Key collector: полное практическое руководство
Содержание:
Сбор частот
Сбор частот позволяет оценить популярность запросов.
Сервис выдает кол-во показов запроса за последние 30 дней.
Статистика обновляется не ежедневно, поэтому не воспринимайте этот период буквально.
Сервис поддерживает различные операторы поиска, поэтому программа способна получать несколько видов частот.
Программа автоматически добавляет нужные операторы при сборе того или иного вида частот (добавлять операторы вручную к текст запросов не требуется).
Базовая частота
Базовая частота соответствует широкому типу вхождения слов. Для выполнения запроса достаточно отправить сам запрос в исходном виде:
- свежий хлеб
- условная вероятность
- теорема Байеса
В результатах могут быть учтены и другие фразы, косвенно относящиеся к запросу «свежий хлеб» в широком соответствии: купить свежий хлеб, свежий ржаной хлеб, рецепт хлеба, свежая выпечка и др.
Фразовая частота
Фразовая частота фиксирует состав слов в искомом запросе, и показы считаются для словосочетания целиком. Для выполнения запроса необходимо добавить двойные кавычки:
- «свежий хлеб»
- «теорема Байеса»
- «плотность распределения»
В результатах к запросу «свежий хлеб» будут учтены только фразы с тем же набором слов:: свежий хлеб, хлеба свежего и др.
Точная фразовая частота
Точная фразовая частота фиксирует не только состав, но и словоформы слов в искомом запросе. Для выполнения запроса необходимо добавить оператор ! перед каждым словом в запросе и взять его в двойные кавычки:
- «!свежий !хлеб»
- «!теорема !Байеса»
- «!плотность !распределения»
В результатах к запросу «!свежий хлеб!» будут учтены только фразы с тем же набором слов в той же словоформе: свежий хлеб, хлеб свежий (порядок не фиксируется).
Точная фразовая частота с порядком
Точная фразовая с порядком частота фиксирует состав, словоформы и порядок следования слов в искомом запросе. Для выполнения запроса необходимо добавить оператор ! перед каждым словом в запросе, взять его в и двойные кавычки:
- «!свежий !хлеб»
- «!теорема !Байеса»
- «!плотность !распределения»
В результатах к запросу «!свежий хлеб!» будут учтены только фразы с тем же набором слов в той же словоформе и том же порядке следования: свежий хлеб.
Частота по маске
Вы можете самостоятельно определить маску запроса, используя поддерживаемые сервисом операторы.
Маска запроса должна содержать фрагмент QUERY, который при сборе частот будет заменяться на текст исследуемого запроса.
Как установить программу на компьютер
Оплатите и скачайте программу на официальном сайте. Цена одной лицензии 1 800 рублей.

Запустите установочный файл скачанной программы и следуйте инструкции.
После установки нужно активировать лицензию:
- При запуске установленной программы появится окно с уникальным идентификатором (HID).
- Лицензия (файл lic.license) придет на почтовый ящик после оплаты, ее нужно положить в папку с программой. По умолчанию Кей Коллектор устанавливается в «Мои документы/Key Collector».
- Можно запускать программу и пользоваться.
Если возникли трудности, ищите всю информацию по инсталляции на сайте программы.
Создание структуры
Результаты группировки могут быть перенесены в проект через создание структуры.

Шаг 1. Нажмите кнопку «Создать структуру» на панели инструментов. Откроется окно параметров выполнения операции.
Шаг 2. Структура может быть создана для помеченных или выделенных групп. Как правило, удобней работать с помеченными группами. находится справа от названия группы, помеченные группы подсвечиваются зеленым цветом (см. скриншот).
Не перепутайте колонку пометки групп и колонку группового статуса отметки фраз внутри группы!
Шаг 3. Выбранные на шаге 2 группы могут быть созданы на корневом уровне проекта или внутри активной группы. Выберите подходящий режим.
Шаг 4. Выберите тип операции: копирование или перенос. При переносе одна и та же фраза может быть перенесена только единожды, т.е. она не будет продублирована во все целевые группы.
Шаг 5. Выберите источник фраз: только отмеченные фразы или все фразы сформированной группы.
Шаг 6. Для достижения эффекта этот шаг нужно выполнять в самом начале перед вызовом инструмента создания структуры. По умолчанию группы создаются в проекте с автоматически сформированными заголовками, однако вы можете переопределить заголовок группы на свой более подходящий. Если несколько групп будут иметь одинаковый заголовок, то их фразы попадут в общую группу с определенным самостоятельно заголовком (дублирования групп не произойдет).
Общая настройка Кей Коллектора
Для работы с вордстатом понадобиться: здесь все просто, нужно отдельно зарегистрировать яндекс почту и создать там тестовую рекламную кампанию, можно с одним объявлением, можно просто черновую (без прохождения модерации и пополнения бюджета). В программе просто прописываем логин и пароль от почты и все работает.
Для работы с гугл планером понадобиться: зарегистрировать новый аккаунт в гугл адвордс. В обязательном порядке скачать последнюю версию браузера internet explorer и зайдя исключительно через данный браузер, также создать тестовую рекламную кампанию (без бюджета и активности). Главное заполнить все настройки пользователя — указать язык и местоположение. Фокус заключается в том, что без данных манипуляций, использовать гугл планер не получиться.
Переходим непосредственно к настройкам:

