года « Данные и реальность» сравнил модель данных с картой территории, подчеркнув, что в реальном мире «шоссе не окрашены в красный цвет, у рек нет линий графств, проходящих посередине, и вы не вижу контурных линий на горе ». В отличие от других исследователей, которые пытались создать математически чистые и элегантные модели, Кент подчеркивал существенную беспорядок в реальном мире и задачу разработчика моделей данных — создать порядок из хаоса без чрезмерного искажения истины.
В 1980-х годах, согласно Яну Л. Харрингтону (2000), «развитие объектно-ориентированной парадигмы привело к фундаментальным изменениям в нашем подходе к данным и процедурам, которые работают с ними. Традиционно данные и процедуры были хранятся отдельно: данные и их взаимосвязь в базе данных, процедуры в прикладной программе. Однако объектная ориентация объединила процедуру сущности с ее данными ».
В начале 1990-х годов три голландских математика Гвидо Бакема, Харм ван дер Лек и Ян Питер Цварт продолжили развитие работы Г. М. Нейссена . Они больше сосредоточились на коммуникационной части семантики. В 1997 году они формализовали метод полностью коммуникационно-ориентированного информационного моделирования FCO-IM .