Как посмотреть кэшированную версию сайта
Содержание:
Использование сервиса WebArchive
Всем, кто задается вопросом, где посмотреть старые версии сайтов, можно порекомендовать воспользоваться таким интересным сервисом как WebArchive.
Его функционал гораздо шире, чем у кэша поисковиков, можно просмотреть, как видоизменялся сайт за месяцы и годы своего существования, а также воспользоваться поиском по конкретному числу, когда была сохранена копия содержимого страницы.
Для того, чтобы воспользоваться сервисом, в поиске на сайте WebArchive введите адрес искомой страницы. Также поддерживается поиск по ключевым словам, относящимся к тематике ресурса — можно воспользоваться им. Как только вы это сделаете, появится статистика по годам. Черным цветом отмечено, в какое время создавалась резервная копия сайта, сохраненная в архиве.

Как только вы выберете нужный год и перейдете на него, откроется календарь, в котором можно выбрать число, за которое была сохранена резервная копия страницы сайта.
Зеленым и синим цветом отмечены даты, когда поисковые роботы заархивировали страницу и добавили ее к просмотру.
Как правило, возможность просмотра изображений отсутствует, однако текст сохраняется в полном объеме. А если вы ищете какую-либо конкретную статью на определенном ресурсе, есть вероятность, что ссылка на нее могла сохраниться.
Архивы веб-страниц, постоянные
Если вы хотите сохранять текстовый контент, то для этих целей рекомендуются Pocket и Instapaper. Вы можете сохранять страницы через электронную почту, расширения для браузеров или через приложения. Эти сервисы извлекают текстовый контент из веб-страниц и делают его доступным на всех ваших устройствах. Но вы не можете загрузить сохраненные статьи, а только прочитать их на сайте Pocket или через мобильное приложение сервиса. Дальше мы расскажем, как полностью скопировать страницу сайта.
Evernote и OneNote — это инструменты для архивирования контента в подборки. Они предоставляют в распоряжение пользователей веб-клипперы (или расширения), которые позволяют легко сохранять полные веб-страницы в один клик.
Захваченные веб-страницы могут быть доступны с любого устройства, сохраняется оригинальный дизайн и возможность поиска по странице. Эти сервисы могут даже выполнять оптическое распознавание, чтобы найти текст на фотографиях. Evernote также позволяет экспортировать сохраненные страницы как HTML-файлы, которые можно загрузить в другом месте.
Если нужен быстрый и простой доступ к веб-страницам, то сохраняйте их в виде PDF-файлов. Перед тем, как скопировать страницу сайта в виде картинки, выберите правильный инструмент.
Google Chrome имеет встроенный PDF-конвертер. Также можно использовать Google Cloud Print. На сервис добавлен новый виртуальный принтер «Сохранить в Google Drive». В следующий раз, когда вы будете печатать страницу на компьютере или мобильном устройстве через Cloud Print, вы сможете сохранить ее PDF-копию в Google Drive. Но это не лучший вариант сохранения страниц со сложным форматированием.
Когда важно сохранить дизайн, то лучше всего использовать скриншотер. Выбор подобных программ довольно велик, но я бы рекомендовал официальное дополнение Chrome от Google
Оно не только захватывает полные скриншоты веб-страниц, но также загружает полученное изображение на Google Drive. Дополнение может сохранять веб-страницы в формате веб-архива (MHT), который поддерживается в IE и Firefox.
Wayback Machine на Internet Archive — это идеальное место для поиска предыдущих версий веб-страницы. Но этот же инструмент можно использовать, чтобы скопировать страницу сайта и сохранить ее. Перейдите на archive.org/web и введите URL-адрес любой веб-страницы. Архиватор скачает на сервер ее полную копию, включая все изображения. Сервис создаст постоянный архив страницы, который выглядит так же, как оригинал. Он останется на сервере, даже если исходная страница была переведена в автономный режим.
Internet Archive не предоставляет возможности загрузки сохраненных страниц, но для этого можно использовать Archive.Is. Этот сервис очень похож на archive.org в том, что вы вводите URL-адрес страницы, и он создает на своем сервере точный ее снимок. Страница будет сохранена навсегда, но здесь есть возможность загрузить сохраненную страницу в виде ZIP-архива. Сервис также позволяет создавать архивы по дате. Благодаря чему вы можете получить несколько снимков одной и той же страницы для разных дат.
