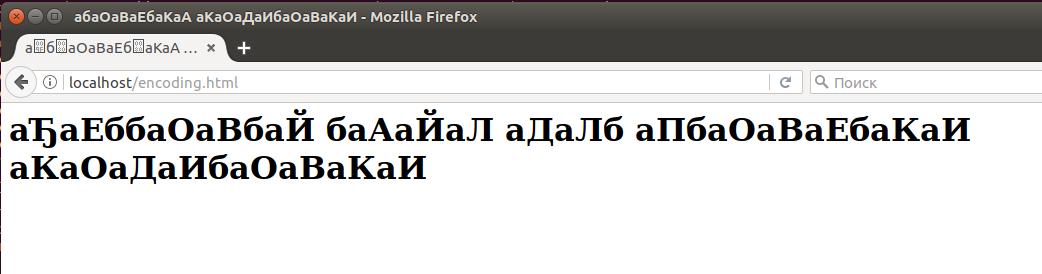
Кодировка от алкоголя
Содержание:
1251 – кодовая страница Windows
| 128 Ђ | 144 Ђ | 160 | 176 ° | 192 А | 208 Р | 224 а | 240 р |
| 129 Ѓ | 145 ‘ | 161 Ў | 177 ± | 193 Б | 209 С | 225 б | 241 с |
| 130 ‚ | 146 ’ | 162 ў | 178 I | 194 В | 210 Т | 226 в | 242 т |
| 131 ѓ | 147 “ | 163 J | 179 i | 195 Г | 211 У | 227 г | 243 у |
| 132 „ | 148 ” | 164 ¤ | 180 ґ | 196 Д | 212 Ф | 228 д | 244 ф |
| 133 … | 149 • | 165 Ґ | 181 μ | 197 Е | 213 Х | 229 е | 245 х |
| 134 † | 150 – | 166 ¦ | 182 ¶ | 198 Ж | 214 Ц | 230 ж | 246 ц |
| 135 ‡ | 151 — | 167 § | 183 · | 199 З | 215 Ч | 231 з | 247 ч |
| 136 € | 152 □ | 168 Ё | 184 ё | 200 И | 216 Ш | 232 и | 248 ш |
| 137 ‰ | 153 | 169 | 185 № | 201 Й | 217 Щ | 233 й | 249 щ |
| 138 Љ | 154 љ | 170 Є | 186 є | 202 К | 218 Ъ | 234 к | 250 ъ |
| 139 < | 155 > | 171 « | 187 » | 203 Л | 219 Ы | 235 л | 251 ы |
| 140 Њ | 156 њ | 172 ¬ | 188 j | 204 М | 220 Ь | 236 м | 252 ь |
| 141 Ќ | 157 ќ | 173 | 189 S | 205 Н | 221 Э | 237 н | 253 э |
| 142 Ћ | 158 ћ | 174 | 190 s | 206 О | 222 Ю | 238 о | 254 ю |
| 143 Џ | 159 џ | 175 Ï | 191 ї | 207 П | 223 Я | 239 п | 255 я |
866 – кодовая страница DOS
| 128 А | 144 Р | 160 а | 176 ░ | 192 └ | 208 ╨ | 224 р | 240 ≡Ё |
| 129 Б | 145 С | 161 б | 177 ▒ | 193 ┴ | 209 ╤ | 225 с | 241 ±ё |
| 130 В | 146 Т | 162 в | 178 ▓ | 194 ┬ | 210 ╥ | 226 т | 242 ≥ |
| 131 Г | 147 У | 163 г | 179 │ | 195 ├ | 211 ╙ | 227 у | 243 ≤ |
| 132 Д | 148 Ф | 164 д | 180 ┤ | 196 ─ | 212 ╘ | 228 ф | 244 ⌠ |
| 133 Е | 149 Х | 165 е | 181 ╡ | 197 ┼ | 213 ╒ | 229 х | 245 ⌡ |
| 134 Ж | 150 Ц | 166 ж | 182 ╢ | 198 ╞ | 214 ╓ | 230 ц | 246 ¸ |
| 135 З | 151 Ч | 167 з | 183 ╖ | 199 ╟ | 215 ╫ | 231 ч | 247 » |
| 136 И | 152 Ш | 168 и | 184 ╕ | 200 ╚ | 216 ╪ | 232 ш | 248 ° |
| 137 Й | 153 Щ | 169 й | 185 ╣ | 201 ╔ | 217 ┘ | 233 щ | 249 · |
| 138 К | 154 Ъ | 170 к | 186 ║ | 202 ╩ | 218 ┌ | 234 ъ | 250 ∙ |
| 139 Л | 155 Ы | 171 л | 187 ╗ | 203 ╦ | 219 █ | 235 ы | 251 √ |
| 140 М | 156 Ь | 172 м | 188 ╝ | 204 ╠ | 220 ▄ | 236 ь | 252 ⁿ |
| 141 Н | 157 Э | 173 н | 189 ╜ | 205 ═ | 221 ▌ | 237 э | 253 ² |
| 142 О | 158 Ю | 174 о | 190 ╛ | 206 ╬ | 222 ▐ | 238 ю | 254 ■ |
| 143 П | 159 Я | 175 п | 191 ┐ | 207 ╧ | 223 ▀ | 239 я | 255 |
Русские названия основных спецсимволов:
| Символ | Название |
| ` | гравис, кавычка, обратный машинописный апостроф |
| ` | гравис, кавычка, обратный машинописный апостроф |
| ~ | тильда |
| ! | восклицательный знак |
| @ | эт, коммерческое эт, «собака» |
| # | октоторп, решетка, диез |
| $ | знак доллара |
| % | процент |
| ^ | циркумфлекс, знак вставки |
| & | амперсанд |
| * | астериск, звездочка, знак умножения |
| ( | левая открывающая круглая скобка |
| ) | правая закрывающая круглая скобка |
| — | минус, дефис |
| _ | знак подчеркивания |
| = | знак равенства |
| + | плюс |
| левая открывающая квадратная скобка | |
| правая закрывающая квадратная скобка | |
| { | левая открывающая фигурная скобка |
| } | правая закрывающая фигурная скобка |
| ; | точка с запятой |
| двоеточие | |
| ‘ | машинописный апостроф, одинарная кавычка |
| « | двойная кавычка |
| , | запятая |
| . | точка |
| слэш, косая черта, знак дроби | |
| < | левая открытая угловая скобка, знак меньше |
| > | правая закрытая угловая скобка, знак больше |
| \ | обратный слэш, обратная косая черта |
| | | вертикальная черта |
Кодировка UNICODE
Юникод (Unicode) — стандарт кодирования символов, позволяющий представить знаки практически всех письменных языков. Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода».
