Парсинг json
Содержание:
Performance
Serialization and deserialization performance of orjson is better than
ultrajson, rapidjson, simplejson, or json. The benchmarks are done on
fixtures of real data:
-
twitter.json, 631.5KiB, results of a search on Twitter for «一», containing
CJK strings, dictionaries of strings and arrays of dictionaries, indented. -
github.json, 55.8KiB, a GitHub activity feed, containing dictionaries of
strings and arrays of dictionaries, not indented. -
citm_catalog.json, 1.7MiB, concert data, containing nested dictionaries of
strings and arrays of integers, indented. -
canada.json, 2.2MiB, coordinates of the Canadian border in GeoJSON
format, containing floats and arrays, indented.
Latency
twitter.json serialization
| Library | Median latency (milliseconds) | Operations per second | Relative (latency) |
|---|---|---|---|
| orjson | 0.59 | 1698.8 | 1 |
| ujson | 2.14 | 464.3 | 3.64 |
| rapidjson | 2.39 | 418.5 | 4.06 |
| simplejson | 3.15 | 316.9 | 5.36 |
| json | 3.56 | 281.2 | 6.06 |
twitter.json deserialization
| Library | Median latency (milliseconds) | Operations per second | Relative (latency) |
|---|---|---|---|
| orjson | 2.28 | 439.3 | 1 |
| ujson | 2.89 | 345.9 | 1.27 |
| rapidjson | 3.85 | 259.6 | 1.69 |
| simplejson | 3.66 | 272.1 | 1.61 |
| json | 4.05 | 246.7 | 1.78 |
github.json serialization
| Library | Median latency (milliseconds) | Operations per second | Relative (latency) |
|---|---|---|---|
| orjson | 0.07 | 15265.2 | 1 |
| ujson | 0.22 | 4556.7 | 3.35 |
| rapidjson | 0.26 | 3808.9 | 4.02 |
| simplejson | 0.37 | 2690.4 | 5.68 |
| json | 0.35 | 2847.8 | 5.36 |
github.json deserialization
| Library | Median latency (milliseconds) | Operations per second | Relative (latency) |
|---|---|---|---|
| orjson | 0.18 | 5610.1 | 1 |
| ujson | 0.28 | 3540.7 | 1.58 |
| rapidjson | 0.33 | 3031.5 | 1.85 |
| simplejson | 0.29 | 3385.6 | 1.65 |
| json | 0.29 | 3402.1 | 1.65 |
citm_catalog.json serialization
| Library | Median latency (milliseconds) | Operations per second | Relative (latency) |
|---|---|---|---|
| orjson | 0.99 | 1008.5 | 1 |
| ujson | 3.69 | 270.7 | 3.72 |
| rapidjson | 3.55 | 281.4 | 3.58 |
| simplejson | 11.76 | 85.1 | 11.85 |
| json | 6.89 | 145.1 | 6.95 |
citm_catalog.json deserialization
| Library | Median latency (milliseconds) | Operations per second | Relative (latency) |
|---|---|---|---|
| orjson | 4.53 | 220.5 | 1 |
| ujson | 5.67 | 176.5 | 1.25 |
| rapidjson | 7.51 | 133.3 | 1.66 |
| simplejson | 7.54 | 132.7 | 1.66 |
| json | 7.8 | 128.2 | 1.72 |
canada.json serialization
| Library | Median latency (milliseconds) | Operations per second | Relative (latency) |
|---|---|---|---|
| orjson | 4.72 | 198.9 | 1 |
| ujson | 17.76 | 56.3 | 3.77 |
| rapidjson | 61.83 | 16.2 | 13.11 |
| simplejson | 80.6 | 12.4 | 17.09 |
| json | 52.38 | 18.8 | 11.11 |
canada.json deserialization
| Library | Median latency (milliseconds) | Operations per second | Relative (latency) |
|---|---|---|---|
| orjson | 10.28 | 97.4 | 1 |
| ujson | 16.49 | 60.5 | 1.6 |
| rapidjson | 37.92 | 26.4 | 3.69 |
| simplejson | 37.7 | 26.5 | 3.67 |
| json | 37.87 | 27.6 | 3.68 |
Memory
orjson’s memory usage when deserializing is similar to or lower than
the standard library and other third-party libraries.