Все популярные браузеры предоставляют возможность загрузить полную версию веб-страницы на компьютер. Они загружают на ПК HTML страницы, а также связанные с ней изображения, CSS и JavaScript. Поэтому вы сможете прочитать ее позже в автономном режиме.
Теперь разберемся, как полностью скопировать страницу сайта на электронную читалку. Владельцы eReader могут использовать dotEPUB, чтобы загрузить любую веб-страницу в формате EPUB или MOBI. Данные форматы совместимы с большинством моделей электронных книг. Amazon также предлагает дополнение, с помощью которого можно сохранить любую веб-страницу на своем Kindle-устройстве, но этот инструмент в основном предназначен для архивирования текстового контента.
Большинство перечисленных инструментов позволяют загружать одну страницу, но если вы хотите сохранить набор URL-адресов, решением может стать Wget. Также существует Google Script для автоматической загрузки веб-страниц в Google Drive, но таким образом можно сохранить только HTML-контент.
Данная публикация представляет собой перевод статьи «The Best Tools for Saving Web Pages, Forever» , подготовленной дружной командой проекта Интернет-технологии.ру
Еще не голосовали рейтинг из ХорошоПлохо Ваш голос принят
Просмотр копии страницы в поисковиках
Зная алгоритмы работы поисковых роботов, можно использовать их возможности в своих целях. Каждый созданный сайт, попадает в Яндекс и Гугл не сразу. Он размещается на специальном сервере и ждет, пока поисковик найдет его и добавит в свою базу. Такие обходы поисковые системы выполняют в среднем один раз в 14 дней. Во время этого процесса они не только добавляют в свою базу новые сайты, но удаляют неработающие. Это значит, что если страничка ВКонтакте была удалена совсем недавно, то возможно ее копия еще сохранилась на серверах поисковиков.
- Скопируйте адрес страницы, которую нужно найти, из адресной строки браузера.
- Вставьте эту ссылку в поисковую строку Яндекса или Гугла и нажмите «Поиск».
- Если страница все еще храниться в поисковике, то она будет первой в результатах выдачи. Справа от ссылки находится еле заметный треугольник. Нажмите на него.
- В открывшемся меню выберите «Сохранённая копия».
Перед вами откроется последняя версия страницы, которую сохранил Яндекс или Гугл. Сохраните фото, видео и всю прочую необходимую информацию себе на компьютер, так как совсем скоро сохраненная копия будет удалена с серверов поисковых машин.
Как посмотреть удаленную страницу в веб-архиве
Веб-архив – это специальный сервис, который хранит на своем сервере данные со всех страниц, которые есть в интернете. Даже, если сайт перестанет существовать, то его копия все равно останется жить в этом хранилище.
В архиве также хранятся все версии интернет страниц. С помощью календаря разрешено смотреть, как выглядел тот или иной сайт в разное время.
В веб-архиве можно найти и удаленные страницы с ВК. Для этого необходимо выполнить следующие действия.
- Зайти на сайт https://archive.org/.
- В верхнем блоке поиска ввести адрес страницы, которая вам нужна. Скопировать его из адресной строки браузера, зайдя на удаленный аккаунт ВК.

Используя интернет-архив вы, естественно, не сможете написать сообщение, также как узнать когда пользователь был в сети. Но посмотреть его последние добавленные записи и фото очень даже можно.