Заходим в настройки программы во вкладку Яндекс Вордстат», где выставляем следующие параметры:
— глубина парсинга — 0. Выставляя такое значение, вы будите получать обычный парсинг, но программа может автоматом парсить и в глубину, т.е. спарсив ключевые слова, она может парсить то, что уже спарсила, разбивая ключевые слова на более конкретные ключевые слова. Смысла глубокого парсинга нет, так как система будет парсить дубли, а не уникальные ключевые слова, и даже без глубокого парсинга мы все равно будем по нему показываться, так как используем основную маску. Если просто — глубокий парсинг делать не надо, выставляем значение ноль.
— парсить страницы, здесь выставляем стандартное значение — 40.
— добавлять в таблицу фразы с частотами от 1 до 99999999999. Здесь вы указываете какую частотность вы хотите видеть с парсенных ключевых слов. Есть директологи, которые не парсят все доскональна, а работают с ключевыми словами, которые имеют частотность от 10 и выше. Я же советую вам парсить все и начинать с 1. При таком подходе у вас будет самое полное семантическое ядро, а если вы решите, что такие ключевые слова вам не нужно, то уже после парсинга, можно при помощи фильтра выделить такие ключи и удалить.
— не снимать частоты для фраз меньше или равной 0. Логика проста, нам не нужно пустые ключевые слова, которые не будут приносить трафик, поэтому такие не ищем.
— количество потоков. Если вы используете одну почту от яндекс директа, то можете смело выставлять сразу 2 потока, и таким образом программа будет работать в два раза быстрее. И если вы не используете прокси сервера, то не убираем галочку «Использовать основной IP адрес».

Далее заходим во вкладку «Яндекс Директ», где указываем адреса свои электронных почт от яндекса и пароли от них. Достаточно указать 1-2 почты.

Во вкладке «Гугл Адвордс» указываем доступы от гугл адвордс (что логично).
Собственно, это все стандартные настройки, после которых заработает кей коллектор.
Неявные дубли
Съем данных Гугл Адвордс полезен для быстрого сравнения и удаления менее частотных неявных дублей с перестановкой слов.
Для этого нужно настроить аккаунт Гугл в программе. Для вызова функции нажмите на иконку, как это показано на скриншоте:

После парсинга Адвордс перейдите во вкладку «Данные» в меню «Анализ неявных дублей».

- Чтобы оставить все многообразие словоформ, снимите галочку с пункта «Не учитывать словоформы при поиске неявных дублей». Если нужна только одна морфологическая словоформа, самая частотная, то, наоборот, поставьте галочку в чекбокс.
- Выберите, где искать дубли.
- Чтобы оставить одну и исключить случайное удаление фраз со снявшейся частотой, выберите такие же параметры, как на скриншоте выше.
- Нажмите кнопку «Выполнить поиск дублей повторно».
- Отметьте дубли с наименьшей частотностью с помощью кнопки «Умная отметка».
Таким образом все неявные дубли будут отмечены в таблице и их можно удалить.
Кей коллектор и семантика
Работа с подбором ключевых вхождений после создания сайта не заканчивается, поэтому ресурс будет полезен не только разработчикам. Продвижение контекстной рекламой, работа с заголовками и многие другие задачи требуют знания частотности.
Бесспорно, Key Collector — лучшая утилита анализа статистики по запросам. Когда начинаешь пользоваться, возникает масса вопросов. Какие прокси использовать, какие кнопки нужные, какие настройки использовать, как собирать статистику, чтоб тебя не заблокировали? Все настроил, через какое-то время заходишь и уже ничего не можешь вспомнить. Заново приходится изучать. Это отнимает много времени, и хочется делегировать работу в надежные руки. С Моабом все становится в разы проще: купил подписку и юзай, без заморочек. Временных лимитов у услуги нет и это большой плюс.
Тем, кто ручками в вордстате сборку делает, совсем не позавидуешь. Там одну капчу запаришься вводить. В Моабе все становится совсем просто. Вносишь список слов и запускаешь процесс. Служба соберет тебе слова на всю указанную глубину, выдаст подсказки, уберет дубли и выдаст все одним файлом. Пользуйтесь.
Сбор семантики в Key Collector
На примере группы запросов: “курсовая работа”, я покажу как я собираю семантику для своего сайта, с помощью кейколлектора.
1. Устанавливаем расширение для браузера “Serpstat Website SEO Checker”
3. Активируем расширение, и переходим во вкладку “Анализ страницы”. Там мы получаем ТОП-10 ключевых слов по URL. Копируем в ключевые слова в текстовый файл, удаляя лишнее.