В Unicode используются 16-битовые (2-байтовые) коды, что позволяет представить 65536 символов.
Применение стандарта Unicode позволяет закодировать очень большое число символов из разных письменностей: в документах Unicode могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы, при этом становится ненужным переключение кодовых страниц.
Для представления символьных данных в кодировке Unicode используется символьный тип wchar_t.
| ASCII | UNICODE |
| char | wchar_t |
| 1 байт | 2 байта |
Тип кодировки задается в свойствах проекта Microsoft Visual Studio:
Многобайтовая кодировка предполагает использование кодировки ASCII.
При этом при построении проекта используется директива условной компиляции, переопределяющая тип TCHAR:
#ifdef _UNICODE typedef wchar_t TCHAR;#else typedef char TCHAR;#endif
_T(«строка»)tchar.hПредставление данных и архитектура ЭВМ
Двоичная методика
Современный компьютер может обрабатывать числовую, текстовую, графическую, звуковую и видео информацию. В процессе хранения, обработки и передачи информации в компьютере используется особая двоичная система кодирования, алфавит которой состоит всего из двух знаков «0» и «1». Дело в том, что компьютер способен обрабатывать и хранить только лишь один вид представления данных – цифровой. Связано это с тем, что в цифровой электронике удобнее всего представлять информацию в виде последовательности электрических импульсов: техническое устройство, безошибочно различающее 2 разных состояния сигнала, оказалось проще создать, чем то, которое бы безошибочно различало 5 или 10 различных состояний. Поэтому любую входящую в него информацию необходимо переводить в цифровой вид. Такое кодирование информации принято называть двоичным, на его основе работают все окружающие нас компьютеры, смартфоны и т.п.
На английском языке используется выражение binary digit либо сокращённо bit (бит). Через 1 бит можно выразить: да либо нет; белое или чёрное; ложь либо истина.
Двоичное кодирование информации привлекает тем, что легко реализуется технически. Электронные схемы для обработки двоичных кодов должны находиться только в одном из двух состояний: есть сигнал/нет сигнала или высокое напряжение/низкое напряжение. В результате любая информация кодируется в компьютерах с помощью последовательностей лишь двух цифр — 0 и 1.
Итак, минимальные единицы измерения информации – это бит и байт. Один бит позволяет закодировать 2 значения (0 или 1). Используя два бита, можно закодировать 4 значения: 00, 01, 10, 11. Тремя битами кодируются 8 разных значений: 000, 001, 010, 011, 100, 101, 110, 111. Из приведенных примеров видно, что добавление одного бита увеличивает в 2 раза то количество значений, которое можно закодировать. 1 байт состоит из 8 бит и способен закодировать 256 значений.
Традиционно для того чтобы закодировать один символ используют количество информации равное 1 байту. Поэтому чаще всего одному символу текста, хранимому в компьютере, соответствует один байт памяти.
Наряду с битами и байтами используют и большие единицы измерения информации.
- 1 бит {0,1};
- 1 байт = 8 бит;
- 1 Кбайт = 2 10 байт = 1024 байт;
- 1 Мбайт = 2 10 Кбайт = 1024 Кбайт = 2 20 байт;
- 1 Гбайт = 2 10 Мбайт = 1024 Мбайт = 2 30 байт;
- 1 Тбайт = 2 10 Гбайт = 1024 Гбайт = 2 40 байт.
- 1 Пбайт = 2 10 Тбайт = 1024 Тбайт = 2 50 байт.
Подробнее о информации в компьютерных системах можно прочтитать в статье Понятие информации. Информатика
Добавление скрытых символов в текст
Студенты придумали следующий оригинальный вариант увеличения уникальности. Они вставляют символы, написанные самым мелким шрифтом, или буквы, окрашенные в белый цвет. Такие знаки не видны в тексте, визуально не выделяются на общем фоне, а программы-анализаторы показывают высокую оригинальность.
Но разработчики систем антиплагиата знают эти способы и борются с ними. Тем более что при внесении этого контента в Word и нажатии кнопки «Очистить формат» большинство скрытых символов становятся видимыми.
В 2017 г. СМИ писали о студенте, который додумался создать в дипломной работе между 2 словами невидимый объект типа «Надпись» размером с 1 букву. Юноша вставил в него более 20 тыс. знаков контента, состоящего из 40 фрагментов одного и того же оригинального текста по 500 символов каждый.
Программа проверила материал и выдала отчет о высокой уникальности.
Эти знаки определялись как рисунок и не были видны в Word. Но программа-анализатор приняла их за необрабатываемый текст, прибавила все знаки к общему количеству и вывела приемлемый процент оригинальности.
Данный способ часто применяют студенты в своих работах.
О символе евро
В разных кодировках символ евро расположен на разных позициях да и вообще бывает он не во всех кодировках:
| Кодировка | Позиция |
| cp1250 | 128 |
| cp1251 | 136 |
| cp1252 | 128 |
| cp1253 | 128 |
| cp1254 | 128 |
| cp1255 | 128 |
| cp1257 | 128 |
| cp1258 | 128 |
| cp874 | 128 |
| ISO-8859-1 | отсутствует |
| ISO-8859-2 | отсутствует |
| ISO-8859-4 | отсутствует |
| ISO-8859-5 | отсутствует |
| ISO-8859-7 | отсутствует |
| ISO-8859-9 | отсутствует |
| ISO-8859-11 | отсутствует |
| ISO-8859-15 | 164 |
| ISO-8859-16 | 164 |
| KOI8-R | отсутствует |
| KOI8-U | отсутствует |
Кодировка ISO-8859-1 широко распространена, но не включает знак евро. Если Вам это нужно, самое простое, что можно сделать это использовать cp1252 или ISO-8859-15 вместо этой кодировки, потому что они почти идентичны, но содержат драгоценный символ.
Вместо ISO-8859-2, можно использовать ISO-8859-16, но эта кодировка содержит много различий. Поэтому здесь проще добавить в кодировку этот символ, как описано выше. То же самое верно и для других кодировок.
Как самому перекодировать текст
Сервисы по выявлению процента уникальности уже могут обнаружить большинство ухищрений, на которые идут пользователи. Но эти системы пока не научились распознавать метод кодирования текста. Поэтому есть смысл применить его при написании текста.
 Программист может изменить внутренний код.
Программист может изменить внутренний код.
Каждый документ имеет какую-либо раскладку (KOI8-U, Windows-1251, ASCII и т. д.) со своим внутренним кодом. Если научиться модифицировать его правильно, то можно получить на выходе текст, визуально не отличающийся от первоисточника. Но профессиональную кодировку может сделать лишь программист.
