Lsi-текст или seo-текст
Содержание:
Как создавать LSI-тексты правильно?
Наилучший вариант – выбрать автора, который хорошо разбирается в нужной вам теме или хотя бы умеет работать с экспертными мнениями в сети. Тогда ему достаточно ключевых запросов, чтобы создать интересный и полезный контент. Он сможет самостоятельно подобрать слова и фразы, связанные с основным запросом по смыслу, и раскрыть тему естественным образом. В результате даже появилась новая сфера деятельности LSI-копирайтинг.
К сожалению, этот вариант редко используется заказчиками. Как правило, рядовой копирайтер не фокусируется на раскрытии темы, а просто «сдирает» наиболее подходящую по теме информацию с других источников.
В таком случае требуется составление ТЗ, в котором для копирайтера прописываются:
- требования к статье;
- объём и структура текста;
- LSI-ключи.
LSI-технология
Что это
Латентно-семантическое индексирование (latent semantic indexing) — это способ поисковых систем анализировать текст не только по ключевым фразам, но и по смыслу.
Как латентно-семантическое индексирование влияет на SEO
Разработчики Яндекс и Google стараются сделать так, чтобы в топ выдачи попадали максимально полезные, соответствующие запросам пользователей (релевантные), страницы. Сеошники как могут подстраиваются под эти требования. Но чаще пытаются манипулировать выдачей и продвинуть сайт в обход системы.
С каждым обновлением поисковых алгоритмов снижается роль оптимизации текстов ключевиками. Старая «школа SEO» работает все хуже и хуже.
Нужен ли LSI-копирайтинг в продвижении сайтов
Все чаще я слышу, что для вывода сайтов в топ ищут не крутого сеошника, а хорошего редактора или копирайтера. Подход такой: «даем специалисту тему, он готовит экспертный контент, который гарантированно попадает в топ выдачи».
Я согласен с таким подходом, но только отчасти. Если нужно попасть в топ-5 по конкретным запросам, экспертный контент побеждает. Но такие статьи далеко не всегда собирают максимум трафика. Вот в чем вижу проблемы:
- Технология только развивается. Да, поисковики научились искать информацию по синонимам, близким по смыслу словам и словоформам. Но в узких нишах это все еще плохо работает. Там страницы ранжируются только по запросам, слова из которых присутствуют в тексте. Поэтому пока есть смысл собирать и использовать в статьях LSI-фразы.
- Постоянно растет конкуренция. Конечно, полезный контент побеждает сеошные портянки. Но если в топ попали две одинаково крутые страницы, больше трафика принесет та, где есть латентно-семантические слова.
- У бизнеса и целевой аудитории разный словарный запас. Коммерческие тексты копирайтер пишет по брифу или после интервью с заказчиком (использует озвученную терминологию). Но конечные потребители далеко не всегда называют продукты или услуги теми словами, которыми пользуются профессионалы. Кажется, мелочь, но это сильно влияет на трафик.
Как привести на сайт больше трафика
Перед подготовкой контента создаем латентно-семантическое ядро. Фразы из него используем в тексте. Чем больше нашли задающих тематику слов, тем больше трафика из поисковых систем собирает наша страница.
 Пример тематического ядра для запроса «трубы холодного водоснабжения».
Пример тематического ядра для запроса «трубы холодного водоснабжения».
Напомню, LSI-копирайтинг — это дополнительный инструмент привлечения трафика. Куда важнее, чтобы страница отвечала на вопрос пользователя и была лучше других в выдаче.
Плюсы и минусы анализа семантического ядра конкурентов с помощью специальных сервисов
Многие программы, определяющие ключевые слова на сторонних сайтах, работают по следующему принципу:
- Составляется перечень самых частых поисковых запросов.
- Отбирается 1−10 страниц выдачи для каждого из них.
- Сбор выдачи ключей повторяют с установленной периодичностью: неделя, месяц или год.
Подобный подход имеет свои минусы. Так, программы:
- выдают только видимую часть поисковых запросов на сайтах компаний-конкурентов;
- сохраняют у себя своего рода «шаблон» выдачи, сформированный при сборе ключей;
- способны определять видимость лишь тех поисковых запросов, которые есть в их базах;
- показывают только известные им ключи.