Страница найдена
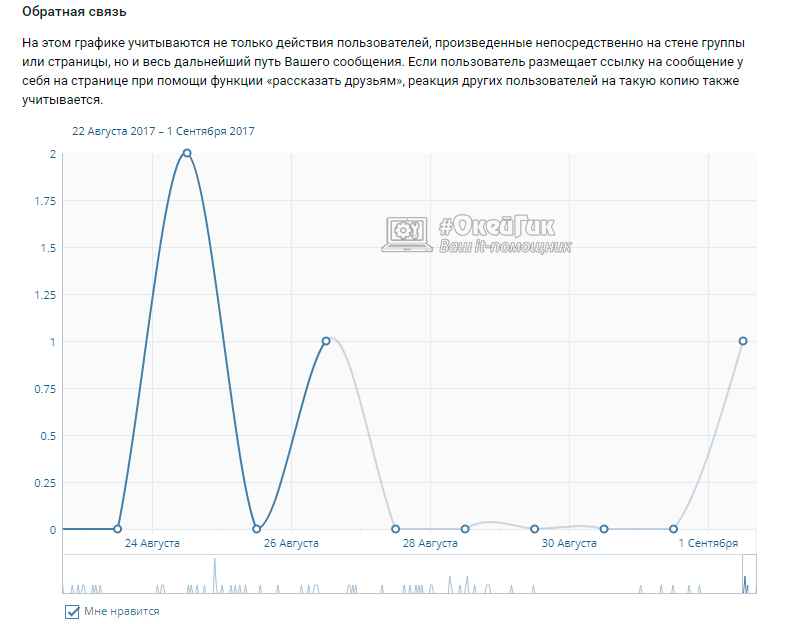
Если искомая страница сохранена на сервере веб-архива, то он выдаст вам результат в виде календарного графика. На нем будут отмечены дни, в которые вносились изменения, добавлялась или удалялась информация с профиля ВК.
Выберите дату, которая вам необходима, чтобы увидеть, как выглядела страница. Используйте стрелочки «вперед» и «назад», чтобы смотреть следующий или предыдущий день либо вернитесь на первую страницу поиска и выберите подходящее число в календаре.

Страница не найдена
Может случиться, что необходимая страница не нашлась на сайте WayBackMachine. Это не значит, что вы что-то сделали не правильно, такое часто случается. Возможно, аккаунт пользователя был закрыт от поисковиков и посторонних сайтов и поэтому не попал в архив. WayBackMachine самый популярный сайт, но он не единственный в своем роде. Попробуйте найти в Яндексе или Гугле другие веб-архиви. Искомая страница могла сохраниться на их серверах.

Попытайте удачу в поисках архивной версии профиля на этих сайтах:
Также обязательно попробуйте найти страничку на русскоязычном аналоге http://web-arhive.ru/.
Как посмотреть кеш в Google
Существует несколько способов найти удаленные страницы сайтов. Самый простой – воспользоваться стандартным поиском Google и придерживаться следующего алгоритма действий:
- В поисковой строке вводим адрес сайта, с которого нужно восстановить информацию.
- В выдаче находим нужную ссылку, а под ней – маленькую стрелку зеленого цвета.
- При нажатии на стрелку появляется меню, в котором нужно выбрать графу «Сохраненная копия».
- Система автоматически переходит в архив сайтов и открывает нужные страницы.
Если для работы в Интернете вы используете Google Chrome, вам подойдет еще один простой способ, как посмотреть удаленную страницу в кеше. Для этого достаточно перед адресом сайта ввести слово «cache» и поставить двоеточие. На примере сайта htmlbook.ru это будет выглядеть так: «cache:htmlbook.ru» и далее адрес конкретной страницы, которая вам нужна.
Если по каким-то причинам перечисленные методы не подошли, найти кеш страницы можно и таким способом:
Обратите внимание! Кеш сайта – это преимущественно текстовая информация. Если на странице были размещены изображения, которые владелец удалил, восстановить их может быть не так просто, как непосредственно статью
Что такое кэш в телефоне
Например, установив какую-нибудь онлайн-игру на устройство, кэш постепенно начнет скапливаться в памяти. В качестве кэша могут быть различные данные, которые были загружены с сервера и сохранены на накопителе. Одна из причин, по которой это может происходить – ускорение загрузки игры или приложения. Чтобы повторно не загружать с сервера нужные данные при каждом входе и используется кэширование. Необходимые файлы будут “одноразово” скачаны и сохранятся в нужном месте. В качестве еще одного примера можно привести обычный браузер.
В некоторых случаях кэш может даже вредить устройству. Программы мало обращают внимания на свободную память и охотно занимают у системы каждый мегабайт (а то и гигабайт) для своих нужд – создания новых кэш-данных. Чаще всего страдают девайсы с малым объемом внутренней памяти, она просто забивается. Иногда отсюда следует и то, что смартфон (или планшет) начинает работать медленнее из-за банальной нехватки памяти.
Создание бэкапа
Резервирование истории исключает всевозможные неприятности, связанные со случайным удалением журнала (по ошибке, в результате вирусной атаки или программного сбоя). Но, разумеется, о создании копии нужно побеспокоиться заранее. Создать бэкап и выполнить восстановление при помощи него можно различными методами.