Самому изменить его сложно, т. к. при его открытии появляется бессмысленный набор знаков, назначение которых понимает только профессионал. Простому пользователю, чтобы разобраться в них, потребуется несколько недель или месяцев.
Но можно попробовать сделать псевдошифрование. Метод заключается в следующем. Чтобы текст прошел антиплагиат, необязательно менять внутренний код, достаточно сменить его раскладку. Этот метод хуже, но большинство систем показывают высокую уникальность.
Смена кода в Word
В этой программе тексту можно придать не только нужный формат (docx или doc), но и задать любую раскладку. Нужно только правильно выполнить приведенную последовательность действий.
Для смены кода нужно:
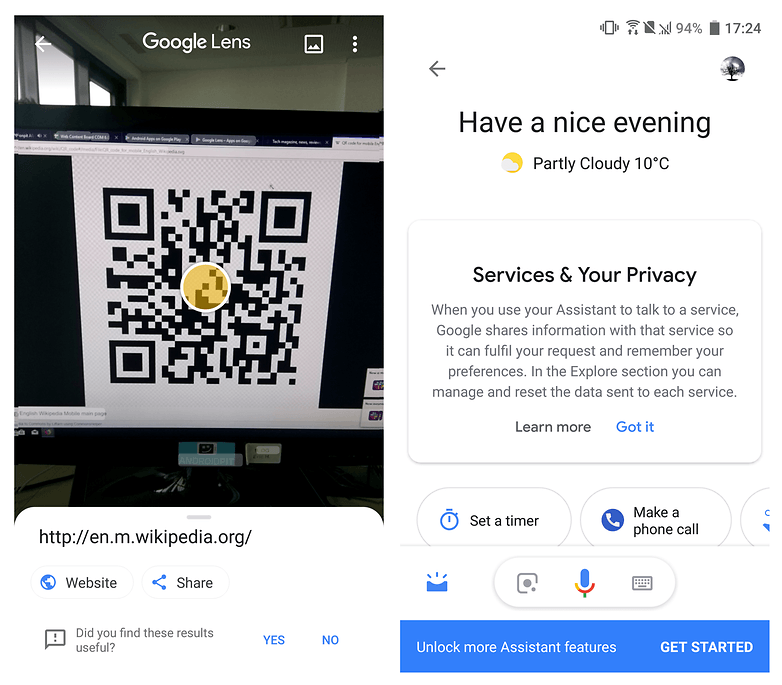
- Найти нужный документ и открыть его.
- Войти в пункт меню «Файл» и нажать на кнопку «Сохранить как».
- Выбрать любое имя.
- В поле «Тит файла» отыскать надпись «Простой текст» и кликнуть по ней.
- Нажать кнопку «Сохранение».
- В появившемся окне выбрать нужную кодировку и записать файл в ПК.
Если все сделано правильно, то появится текст. При неверном написании символов или слов процедуру повторяют до получения читабельного варианта.
 Некоторые кодировки применяются к определенным языкам.
Некоторые кодировки применяются к определенным языкам.
Замена кодировки в блокноте
Иногда обойти систему анализа оригинальности удается с помощью перемещения контента из Word в текстовый редактор «Блокнот», а затем вставки его обратно.
 Смена кодировки.
Смена кодировки.
Чтобы сменить кодировку, надо сделать следующее:
- Открыть word-файл и скопировать текст.
- Вставить его в блокнот.
- В меню нажать на «Файл» и выбрать «Сохранить как».
- Указать в нижнем поле открывшегося окна раскладку контента, а в остальных — его тип и имя.
- Сохранить текстовый файл.
- Перенести его в Word.
Работа с изображениями
Кодирование рисунка или фотографии требует навыка. При попытке зашифровать графический файл, а затем открыть его в редакторе, в тексте появится абракадабра из непонятных символов и программа антиплагиата откажется принимать контент.
Чтобы все было корректно распознано, рекомендуется поступить так:
- Открыть документ.
- С помощью меню «Файл» выбрать необходимые параметры.
- Перейти в пункт «Дополнительно» и кликнуть по полю «Общие».
- Согласиться с методом преобразования.
- Выбрать надпись «Кодированный текст».
- Подобрать кодировку и нажать на кнопку «Сохранить».
 Наглядная инструкция по изменению кодировки рисунку.
Наглядная инструкция по изменению кодировки рисунку.
Электронная таблица в 1С средствами табличного документа
Функционал электронной таблицы для программ на платформе 1С реализован на основе табличного документа. Функционал реализован в виде обработки (тонкий клиент). В формулах электронной таблицы можно использовать любые языковые конструкции, процедуры и функции 1С, ссылки на другие ячейки электронной таблицы. Допустимо обращаться к ячейкам электронной таблицы по имени именованной области. В случае использования в формулах электронной таблицы данных из самой таблицы пересчет зависимых ячеек с формулами производится автоматически. Электронную таблицу можно сохранить в файл формата xml.
1 стартмани
Что представляет собой кодировка и от чего она зависит?
Для каждого региона кодировка может в значительной степени разниться. Для понимания кодировки необходимо знать то, что информация в текстовом документе сохраняется в виде некоторых числовых значений. Персональный компьютер самостоятельно преобразует числа в текст, используя при этом алгоритм отдельно взятой кодировки. Для стран СНГ используется кодировка файлов с названием «Кириллица», а для других регионов, таких как Западная Европа, применяется «Западноевропейская (Windows)». Если текстовый документ был сохранен в кодировке кириллицы, а открыт с использованием западноевропейского формата, то символы будут отображаться совершенно неправильно, представляя собой бессмысленный набор знаков.
 При открытии документа, сохраненного одним типом кодировки, в другом формате кодировки невозможно будет прочитать
При открытии документа, сохраненного одним типом кодировки, в другом формате кодировки невозможно будет прочитать
Во избежание недоразумений и облегчения работы разработчики внедрили специальную единую кодировку для всех алфавитов – «Юникод». Этот общепринятый стандарт кодировки содержит в себе практически все знаки большинства письменных языков нашей планеты. К тому же он преобладает в интернете, где так необходима подобная унификация для охвата большего количества пользователей и удовлетворения их потребностей.
 Тип кодировок, которые используются, как стандартные для всех языков
Тип кодировок, которые используются, как стандартные для всех языков
«Word 2013» работает как раз на основе Юникода, что позволяет обмениваться текстовыми файлами без применения сторонних программ и исправления кодировок в настройках. Но нередко пользователи сталкиваются с ситуацией, когда при открытии вроде бы простого файла вместо текста отображаются только знаки. В таком случае программа «Word» неправильно определила существующую первоначальную кодировку текста.
Windows-125x
В начале 90-х годов компания Microsoft разработала группу кодировок для ОС Windows. Среди прочих хочется отметить две кодировки: Windows-1251 и Windows-1252.