Кроме того:
- чтобы получить достоверные данные о ключах на сайте компании-конкурента, надо знать, когда собираются поисковые запросы (анализируется видимость);
- не все запросы отражаются в поисковой выдаче, и потому программе они не видны. Это может происходить по разным причинам: страницы сайта еще не проиндексированы, поисковая система не ранжирует их из-за длительной загрузки, содержания вирусов и т. д.;
- сведений о том, какие ключевые запросы включены в базу сервиса, используемого для сбора поисковой выдачи, как правило, нет.
То есть программа составляет не достоверное семантическое ядро, положенное в основу сайта, а только его малую видимую часть.

Основываясь на вышеизложенном, можно сказать следующее:
- Семантика конкурирующего сайта, сформированная при помощи специализированных программ, не дает полной актуальной картины.
- Чем более обширна база ключевых слов в программе, тем медленнее обрабатывается выдача и тем менее актуальна семантика. Пока программа формирует поисковую выдачу по началу базы, сведения по концу баз теряют актуальность.
- Программы не разглашают сведения о том, актуальны ли их базы и когда было последнее обновление. Поэтому вам не может быть известно, насколько ключи с конкурирующего сайта, отобранные программой, отражают его реальную семантику.
Но существенным плюсом такого подхода можно назвать получение доступа к большому количеству ключей конкурентов, многие из которых вы можете применять, чтобы расширять семантическое ядро своего сайта. Помимо этого, проверка семантики конкурирующего ресурса позволяет дополнить семантику вашей веб-площадки или проанализировать маркетинговую политику компаний-соперников.
7. Почему ключевые слова LSI — не просто синонимы.
Как упоминал ранее в этой статье, ключевые слова LSI не совсем синонимы. Они на самом деле тесно связанные и актуальные термины.Вот пример: представьте, что хотите написать статью о пицце и узнать, какие термины должны включить, чтобы иметь больше шансов на высокий рейтинг с LSI с точки зрения на странице.Сначала запустите слово «пицца» через Keys4Up.

Кто не знает английского:
- пицца
- сыр
- питание/еда
- корка
- начинка
- блюда/тарелки
- ингредиенты
- ресторан
- пицца
- стол
Теперь давайте посмотрим, что инструмент для связанных ключевых слов SEMRush держит для нас:


Видите, огромную разницу в результатах?
Мы больше не видим список с простыми предложениями ключевых слов, основанных исключительно на слове, которое вводим в инструмент, вместо этого эти результаты дают другую точку зрения, с которой следует рассматривать ключевые слова со скрытой семантической индексацией.Получается, что:
- Румяная корочка
- Начинка с грибами
- Стол в ресторане
- Сыр на тарелке
- И т. д.
Эти фразы будут не лишние в нашем сочинении про вкусную, хрустящую пиццу.Если пишете о пицце и хотите убедиться, что используете LSI, чтобы получить как можно более высокий рейтинг, обязательно включите такие термины, как:
- Сыр
- Пепперони
- Доставка
- Корочка
- Еда
- Ингредиенты
- Ресторан
Для достижения наилучших результатов. Как видите, ключевые слова LSI — это не просто варианты вашего основного ключевого слова. Это тесно связанные термины, которые Google любит видеть при сканировании страниц с определенным ключевым словом.Это все о моделях.
Чем отличается SEO от LSI
Чтобы освоить LSI-копирайтинг, нужно понимать, чем он отличается от привычной оптимизации
Давайте вспомним, на что мы обращаем внимание при работе с SEO-текстами:
- список ключей для прямого и разбавленного вхождения, их количество;
- уровень тошнотности и воды;
- уникальность;
- наращивание ссылочной массы;
- перелинковка.
Как выглядят тексты SEO и LSI в анализе?
Я решила проверить, какие статьи находятся в топ-10 Гугла по запросу “купить одежду для новорожденного”. На первой странице выдачи мне попалась SEO-статья, перенасыщенная ключами. Только представьте, на 2 000 символов пришлось 8–12 ключевых фраз. К тому же много воды, сложноподчиненных и сложносочиненных предложений, которые затрудняют восприятие информации.
Анализ провела с помощью TextAnalyzer.