This measures, in the first column, RSS after importing a library and reading
the fixture, and in the second column, increases in RSS after repeatedly
calling on the fixture.
| Library | import, read() RSS (MiB) | loads() increase in RSS (MiB) |
|---|---|---|
| orjson | 13.5 | 2.5 |
| ujson | 14 | 4.1 |
| rapidjson | 14.7 | 6.5 |
| simplejson | 13.2 | 2.5 |
| json | 12.9 | 2.3 |
github.json
| Library | import, read() RSS (MiB) | loads() increase in RSS (MiB) |
|---|---|---|
| orjson | 13.1 | 0.3 |
| ujson | 13.5 | 0.3 |
| rapidjson | 14 | 0.7 |
| simplejson | 12.6 | 0.3 |
| json | 12.3 | 0.1 |
citm_catalog.json
| Library | import, read() RSS (MiB) | loads() increase in RSS (MiB) |
|---|---|---|
| orjson | 14.6 | 7.9 |
| ujson | 15.1 | 11.1 |
| rapidjson | 15.8 | 36 |
| simplejson | 14.3 | 27.4 |
| json | 14 | 27.2 |
canada.json
| Library | import, read() RSS (MiB) | loads() increase in RSS (MiB) |
|---|---|---|
| orjson | 17.1 | 15.7 |
| ujson | 17.6 | 17.4 |
| rapidjson | 18.3 | 17.9 |
| simplejson | 16.9 | 19.6 |
| json | 16.5 | 19.4 |
Reproducing
The above was measured using Python 3.8.3 on Linux (x86_64) with
orjson 3.3.0, ujson 3.0.0, python-rapidson 0.9.1, and simplejson 3.17.2.
The latency results can be reproduced using the and
scripts. The memory results can be reproduced using the script.
Пример десериализации JSON Python
На этот раз, представьте что у вас есть некие данные, хранящиеся на диске, которыми вы хотите манипулировать в памяти. Вам все еще нужно будет воспользоваться контекстным менеджером, но на этот раз, вам нужно будет открыть существующий data_file.json в режиме для чтения.
Python
with open(«data_file.json», «r») as read_file:
data = json.load(read_file)
|
1 2 |
withopen(«data_file.json»,»r»)asread_file data=json.load(read_file) |
Здесь все достаточно прямолинейно, но помните, что результат этого метода может вернуть любые доступные типы данных из таблицы конверсий
Это важно только в том случае, если вы загружаете данные, которые вы ранее не видели. В большинстве случаев, корневым объектом будет dict или list
Если вы внесли данные JSON из другой программы, или полученную каким-либо другим способом строку JSON форматированных данных в Python, вы можете легко десериализировать это при помощи loads(), который естественно загружается из строки:
Python
json_string = «»»
{
«researcher»: {
«name»: «Ford Prefect»,
«species»: «Betelgeusian»,
«relatives»:
}
}
«»»
data = json.loads(json_string)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
json_string=»»» { } data=json.loads(json_string) |
Ву а ля! Вам удалось укротить дикого JSON, теперь он под вашим контролем. Но что вы будете делать с этой силой — остается за вами. Вы можете кормить его, выращивать, и даже научить новым приемам. Не то чтобы я не доверяю вам, но держите его на привязи, хорошо?
19.2.4. Standard Compliance and Interoperability¶
The JSON format is specified by RFC 7159 and by
ECMA-404.
This section details this module’s level of compliance with the RFC.
For simplicity, and subclasses, and
parameters other than those explicitly mentioned, are not considered.