Windows-1251 была разработана на базе «самодельных» кодировок для русификаторов Windows при участии российской компании-разработчика ПО «ПараГраф» и СП «Диалог» — совместного советско-американского предприятия в области вычислительной техники. В эту кодировку вошли все символы русского и близких к нему языков: украинского, белорусского, болгарского, сербского и македонского. На практике этого оказалось достаточно, чтобы кодировка Windows-1251 закрепилась в интернете вплоть до распространения UTF-8.
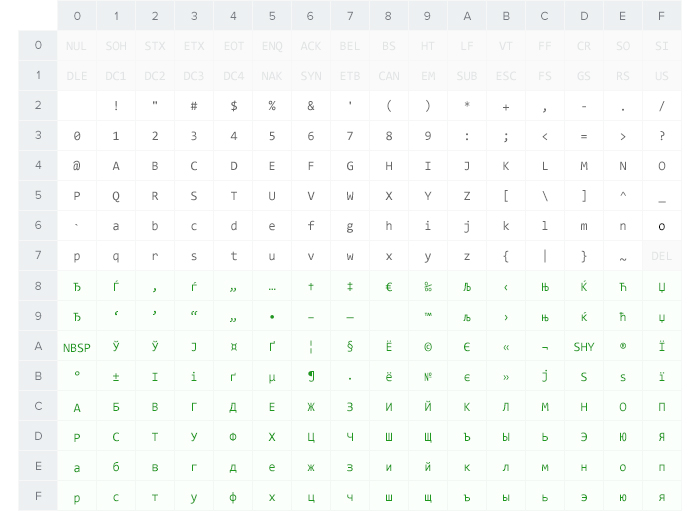 Таблица кодов символов в Windows-1251.
Таблица кодов символов в Windows-1251.
Windows-1252 была разработана на основе кодировки ISO-8859-1 путем замены ряда непечатных контрольных символов на печатные (в частности, символ евро, ряд пунктуационных и несколько других символов). Сходство этих двух кодировок часто приводило к неверному отображению текста, когда вместо новых символов из Windows-1252 отображались знаки вопроса. Эта ситуация была настолько частой, что многие почтовые клиенты для отображения писем кодировки ISO-8859-1 стали использовать Windows-1252. В конечном итоге такое поведение было внесено в спецификацию HTML 5 в качестве требования.
Есть ли альтернатива кодировке текста в WORD для антиплагиата?
Конечно есть – достаточно обложиться учебниками и справочниками, написав работу самому. Но для многих студентов — это самая настоящая мука, отнимающая от одного до нескольких дней. Есть и альтернативные способы:
Сделать глубокий рерайт готовящейся работы – для этого не нужно много знаний, но нужен соответствующий склад ума, позволяющий переписать текст своими словами. Одновременно с этим необходимо полностью изменить структуру документа – поработать над абзацами (уменьшить или увеличить объём, добавить новые или убрать некоторые из них), переработать тексты, добавить свои мысли. Это довольно трудно, зато даёт великолепные результаты. Глубокий рерайт – самый простой выход из ситуации, когда нужно поднять уникальность чужой работы.
Заказать написание работы у других студентов или у фрилансеров – в интернете полно людей, зарабатывающих деньги на написании дипломов, курсовых, рефератов и других работа. Правда, для этого студенту потребуются деньги – придётся потратить то, что откладывалось на очередную гулянку с однокурсниками или свидание с девушкой. Но здесь есть определённая опасность – человек, которому заказано написание работы, может пропасть
Поэтому поиску надёжного человека придётся уделить особое внимание.
Использовать методы обмана – это внедрение дополнительных слов и выражений, замена слов синонимами, метод шингла (нужно заменить каждое третье слово в тексте), заменить русскоязычные символы на греческие или английские. Также существует методика внесения ошибок – в словах меняются отдельные буквы, убираются или добавляются лишние пробелы
Но обмануть Антиплагиат это не поможет – он прекрасно распознает такие уловки, показывая крайне низкую уникальность. А если текст изобилует сотнями ошибок, то он получает статус «Подозрительный документ» – такую работу никто не примет.
Есть ещё один способ – разработать собственный алгоритм кодировки файлов под Антиплагиат. Но это не копеечное дело – придётся провести сотни тестов над сотнями работ. К тому же, для успешного тестирования собственного инструмента потребуется доступ к полной версии Антиплагиата, а это очень дорого. Дешевле заказать написание уникальной работы, чем пытаться заново изобрести велосипед.
Ещё проще воспользоваться уже готовым инструментом для повышения уникальности курсовых и дипломных работ, диссертаций и рефератов – нашим сервисом. Его преимущества:
Повышение уникальности за 100 рублей и две минуты времени – отличное решение для тех, у кого возникают трудности с самостоятельным написанием работ.
Как поменять кодировку в «Mozilla Firefox»
Для этого пользователю потребуется:
Шаг 1. Запустить браузер и открыть меню, нажав по иконке трех линий левой клавишей мыши в правом верхнем углу страницы.
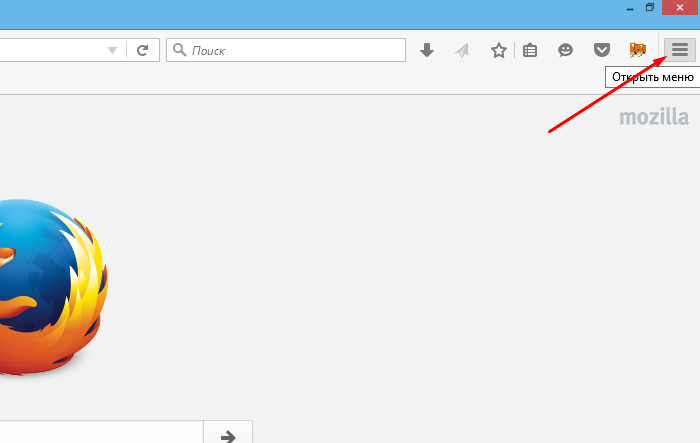 Нажимаем по иконке из трех линий в правом верхнем углу
Нажимаем по иконке из трех линий в правом верхнем углу
Шаг 2. В контекстном меню запустить «Настройки».