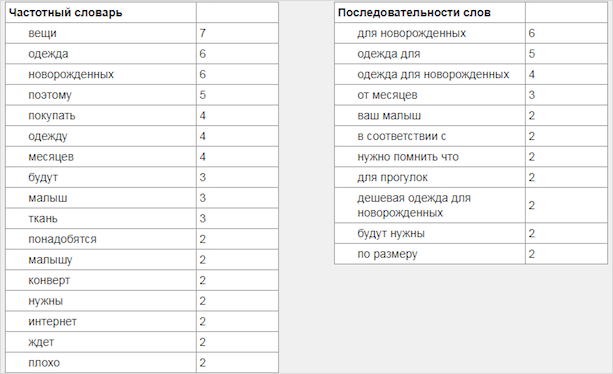
Затем я решила прошерстить выдачу по запросу “что такое SEO”. В первой десятке нашла неплохую статью. Встречаются тематические слова, синонимы, плотность вхождений выглядит естественно. Объем – 10 000 знаков.
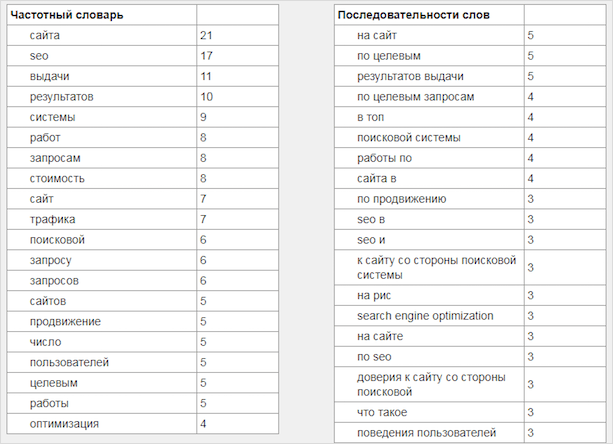
Посмотрите, на первых позициях у ЛСИ-текста стоят тематические слова, их количество умеренно. В случае с SEO-текстом заметна жесткая переоптимизация. SEO-статья пока в топе, но держится она там непрочно.
Что нового в LSI:
- Цена. Компаниям и вебмастерам придется раскошелиться. Минимальный объем LSI-статей – 10 000 знаков, стоимость за килознак в 2-3 раза выше привычного SEO-копирайтинга. Требуются опытные специалисты, время, хорошие программы. Дешевый рерайт не прокатит.
- Упрощенный сбор ТЗ. Специалистам по продвижению не придется ломать голову над ключами, анализировать плотность вхождений. Главная задача – четко и естественно ответить на вопрос пользователя. Технические аспекты на втором месте.
- Характер работы с ключами. Специалистам необходимо искать синонимы, тематические слова вручную, так как нет совершенных алгоритмов кроме матрицы и программных модулей, но они слишком сложные. Если в тексте тематических слов мало – качество низкое. Детальное ТЗ может содержать список обязательных к употреблению синонимов. Подбор ключей ведется с точки зрения релевантности теме, а не частотности. То есть насколько хорошо ключ соответствует теме.
- Качество. Статья должна содержать примеры, изображения, таблицы, а не просто быть объемной.
- Ценность для читателя. Пользователь не должен покидать страницу в течение 15 секунд. Если люди быстро уходят – поисковики будут считать контент бесполезным.
Можно ли назвать просто естественный текст LSI-копирайтингом? Нет.
Каждый смотрит на тему под своим углом, не видя полной картины. А читать статью будут тысячи людей, и у всех свой взгляд на вещи. Статистика от Яндекса и Google помогает собрать список ключей, которые будут важны потенциальной аудитории, оценить степень релевантности каждого к статье.
Что такое LSI
Сама аббревиатура LSI расшифровывается как «латентный, семантический и индексирование» в итоге получается выражение «скрытое (или латентное) семантическое индексирование». LSI представляет собой алгоритм поисковой системы, который способен оценивать материал не только по прямым вхождениям ключа, но и его разновидностям. При написании статей в отличие от СЕО, данные ключи ориентированы как на пользователя, так и на поисковиков. На сегодняшний день можно определить два вида LSI ключей:
- Синонимические – использование слов и словосочетаний, близких по значению. Например, машина и автомобиль. Поэтому сайт занимающийся продажей автомобилей может продвигаться по запросам «Купить машину» и «Купить автомобиль» — они будут синонимическими.