Способ №1: копирование файла
1. Откройте профиль в директории браузера:C: → Users → → AppData → Local → Yandex → YandexBrowser → User Data → Default
2. Кликните правой кнопкой по файлу History. В списке клацните «Копировать».

3. Вставьте файл в другую папку. Желательно, чтобы она находилась в другом разделе диска (не системном!).
4. Это и будет ваш бэкап. При необходимости вы можете его снова вставить в профиль Яндекса — заменить текущий файл History.
Способ №2: резервирование утилитой hc.Historian
hc.Historian — достойная альтернатива штатному инструменту браузеров для просмотра журнала посещений. В автоматическом режиме она создаёт отдельный бэкап истории, который в любой момент можно просмотреть и использовать для восстановления. Даже в случае полного удаления браузера.
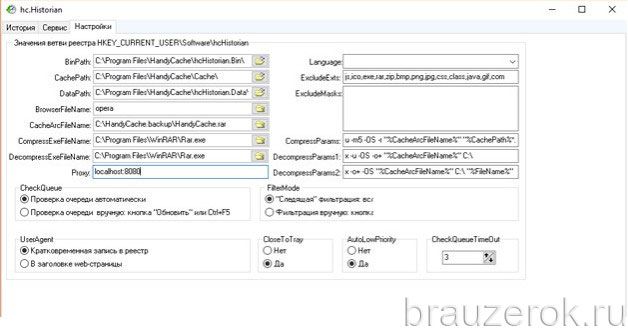
В интерфейсе утилиты можно задавать настройки резервирования (указывать директорию, архиватор для компрессии копии, а также браузер, данные которого нужно обрабатывать).
Способ №3: синхронизация
Синхронизация подразумевает сохранение всех настроек пользовательского профиля с возможностью последующего его восстановления (загрузки) в браузере не только на компьютере, но и на мобильных устройствах (например, на Андроиде).
Примечание.
Чтобы воспользоваться этим способом, вам понадобится учётная запись в системе Yandex.
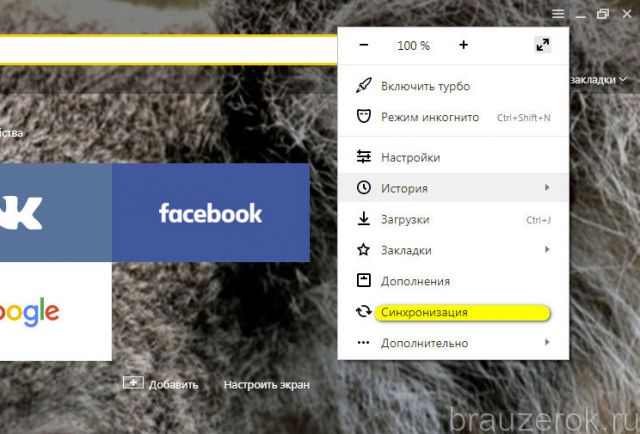
1. Кликните «Меню». В списке нажмите «Синхронизация».
2. Введите логин и пароль для входа в аккаунт.
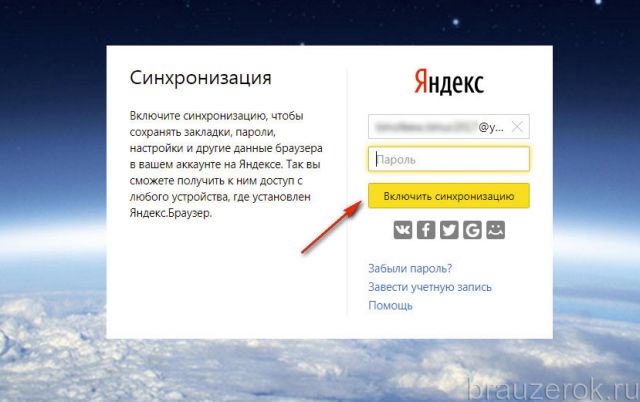
3. Клацните «Включить синхронизацию».
4. Теперь, когда вам нужно будет восстановить историю и другие пользовательские данные, снова откройте раздел «Синхронизация» и выполните авторизацию в профиле.