This module does not comply with the RFC in a strict fashion, implementing some
extensions that are valid JavaScript but not valid JSON. In particular:
-
Infinite and NaN number values are accepted and output;
-
Repeated names within an object are accepted, and only the value of the last
name-value pair is used.
Since the RFC permits RFC-compliant parsers to accept input texts that are not
RFC-compliant, this module’s deserializer is technically RFC-compliant under
default settings.
19.2.4.1. Character Encodings
The RFC requires that JSON be represented using either UTF-8, UTF-16, or
UTF-32, with UTF-8 being the recommended default for maximum interoperability.
As permitted, though not required, by the RFC, this module’s serializer sets
ensure_ascii=True by default, thus escaping the output so that the resulting
strings only contain ASCII characters.
Other than the ensure_ascii parameter, this module is defined strictly in
terms of conversion between Python objects and
, and thus does not otherwise directly address
the issue of character encodings.
The RFC prohibits adding a byte order mark (BOM) to the start of a JSON text,
and this module’s serializer does not add a BOM to its output.
The RFC permits, but does not require, JSON deserializers to ignore an initial
BOM in their input. This module’s deserializer raises a
when an initial BOM is present.
The RFC does not explicitly forbid JSON strings which contain byte sequences
that don’t correspond to valid Unicode characters (e.g. unpaired UTF-16
surrogates), but it does note that they may cause interoperability problems.
By default, this module accepts and outputs (when present in the original
) code points for such sequences.
19.2.4.2. Infinite and NaN Number Values
The RFC does not permit the representation of infinite or NaN number values.
Despite that, by default, this module accepts and outputs ,
, and as if they were valid JSON number literal values:
>>> # Neither of these calls raises an exception, but the results are not valid JSON
>>> json.dumps(float('-inf'))
'-Infinity'
>>> json.dumps(float('nan'))
'NaN'
>>> # Same when deserializing
>>> json.loads('-Infinity')
-inf
>>> json.loads('NaN')
nan
In the serializer, the allow_nan parameter can be used to alter this
behavior. In the deserializer, the parse_constant parameter can be used to
alter this behavior.
19.2.4.3. Repeated Names Within an Object
The RFC specifies that the names within a JSON object should be unique, but
does not mandate how repeated names in JSON objects should be handled. By
default, this module does not raise an exception; instead, it ignores all but
the last name-value pair for a given name:
>>> weird_json = '{"x": 1, "x": 2, "x": 3}'
>>> json.loads(weird_json)
{'x': 3}
The object_pairs_hook parameter can be used to alter this behavior.
19.2.4.4. Top-level Non-Object, Non-Array Values
The old version of JSON specified by the obsolete RFC 4627 required that
the top-level value of a JSON text must be either a JSON object or array
(Python or ), and could not be a JSON null,
boolean, number, or string value. RFC 7159 removed that restriction, and
this module does not and has never implemented that restriction in either its
serializer or its deserializer.
Regardless, for maximum interoperability, you may wish to voluntarily adhere
to the restriction yourself.
Простой пример в JSON
В следующем примере показано, как использовать JSON для хранения информации, связанной с книгами, в зависимости от их темы и издания.
{
"book":
}
После понимания вышеупомянутой программы мы попробуем другой пример. Давайте сохраним код ниже как json.htm —
<html>
<head>
<title>JSON example</title>
<script language = "javascript" >
var object1 = { "language" : "Java", "author" : "herbert schildt" };
document.write("<h1>JSON with JavaScript example</h1>");
document.write("<br>");
document.write("<h3>Language = " + object1.language+"</h3>");
document.write("<h3>Author = " + object1.author+"</h3>");
var object2 = { "language" : "C++", "author" : "E-Balagurusamy" };
document.write("<br>");
document.write("<h3>Language = " + object2.language+"</h3>");
document.write("<h3>Author = " + object2.author+"</h3>");
document.write("<hr />");
document.write(object2.language + " programming language can be studied " + "from book written by " + object2.author);
document.write("<hr />");
</script>
</head>
<body>
</body>
</html>
Теперь давайте попробуем открыть json.htm с помощью IE или любого другого браузера с поддержкой javascript, который выдает следующий результат:

Вы можете обратиться к главе «Объекты JSON» для получения дополнительной информации об объектах JSON.
