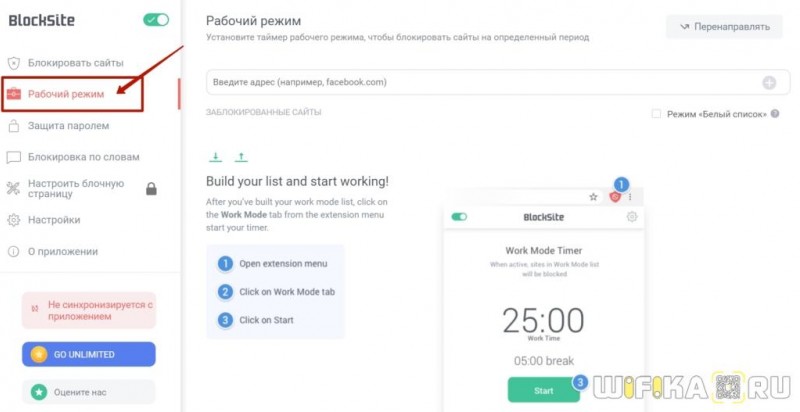
Как скачать сайт целиком
Содержание:
Цензура и другие угрозы
Archive.org в настоящее время заблокирован в Китае . После того, как террористическая организация «Исламское государство» была запрещена, Интернет-архив был полностью заблокирован в России в течение короткого периода в 2015–2016 годах, в котором размещалось информационное видео этой организации. С 2016 года веб-сайт вернулся и стал доступен полностью, хотя местные коммерческие лоббисты подали иск против Интернет-архива в местный суд, чтобы запретить его на основании авторских прав.
Элисон Макрина , директор проекта «Библиотечная свобода», отмечает, что «библиотекари глубоко ценят личную неприкосновенность частной жизни, но мы также категорически против цензуры».
Известны редкие случаи, когда интернет-доступ к контенту, который «напрасно» подвергал опасности людей, был отключен веб-сайтом.
Другие угрозы включают стихийные бедствия, разрушение (удаленное или физическое), манипуляции с содержимым архива (см. Также: кибератаки , резервное копирование ), проблемные законы об авторском праве и наблюдение за пользователями сайта.
Александр Роуз, исполнительный директор Long Now Foundation , подозревает, что в долгосрочной перспективе несколько поколений «почти ничего» выживут полезным способом, заявляя: «Если у нас будет преемственность в нашей технологической цивилизации, я подозреваю, что многие голые данные останутся доступными для поиска и поиска. Но я подозреваю, что почти ничто из формата, в котором они были доставлены, не будет узнаваемым «, потому что сайты» с глубокими внутренними системами управления контентом, такими как Drupal, Ruby и Django «труднее архив.
В статье, посвященной сохранению человеческих знаний, The Atlantic отметила, что Интернет-архив, который описывает себя как построенный на долгосрочную перспективу, «яростно работает над сбором данных до того, как они исчезнут без какой-либо долгосрочной инфраструктуры. из.»
Что если сохраненной страницы нет?
Иногда в выдаче при нажатии на зеленую стрелку отсутствует пункт «Сохраненная копия». Этому может быть несколько причин:
- Иногда некоторые браузеры, в которых установлены плагины для блокировки рекламы, могут не отображать эту ссылку. Стоит попробовать приостановить плагин или удалить его и просмотреть сайт снова;
- Яндекс вообще не гарантирует попадание страницы сайта в сохраненные копии. То есть если ресурса нет, значит по какой-то причине поисковик решил не делать резервной копии. Ничего страшного, стоит проверить, не сохранила ли страницы сайта другая поисковая система — например, Google;
- Сайт отказал поисковым роботам в индексации своих страниц. Файл robots.txt, который может лежать в корне сайта, содержит инструкции для поисковых роботов, каким образом они должны сканировать его. Например, он может содержать требование не сканировать сайт совсем или сканировать только отдельные его страницы;
- Схожая с предыдущим пунктом причина. В html коде веб-ресурса может быть указан мета-тег Robots с атрибутом noarchive. Эта директива запрещает поисковому роботу делать копию сохраненной страницы.

Как архивировать фото, видео и Истории
Чтобы добавить какой-либо медиафайл в Архив, пользователь должен:
- Открыть публикацию на своей странице – нажать три точки сверху.
- В выпадающем меню: «Архивировать».
После, можно посмотреть архивированные фото перейдя в соответствующий раздел. Найти архив с заранее архивированными фото в Инстаграме проще по датам и снимку, который был добавлен.
С помощью такой функции, в памяти учетной записи сохраняются фотографии сроком более одного года. Вернуть архивированные фото в Инстаграме возможно в любой момент, когда пользователь захочет разнообразить Ленту.