Выберите наиболее действенный способ восстановления конкретно для вашего случая. Восстановление файла утилитой Recuva, безусловно, выполнить проще и безопасней. Но если она не смогла обнаружить ранее удалённый журнал, можно выполнить откат настроек системы. Не забывайте периодически создавать бэкапы истории, если в ней хранятся важные, ценные для вас ссылки.
Когда случайно пропала одна закладка из архива браузера – это уже неприятно, но что делать, если после запуска “Яндекса” исчезли они все? Восстановить букмарки легко, если знать правильный подход к настройкам и горячим клавишам программы.
Как удалить страницу на Фейсбук без вероятности восстановления
У всякого пользователя общественной сети имеется вероятность удалить страницу на Фейсбук навечно сразу и без необходимости ждать механической деинсталяции в течение 90 дней. Для этого довольно написать администрации Facebook через форму обратной связи в основном меню и осведомить причину, по которой все данные надобно стереть немедленно. Скажем, представители сайта в таких случаях идут насупротив пользователям, у которых высока вероятность взлома со стороны других лиц. Но дозволено указать и другие поводы, в том числе личного нрава.
Также через форму обратной связи вы можете попросить администрацию удалить страницу на Фейсбук иного пользователя, являющегося вашим родственником. Немедленно удаляются профили пользователей, которым еще нет 13 лет, а также физически либо умственно неполноценных людей, которые не могут сделать это самосильно. То же самое относится к лицам, отбывающим наказание в местах лишения воли либо находящимся на долгом медицинском лечении. В всякий из вышеперечисленных обстановках не позабудьте предварительно сберечь на своем компьютере все собственные данные из вашего профиля на Фейсбук, от того что все они будут удалены навечно без вероятности поправления.
Видео по теме
https://youtube.com/watch?v=G4W-zwsI2cw
Параметры файла подкачки
Иногда наряду с изменением размера кэша в сторону увеличения некоторые специалисты рекомендуют произвести дополнительные действия с так называемым файлом подкачки, который отвечает за работу и использование виртуальной памяти – такого же резервируемого объема на жестком диске, но используемого для выгрузки программных компонентов в случае нехватки оперативной памяти. Как и в случае с системным кэшем, нужно быть предельно осторожным. При малом объеме ОЗУ файл подкачки действительно можно немного увеличить, установив для него значение, которое в 1,5-2 раза превышает определяемое или рекомендуемое системой по умолчанию. Но и тут следует помнить, что при установке слишком большого объема можно добиться обратного эффекта, когда программы в приоритете будут производить обращение не к оперативной, а к виртуальной памяти. Повторимся: скорость доступа к винчестеру ниже, чем к планкам ОЗУ. Из-за этого мы получаем торможение программ при запуске или в процессе работы.

Негласно считается, что при установленных объемах оперативной памяти на уровне 8 Гб и более файл подкачки можно отключить вовсе, что никаким образом не скажется на работоспособности системы в отрицательную сторону. Наоборот, иногда можно добиться повышения производительности.
Как посмотреть кэшированную копию в Яндексе: основные способы
Перед тем как открыть сохраненную копию сайта в Яндексе, выберите удобный способ — с помощью сервисов (Page Promoter в Firefox или RDS bar в Google Chrome) или вручную. Плагины — это удобно, но они могут давать сбой, поэтому стоит освоить и ручной метод просмотра.
Способ № 1 — плагины
Расширения для браузеров, плагины и различные онлайн-сервисы позволяют быстро открывать кэш сайтов. Один из самых популярных на сегодня сервисов — это RDS bar. Плагин отличается интуитивным пользовательским интерфейсом и позволяет посмотреть последние изменения страницы, отсканированной роботами. Но если нужная страница еще не проиндексировалась, то и плагин ничего не покажет. 
Способ № 2 — вручную
Самый простой и эффективный «механический» способ просмотра. Что нужно сделать:
- Найти в поисковике нужную страницу — по запросу или вбив в поисковую строку адрес сайта.
- В результате поиска в сниппете нажать на маленькую стрелочку.
- В выпавшем окошке нажать «Сохраненная копия».
- Нажать и посетить сайт с данными, сохраненными с последнего визита робота на страницу.
Как посмотреть удаленную страницу в веб-архиве
Веб-архив – это специальный сервис, который хранит на своем сервере данные со всех страниц, которые есть в интернете. Даже, если сайт перестанет существовать, то его копия все равно останется жить в этом хранилище.