JSON — Синтаксис
Давайте кратко рассмотрим основной синтаксис JSON. Синтаксис JSON в основном рассматривается как подмножество синтаксиса JavaScript; это включает в себя следующее —
-
Данные представлены в парах имя / значение.
-
В фигурных скобках хранятся объекты, и за каждым именем следует ‘:’ (двоеточие), пары имя / значение разделяются (запятая).
-
Квадратные скобки содержат массивы, а значения разделяются, (запятая).
Ниже приведен простой пример —
{
"book":
}
JSON поддерживает следующие две структуры данных —
-
Коллекция пар имя / значение — эта структура данных поддерживается различными языками программирования.
-
Упорядоченный список значений — включает массив, список, вектор или последовательность и т. Д.
JSON — DataTypes
Формат JSON поддерживает следующие типы данных —
| Sr.No. | Тип и описание |
|---|---|
| 1 |
номер формат с плавающей точкой двойной точности в JavaScript |
| 2 |
строка Unicode с двойными кавычками с обратной косой чертой |
| 3 |
логический правда или ложь |
| 4 |
массив упорядоченная последовательность значений |
| 5 |
Значение это может быть строка, число, истина или ложь, null т. д. |
| 6 |
объект неупорядоченный набор пар ключ: значение |
| 7 |
Пробелы может использоваться между любой парой токенов |
| 8 |
null опорожнить |
Numpy arrays¶
The array is encoded in sort-of-readable and very flexible and portable format, like so:
arr = arange(, 10, 1, dtype=uint8).reshape((2, 5))
print(dumps({'mydata' arr}))
this yields:
{
"mydata" {
"dtype" "uint8",
"shape" 2, 5],
"Corder" true,
"__ndarray__" , 5, 6, 7, 8, 9]]
}
}
which will be converted back to a numpy array when using . Note that the memory order () is only stored in v3.1 and later and for arrays with at least 2 dimensions.
As you’ve seen, this uses the magic key . Don’t use as a dictionary key unless you’re trying to make a numpy array (and know what you’re doing).
Numpy scalars are also serialized (v3.5+). They are represented by the closest python primitive type. A special representation was not feasible, because Python’s json implementation serializes some numpy types as primitives, without consulting custom encoders. If you want to preverse the exact numpy type, use .
Performance: this method has slow write times similar to other human-readable formats, although read time is worse than csv. File size (with compression) is high on a relative scale, but it’s only around 30% above binary. See this benchmark (it’s called JSONGzip). A binary alternative might be added, but is not yet available.
Сохранение данных в JSON
Чтобы записать информацию в формате JSON с помощью средств языка Python, нужно прежде всего подключить модуль json, воспользовавшись командой import json в начале файла с кодом программы. Метод dumps отвечает за автоматическую упаковку данных в JSON, принимая при этом переменную, которая содержит всю необходимую информацию. В следующем примере демонстрируется кодирование словаря под названием dictData. В нем имеются некие сведения о пользователе интернет-портала, такие как идентификационный код, логин, пароль, полное имя, номер телефона, адрес электронной почты и данные об активности. Эти значения представлены в виде обычных строк, а также целых чисел и булевых литералов True/False.
import json
dictData = { "ID" : 210450,
"login" : "admin",
"name" : "John Smith",
"password" : "root",
"phone" : 5550505,
"email" : "smith@mail.com",
"online" : True }
jsonData = json.dumps(dictData)
print(jsonData)
{"ID": 210450, "login": "admin", "name": "John Smith", "password": "root", "phone": 5550505, "email": "smith@mail.com", "online": true}
Результат выполнения метода dumps передается в переменную под названием jsonData. Таким образом, словарь dictData был преобразован в JSON-формат всего одной строчкой. Как можно увидеть, благодаря функции print, все сведения были закодированы в своем изначальном виде. Стоит заметить, что данные из поля online были преобразованы из литерала True в true.