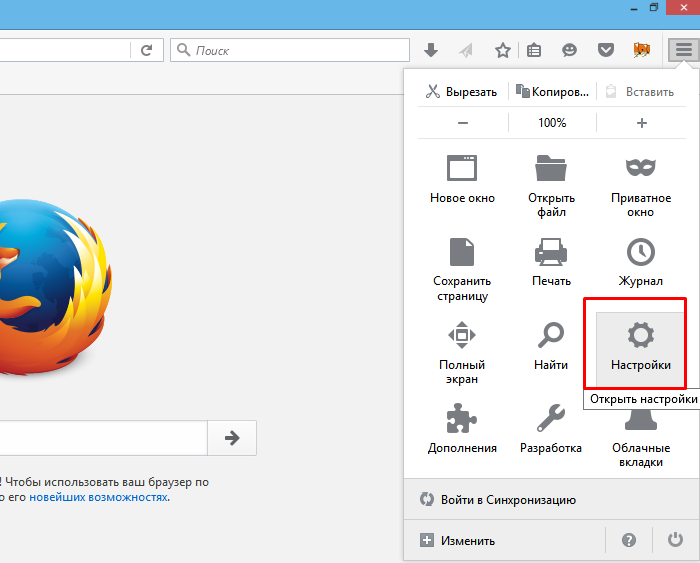 Открываем «Настройки»
Открываем «Настройки»
Шаг 3. Перейти во вкладку «Содержимое».
 Переходим во вкладку «Содержимое»
Переходим во вкладку «Содержимое»
Шаг 4. В разделе «Шрифты и цвета» нажать на блок «Дополнительные».
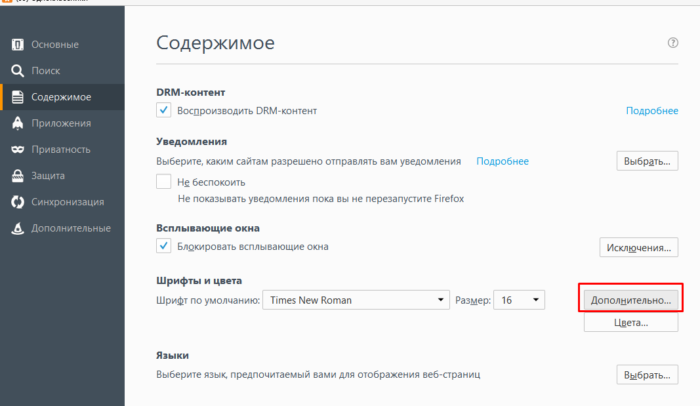 В разделе «Шрифты и цвета» нажимаем по блоку «Дополнительно»
В разделе «Шрифты и цвета» нажимаем по блоку «Дополнительно»
Шаг 5. Перед пользователем отобразится специальная панель, на которой будет указана использующаяся кодировка. Для ее изменения потребуется нажать на название кодировки и выбрать нужную.
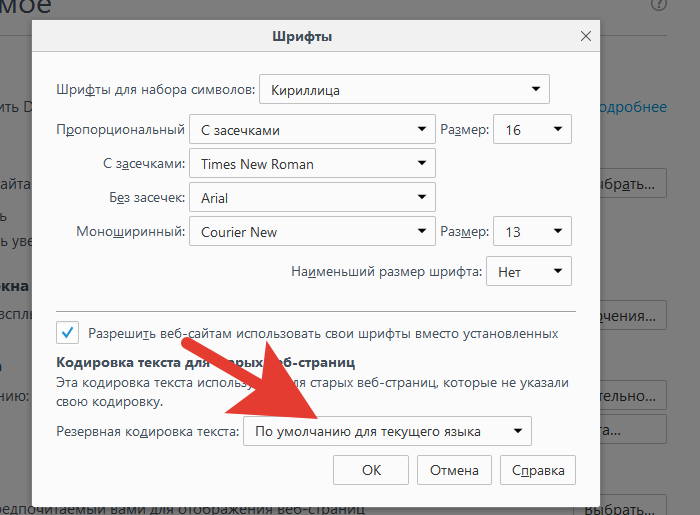 Нажимаем на название кодировки
Нажимаем на название кодировки
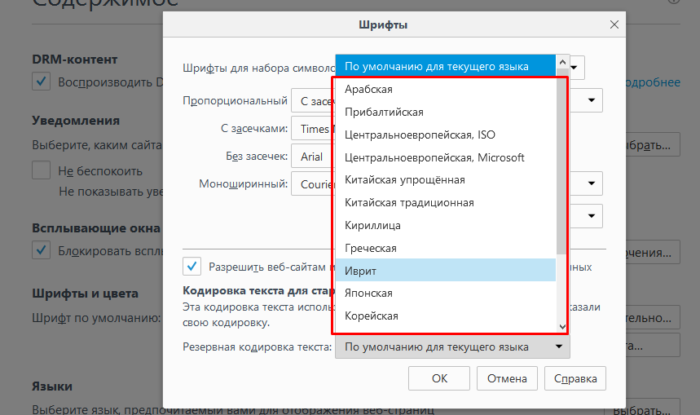 Выбираем подходящую кодировку, нажимаем «ОК»
Выбираем подходящую кодировку, нажимаем «ОК»
Растровое изображение
Графическая информация, представленная в виде рисунков, фотографий, слайдов, подвижных изображений (анимация, видео), схем, чертежей, может создаваться и редактироваться с помощью компьютера, при этом она соответствующим образом кодируется. В настоящее время существует достаточно большое количество прикладных программ для обработки графической информации, но все они реализуют три вида компьютерной графики: растровую, векторную и фрактальную. Мы рассмотрим самую распространенный, растровый формат кодирования изображения.
Графические данные на мониторе представляются в качестве растрового изображения. Если более пристально рассмотреть графическое изображение на экране монитора компьютера, то можно увидеть большое количество разноцветных точек (пикселов – от англ. pixel, образованного от picture element – элемент изображения), которые, будучи собраны вместе, и образуют данное графическое изображение. Каждому пикселю присвоен особый код, в котором хранится информация об оттенке пикселя. Из этого можно сделать вывод: графическое изображение в компьютере определенным образом кодируется и должно быть представлено в виде графического файла.
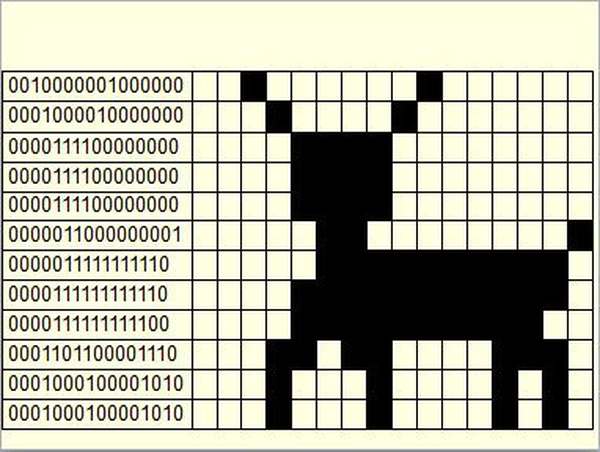
Файлы, созданные на основе растровой графики, предполагают хранение данных о каждой отдельной точке изображения. Для отображения растровой графики не требуется сложных математических расчетов, достаточно лишь получить данные о каждой точке изображения (ее координаты и цвет) и отобразить их на экране монитора компьютера.