4. Полученный список ключей переносим в текстовый файл.
5. Открываем кейколлектор. Вкладка: “Данные” — Прочее — “Планировщик задач”. Далее нажимаеv на шестеренку “Задать параметры”.
Выбираем сбор фраз из Яндекс Вордстат. Выбираем регион, в моем случае это Россия. Далее нажимаем на значок “Распределить по группам” — загружаем список наших ключей — нажимаем “Применить изменения”.

6. Далее добавляем в скрипт задачу: “Собрать поисковые подсказки Яндекс” В настройках с помощью желтых и зеленых папок переносим наши фразы.
Потом добавляем в скрипт: “Собрать прогноз из Яндекс Директ”. В настройках выбираем все наши группы, выбираем нужный регион, ставим галочки напротив всех частот. Для полной семантики, можно добавить ПС Google.
7. Нажимаем “Создать скрипт”, пишем имя для скрипта и нажимаем “Продолжить”. Все, теперь ждем пока спарсятся все ключи.

8. После того как Key Collector закончит сбор фраз и частотность, нам нужно удалить все запросы равные нулю. Включаем мультигруппы: выделяем все наши группы Ctrl+A и нажимаем F3.
В колонке с точной частотность настраиваем фильтр: равно 0.

9. Собранную семантику нужно очистить на предмет дублей. Переходим во вкладку: Главная — «Неявные дубли» — Найти. С помощью умной отметки выбираем запросы, далее нажимаем удалить и применить.
10. Далее с помощью функции “Минус Слова” удалить ненужные запросы, типа скачать торрент, порно, итд.
11. Теперь все оставшиеся фразы нам нужно перенести в одну, новую группу.
Выделяем все наши группы Ctrl+A — Вкладка данные — Копировать/перенести фразы. Перенести в «Новая группа». После чего все остальные группы можно удалять. Новую группу переименовываем в «Курсовая работа». Теперь у нас есть пул запросов, и можно переходить на этап кластеризации.
Семантическое ядро — основа сайта
Собрать большое и хорошее семантическое ядро для ресурса стоит недешево. Любой сеошник скажет, что на это потребуется немало времени и ресурсов. Когда начинаешь парсить большое СЯ, то сложности возникают даже в таком суперском софте от LegatoSoft. Прокси уходят в бан, нужно постоянно искать новые. Капчу вручную набивать не будешь, если надо собрать 10к фраз, придется покупать антикапчу. Быстрый сбор семантического ядра возьмет и застопорится на ровном месте. Проще на большой объем купить пакет Моаба, еще останется на дальнейшее продвижение.
Ограничений по использованию пакетов нет. Хочешь, используй прямо на портале, хочешь в связке с КК. Как тебе удобнее. На сайте результат выдается архивом с тремя вариантами: в формате csv, текстовым файлом и классический эксельный.
Борьба с погрешностями и операторы поиска
К сожалению, при работе в формонезависимых режимах возможны погрешности. Иногда программа считает близкие по смыслу слова одинаковыми, а иногда наоборот не улавливает связи между одним и тем же словом в разных склонениях.
Специальными операторы поиска позволяются исправить ошибки или уточнить его критерии.
Фиксация словоформы (точный поиск)
Если программа ошибочно принимает какое-то слово за искомое, вы можете зафиксировать проблемное минус-слово оператором !
- !Киев
- !кий
- !как
- !тянули !репку
Например, «Киев» и «кий» в упрощенном быстром режиме могут считаться равными, т.к. их неизменяемая часть «ки» совпадает в обоих словах. Или же «как» и «почему» может быть приняты за равнозначные слова в улучшенном режиме.
Для фиксации минус-фразы необходимо использовать оператор ! перед каждым словом фразы. Фиксировать отдельные слова минус-фразы не допускается.
Фиксация фразы (фразовый поиск)
При поиске минус-фраз, состоящих из нескольких слов, по умолчанию программа разрешает присутствие посторонних слов между словами искомой фразы. Оператор » » локально запрещает эту возможность.
- «заказать торт»
- «в банке»
Например, минус-фраза заказать торт (без кавычек) будет найдена в запросе «заказать свадебный бисквитный торт с кремом». Если добавить оператор » «, то минус-фраза будет найдена только в запросах вида «заказать торт на праздник» (слова искомой фразы не разделены посторонними словами).
Фиксация порядка слов
- заказать торт
- в банке
Например, минус-фраза заказать торт (без кавычек) будет найдена в запросе «торт на праздник заказать». Если добавить оператор , то минус-фраза будет найдена только в запросах вида «заказать праздничный торт» (слова искомой фразы следуют строго в заданном порядке).
Композиция операторов
Допускается использование различных операторов сразу, однако важен порядок их применения.
- Фразовая фиксация » »
- Точная фиксация !
Как собрать запросы в группы на основе выдачи Google
Чтобы выполнить пакетный сбор для конкретной поисковой системы, необходимо сделать следующее:
- определить конкретный регион и интересующий поисковик;
- собрать KEI для нужной зоны;
- сгруппировать запросы.
Первым делом на верхней панели инструментов надо выбрать кнопку «KEI». В выпадающем списке отметить необходимость получения данных для ПС Google.
После запуска поиска до момента получения результатов может пройти немало времени. К тому же, придется столкнуться с большим количеством капчи. А когда процесс отбора будет завершен, останется собрать запросы в группы. На верхней панели есть кнопка «Анализ групп». После ее активации откроется окно для настроек. Тут нужно задать актуальные параметры.
Есть смысл обратить внимание на пункт «сила связи SERP». Ее показатель можно менять, наблюдая за тем, как система формирует группы после внесенных изменений
Вместо 6 часто используют 4 или 5. Это оптимальные значения. Но окончательный и наиболее эффективный вариант зависит от специфики конкретной задачи.
Готовые группы можно сразу перенести в Excel для удобства пользования ключами. В той же вкладке на верхней панели с правой стороны есть соответствующий значок программы. Кликнув по нему, вы запускаете экспорт. В результате получится информативная таблица.
В целом, работать с Кей Коллектором довольно удобно и просто. К тому же, программа полностью бесплатная. А если рассматривать отзывы ее активных пользователей, то по 10-бальной шкале ПО получает уверенную и твердую 8.
Собираем стартовые ключи
Полученный список конкурентов заносим в таблицу, он еще пригодиться для дальнейшего продвижения проекта.
Проанализировав структуру каждого сайта, мы видим, что она у всех одинаковая. А все целевые запросы, типа курсовая, дипломная, реферат, находится разделе “Услуги”.
Таким образом из структуры сайта конкурентов мы получаем стартовые ключи, которые дальше нужно распарсить.
 Типы студенческих работ
Типы студенческих работ
Далее… С нулевым бюджетом и стартовыми ключами можно пойти в Яндекс Вордстат, взять Excel или Google Таблицы, и закопаться еще на месяц — другой в ручной работе. Кто собирал семантику таким образом знает
Поэтому чтобы ускорить процесс я купил себе Key Collector 4. Стоит это удовольствие всего 1800 рублей. Лицензия покупается один раз, и на всю жизнь. Основной плюс — отсутствие ежемесячной подписки.
В нем можно собирать семантику и делать кластеризацию. А еще мониторить позиции и много, много чего полезного. Главное, разобраться как!
Группировка
В Кей Коллекторе можно делать группировку вручную и с помощью автоматического кластеризатора.
Для ручной группировки отметьте нужные ключи и выберите / создайте новую папку для переноса.