С помощью Python сделаем запись json в файл. Для этого дополним код предыдущего примера следующим образом:
with open("data.json", "w") as file:
file.write(jsonData)
Подробнее про запись данных в текстовые файлы описано в отдельной статье на нашем сайте.
Преобразование данных JSON
В предыдущих двух разделах вы могли заметить, что список Python преобразуется в данные JSONArray, а словарь Python становится JSONObject. Итак, какой объект Python по умолчанию преобразован в объект JSON, показан в таблице ниже.
| dict | object |
| list, tuple | array |
| str | string |
| int, float, int — производные от float перечисления | number |
| True | true |
| False | false |
| None | null |
Кроме того, если вы конвертируете JSONArray, вы получите список. Так что здесь тоже есть некоторые правила. Итак, в следующих таблицах показан тип данных JSON, которые преобразуются в данные.
| object | dict |
| array | list |
| string | str |
| number (int) | int |
| number (real) | float |
| true | True |
| false | False |
Python JSON Cheat Sheet
| Python JSON Function | Description |
|---|---|
|
json.dumps(person_data) |
Create JSON Object |
|
json.dump(person_data, file_write) |
Create JSON File using File I/O of Python |
|
compact_obj = json.dumps(data, separators=(‘,’,’:’)) |
Compact JSON Object by removing space character from JSON Object using separator |
|
formatted_obj = json.dumps(dic, indent=4, separators=(‘,’, ‘: ‘)) |
Formatting JSON code using Indent |
|
sorted_string = json.dumps(x, indent=4, sort_keys=True) |
Sorting JSON object key by alphabetic order |
|
complex_obj = json.dumps(4 + 5j, default=complex_encode) |
Python Complex Object encoding in JSON |
|
JSONEncoder().encode(colour_dict) |
Use of JSONEncoder Class for Serialization |
|
json.loads(data_string) |
Decoding JSON String in Python dictionary using json.loads() function |
|
json.loads(‘{«__complex__»: true, «real»: 4, «img»: 5}’, object_hook = is_complex) |
Decoding of complex JSON object to Python |
|
JSONDecoder().decode(colour_string) |
Use of Decoding JSON to Python with Deserialization |
Command Line Interface¶
Source code: Lib/json/tool.py
The module provides a simple command line interface to validate
and pretty-print JSON objects.
If the optional and arguments are not
specified, and will be used respectively:
$ echo '{"json": "obj"}' | python -m json.tool
{
"json": "obj"
}
$ echo '{1.2:3.4}' | python -m json.tool
Expecting property name enclosed in double quotes: line 1 column 2 (char 1)
Changed in version 3.5: The output is now in the same order as the input. Use the
option to sort the output of dictionaries
alphabetically by key.
Command line options
-
The JSON file to be validated or pretty-printed:
$ python -m json.tool mp_films.json { "title": "And Now for Something Completely Different", "year": 1971 }, { "title": "Monty Python and the Holy Grail", "year": 1975 }If infile is not specified, read from .
-
Write the output of the infile to the given outfile. Otherwise, write it
to .
-
Sort the output of dictionaries alphabetically by key.
New in version 3.5.
-
Disable escaping of non-ascii characters, see for more information.
New in version 3.9.
-
Parse every input line as separate JSON object.
New in version 3.8.
-
Mutually exclusive options for whitespace control.
New in version 3.9.
-
Show the help message.
Footnotes
-
As noted in the errata for RFC 7159,
JSON permits literal U+2028 (LINE SEPARATOR) and
U+2029 (PARAGRAPH SEPARATOR) characters in strings, whereas JavaScript
(as of ECMAScript Edition 5.1) does not.