Что делать, если рисунок цветной? Формирование цветного изображения на мониторе осуществляется путём смешивания 3-х основных цветов: синего, красного и зелёного. В этом случае для кодирования цвета пикселя уже не обойтись одним битом. В системе кодирования цветных изображений RGB (R — красный, G — зеленый и B — синий) яркость каждой цветовой составляющей (или, как говорят, каждого канала) кодируется целым числом от 0 до 255. При этом код цвета — это тройка чисел (R,G,B), яркости отдельных каналов. Цвет (0,0,0) — это черный цвет, а (255,255,255) — белый. Если все составляющие имеют равную яркость, получаются оттенки серого цвета, от черного до белого. При кодировании цвета на веб-страницах также используется модель RGB, но яркости каналов записываются в шестнадцатеричной системе счисления (от 0016 до FF16), а перед кодом цвета ставится знак #. Например, код красного цвета записывается как #FF0000, а код синего — как #0000FF.
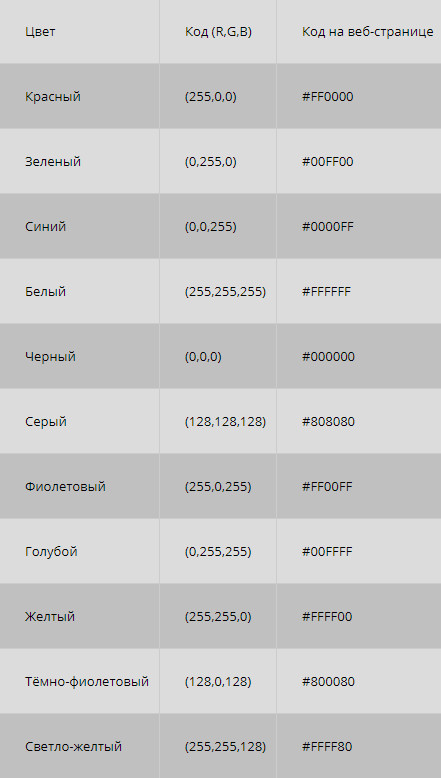
Всего есть по 256 вариантов яркости каждого из трех цветов. Это позволяет закодировать 2563= 16 777 216 оттенков, что более чем достаточно для человека. Так как 256 = 28, каждая из трех составляющих занимает в памяти 8 бит или 1 байт, а вся информация о каком-то цвете — 24 бита (или 3 байта). Эта величина называется глубиной цвета.
Кодировки стандарта ASCII[править]
| Определение: |
| ASCII — таблицы кодировок, в которых содержатся основные символы (английский алфавит, цифры, знаки препинания, символы национальных алфавитов(свои для каждого региона), служебные символы) и длина кода каждого символа бит. |
бит:
ASCII7 — первая кодировка, пригодная для работы с текстом. Помимо маленьких букв английского алфавита и служебных символов, содержит большие буквы английского языка, цифры, знаки препинания и другие символы.
Кодировки стандарта ASCII ( бит):
- ASCII — первая кодировка, в которой стало возможно использовать символы национальных алфавитов.
- КОИ8-R — первая русская кодировка. Символы кириллицы расположены не в алфавитном порядке. Их разместили в верхнюю половину таблицы так, чтобы позиции кириллических символов соответствовали их фонетическим аналогам в английском алфавите. Это значит, что даже при потере старшего бита каждого символа, например, при проходе через устаревший семибитный модем, текст остается «читаемым».
- CP866 — русская кодировка, использовавшаяся на компьютерах IBM в системе DOS.
- Windows-1251 — русская кодировка, использовавшаяся в русскоязычных версиях операционной системы Windows в начале 90-х годов. Кириллические символы идут в алфавитном порядке. Содержит все символы, встречающиеся в типографике обычного текста (кроме знака ударения).
Структурные свойства таблицыправить
- Цифры 0-9 представляются своими двоичными значениями (например, ), перед которыми стоит . Таким образом, двоично-десятичные числа (BCD) превращаются в ASCII-строку с помощью простого добавления слева к каждому двоично-десятичному полубайту.
- Буквы A-Z верхнего и нижнего регистров различаются в своём представлении только одним битом, что упрощает преобразование регистра и проверку на диапазон. Буквы представляются своими порядковыми номерами в алфавите, записанными в двоичной системе счисления, перед которыми стоит (для букв верхнего регистра) или (для букв нижнего регистра).
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NUL | SOH | STX | ETX | EOT | ENQ | ACK | BEL | BS | TAB | LF | VT | FF | CR | SO | SI | |
| 1 | DLE | DC1 | DC2 | DC3 | DC4 | NAK | SYN | ETB | CAN | EM | SUB | ESC | FS | GS | RS | US |
| 2 | ! | » | # | $ | % | & | ‘ | ( | ) | * | + | , | — | . | ||
| 3 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ; | < | = | > | ? | ||
| 4 | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| 5 | P | Q | R | S | T | U | V | W | X | Y | Z | \ | ^ | _ | ||
| 6 | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| 7 | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | DEL |
Примеры[править]
Если записать строку ‘hello мир’ в файл exampleBOM, а затем сделать его hex-дамп, то можно убедиться в том, что разные символы кодируются разным количеством байт. Например, английские буквы,пробел, знаки препинания и пр. кодируются одним байтом, а русские буквы — двумя
Код на pythonправить
#!/usr/bin/env python
#coding:utf-8
import codecs
f = open('exampleBOM','w')
b = u'hello мир'
f.write(codecs.BOM_UTF8)
f.write(b.encode('utf-8'))
f.close()
hex-дамп файла exampleBOMправить
| Символ | BOM | h | e | l | l | o | Пробел | м | и | р | |||||
| Код в UNICODE | EF | BB | BF | 68 | 65 | 6C | 6C | 6F | 20 | D0 | BC | D0 | B8 | D1 | 80 |
| Код в UTF-8 | 11101111 | 10111011 | 10111111 | 01101000 | 01100101 | 01101100 | 01101100 | 01101111 | 00100000 | 11010000 | 10111100 | 11010000 | 10111000 | 11010001 | 10000000 |
Сайты для перекодировки онлайн
Сегодня мы расскажем о самых популярных и действенных сайтах, которые помогут угадать кодировку и изменить ее на более понятную для вашего ПК. Чаще всего на таких сайтах работает автоматический алгоритм распознавания, однако в случае необходимости пользователь всегда может выбрать подходящую кодировку в ручном режиме.