Для автоматической группировки воспользуйтесь инструментом «Анализ групп» во вкладке «Данные».

Есть несколько способов группировки и несколько уровней силы кластеризации:
- По выдаче.
- По составу фраз – группировка на основе слов в ключевой фразе.
- Комбинация этих способов.
Для кластеризации в соответствии с выдачей нужно снять ее данные. Для этого подходит инструмент Вычисления KEI.

Ускорить процесс можно с помощью XML-лимитов. Также можно парсить выдачу в несколько потоков, если используются прокси.

Автоматическая группировка в Кей Коллектор не выдаст хороших групп, а наделает массу смысловых дублей, какие бы параметры кластеризации вы ни выбрали. Поэтому такой способ больше подходит для группировки мусорных фраз и дальнейшего их удаления целыми кластерами.
Другие функции Кей Коллектора полезные для директолога:
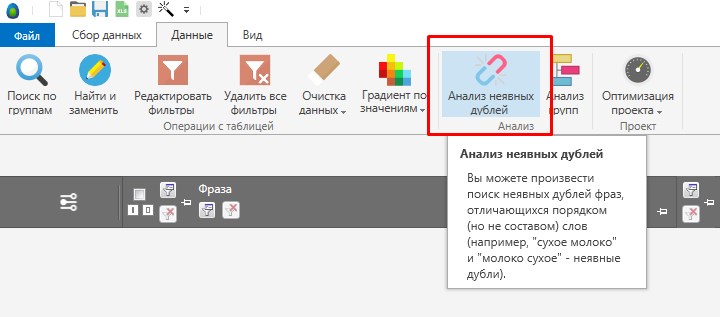
Удаление неявных дублей.
Если перейти во вкладку «Данные», то там будет полезная функция «Анализ неявных дублей», с помощью данной функции вы можете очистить собранное семантическое ядро не только от дублей, но и то неявных дублей. Например: как убрать комнату и как комнату убрать, будут считаться дублями. Программа покажет какие есть дубли, в каких группах, там же есть кнопка «Умная отметка», она автоматом выделяет один из дублей и вы его (или их удаляете), т.е. самостоятельно выделять и удалять дубли не надо, это делается в два клика.
Фильтры.
Каждый столбец в программе имеет самые различные фильтра. Например в столбце «Фразы» по фильтрам можно отыскать нужные ключевые слова, можно найти ключевые слова, которые состоят из определенного числа слов, это удобно при группировки ключей при обходе статуса «мало показов», когда в одну группу помещаются ключи с малой частотностью, но схожие по смыслу и написанию; в столбце «Базовая чистота», можно отфильтровать частотность по любому направлению (все ключи больше или равны 10, или меньше 5 и т.д.).