В настройках Истории доступно два параметра: сохранять в Архив и на смартфона. Но все публикации, которые ранее не были отмечены как архивируемые, добавлены в раздел не будут. Их нельзя восстановить или найти в Архиве Инстаграма.
В Архив можно добавить:
- фотографии. Публикации из Ленты с описанием, геолокацией и комментариями;
- Stories. Любые записи: начиная от целого набора коротких видео и заканчивая изображениями;
- видео. Вне зависимости от продолжительности и качества;
- карусели. Фото и видео альбомы, которые были добавлены на страницу.
При архивировании сохраняются лайки и комментарии. Но информация из статистики будет утеряна. Восстанавливая архивированные фото в Инстаграме, информация о количестве ранее просмотревших удаляется.
Сайт клуба программистов Новосибирского Государственного Университета Octopus
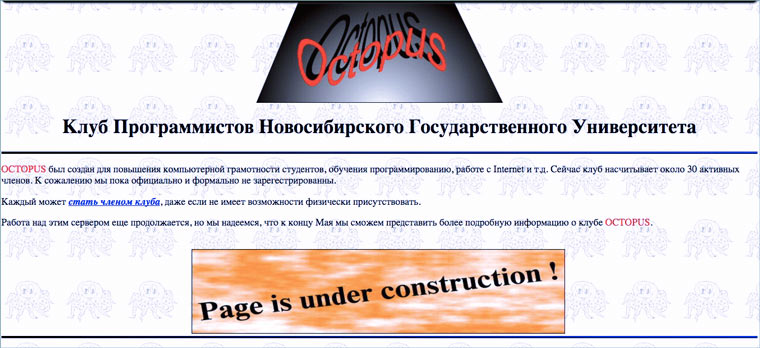
Многие сайты тех лет создавались следующим образом: собиралась группа энтузиастов в каком-нибудь научно-техническом учреждении (где был доступ к интернету) и создавали страницу с кратким рассказом о себе. Часто такие сайты оставались в полуготовом состоянии. Ведь тогда не было четкого видения как нужно делать сайт, зачем и, главное, для кого.
«Работа над этим сервером еще продолжается, но мы надеемся, что к концу Мая сможем представить более подробную информацию о клубе Octopus» — различные вариации подобной надписи встречаются в 1996 году на каждом углу. Сайт тогда часто называли сервером, а простую страницу с текстом верстали неделями (по самоучителю html и в свободное от работы время).
Сохраненная страница: 6 апреля 1997 года.
r-tools.org

Первое, что бросается в глаза дизайн сайта стороват. Ребята, пора обновлять!
Плюсы:
- Подходит для парсинга сайтов у которых мало html страниц и много ресурсов другого типа. Потомучто они рассчитывают цену по html страницам
- возможность отказаться от сайта, если качество не устроило. После того как система скачала сайт, вы можете сделать предпросмотр и отказаться если качество не устроило, но только если еще не заказали генерацию архива. (Не проверял эту функцию лично, и не могу сказать на сколько хорошо реализован предпросмотр, но в теории это плюс)
- Внедрена быстрая интеграция сайта с биржей SAPE
- Интерфейс на русском языке
Минусы:
- Есть демо-доступ — это плюс, но я попробовал сделать 4 задания и не получил никакого результата.
- Высокие цены. Парсинг 25000 стр. обойдется в 2475 руб. , а например на Архивариксе 17$. Нужно учесть, что r-tools считает html страницы, архиварикс файлы. Но даже если из всех файлов за 17$ только половина html страницы, все равно у r-tools выходит дороже. (нужно оговориться, что считал при $=70руб. И возможна ситуация, когда r-tools будет выгоден написал про это в плюсах)
Инструкция по получению уникальных статей с вебархива
1. Запускаем ваш любимый браузер и вводим адрес web.archive.org.
Главная страница вебархива, где будем искать статьи
2. В поисковой строке набираем интересующую вас тематику, например «траляля»
3. Смотрим выдачу сайтов из вебархива
4. Анализируем домены по следующим признакам
4.1. Количество страниц в вебархиве должно быть больше 50
Выдача вебархива, где можно увидеть сколько страниц в архиве
4.2. Проверяем сайт на работоспособность, для этого копируем домен и вставляем в адресную строку браузера. В нашем случае это домен www.generix.com.ua, он оказался свободен.
4.3. Если же домен будет занят и на нем будет находится сайт по схожей тематике то повторите пункты 4.1 и 4.2
4.4. Проверяем таким образом все домены в выдаче вебархива и сохраняем в блокнот те домены которые нам подходят.
5. Скачиваем программу Web Archive Downloader и с помощью нее сохраняем на компьютер архивные копии сайтов, более подробно по работе с программой вы можете ознакомиться в разделе FAQ.
6. Проверяем полученные статьи на уникальность (как читайте ниже)
7. Используем полученные уникальные статьи по назначению
В принципе все, как вы видите ничего сложного нет, осталось разобраться как проверять статьи на уникальность массово. Ведь вы скачаете их
большое количество.