Способ 1: Универсальный декодер
Декодер предлагает пользователям просто скопировать непонятный отрывок текста на сайт и в автоматическом режиме переводит кодировку на более понятную. К преимуществам можно отнести простоту ресурса, а также наличие дополнительных ручных настроек, которые предлагают самостоятельно выбрать нужный формат.
Работать можно только с текстом, размер которого не превышает 100 килобайт, кроме того, создатели ресурса не гарантируют, что перекодировка будет в 100% случаев успешной. Если ресурс не помог – просто попробуйте распознать текст с помощью других способов.
- Копируем текст, который нужно декодировать, в верхнее поле. Желательно, чтобы в первых словах уже содержались непонятные символы, особенно в случаях, когда выбрано автоматическое распознавание.
- Указываем дополнительные параметры. Если необходимо, чтобы кодировка была распознана и преобразована без вмешательства пользователя, в поле «Выберите кодировку» щелкаем на «Автоматически». В расширенном режиме можно выбрать начальную кодировку и формат, в который нужно преобразовать текст. После завершения настройки щелкаем на кнопку «ОК».
- Преобразованный текст отобразится в поле «Результат», оттуда его можно скопировать и вставить в документ для последующего редактирования.
Способ 2: Студия Артемия Лебедева
Еще один сайт для работы с кодировкой, в отличие от предыдущего ресурса имеет более приятный дизайн. Предлагает пользователям два режима работы, простой и расширенный, в первом случае после декодировки пользователь видит результат, во втором случае видна начальная и конечная кодировка.
- Выбираем режим декодировки на верхней панели. Мы будем работать с режимом «Сложно», чтобы сделать процесс более наглядным.
- Вставляем нужный для расшифровки текст в левое поле. Выбираем предполагаемую кодировку, желательно оставить автоматические настройки — так вероятность успешной дешифровки возрастет.
- Щелкаем на кнопку «Расшифровать».
- Результат появится в правом поле. Пользователь может самостоятельно выбрать конечную кодировку из ниспадающего списка.
С сайтом любая непонятная каша из символов быстро превращается в понятный русский текст. На данный момент работает ресурс со всеми известными кодировками.
Способ 3: Fox Tools
Fox Tools предназначен для универсальной декодировки непонятных символов в обычный русский текст. Пользователь может самостоятельно выбрать начальную и конечную кодировку, есть на сайте и автоматический режим.
Дизайн простой, без лишних наворотов и рекламы, которая мешает нормальной работе с ресурсом.
- Вводим исходный текст в верхнее поле.
- Выбираем начальную и конечную кодировку. Если данные параметры неизвестны, оставляем настройки по умолчанию.
- После завершения настроек нажимаем на кнопку «Отправить».
- Из списка под начальным текстом выбираем читабельный вариант и щелкаем на него.
- Вновь нажимаем на кнопку «Отправить».
- Преобразованный текст будет отображаться в поле «Результат».
Несмотря на то, что сайт якобы распознает кодировку в автоматическом режиме, пользователю все равно приходится выбирать понятный результат в ручном режиме. Из-за данной особенности куда проще воспользоваться описанными выше способами.
Рассмотренный сайты позволяют всего в несколько кликов преобразовать непонятный набор символов в читаемый текст. Самым практичным оказался ресурс Универсальный декодер — он безошибочно перевел большинство зашифрованных текстов.
Опишите, что у вас не получилось.
Наши специалисты постараются ответить максимально быстро.
Противопоказания при кодировании от алкоголизма


Основные противопоказания при медикаментозной кодировке от алкоголя:
- беременность и период грудного вскармливания;
- болезни печени;
- грибковые заболевания;
- остеопороз;
- астма;
- глаукома;
- эпилепсия;
- заболевания сердечно-сосудистой системы.
Основные противопоказания к кодировке психотерапевтическим методом:
- недавно перенесшим инфаркт миокарда;
- Наличие некоторых видов хронических заболеваний;
- при обострении инфекций;
- во время алкогольного опьянения;
- при наличии абстинентного синдрома;
- в момент гипертонического кризиса;
- страдающим психическими заболеваниями;
- если у пациента наблюдаются бредовые состояния или галлюцинации.
Почему стоит делать кодировку от алкоголя?
 Стоит ли делать кодировку от алкоголя?
Стоит ли делать кодировку от алкоголя?
Кодирование позволяет начать процессы лечения от алкоголизма
Одно из главных требований к началу лечения алкоголизма — прекращения употребления алкоголя. И если пациент не может прекратить пить спиртное своим желанием, своей силой воли, то рекомендуется кодирование как гарантированный способ прекращения употребления алкогольных напитков. Кроме того, после противоалкогольного закодирования у пациента появляется возможность восстановить свое здоровье, наладить семейные отношения и рабочую карьеру.
Кодировка от алкоголя позволяет восстановить свое здоровье
Здоровье у пьющего человека практически всегда будет подорвано. Алкоголь создает на промежуточной стадии окисления в организме сильнейшее токсичное вещество — ацетальдегид . Оно способно значительно подорвать здоровье внутренних органов пьющего алкоголь человека.
Кодировка позволяет избавиться от употребления алкоголя на какое-то время, а значит прекратится воздействие на организм токсином ацетальдегидом и начать «ремонтировать» свое здоровье.
Восстановления полноценного рабочего режима после кодирования
Пьянство значительно мешает работе человека. Он способен пропускать рабочие дни из-за запоев, опаздывать на работу из-за похмельного туманного утра, быть пьяным на рабочем месте. Все это часто не допускает работодатель, и человек теряет свое рабочее место, кадровую перспективу.
В процессе увеличения доз потребления и частоты пьяных посиделок, человек все больше и больше теряет возможность возвращения трезвой нормальной жизни, а значит и возможности полноценно работать и зарабатывать денег для себя и семьи.

Также происходит постепенная деградация личности, так как спирт (этанол) уничтожает часть популяции нейронов в мозгу. С каждой пьянкой нейронов и их связей в голове у пьяницы становится все меньше и меньше.
Кодировка от употребления спиртного позволит восстановить отношения в семье
Семье пьющего человека очень трудно — ведь терпеть пьяного всегда тяжело. Он часто не контролирует ситуацию и свои эмоции, раздражен, и не дает семье и окружающим покоя. Многие сталкивались с такой ситуацией в детстве. У кого-то родственник пьет, и с ним одни проблемы. У кого-то знакомые намучались и не знают как сделать так, чтобы алкоголик прекратил пить навсегда
Кодировка от спиртного позволяет прекратить на достаточно длительное время пьянство, запои, пьяные дебоши и вечерние скандалы на фоне алкоголизма. После окончания кодировки ее можно будет сделать снова.