В архиве также хранятся все версии интернет страниц. С помощью календаря разрешено смотреть, как выглядел тот или иной сайт в разное время.
В веб-архиве можно найти и удаленные страницы с ВК. Для этого необходимо выполнить следующие действия.
- Зайти на сайт https://archive.org/.
- В верхнем блоке поиска ввести адрес страницы, которая вам нужна. Скопировать его из адресной строки браузера, зайдя на удаленный аккаунт ВК.
Используя интернет-архив вы, естественно, не сможете написать сообщение, также как узнать когда пользователь был в сети. Но посмотреть его последние добавленные записи и фото очень даже можно.
Страница найдена
Если искомая страница сохранена на сервере веб-архива, то он выдаст вам результат в виде календарного графика. На нем будут отмечены дни, в которые вносились изменения, добавлялась или удалялась информация с профиля ВК.
Выберите дату, которая вам необходима, чтобы увидеть, как выглядела страница. Используйте стрелочки «вперед» и «назад», чтобы смотреть следующий или предыдущий день либо вернитесь на первую страницу поиска и выберите подходящее число в календаре.
Страница не найдена
Может случиться, что необходимая страница не нашлась на сайте WayBackMachine. Это не значит, что вы что-то сделали не правильно, такое часто случается. Возможно, аккаунт пользователя был закрыт от поисковиков и посторонних сайтов и поэтому не попал в архив. WayBackMachine самый популярный сайт, но он не единственный в своем роде. Попробуйте найти в Яндексе или Гугле другие веб-архиви. Искомая страница могла сохраниться на их серверах.
Попытайте удачу в поисках архивной версии профиля на этих сайтах:
- archive.is;
- webcitation.org;
- freezepage.com;
- perma.cc.
Также обязательно попробуйте найти страничку на русскоязычном аналоге http://web-arhive.ru/.
Http заголовки для управления клиентским кэшированием
Для начала давайте посмотрим, как сервер и браузер взаимодействуют при отсутствии какого-либо кэширования. Для наглядного понимания я попытался представить и визуализировать процесс общения между ними в виде текстового чата. Представьте на несколько минут, что сервер и браузер – это люди, которые переписываются друг с другом 🙂
Без кэша (при отсутствии кэширующих http-заголовков)
Как мы видим, каждый раз при отображении картинки cat.png браузер будет снова загружать ее с сервера. Думаю, не нужно объяснять, что это медленно и неэффективно.
Заголовок ответа и заголовок запроса .
Идея заключается в том, что сервер добавляет заголовок к файлу (ответу), который он отдает браузеру.
Теперь браузер знает, что файл был создан (или изменен) 1 декабря 2014. В следующий раз, когда браузеру понадобится тот же файл, он отправит запрос с заголовком .
Если файл не изменялся, сервер отправляет браузеру пустой ответ со статусом . В этом случае, браузер знает, что файл не обновлялся и может отобразить копию, которую он сохранил в прошлый раз.
Таким образом, используя мы экономим на загрузке большого файла, отделываясь пустым быстрым ответом от сервера.
Заголовок ответа и заголовок запроса .
Принцип работы очень схож с , но, в отличии от него, не привязан ко времени. Время – вещь относительная.
Идея заключается в том, что при создании и каждом изменении сервер помечает файл особой меткой, называемой , а также добавляет заголовок к файлу (ответу), который он отдает браузеру:
Теперь браузер знает, что файл актуальной версии имеет равный “686897696a7c876b7e”. В следующий раз, когда брузеру понадобится тот же файл, он отправит запрос с заголовком .
Сервер может сравнить метки и, в случае, если файл не изменялся, отправить браузеру пустой ответ со статусом . Как и в случае с браузер выяснит, что файл не обновлялся и сможет отобразить копию из кэша.
Заголовок
Принцип работы этого заголовка отличается от вышеописанных и . При помощи определяется “срок годности” (“срок акуальности”) файла. Т.е. при первой загрузке сервер дает браузеру знать, что он не планирует изменять файл до наступления даты, указанной в :
В следующий раз браузер, зная, что “дата истечения срока годности” еще не наступила, даже не будет пытаться делать запрос к серверу и отобразит файл из кэша.