Python to JSON (Encoding)
JSON Library of Python performs following translation of Python objects into JSON objects by default
| Python | JSON |
| dict | Object |
| list | Array |
| unicode | String |
| number — int, long | number – int |
| float | number – real |
| True | True |
| False | False |
| None | Null |
Converting Python data to JSON is called an Encoding operation. Encoding is done with the help of JSON library method – dumps()
JSON dumps() in Python
json.dumps() in Python is a method that converts dictionary objects of Python into JSON string data format. It is useful when the objects are required to be in string format for the operations like parsing, printing, etc.
Now lets perform our first json.dumps encoding example with Python:
import json
x = {
"name": "Ken",
"age": 45,
"married": True,
"children": ("Alice","Bob"),
"pets": ,
"cars":
}
# sorting result in asscending order by keys:
sorted_string = json.dumps(x, indent=4, sort_keys=True)
print(sorted_string)
Output:
{"person": {"name": "Kenn", "sex": "male", "age": 28}})
Let’s see an example of Python write JSON to file for creating a JSON file of the dictionary using the same function dump()
# here we create new data_file.json file with write mode using file i/o operation
with open('json_file.json', "w") as file_write:
# write json data into file
json.dump(person_data, file_write)
Output:
Nothing to show…In your system json_file.json is created. You can check that file as shown in the below write JSON to file Python example.
Standard Compliance and Interoperability¶
The JSON format is specified by RFC 7159 and by
ECMA-404.
This section details this module’s level of compliance with the RFC.
For simplicity, and subclasses, and
parameters other than those explicitly mentioned, are not considered.
This module does not comply with the RFC in a strict fashion, implementing some
extensions that are valid JavaScript but not valid JSON. In particular:
- Infinite and NaN number values are accepted and output;
- Repeated names within an object are accepted, and only the value of the last
name-value pair is used.
Since the RFC permits RFC-compliant parsers to accept input texts that are not
RFC-compliant, this module’s deserializer is technically RFC-compliant under
default settings.
Character Encodings
The RFC recommends that JSON be represented using either UTF-8, UTF-16, or
UTF-32, with UTF-8 being the recommended default for maximum interoperability.
As permitted, though not required, by the RFC, this module’s serializer sets
ensure_ascii=True by default, thus escaping the output so that the resulting
strings only contain ASCII characters.
Other than the ensure_ascii parameter, this module is defined strictly in
terms of conversion between Python objects and
, and thus does not otherwise directly address
the issue of character encodings.
The RFC prohibits adding a byte order mark (BOM) to the start of a JSON text,
and this module’s serializer does not add a BOM to its output.
The RFC permits, but does not require, JSON deserializers to ignore an initial
BOM in their input. This module’s deserializer will ignore an initial BOM, if
present.
Changed in version 3.6.0: Older versions would raise when an initial BOM is present
The RFC does not explicitly forbid JSON strings which contain byte sequences
that don’t correspond to valid Unicode characters (e.g. unpaired UTF-16
surrogates), but it does note that they may cause interoperability problems.
By default, this module accepts and outputs (when present in the original
) codepoints for such sequences.
Infinite and NaN Number Values
The RFC does not permit the representation of infinite or NaN number values.
Despite that, by default, this module accepts and outputs ,
, and as if they were valid JSON number literal values:
>>> # Neither of these calls raises an exception, but the results are not valid JSON
>>> json.dumps(float('-inf'))
'-Infinity'
>>> json.dumps(float('nan'))
'NaN'
>>> # Same when deserializing
>>> json.loads('-Infinity')
-inf
>>> json.loads('NaN')
nan
In the serializer, the allow_nan parameter can be used to alter this
behavior. In the deserializer, the parse_constant parameter can be used to
alter this behavior.
Repeated Names Within an Object
The RFC specifies that the names within a JSON object should be unique, but
does not mandate how repeated names in JSON objects should be handled. By
default, this module does not raise an exception; instead, it ignores all but
the last name-value pair for a given name:
>>> weird_json = '{"x": 1, "x": 2, "x": 3}'
>>> json.loads(weird_json) == {'x' 3}
True
The object_pairs_hook parameter can be used to alter this behavior.