Макеты из архива, как бюджетное решение для нового проекта
Очень много встречается лэндингов (landing page). Сейчас существует множество сервисов предлагающих за арендную плату воспользоваться конструктором для построения целевых страниц под контекстную рекламу. Но зачем платить ежемесячно, когда можно заплатить один раз и получить готовое решение, проверенное кем-то на практике. Более того, если на сайте были установлены счетчики, вы можете их восстановить на своем аккаунте и посмотреть какой трафик был в прошлом.
Макеты можно использовать как уникальный дизайн для своего веб-проекта. И в итоге он может оказаться ничем не хуже чем дизайн за $1000. А тем более учитывая стоимость восстановления в ~$4, вы получаете его уже с готовой html-версткой.
Альтернативы сохраненной копии Яндекса
Яндекс — не единственный поисковик в мире. Просто он лучше адаптирован и ориентирован больше на русскоязычный сегмент интернета. Тем не менее, всегда есть альтернативные способы найти копию своего сайта в интернете:
- Google. Полный аналог Яндекс и по функционалу, и по возможности найти резервную копию сайта. Найти ее можно точно так же, как в российском поисковике — нажав стрелочку рядом с выбранным пунктом выдачи и открыв пункт «Сохраненная копия».
- Web.archive.org. Огромная база сохраненных сайтов с просторов всего интернета. Вероятность попадания туда относительно молодого сайта крайне мала, однако она есть.
- CachedView.com. Это поисковик по сохраненным копиям на различных ресурсах, в том числе и в Google.

Естественно, не стоит игнорировать и менее известные поисковые системы. Это может быть Рамблер, Yahoo, поиск от Mail.ru, Bing, Апорт. Возможно, кто-то из них закэшировал нужный веб-ресурс.
Специальные программы для скачивания сайтов
Разработчики приложений создают специальные программы, которые позволяют быстро скачать необходимый сайт в интернете. Для этого нужно знать, какие утилиты лучше применять, принципы их работы и прочие нюансы.
HTTrack WebSite Copier
Это приложение является лучшим среди бесплатных программ для сохранения интернет-страничек в оффлайн режиме. Скачать его можно с официального сайта разработчика или на других порталах.
Как пользоваться утилитой:
- для начала нужно скачать приложение на компьютер, установить и запустить;
- появится окно с настройками, где нужно будет выбрать язык, среди перечисленных вариантов выделяем русский;
- после этого откроется окно, где нужно подписать проект, указать категорию и место для загрузки сайта;
- далее, в специальной графе вводим адрес самого сайта для скачивания.
Через несколько минут программа автоматически загрузит все данные из веб-страницы в указанную папку на компьютере. Информация будет доступна в off-line режиме в файле index.htm.
Сама по себе утилита проста в использовании, интерфейс несложный, сможет разобраться любой пользователь. Есть возможность настроить программу под себя, например, запретить скачивать картинки с сайта или отметить только желаемые страницы. Среди плюсов можно выделить: бесплатную версию, простой интерфейс, быстрое сохранение сайта. Минусов не обнаружено, так как утилита имеет большое количество положительных отзывов со всего мира.
Teleport Pro
Продолжает список лучших программ Teleport Pro. Это одно из самых старых приложений, которое позволяет скачать сайт на компьютер. По сравнению с прошлой утилитой, эта программа платная, ее стоимость на официальном портале составляет $50. Для тех, кто не хочет платить, есть тестовая версия, которая даст возможность пользоваться приложением определенный период времени.
После скачивания и установки откроется главное окно утилиты, там нужно указать параметры для сохранения сайта. Предлагается выбрать такие варианты: сохранить загружаемую копию, дублировать портал, включая структуру, сохранить определенный тип файлов, сохранить все интернет-ресурсы, связанные с источником, загрузить файлы по указанным адресам, скачать страницы по ключевым словам.
Далее создается новый проект, где указывается адрес самого сайта, а также папка для сохранения данных. Чтобы запустить программу, нужно нажать на кнопку «Start». Оффлайн доступ к файлам сайта будет открыт уже через несколько минут.
https://youtube.com/watch?v=Q3n9vsrE9P4
Положительные стороны приложения – простота в использовании, удобное и быстрое скачивание. Среди минусов стоит выделить платную версию, которую смогут купить далеко не все пользователи.
Offline Explorer Pro
На этом список программ для скачивания сайтов не заканчиваются. Есть еще одна платная утилита, которая имеет большое количество функций и возможностей. На официальном сайте можно скачать бесплатную версию, но она будет иметь ряд ограничений на сохранение файлов. Полная версия приложения делиться на три пакета: Standard, Pro и Enterprise. Стоимость стандартной утилиты обойдется в $60, а с расширением Pro – $600.