- Релевантные – такие ключи не связаны напрямую, но по смыслу напоминают их. Например, сайт по продаже светильников, может использовать в тексте релевантные слова «LED», светодиоды и т.п.
В итоге получается более естественный текст с наличием основных и дополнительных LSI слов. По сути – это новая эпоха в поисковой оптимизации, которая позволяет избавляться от плохих СЕО текстов. Однако алгоритмы поисковых систем не настолько хороши, поэтому не всегда получает получить качественный текст даже с использованием всех ключей.
Принципы создания LSI-контента
Процесс LSI-оптимизации будет понятнее при его рассмотрении в сравнении с традиционной или классической SEO. Отметим 3 принципиальных отличия.
- В SEO это обязательное внедрение ключевых словосочетаний в заголовки, контент и метатеги. В LSI — исчерпывающие ответы на предполагаемые вопросы пользователя, когда он вводит тот или иной поисковый запрос. Ключи могут естественным образом присутствовать в тексте, но их может и не быть.
- В SEO это отслеживание процента плотности ключевиков, а в LSI — использование максимального количества дополнительных слов по тематике статьи.
- В SEO это работа над уникальностью по техническим алгоритмам. В LSI — достижение смысловой исчерпанности и уникальности контента.
Важно! Иногда отдельные хорошо LSI-оптимизированные и интересно написанные статьи могут появиться на верхних позициях выдачи, даже если в них нет набранного в строке поиска ключа в чистом виде

Пример LSI-текстов
Допустим, я решил написать текст о том, как хранить кофе. Работа ведётся поэтапно.
1 этап: сбор локального семантического ядра по теме. Вот что получилось.

2 этап: сбор ассоциаций, синонимов, гипонимов и около тематических слов 1 порядка для каждого из ключевых запросов. Возьмём запрос «как хранить кофе в домашних условиях» и соберём для него LSI-запросы.

3 этап: сбор LSI-запросов 2 порядка по каждому из предыдущих ключей. Рассмотрим на примере «в холодильнике».
Слова и словосочетания 1 и 2 порядка могут перекликаться между собой. На практике вы видите последовательность работы. К сожалению, пока ни одна программа не может выполнить её лучше человека, потому что бездумное использование ключевых слов приводит к топорным и нечитабельным текстам. Сервисы только помогают расширить ядро для дальнейшего анализа.
На основании собранных данных структура публикации может быть следующей.

Пример структуры LSI-статьи
Создание структуры
Скелет любой статьи — структура. Именно она позволяет с первого взгляда оценить качество. Текст должен иметь иерархию и подчиняться внутренней логике. Части статьи не должны противоречить друг другу.
- Статья должна содержать заголовки и подзаголовки, маркированные списки и таблицы. Если это страница сайта, то стоит предусмотреть расположение отдельных элементов: кнопок, форм заказа, фотографий.
- Заголовок должен отражать основную идею материала, заголовки второго уровня — развивать тему в различных аспектах. Подзаголовки и заголовки третьего уровня указывают на частности или какие-то подробности.
- Заголовок и абзацы образуют, так называемые блоки. В каждом блоке может быть несколько абзацев. Абзац содержит от трех до шести строк и раскрывает одну определенную мысль. Короткие абзацы создают ощущение легкого, динамичного текста.
- Иерархию заголовков можно создать, опираясь на ключевые слова. Их нужно сгруппировать по смыслу. В статье идите от общего к частному — получится четкое и логичное повествование.
Обычно высокочастотные запросы касаются общей информации. Группа среднечастотников даст возможность глубже раскрыть тему. А низкочастотники позволят охватить нюансы, которые интересны пользователям.
И зачем вот это все?
Смысл латентно-семантической индексации в том, чтобы, используя контент из ТОП-10, прошедший ранжирование, собрать группу терминов из всех упоминаемых ключей, возможных вариаций связанных с ними слов, фраз и форм запросов, а поисковая машина на их основании смогла бы сформулировать наиболее полный ответ. Задача LSI-копирайтинга — в создании полезного, органично наполненного ключами контента, который поисковики будут узнавать, принимать и пропускать на первые позиции. Следовательно, будет увеличиваться посещаемость сайта и конверсия. Что и требовалось.