Top-level Non-Object, Non-Array Values
The old version of JSON specified by the obsolete RFC 4627 required that
the top-level value of a JSON text must be either a JSON object or array
(Python or ), and could not be a JSON null,
boolean, number, or string value. RFC 7159 removed that restriction, and
this module does not and has never implemented that restriction in either its
serializer or its deserializer.
Regardless, for maximum interoperability, you may wish to voluntarily adhere
to the restriction yourself.
Основные методы
Метод json dump
Сериализует в JSON-подобный формат записывая его в (который поддерживает ) используя эту .
Если (по умолчанию: ), тогда ключи словаря не базового типа (, , , , ) будут пропущены, вместо того, чтобы вызывать исключение .
Модуль всегда создает объекты , не . Следовательно, должен поддерживать ввод .
Когда (по умолчанию), все не-ASCII символы в выводе будут экранированы последовательностями ,. Если , эти символы будут записаны как есть.
Когда (по умолчанию: ), тогда проверка циклических ссылок для типов контейнера будет пропущена, а такие ссылки будут вызывать (или ошибку серьёзнее).
Если (по умолчанию: ), при каждой попытке сериализировать значение , выходящее за допустимые пределы (, , ), будет возникать , в соответствии с сертификацией JSON. В случае если , будут использованы JavaScript аналоги (, , ).
Когда является неотрицательным целым числом или строкой, то объекты и массивы JSON будут выводиться с этим количеством отступов. Если уровень отступа равен 0, отрицательный или , будут использоваться новые строки без отступов. (по умолчанию) отражает наиболее компактное представление. Если строка (например, ), эта строка используется в качестве отступа.
должны быть tuple . По умолчанию используется значение если и при другом значении. Чтобы получить наиболее компактное представление JSON, вы должны указать .
Значение должно быть функцией. Он вызывается для объектов, которые не могут быть сериализованы. Функция должна вернуть кодируемую версию объекта JSON или вызывать . Если не указано, возникает ошибка .
Если (по умолчанию: ), ключи выводимого словаря будут отсортированы.
Чтобы использовать собственный подкласс (например, тот который переопределяет метод для сериализации дополнительных типов), укажите его с помощью аргумента ; в противном случае используется .
Метод json dumps
Сериализирует в строку формата JSON с помощью . Аргументы имеют то же значение, что и для .
Ключи в парах ключ/значение всегда являются строками. Когда словарь конвертируется в JSON, все ключи словаря преобразовываются в строки. Если в результате, сначала конвертировать его в JSON, а потом обратно, новый в словарь может отличаться от, то можно получить словарь идентичный исходному. Другими словами, если x имеет не строковые ключи.
Метод json load
Десериализует из (текстовый или бинарный файл, который поддерживает метод и содержит JSON документ) в объект Python используя эту таблицу конвертации.
— опциональная функция, которая применяется к результату декодирования объекта. Использоваться будет значение, возвращаемое этой функцией, а не полученный словарь . Эта функция используется для реализации пользовательских декодеров (например JSON-RPC).
— опциональная функция, которая применяется к результату декодирования объекта с определенной последовательностью пар ключ/значение. Вместо исходного словаря будет использоваться результат, возвращаемый функцией. Эта функция используется для реализации пользовательских декодеров. Если задан , будет в приоритете.
В случае определения , он будет вызван для каждого значения JSON с плавающей точкой. По умолчанию, это эквивалентно . Можно использовать другой тип данных или парсер для этого значения (например )
В случае определения , он будет вызван для декодирования строк JSON int. По умолчанию, эквивалентен . Можно использовать другой тип данных или парсер для этого значения (например ).
В случае определения , он будет вызван для строк: , , . Может быть использован для вызова исключений при обнаружении недопустимых чисел JSON. больше не вызывается при .
Чтобы использовать собственный подкласс , укажите его с помощью аргумента ; в противном случае используется . Дополнительные аргументы ключевого слова будут переданы конструктору класса.