Как и в большинстве программ, процесс скачивания начинается с создания нового проекта. Там вводится название, веб-адрес, необходимая папка на компьютере. Также сеть большое количество настроек, которые позволяют скачать только самую нужную информацию. Предлагается сохранить только текст или с картинками. Программисты и разработчики сайтов точно ее оценят.
После регулировки параметров нужно нажать на кнопку «Загрузка», и утилита начнет сохранять файлы на ПК. Скачивание длится недолго, уже через несколько минут данные сайта будут в папке. Преимущества – многофункциональность, доступна русская версия, быстрая загрузка. Недостатки – только платная версия, которая стоит недешево.
Webcopier
Еще одно платное приложение, которое имеет бесплатную версию, действующую 15 дней. Процесс работы похож на предыдущие программы. Необходимо создать новый проект, заполнить информацию о сайте, ввести адрес и указать папку для загрузки. Нажатие кнопки «Start download» позволит запустить работу утилиты. Скорость скачивания среднее, ниже, чем у других программ. Приобрести полную версию можно за $40.
Плюсы – приятный интерфейс, удобные настройки, простое управление.
Минусы – платная версия.
Просмотр копии страницы в поисковиках
Зная алгоритмы работы поисковых роботов, можно использовать их возможности в своих целях. Каждый созданный сайт, попадает в Яндекс и Гугл не сразу. Он размещается на специальном сервере и ждет, пока поисковик найдет его и добавит в свою базу. Такие обходы поисковые системы выполняют в среднем один раз в 14 дней. Во время этого процесса они не только добавляют в свою базу новые сайты, но удаляют неработающие. Это значит, что если страничка ВКонтакте была удалена совсем недавно, то возможно ее копия еще сохранилась на серверах поисковиков.
- Скопируйте адрес страницы, которую нужно найти, из адресной строки браузера.
- Вставьте эту ссылку в поисковую строку Яндекса или Гугла и нажмите «Поиск».
- Если страница все еще храниться в поисковике, то она будет первой в результатах выдачи. Справа от ссылки находится еле заметный треугольник. Нажмите на него.
- В открывшемся меню выберите «Сохранённая копия».

Перед вами откроется последняя версия страницы, которую сохранил Яндекс или Гугл. Сохраните фото, видео и всю прочую необходимую информацию себе на компьютер, так как совсем скоро сохраненная копия будет удалена с серверов поисковых машин.
Кто такой Тим Бернерс Ли

У Бернерса Ли идеальный образ значимой фигуры в IT-индустрии.
Он знаком с технологиями с детства. Его родители были математиками и занимались разработкой одного из первых компьютеров в мире «Марк I».
Учась в Оксфордском королевском колледже, Тим устроил хакерскую атаку на учебное заведение. За это ему запретили пользоваться университетскими десктопами.
 Ломал сетку, до того как это стало мэйнстримом.
Ломал сетку, до того как это стало мэйнстримом.
С начала запуска Веба британец настаивал, что интернет должен быть общедоступным и децентрализованным.
Он даже не попытался заработать на правах на технологию и отказался патентовать ее.
«Если бы эта технология была проприетарной, и я полностью ее контролировал, она бы, скорее всего, не взлетела. Невозможно предложить то, что было бы общедоступным, и при этом вы сохранили контроль над ним», — говорил ученый.
 Тим Бернерс Ли слева, Роберт Кайо справа
Тим Бернерс Ли слева, Роберт Кайо справа
Помимо причастности к созданию первого сайта, Тим Бернерс Ли считается изобретателем URI, URL, HTTP и HTML. Именно эти технологии можно найти в info.cern.ch.
Если точнее, Бернерс Ли придумал:
язык разметки HTML для создания веб-страниц
протокол HTTP для передачи данных в Вебе
систему унифицированных адресов ресурсов URL для поиска документа или страницы
Эти технологии применяются в интернете и сейчас.
Зачем нужна информация об истории сайта в прошлом
Историю любого сайта можно посмотреть в интернете. Для этого достаточно, чтобы ресурс существовал хотя бы пару дней. Это может понадобиться в следующих случаях:
- Если необходимо купить домен, который уже был в использовании, и нужно посмотреть контент какой тематики был на нем размещен, не было ли огромного количества рекламы, исходящих ссылок и т.д.
- Нужен уникальный контент. Его можно скачать с существовавших когда-то ресурсов. Такое наполнение подойдет, например, для сайта-сателлита.
- Нужно восстановить сайт, когда нет его бэкапа.
- Нужно проанализировать конкурентов. Этот способ понадобится чтобы посмотреть историю изменений на их сайтах, какие ошибки они допускали или, наоборот, какие “фишки” стоит позаимствовать.
- Необходимо посмотреть страницу, если она теперь недоступна напрямую.