Быстрое составление списка минус слов.
Для того, чтобы максимально комфортно собрать полный список минус слов, достаточно выделить все ключевые слова, кликнуть правой кнопкой мыши на них и выбрать «Отправить выделенные фразы в окно стоп-слов». После этого откроется список со всеми выделенными ключами, где отмечая нужные слова далее их помещаем в список минус-слов.

Режим мульти-группы.
Для того, чтобы выгрузить полученное семантическое ядро в единый эксель файл, или применить на все группы (папки) ключей минус слов и т.д. и т.п. необходимо сначала выделить все папки, и нажать на мульти-группы, и только тогда все папки как-бы объединяться в одну. Например: у вас много папок, и вы хотите выгрузить полное семантическое ядро в один единый файл в формате эксель. Если просто выделить все папки, то в эксель отправиться лишь одна папка, а для выбора и работы со всеми папками, как раз и нужен режим мульти-группа:
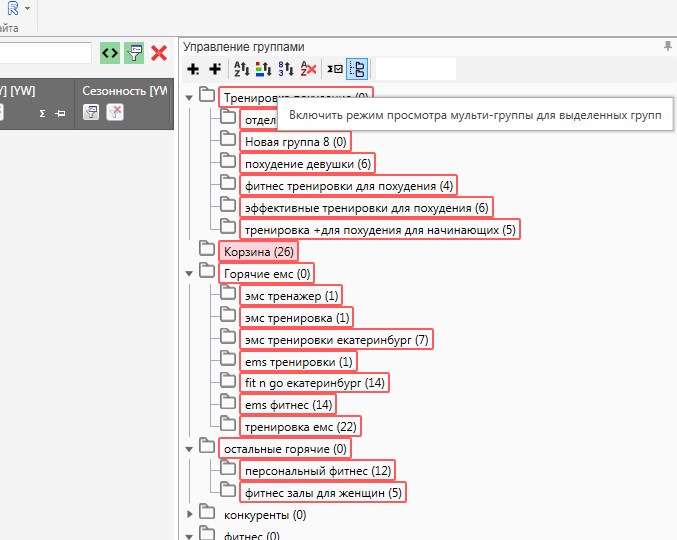
Сбор частотности ключевых слов.
С помощью Кей Коллектора можно не только парсить ключевые слова, но и собирать статистику с нужных ключевых слов. Это пригодиться тогда, когда вы делаете искусственную семантику и нужно ключи не спарсить, а просто узнать их частотность.
Для этого выбираем значок «Д», как указано на картинке, выбираем нужное гео именно в открывшейся вкладке и жмем «Получить данные»:

Режим мультигруппы
Иногда требуется просмотреть список фраз и параметров из нескольких групп сразу, чтобы воспользоваться общей сортировкой, фильтром или выполнить ту или иную операцию.
Мультигруппа — это временное виртуальное представление данных, отображающее фразы из составляющего это представление набора групп.