Если десериализованные данные не являются допустимым документом JSON, возникнет .
Метод json loads
Десериализует (экземпляр , или , содержащий JSON документ) в объект Python используя таблицу конвертации.
Остальные аргументы аналогичны аргументам в , кроме кодировки, которая устарела либо игнорируется.
Если десериализованные данные не являются допустимым документом JSON, возникнет ошибка .
19.2.5. Command Line Interface¶
Source code: Lib/json/tool.py
The module provides a simple command line interface to validate
and pretty-print JSON objects.
If the optional and arguments are not
specified, and will be used respectively:
$ echo '{"json": "obj"}' | python -m json.tool
{
"json": "obj"
}
$ echo '{1.2:3.4}' | python -m json.tool
Expecting property name enclosed in double quotes: line 1 column 2 (char 1)
Changed in version 3.5: The output is now in the same order as the input. Use the
option to sort the output of dictionaries
alphabetically by key.
19.2.5.1. Command line options
-
The JSON file to be validated or pretty-printed:
$ python -m json.tool mp_films.json { "title": "And Now for Something Completely Different", "year": 1971 }, { "title": "Monty Python and the Holy Grail", "year": 1975 }If infile is not specified, read from .
-
Write the output of the infile to the given outfile. Otherwise, write it
to .
-
Sort the output of dictionaries alphabetically by key.
New in version 3.5.
-
Show the help message.
Footnotes
-
As noted in the errata for RFC 7159,
JSON permits literal U+2028 (LINE SEPARATOR) and
U+2029 (PARAGRAPH SEPARATOR) characters in strings, whereas JavaScript
(as of ECMAScript Edition 5.1) does not.
Создание объектов Array
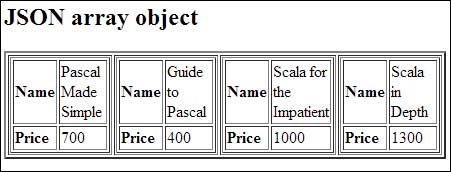
В следующем примере показано создание объекта массива в javascript с использованием JSON, сохраните приведенный ниже код как json_array_object.htm —
<html>
<head>
<title>Creation of array object in javascript using JSON</title>
<script language = "javascript" >
document.writeln("<h2>JSON array object</h2>");
var books = { " Pascal " : ,
"Scala" :
}
var i = 0
document.writeln("<table border = '2'><tr>");
for(i = 0;i<books. Pascal .length;i++) {
document.writeln("<td>");
document.writeln("<table border = '1' width = 100 >");
document.writeln("<tr><td><b>Name</b></td><td width = 50>" + books. Pascal .Name+"</td></tr>");
document.writeln("<tr><td><b>Price</b></td><td width = 50>" + books. Pascal .price +"</td></tr>");
document.writeln("</table>");
document.writeln("</td>");
}
for(i = 0;i<books.Scala.length;i++) {
document.writeln("<td>");
document.writeln("<table border = '1' width = 100 >");
document.writeln("<tr><td><b>Name</b></td><td width = 50>" + books.Scala.Name+"</td></tr>");
document.writeln("<tr><td><b>Price</b></td><td width = 50>" + books.Scala.price+"</td></tr>");
document.writeln("</table>");
document.writeln("</td>");
}
document.writeln("</tr></table>");
</script>
</head>
<body>
</body>
</html>
Теперь давайте попробуем открыть Json Array Object с помощью IE или любого другого браузера с поддержкой javaScript. Это дает следующий результат —
JSON — схема
Схема JSON — это спецификация формата на основе JSON для определения структуры данных JSON. Он был написан по проекту IETF, срок действия которого истек в 2011 году. Схема JSON —
- Описывает ваш существующий формат данных.
- Четкая, понятная человеку и машинная документация.
- Полная структурная проверка, полезная для автоматизированного тестирования.
- Полная структурная проверка, проверка данных, предоставленных клиентом.