- Интересно , как выглядел ресурс 10-20 лет назад.
Ниже приведен пример того, как выглядела стартовая страница поисковой системы Яндекс в 2000 году:

Всемирный Веб архив сайтов интернета
Хранилище интернет-архив конечно не содержит всех страниц, которые когда-либо были созданы. Но шанс найти интересующий вас сайт и его архивную копию достаточно велик.
Самый мощный архив веб-сайтов доступен на Archive.org по адресу www.archive.org. Он индексирует веб, виде-, аудио и текстовые материалы, которые доступны в интернете.
Запустите ваш любимый веб-браузер и введите www.archive.org в адресной строке . Через некоторое время вы увидите главную страницу сайта интернет-архива. Она разделена на несколько частей. Каждая часть позволяет искать различный тип контента.
Раздел видео, содержит на момент написания статьи более 830 тысяч фильмов.
Раздел аудио, включает в себя более 2 миллионов записей, при это доступен еще раздел живой музыки, который насчитывает около 200 тысяч прямых трансляций с концертов в Интернет.
Однако наиболее интересным и значимым разделом сайта Archive.org является раздел web-страницы. На сегодняшний день он позволяет получить доступ к более чем 349 миллиардам архивных веб-сайтов. Для данного раздела даже выделен отдельный поддомен web.

Главная страница сайта Archive.org
Уникальный контент из веб-архива
Многие коммерческие сайты через некоторое время существования закрываются. Если на них был опубликован полезный контент (экспертные статьи, аналитические обзоры и другая важная информация), то после закрытия первоисточника они могут быть востребованными. То есть, сайт уже не работает и ранее написанные статьи могут использоваться на информационных порталах (если они уникальны).
Веб-архив является очень полезным сервисом, который может пригодиться в различных ситуациях. Быстрое восстановление потерянных данных может значительно сэкономить время и финансы, если сайт подвергнется хакерской атаке или же перестанет работать из-за серьезной технической проблемы. Веб-архив дает возможность не только просматривать старые версии своего сайта, но и анализировать контент конкурентов, сохраненный в разные периоды времени.
Twitter (март 2006): привет из девяностых
Даже сервис микроблоггинга Twitter использовал Flash в силу отсутствия достойной альтернативы. И если его суть за одиннадцать с лишним лет практически не изменилась, дизайн даже близко перестал напоминать первоначальный «привет из 1990-х», став максимально лёгким. И, конечно, в логотипе появилась знаменитая птичка.

Ноябрь 2006
Apple.com (1992 год): когда яблочко падает далеко от яблони
Для мегакорпорации Apple в 1990-х Интернет был скорее вспомогательной, нежели целевой площадкой. Только в «нулевых» с развитием iTunes ситуация изменилась. Тем не менее, даже без Стива Джобса (к тому моменту покинувшего Apple и ещё не вернувшегося) компания старалась использовать это перспективное направление для создания собственной экосистемы.

1992 год
Правда, дизайн и наполнение сайта до возвращения Джобса к родным пенатам говорят о том, что попытки провалились. Apple.com превратился в заурядную площадку, полностью потеряв свою идентичность — равно как и вся компания.

Апрель 1997
Вконтакте
Чего только не скрывалось под популярным ныне доменом vk.com. Кстати, использовать его стали не сразу, изначально в контакт можно было зайти только по URL: vkontakte.ru, но потом ситуация изменилась и администрация решила облегчить нашу с вами жизнь.
Кстати, само название социальной сети стало производным от фразы, которую Павел Дуров, создатель, постоянно слышал по радио «Эхо Москвы». Она звучала как «В полном контакте с информацией».
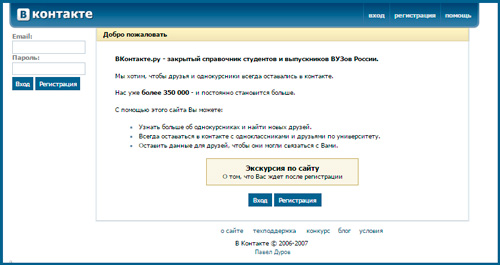
Изначально проект был создан как закрытый справочник студентов и выпускников. Об этом свидетельствует надпись на главной странице того периода.
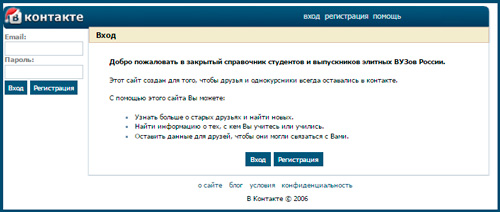
Мог ли тогда представить Павел Дуров, насколько популярным станет его проект? Сейчас даже смешно смотреть на горделивую надпись: «Нас уже 350 000». Сейчас численность проекта насчитывает миллионы.