Для активации режима мультигруппы выделите несколько групп и нажмите кнопку активации режима мультигруппы на панели«Управление группами». Часто используемые мультигруппы можно добавить в закладки.
В пределах мультигруппы вы можете выполнять любые операции: сортировку и фильтрацию данных, поиск и минусацию, парсинг и выгрузку данных и пр.
Сбор семантики
Допустим, вам нужно собрать семантическое ядро для рекламы в Яндекс.Директ. Запустите Key Collector и откройте настройки кликом по шестеренке:
Настройки парсинга
Перейдите в раздел «Парсинг» и здесь внесите следующие изменения:
1) На вкладке «Общие» уберите знак плюс в поле «Удалять символы» – в Директе плюсы мы не используем.
2) На вкладке «Yandex.Direct» впишите данные по аккаунту, который нужно предварительно создать специально для парсинга.
Дело в том, что Яндекс лоялен к парсерам, так как с помощью них рекламодатели могут настроить более качественные рекламные объявления. Это с одной стороны.
С другой – рабочий аккаунт использовать ни в коем случае нельзя. Яндекс может его забанить за нарушение правил пользования сервисом (из-за автоматических запросов)
Лучше рискнуть потерять доступ к «фейковому» аккаунту, а не к настоящему.
Важно! Несмотря на то, что аккаунты «фейковые», задавайте им читабельные имена пользователей, чтобы впредь процесс не тормозили капчи Яндекса.
Также обратите внимание на настройки:
- Автоматически перезапускать процесс при ошибке «Сервис недоступен» через 120 секунд. Иногда Yandex.Direct становится временно недоступен. Эта галочка включает повторную попытку собрать статистику.
- Валюта. По умолчанию цены, бюджеты, стоимость клика в рублях. После изменения типа необходимо переоткрыть проект.
3) На вкладке Yandex Wordstat ничего не меняйте – подойдут настройки по умолчанию.
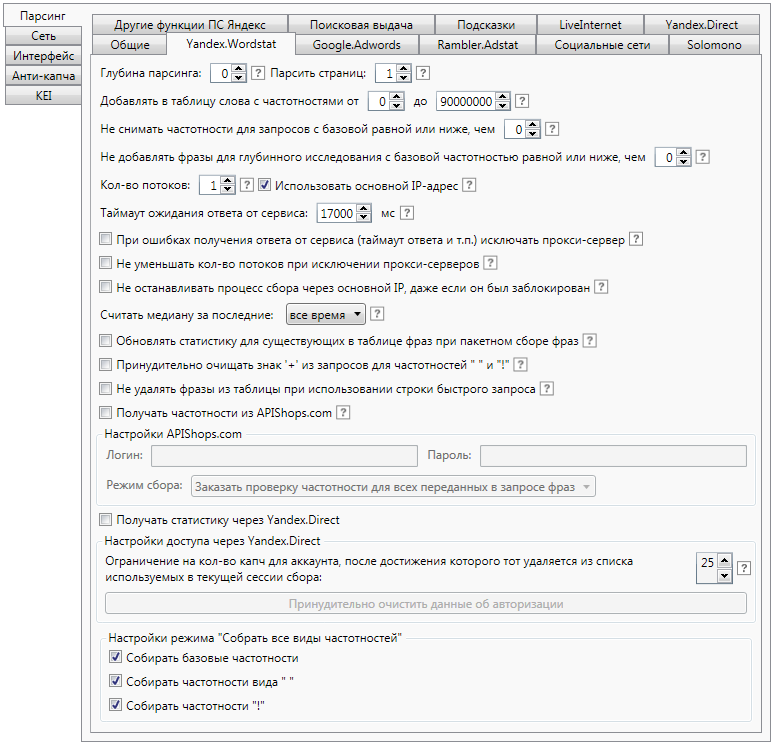
Кратко скажем об основных.
Глубина парсинга – это количество обходов списка слов, которое делает программа для одного ключевика. Соответственно, чем больше раз – тем больше слов и времени идет на обработку. Рекомендованная глубина 2 – так вы сразу получаете результаты парсинга + дополнительную выдачу по каждому из них.
Парсить страниц – сколько страниц в выдаче будет просматривать программа. Максимум в Wordstat – 40, на каждой – до 50 фраз, то есть 2 тысячи результатов по одной фразе. Сервис предлагает такое количество лишь для ВЧ-запросов.
Добавлять в таблицу фразы с частотностями … – задаем диапазон частотностей. Чтобы избежать потери важных ключевиков, используйте фильтрацию в таблицах данных.
Не снимать частотности для фраз с базовой частотностью равной или ниже, чем … – это экономит время, трафик, а также позволяет снизить вероятность получения капчи, исключая из проверки заведомо не интересующие фразы.
Не добавлять фразы для глубинного исследования с базовой частотностью равной или ниже, чем … – это сокращает время на сбор информации за счет игнорирования недостаточно популярных фраз с низкой базовой частотностью.
Считать медиану за последние … месяцев. Программа вычисляет значение по указанному периоду при сборе данных о сезонности.
Принудительно очищать знак + из запросов для частотностей « » и «!». При снятии частотностей вида « » и «!», запрос заключается в кавычки. При этом знак +, если это оператор, теряет смысл – его нужно отфильтровать, что и позволяет эта опция. Если это часть запроса, фильтрация не нужна.
Получать статистику через Yandex.Direct. Данная опция позволяет снимать статистику Yandex.Wordstat (кроме данных сезонности) через интерфейс Yandex.Direct. Это резервный режим на случай, если заблокирован доступ к Yandex.Wordstat. Для его запуска нужно прописать доступ к аккаунтам Яндекс.Директа во вкладке «Yandex.Direct».
4) На вкладке «Подсказки» – аналогично.
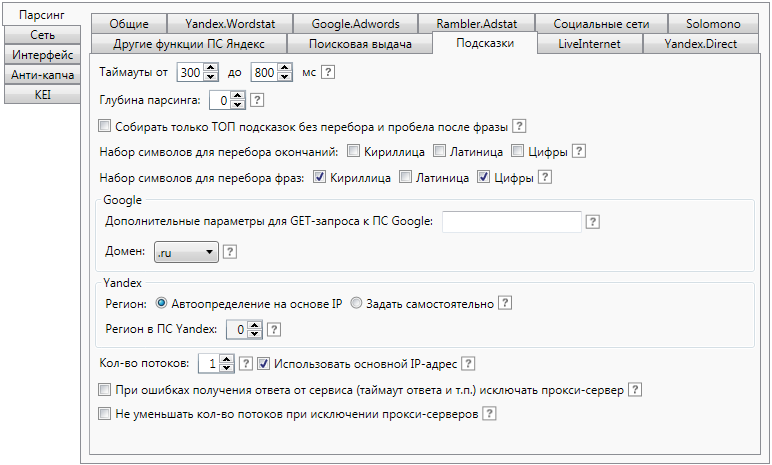
Внизу окна программы также не забудьте настроить целевые регионы для Вордстата и Яндекс.Директа (или другой системы, для которой собираете семантическое ядро).