Такой вид кэша особенно актуален для иллюстраций к статьям, иконкам, фавиконкам, некоторых css и js файлов и тп.
Заголовок с директивой .
Принцип работы очень схож с . Здесь тоже определяется “срок годности” файла, но он задается в секундах и не привязан к конкретному времени, что намного удобнее в большинстве случаев.
Для справки:
- 1 день = 86400 секунд
- 1 неделя = 604800 секунд
- 1 месяц = 2629000 секунд
- 1 год = 31536000 секунд
К примеру:
У заголовка , кроме , есть и другие директивы. Давайте коротко рассмотрим наиболее популярные:
public
Дело в том, что кэшировать запросы может не только конечный клиент пользователя (браузер), но и различные промежуточные прокси, CDN-сети и тп. Так вот, директива позволяет абсолютно любым прокси-серверам осуществлять кэширование наравне с браузером.
private
Директива говорит о том, что данный файл (ответ сервера) является специфическим для конечного пользователя и не должен кэшироваться различными промежуточными прокси. При этом она разрешает кэширование конечному клиенту (браузеру пользователя). К примеру, это актуально для внутренних страниц профиля пользователя, запросов внутри сессии и т.п.
no-cache
Позволяет указать, что клиент должен делать запрос на сервер каждый раз. Иногда используется с заголовком , описанным выше.
no-store
Указывает клиенту, что он не должен сохранять копию запроса или частей запроса при любых условиях. Это самый строгий заголовок, отменяющий любые кэши. Он был придуман специально для работы с конфиденциальной информацией.
must-revalidate
Эта директива предписывает браузеру делать обязательный запрос на сервер для ре-валидации контента (например, если вы используете eTag). Дело в том, что http в определенной конфигурации позволяет кэшу хранить контент, который уже устарел. обязывает браузер при любых условиях делать проверку свежести контента путем запроса к серверу.
proxy-revalidate
Это то же, что и , но касается только кэширующих прокси серверов.
s-maxage
Практически не отличается от , за исключением того, что эта директива учитывается только кэшем резличных прокси, но не самим браузером пользователя. Буква “s-” исходит из слова “shared” (например, CDN). Эта директива предназначена специально для CDN-ов и других посреднических кэшей. Ее указание отменяет значения директивы и заголовка . Впрочем, если вы не строите CDN-сети, то вам вряд ли когда-либо понадобится.
Для чего нужны сохраненные страницы?
Кэш-страницы сайта в поисковых системах позволяют увидеть, какую версию документа уже успели проиндексировать роботы поисковых систем и участвует ли страница в ранжировании. Грубо говоря, если страница начала сохраняться — это главный фактор пройденной индексации.
Бесплатный бэкап
В работе с сайтами, может возникнуть масса непредвиденных ситуаций. Особенно на стадии запуска проекта, на сайте частенько ведутся технические работы, предполагающие корректировку дизайна и текстовых блоков. В такие моменты не исключены ошибки, которые могут «положить» сайт или нарушить его работу, также могут пропасть тексты, изображения и так далее.
Большинству разработчиков знакомы такие ситуации и если не был проведен бэкап, а дешевый хостинг не позволяет сделать «откат», то все печально. Вот тут-то и приходит на помощь кэш сайтов — копия позволяет сохраниться и проверить, какие ошибки нужно исправить.
SEO-продвижение
Еще один случай, когда кеш придет на помощь, связан с текстами. Например, вы откорректировали текст, чтобы повысить его релевантность. Чтобы проверить, обновилась и проиндексировалась ли нужная страница, достаточно взглянуть на копию.
Технические проблемы, просрочка оплаты и так далее
Часто интернет-ресурсы бывают недоступны из-за технических проблем на сервере, истечения срока оплаты хостинга и т.п. В этом случае попасть на сайт можно также через копию, которая хранится в кэше.
Как сохранить страницу с интернета на компьютер
Каждый интернет-браузер имеет функцию сохранения веб-страниц на ноутбук или компьютер. Рассмотрим пример сохранения страницы сайта в популярном браузере Opera.
Для этого перейдём в браузер Opera на нужную для нас веб-страницу, чтобы скопировать её. Переходим на кнопку, которая находится в левом верхнем углу браузера и открываем меню. После нажимаем на вкладку «Страница», чтобы увидеть пункт «Сохранить как…» Тот же самый результат будет, если нажмёте комбинацию Ctrl+S.