Интересных историй о этой социальной сети предостаточно, но на мой взгляд самая впечатляющая заключается в том, что вплоть до 2014 года через Одноклассники нельзя было послать ссылку на информацию, находящуюся Вконтакте. Система не блокировала их, а просто заменяла буквы в словах.
Еще один интересный факт, о котором многие пользователи помнят. В какой-то момент администрация сайта решила поменять дизайн личных страниц. Это вызвало бурю эмоций среди пользователей.
И тут и там кипели возгласы: «Верните стену, нет микроблогу». Павел Дуров был не преклонен. В моей памяти эти воспоминания все еще свежи, а тем не менее с той поры прошло 6 лет. Военные действия разворачивались в 2010 году. Согласитесь, сейчас смотришь на этот кошмар и думаешь, что там могло нравиться, за что воевали?

Интересный момент, но благодаря социальным сетям люди не только общаются между собой и зарабатывают, но и достигают других интересных целей. Хоть в свое время дизайн стены не вернули, зато деятельность пользователей на Facebook и Вконтакте вернула в мультсериал «Гриффины» умершего пса Брайна.
Ну и на последок мне бы хотелось порекомендовать вам курс «Из зомби в интернет-предпринимателя». Становитесь популярными и вы, достигайте своих целей.

Если вы переживаете, что ничего не умеете и не знаете, просто посмотрите как изначально выглядел любой сайт, тот же Яндекс. Время решает многое. Мы растем, двигаемся вперед и учимся на своих ошибках.
Подписывайтесь на рассылку и я помогу вам справиться со сложностями. До новых встреч.
Элементы сайта-истории
Любая история – это в первую очередь повествование. История на сайте – не исключение.
Повествование складывается из следующих элементов:
- Персонаж. Выступать в качестве персонажа может продукт компании, сам бренд или что-то еще. Может быть и вымышленный персонаж, который несет в себе собирательный образ, например, целевой аудитории компании.
- Конфликт (событие). В роли конфликта могут быть какие-либо волнующие целевую аудиторию проблемы. Ситуации, в которые попадает клиент и в решении которых может помочь компания.
- Действие. Это те действия, который должен совершить клиент, чтобы решить конфликт, проблему. И в истории рассказывается, какие это должны быть действия. Тут могут быть и действия, которые совершает компания, чтобы решить проблему клиента. Часто описывается конечный результат действий, положительные эмоции от использования продукта, счастье клиента после того, как проблема решена.
Зачем нужен web archive и как его можно использовать
Веб-архивирование нужно для того, чтобы можно было восстановить важную утерянную информацию с сайта, которая может не сохраниться из-за технических проблем или повреждения вирусом.
Например, владелец сайта создал его и наполнил описанием продукции, полезными статьями и изображениями по тематике. Через время веб-ресурс был обновлен и тексты заменены на новые. А еще через время понадобились именно старые тексты. В таких случаях и нужен открытый интернет-архив, в котором можно найти десятки сохраненных версий сайта на разные даты.
Предназначение веб-архивов:
- Возможность восстановления собственного контента в случае повреждения или удаления старых текстов и изображений.
- Просмотр старых файлов на других работающих веб-сайтах.
- Анализ изменений наполнения онлайн-ресурсов (собственных и конкурентных).
Сохранение авторского контента — это важная функция. Намного проще корректировать уже имеющиеся тексты, чем писать новые с нуля. Можно сделать рерайт (переписывание текста другим словами с сохранением смысла и структуры). Особенности использования резервных копий приведены в Табл. 1.
Табл. 1. Для каких целей можно использовать более ранний контент
Сайт «Аэрофлота»

Не все первые российские сайты были «домашними поделками». Крупнейшая авиакомпания страны заказывала сайт у дизайн-студии при компании Seanet и он выглядел довольно привлекательно и гармонично, но не очень читаемо. Также присутствовала традиционная надпись «under construction», а расписание рейсов выложить пока не успели.
Точная дата создания ресурса неизвестна, но по счетчику посещений видно, что к концу октября 1996 года сайт главного авиаперевозчика страны посетили всего 12 тысяч человек. Ведь интернет тогда был редким и дорогим развлечением.
Сохраненная страница: 25 октября 1996 года.
Яndex (сентябрь 1999): разговаривайте с ним человеческим языком
Возможно, вы и не знали, но «Яндекс» для широких масс был запущен примерно на год раньше, чем Google, к тому же поначалу имевший статус beta. Поначалу блок «Горячих новостей» сопровождался сигаретным «бычком», спасибо Великому и Ужасному Дизайнеру всея Рунета, но из второй версии его (речь о «бычке») всё же убрали.
Помимо очевидных визуальных изменений обращает на себя внимание возможность выбора кодировки — актуальная для Интернета двадцатилетней давности опция. Есть ещё и таинственный раздел «Сказки» — эдакий блог разработчиков о наблюдениях в Сети и свежих достижениях
Например, из «Сказок» стало известно о возможности получать информацию по запросам, заданным естественным, а не машинным языком.