Поэтому кодировка от алкоголя — это хороший способ прекращения употребления спиртного у больного алкогольной зависимостью.
ISO/IEC 8859
Ранние кодировки были ограничены 7 битами из-за особенностей некоторых протоколов передачи данных. Однако со временем эти ограничения свою актуальность потеряли, в то время как необходимость в дополнительных символах для языков, использующих латинский алфавит, только росла. Поэтому в середине 80-х началась работа над группой 8-битных кодировок, получившей название ISO/IEC 8859. Все кодировки этой группы были основаны на ASCII. Помимо расширения диапазона доступных символов за счет восьмого бита, на печатные символы была заменена часть устаревших к тому моменту непечатных управляющих символов.
Здесь стоит отметить две кодировки из группы. Первая — ISO-8859-1 — была опубликована в 1987 году. Она включала в себя так называемый «Латинский алфавит номер 1» (сокращенно Latin-1), состоящий из 191 символа латинского письма. Этот набор символов используется по всей Северной и Южной Америке, в Западной Европе, Океании и на большей части Африки. Кодировка ISO-8859-1 стала основой для наиболее популярных 8-битных кодировок.
В 1988 году была опубликована ISO-8859-5. Она была создана для работы с кириллическими языками. Включенные в эту кодировку символы обеспечивали полную поддержку русского, белорусского, болгарского, сербского и македонского языков. А вот для полной поддержки украинского языка ей не хватало буквы «ґ». Особого распространения эта кодировка не получила, но интересен сам факт разработки кириллической кодировки в рамках группы кодировок ISO/IEC.
Изменение кодировки в программе «Notepad ++»
Подобное приложение используется многими программистами для создания сайтов, различных приложений и многого другого
Поэтому очень важно сохранять и создавать файлы, используя необходимую кодировку. Для того, чтобы настроить нужный вариант для пользователя, следует:
Шаг 1. Запустить программу и в верхнем контекстном меню выбрать вкладку «Кодировки».
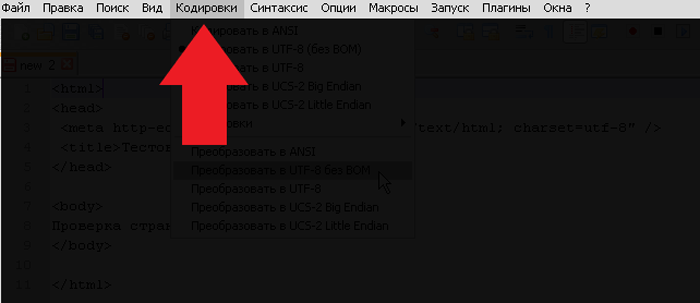 Выбираем вкладку «Кодировки»
Выбираем вкладку «Кодировки»
Шаг 2. В выпадающем списке пользователю требуется выбрать из списка необходимую для него кодировку и щелкнуть на нее.
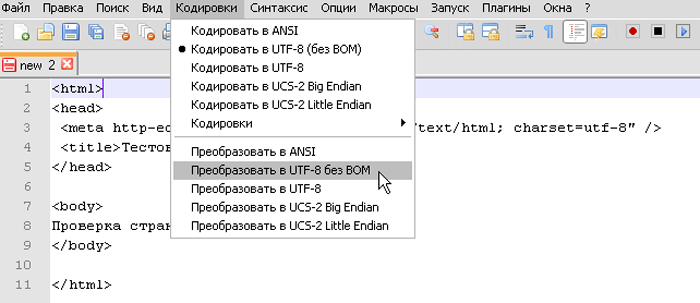 Выбираем из списка необходимую кодировку, щелкаем на ней
Выбираем из списка необходимую кодировку, щелкаем на ней
Шаг 3
Правильность проведения процедуры легко проверить, обратив внимание на нижнюю панель программы, которая будет отображать только что измененную кодировку
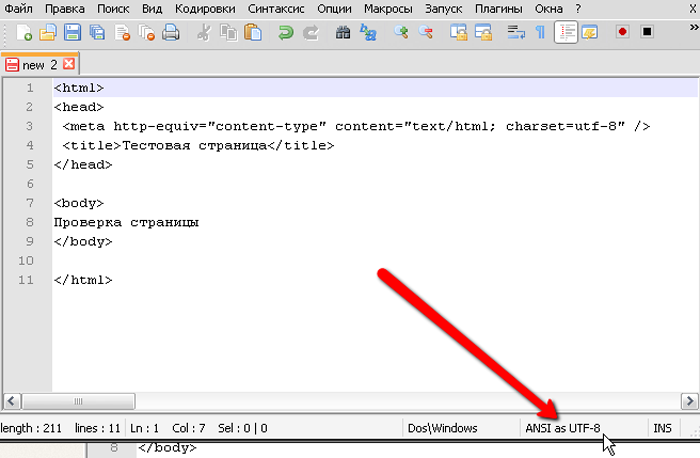 В нижней панели программы можно увидеть измененную кодировку
В нижней панели программы можно увидеть измененную кодировку
Заключение
Зачем нам знать, как менять кодировку в текстовых редакторах? IDE Visual C++ сама выбирает кодировку. Если вы откроете любой файл с исходным кодом (.cpp или .h) в простом текстовом редакторе, то увидите, что кодировка этого файла — ANSI.
В программах на ассемблере мы тоже будем использовать ANSI — этого требует компилятор. А вот когда будем разбирать скриптовые языки, то файлы с исходниками можно будет сохранять в UTF-8.
Источники
- http://oldshatalov.ghost17.ru/ru/articles/theory/text_editors.html
- https://mb4.ru/text-editors/notepad/146-notepad-change-default-encoding.html
- http://workip.ru/stati/smena-kodirovki-teksta-v-bloknote.html
- https://besthard.ru/faq/kak-izmenit-kodirovku-v-vord/
- https://support.office.com/ru-ru/article/%D0%B2%D1%8B%D0%B1%D0%BE%D1%80-%D0%BA%D0%BE%D0%B4%D0%B8%D1%80%D0%BE%D0%B2%D0%BA%D0%B8-%D1%82%D0%B5%D0%BA%D1%81%D1%82%D0%B0-%D0%BF%D1%80%D0%B8-%D0%BE%D1%82%D0%BA%D1%80%D1%8B%D1%82%D0%B8%D0%B8-%D0%B8-%D1%81%D0%BE%D1%85%D1%80%D0%B0%D0%BD%D0%B5%D0%BD%D0%B8%D0%B8-%D1%84%D0%B0%D0%B9%D0%BB%D0%BE%D0%B2-60d59c21-88b5-4006-831c-d536d42fd861