Далее, нужно нажать на «Сохранить как…» и выбрать место на диске, куда вы желаете сохранить файл. Выберете тип файла и сохраняйте. Выбранная страница сайта сохранится в нужном формате и расширением html. Это очень удобный формат. В нём текст и все элементы сайта вместе с картинками сохранятся полностью и в одном файле. Браузер Internet Explorer тоже может сохранять в таком формате.
Если при сохранении выбрать тип файла «HTML с изображениями», то создаётся не только файл с таким расширением. Вместе с этим будет создан отдельный каталог, где будут храниться картинки и прочие элементы. Хотя страница и полностью сохранится, такой вариант архивации не очень удобен.
 Иногда, копируя нужную информацию на флеш-карту, каталог с картинками может не поместиться по каким-либо причинам. Например, загруженность флеш-карты или большая величина самого каталога с картинками. В этом случае возникнет неудобство при открытии сохранённого сайта. Он будет открываться в виде текста без картинок. Поэтому такой вариант устроит далеко не всех.
Иногда, копируя нужную информацию на флеш-карту, каталог с картинками может не поместиться по каким-либо причинам. Например, загруженность флеш-карты или большая величина самого каталога с картинками. В этом случае возникнет неудобство при открытии сохранённого сайта. Он будет открываться в виде текста без картинок. Поэтому такой вариант устроит далеко не всех.
Если картинки вас не очень интересуют, то всю страницу можно скопировать в текстовом формате. Файл будет храниться на компьютере или флеш-карте с расширением txt. Или выделить фрагмент нужного текста и скопировать в Word. После чего документ будет сохранён с соответствующим расширением этой программы.
Аналогично сохранить веб-страницу можно и в других браузерах. Хотя существуют некоторые нюансы.
- В Google Chrome команда «Сохранить страницу как…» выполняется из пункта настроек и управления. Меню расположено в правом верхнем углу. При этом следует заметить, что сохранение в текстовый и архивный файл Chrome не поддерживает.
- В Mozilla Firefox пункт «Сохранить как…» появится, если нажать на кнопку «Файл» в появившемся меню.
- Internet Explorer страница сохраняется аналогично вышеуказанным браузерам.
Мы уверены, что Вам будет полезна статья о том, как пользоваться торрентом.
Сохранение веб-страницы в PDF формате
Скачать страницу через веб-браузер на ноутбук или компьютер не каждому покажется удобным. Поскольку, кроме неё, создаётся каталог с изображениями, а также масса других отдельных элементов. Для наиболее компактного сохранения страницы можно преобразовать её в PDF файл. Эта возможность есть в браузере Google Chrome, который сохранит её в этом формате полностью.
Для этого нужно зайти в «управление и настройки» из меню и нажать на команду «Печать». В появившемся окне печати документа и подпункте «Принтер» кликнуть на кнопку «Изменить». Появятся все доступные принтеры и строчка «Сохранить как PDF». Нужно нажать на «Сохранить» и указать место на диске, куда будет сохранена интернет-страница. После чего её можно будет преобразовать практически в любой формат с помощью специальных конверторов.
Сохранение через скриншот
 Ещё один вариант сохранения веб-страницы в виде картинки при помощи скриншота. Для этого нажмите комбинацию Shift+Print Screen. При этом сохранится область страницы, которая находится в рамках экрана. Если текст входит не весь можно уменьшить захват экрана путём изменения масштаба. После сохранения можно использовать любой графический редактор для различных корректировок.
Ещё один вариант сохранения веб-страницы в виде картинки при помощи скриншота. Для этого нажмите комбинацию Shift+Print Screen. При этом сохранится область страницы, которая находится в рамках экрана. Если текст входит не весь можно уменьшить захват экрана путём изменения масштаба. После сохранения можно использовать любой графический редактор для различных корректировок.
А также можно использовать специальные программы для создания скриншотов. Одной из таких программ является Clip2net. Она довольна популярна из-за своей многофункциональности и простоты в использовании. Скачать её можно бесплатно с официального сайта. После создания скриншотов она сохранит их в любую указанную вами папку. А также ими можно будет обмениваться через интернет даже с помощью созданных ею ссылок.