Поисковые системы
Поисковики автоматически помещают копии найденных веб‑страниц в специальный облачный резервуар — кеш. Система часто обновляет данные: каждая новая копия перезаписывает предыдущую. Поэтому в кеше отображаются хоть и не актуальные, но, как правило, довольно свежие версии страниц.
1. Кеш Google
Чтобы открыть копию страницы в кеше Google, сначала найдите ссылку на эту страницу в поисковике с помощью ключевых слов. Затем кликните на стрелку рядом с результатом поиска и выберите «Сохранённая копия».
Есть и альтернативный способ. Введите в браузерную строку следующий URL: . Замените lifehacker.ru на адрес нужной страницы и нажмите Enter.
2. Кеш «Яндекса»
Введите в поисковую строку адрес страницы или соответствующие ей ключевые слова. После этого кликните по стрелке рядом с результатом поиска и выберите «Сохранённая копия».
3. Кеш Bing
В поисковике Microsoft тоже можно просматривать резервные копии. Наберите в строке поиска адрес нужной страницы или соответствующие ей ключевые слова. Нажмите на стрелку рядом с результатом поиска и выберите «Кешировано».
4. Кеш Yahoo
Если вышеупомянутые поисковики вам не помогут, проверьте кеш Yahoo. Хоть эта система не очень известна в Рунете, она тоже сохраняет копии русскоязычных страниц. Процесс почти такой же, как в других поисковиках. Введите в строке Yahoo адрес страницы или ключевые слова. Затем кликните по стрелке рядом с найденным ресурсом и выберите Cached.
Механический метод удаления
Есть два основных типа особых приложений, предуготовленных для удаления программ. К первому типу относятся типовые деинсталляторы Windows, ко второму – деинсталляторы, которые установил сам пользователь. Дабы воспользоваться первым типом приложений, войдите в меню «Пуск», «Все программы», «Internet Explorer» и нажмите удалить либо в некоторых случаях деинсталлировать. Появится окно, жмите «Дальше» вплотную до происхождения прогресс-бара, тот, что свидетельствует о начале процедуры удаления. Примерно такой же алгорифм дозволено применять, если удалять браузер через «Панель управления». Войдите в панель, щелкните по иконке «Программы и компоненты». Откроется окно с перечнем программ, установленных на компьютере. Из них выберите «Internet Explorer», жмите удалить. Как и в предыдущем случае в правом нижнем углу клик мышкой по «Дальше» и обозреватель удалится. Перед тем как воспользоваться вторым типом деинсталляторов, установите один из них на ПК. Позже установки, перезагрузите девайс и откройте приложение. Оно выдаст все программы, которые устанавливались пользователем. Из них предпочтете, соответственно, «Internet Explorer» и щелкните «Деинсталлировать». Плюсом такой программы является то, что она не примитивно стирает приложение с компьютера, но и подчищает так называемые «хвосты» в реестре. От удаленного приложения не останется ни следа, как словно его и не устанавливали. Это, разумеется, правильно влияет на систему. Поменьше вероятности происхождения ошибок. Основной недочет – в основном все эти программы требую вступления лицензионного ключа и многие на английском языке. Если с языком хоть как то дозволено будет разобраться, то поиск бесплатного ключа в интернете – задачка трудоемкая, а его неимение вполовину уменьшает рабочий потенциал программы, либо просто делает ее неработоспособной.
Что такое исходящие ссылки
Для начала, немного теории и терминов. В SEO часто упоминаются два субъекта — донор и акцептор. Донор — это сайт, с которого ведет ссылка, акцептор, соответственно — сайт, на который ссылается донор. Исходящие ссылки — это линки, ведущие с сайта-донора на сайт-акцептор. Все очень просто. При добавлении на сайт исходящих ссылок, нужно руководствоваться некоторыми правилами и здравым смыслом. При чем здесь смысл, может спросить неопытный вебмастер? Да при том, что современные сеошники очень часто боятся исходящих ссылок, считая их вселенским злом, и пытаясь непременно закрыть от индексации даже ссылки на соцсети. Все это ерунда. Исходящие ссылки никакого вреда не несут, если сайт-акцептор — тематический, анкоры — некоммерческие, общий уровень заспамленности сайта-донора — невысокий. Более, того, ссылаясь на авторитетные ресурсы, вы только поднимете уровень доверия поисковиков к вашему ресурсу. Также, следует понимать, что если сайт — , то ни входящие, ни исходящие ссылки не помогут, нужно удалить все папочки с сервера, и не забыть про базу данных хотя бы довести его до ума в плане внутренней оптимизации.
Где взять уникальный контент для сателлитов?