На этом настройки парсинга готовы.
С чего начать парсинг
Кликните иконку «Добавить фразы»:

В окно вставьте исходные фразы (маски / базисы ключевых слов):

Рекомендуем подключить автораспознавание капчи, чтобы она не мешала работе Key Collector. Особенно если вы планируете парсить большие объемы ключей. Актуальные цифры по стоимости смотрите в разделе «Антикапча» по ссылкам.
Нажмите кнопку «Начать сбор» в этом окне – и процесс запустится!
Кстати, найти еще больше целевых ключей помогут поисковые подсказки. Собрать их в Key Collector можно нажатием следующей кнопке в верхнем меню:
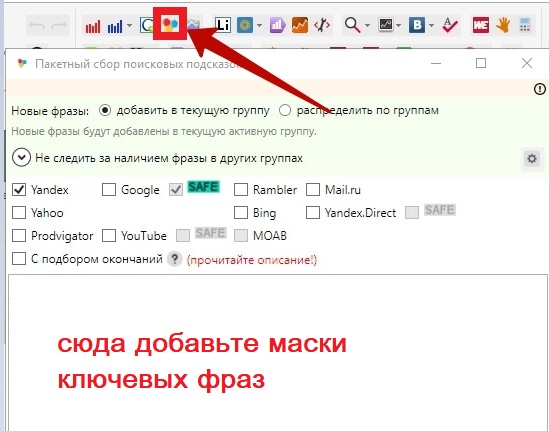
Затем остается скопировать сюда список маркеров и отметить галочкой поисковую систему, из которой хотите получить подсказки – и сервис начнет сбор.
Настройка Кей Коллектора
После того, как вы оплатили лицензию с помощью Вебмани, вам придет подробная и простая инструкция по установке Key Collector. Не буду тут дублировать данную информацию.
Лучше приступим непосредственно к запуску и настройке программы Key Collector.
Окно программы состоит из верхней, нижней, боковой панели, а также основного поля, где отображаются собранные ключевые слова.
Верхняя панель инструментов:

Нижняя панель состояния:

Бокова панель управления группами:
Основное поле сбора:
Для начала работы нам необходимо зайти в настройки в верхней панели слева.
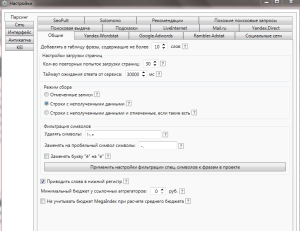
Первым делом, в настройках необходимо указать зарегистрированные вами аккаунты в тех сервисах, которые вы собираетесь использовать.
Например, для Яндекс Директа (основной источник сбора информации):
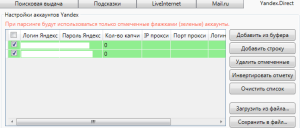
Указываете логин и через двоеточие пароль: к примеру, pro.wp:1234. Можно указать два или больше аккаунтов, тогда в случае блокировки одного, будет задействован второй. Не рекомендуется использовать больше 3-х.
Аккаунт может быть вычеркнуть системой, а соответственно информация не будет обрабатываться по причине слишком маленьких промежутков между запросами.
Для Яндекс Директа у меня проставлены такие значение:
Пока проблем не наблюдалось. Соответственно, если сократить временные диапазоны между обращениями к системе, результаты будут обрабатываться быстрее, но это может привести к блокировке аккаунта.
Обратите также внимание на остальные закладки настроек, кроме «Парсинга» это «Сеть», «Интерфейс», «Антикапча», «KEI». В разделе «Сеть» вы можете задать значения прокси-серверов, если вы их используете для работы с программой
В разделе «Сеть» вы можете задать значения прокси-серверов, если вы их используете для работы с программой.
В «Интерфейс» в Key Collector можно настроить отображения столбцов и заголовков таблиц, особенности экспорта файлов в Excel.
На вкладке «KEI» вы можете задать любые значения, которые вам нужно просчитать посредством вами заданных формул Kei в Кей Коллекторе. Например, просчет конкурентности запроса: сумма главных страниц с данным ключевым словом и заголовков других страниц с этим словом в Яндексе или Гугле.
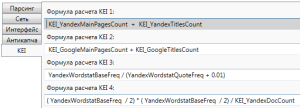
Когда вы подкорректировали все настройки, можно приступать к работе с Кей Коллектор.
Преимущества сервиса от Моаб очевидны:
— Глубина парсинга на площадке достаточно большая. Дополнительно, есть вариант выбора длины хвоста.
— Скорость выполнения исследования достаточно высокая. Для сравнения обычная обработка запроса «ОКНА» занимает 14 часов, а при использовании ресурса процесс заканчивается за 5 часов и приносит даже большее количество результатов.
— берёте пакет ПРО за 4999 рублей, а получаете почти бесконечный боезапас, полноценный Key Collector и огромное количество бонусов.
— Никакие капчи, прокси и прочие проблемы подборки вас не беспокоят. Просто нажимаете кнопку и получаете результат.
— 500 000 фраз — это объем, на википедию, не говоря уж о простых ресурсах.
Большой полюс в MOAB Tools — качество подбора фраз. Попробуйте в действии все функции на тарифе Free и убедитесь в возможностях сами. Лучше один раз потрогать, чем сто раз услышать.
Не упустите свой шанс и принимайте участие в акции тут.
SimpleSearch — поиск по сайту
Новая технология сбора семантики >
Что такое Key Collector?
Кей Коллектор – это платная утилита, которая повсеместно используется сеошниками и маркетологами. Суть ее состоит в почти полной автоматизации сбора семантического ядра. Приложение тесно интегрировано с Яндекс Директом, Вордстатом, гугловскими сервисами и прочими инструментами, которые поодиночке не выглядят такими практичными.
То есть Key Collector объединяет в себе несколько сервисов, интегрируя их возможности. Это позволяет людям легко и просто парсить запросы с того же Вордстата или Директа, в последствии превращая их во вполне себе обоснованное семантическое ядро.
Как я уже сказал, чтобы пользоваться программой, ее придется купить. Разработчики очень сильно заботятся о сохранении лицензии, поэтому каждая отдельная программа привязывается к одному персональному компьютеру с помощью идентификатора жесткого диска. Следовательно, вы не сможете скачать приложение, чтобы использовать его на нескольких машинах – 1 лицензия для 1 компьютера.
В интернете, конечно, есть взломанные версии, которые якобы предоставляют те же возможности, что и оригинал. Однако стоит учитывать, что через пиратское ПО очень часто распространяются вирусы
Если уж вы не хотите покупать Коллектор, то я бы рекомендовал вам обратить внимание на СловоЁб. Это бесплатное приложение от тех же разработчиков, которое представляет собой урезанный вариант Коллектора
Теперь давайте более подробно рассмотрим возможности программы. Итак, как заявляют разработчики, с помощью Key Collector мы сможем составить более точное семантическое ядро, не прибегая к помощи сторонних специалистов. Нам лишь нужно правильно настроить все параметры и познать некоторые азы.
Надо сказать, что Key Collector не работает с готовыми базами данных, которые требуют постоянные обновления. Он парсит всю информацию в реальном времени через интернет, подключаясь ко все тем же сервисам: Вордстат, Яндекс Директ, Гугл Адвордс и прочим. Такой подход гарантирует вам актуальность всех ключей, которые вы получите на выходе.
Эта программа поможет вам увидеть наиболее популярные страницы вашего сайта, определить верную стратегию продвижения, основываясь на статистических данных. В конечном итоге вы можете выгрузить всю информацию в удобный формат, например, в таблицу Excel.
Я уверен, что купить программу определенно стоит. Если понять, как работать, то это может сэкономить существенную часть финансов и времени. Да и проекты с качественной семантикой будут давать больше отдачи, что также является плюсом.
Заключение
Key Collector – сложная, многофункциональная утилита, которую вот так вот просто не освоить. Для более полного понимания чаще всего проходят специальное обучение. На курсах получают уроки по работе с семантикой и навыки по Кей Коллектору или аналогам. Поэтому сразу изучить эту программу полностью не получится.

Необходимый минимум в этой небольшой статье я вам дал. При помощи модуля Яндекс Вордстат вы сможете осуществлять съем семантического ядра, получать все виды частотностей и использовать это для составления крутых материалов. Имейте в виду, что сбор семантического ядра – работа тяжелая. Она требует серьезного подхода, и ни один инструмент не будет делать за вас абсолютно всю работу.
В случае с Кей Коллектором вам определенно придется покопаться с настройками. Многие пользователи изначально уделяют не так много времени этому, за что впоследствии расплачиваются неправильно составленной семантикой
Не совершайте ошибок, старайтесь уделить должное внимание настройкам и изучению особенностей работы этой утилиты
Если вы хотите разбираться не только в сборе семантического ядра, но еще и в создании крутых сайтов и их монетизации, я могу предложить вам пройти курс Василия Блинова “Как создать блог”. В нем будут рассмотрены все нюансы работы вебмастера, в том числе и такого аспекта, как сбор семантического ядра. По программе Key Collector вы тоже пройдетесь, получив более полные знания о работе в нем. Доступ на первый уровень предоставляется абсолютно бесплатно, поэтому не упустите свой шанс.