Оригинальный контент, пожалуй, один из важнейших параметров для хорошего сателлита. Несколько способом его получить:
Копирайтинг:
Самый простой и самый дорогостоящий метод. Необходимо создать техническое задание и отдать его SEO-копирайтеру, который напишет для вас уникальный, оптимизированный текст. Остается только разместить его.
Рерайт :
Более практичный способ получить уникальный материал для сайта. Рерайт – это переписывание уже созданного кем-то текста. В интернете размещено огромное количество контента. Качественный рерайт также, как и копирайтинг, даст вам уникальный, читабельный материал. Такой контент будет хорошо восприниматься и посетителями, и роботами поисковых систем.
Генерация текстов по шаблонам:
Можно назвать этот способ автоматическим рерайтом текста. Позволяет получить из одного материала множество новых. В этом вам помогут сервисы онлайн-генерации текстов. Например, Seogenerator. Принцип работы строится на использовании конструкций, которые заменяют фрагменты текущего текста на заданные варианты. Вот простой пример.
Задаем шаблон:
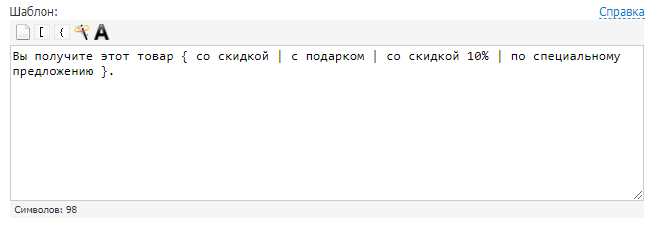
Получаем тексты:
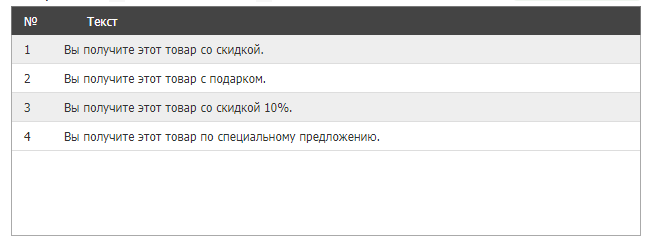
Важно следить за качеством, осмысленностью и уникальностью полученных материалов, объемные тексты проверять на возможный переспам. Вы формируете YML-выгрузку товаров
Почти все популярные CMS сегодня умеют экспортировать данные в YML-файлы. В полученную выгрузку вносите небольшие корректировки в ценах, размерах скидки, названиях товаров и используете ее для наполнения сателлита
Вы формируете YML-выгрузку товаров. Почти все популярные CMS сегодня умеют экспортировать данные в YML-файлы. В полученную выгрузку вносите небольшие корректировки в ценах, размерах скидки, названиях товаров и используете ее для наполнения сателлита.
Восстановление контента из веб-архива:
Ищем «дропы» – домены, у которых закончился срок регистрации – схожей тематики. Найти такие домены можно, например, с помощью Reg.ru. Проверяем историю, обратные ссылки, анкоры, не менялась ли тематика и т.д. Восстанавливаем нужный контент из веб-архива и получаем уникальный сайт. Для скачивания файлов из архива есть готовые сервисы, например, Archivarix. Все сайты имеют свои особенности, поэтому при восстановлении могут быть ошибки. Наш совет – заниматься восстановлением старых сайтов вместе с разработчиком.
Сохраненная копия страницы в поисковых системах Яндекс и Google
Для сохранения копий страниц понадобятся дополнительные сервисы. Поисковые системы сохраняют последние версии страниц, которые были проиндексированы поисковым роботом.
Для этого в строке поиска Яндекс вводим адрес сайта с оператором site: или url: в зависимости от того, что хотим проверить конкретную страницу или ресурс целиком. Нажимаем на стрелочку рядом с URL и выбираем «Сохраненная копия».
Откроется последняя версия страницы, которая есть у ПС. Можно посмотреть только текст, выбрав одноименную вкладку.
Посмотреть сохраненную копию конкретной страницы в Google можно с помощью оператора cache. Например, вводим cache:trinet.ru и получаем:
Вы так же можете посмотреть текстовую версию страницы.
Найти сохраненную версию страницы можно и через выдачу Google. Необходимо:
- использовать оператор site:, либо указать сразу необходимый URL
- найти страницу в выдаче
- нажать на стрелочку рядом с URL
- выбрать «Сохраненная копия»
Платформа Serpstat
С помощью этого инструмента можно посмотреть изменения видимости сайта в поисковой выдаче за год или за все время, что сайт находится в базе Serpstat.
Сервис Keys.so
Используя этот сервис можно посмотреть, сколько страниц находится в выдаче, в ТОП – 1, ТОП – 3 и т.д. Можно регулировать параметры на графике и выгружать полную статистику в Excel.