А самый крупный недостаток этого метода только один. Это дорого. От пяти баксов до бесконечности за килознак. Заказчики, бегите за валерьянкой!
Что такое SEO-текст
SEO-статья – это текст, который ориентирован не только на посетителя сайта, но и на поискового робота. Его основная цель – привлечь поисковый трафик на сайт. Такая статья отвечает на пользовательский запрос и содержит ключевые слова, которые чаще всего используются при поиске материала на определенную тему.
Основные требования к оптимизированному тексту
Чтобы текст, который вы пишете, можно было назвать SEO, он должен соответствовать следующим требованиям:
- В нем должны быть ключевые слова в точном и разбавленном вхождениях. Первое означает, что ключевой запрос указывается в том виде, в котором он был определен, порой даже склонения недопустимы. Для разбавленного вхождения требования будут мягче – разрешается вставка 1-2 дополнительных слов, допустимо склонение. Ключевые запросы должны быть равномерно распределены по всему тексту.
- Текст делится на абзацы по 3-7 строк. Причем такое деление должно быть смысловым. В идеале в одном абзаце раскрывается одна мысль.
- Используются заголовки уровня H1, H2 и так далее. Такая разбивка тоже влияет на выдачу в поисковой системе. H1, он же заголовок первого уровня, указывается только один раз, в самом начале, а заголовков H2 в тексте может быть несколько. В некоторых случаях могут понадобиться и другие уровни – H3, H4 или H5.
- Необходимо использовать нумерованные или маркированные списки. Тут опять включается фактор структурированности – чем он выше, тем легче читается и воспринимается текст.
- Нужно использовать внутренние ссылки в тексте. Эту систему еще называют перелинковкой. Она подразумевает указание в материале ссылок на другие страницы сайта. Таким образом, и пользователь быстрее найдет релевантную информацию, и выдача в поисковике улучшится за счет поведенческого фактора (для Google и Яндекса лучшим считается сайт, на котором пользователи активно проводят много времени).
- Текст должен быть уникальным. Этот показатель означает, что ваш текст не похож ни на один другой в интернете. Если уникальность будет недостаточно высокой, поисковик может воспринять это как нарушение авторского права. В итоге сайт либо упадет в выдаче, либо вообще будет забанен.
- Статья должна быть грамотной. Не стоит забывать, что, несмотря на ориентированность под поисковых роботов, SEO-текст все же пишется для людей. А многие не любят читать тексты с ошибками.
- Текст должен быть определенного объема (согласно ТЗ). Длина материала зависит от тематики. Объем можно определить с помощью анализа сайтов конкурентов.
Необходимо также прописывать метатеги Title и Description, в них обязательно указываются ключевые фразы и тематические запросы.
Частые ошибки при написании и публикации SEO-текстов
Процесс написания SEO-текстов претерпел кучу изменений с момента возникновения. На протяжении этого времени одни принципы уходили, другие до сих пор остаются актуальными. Но остаются некоторые аспекты, которые не самым положительным образом влияют на процесс продвижения и восприятия текста читателями. И вот некоторые из них:
- Выделение ключевых слов в тексте. Если фразы выделяются каким-либо образом в документе, это позволяет отследить их использование. Но при размещении на сайте стиль никак не влияет на выдачу, так что в этом нет необходимости.
- Сплошной текст. Читать его будет неудобно. Дело в том, что пользователи интернета читают по диагонали, в сплошном тексте им не за что зацепиться. Обязательно разбиваем материал на небольшие абзацы и оформляем подзаголовками.
- Ошибки в грамматике, орфографии и пунктуации. Поисковик, может, и не сделает ничего, но пользователи точно перестанут доверять ресурсу, на котором размещены тексты с ошибками.
- Избыток ключевых запросов, то бишь переспам. Несколько лет назад поисковые системы Google и Яндекс ввели санкции против сайтов, на которых размещены переспамленные тексты. К тому же такие материалы очень сложно читать обычному пользователю. Оптимальным будет использование не более одного ключа на 500-700 знаков без пробелов (при необходимости можно указывать их немного чаще).
- Тексты «для машины». В таких материалах ключи вставляются в исходном виде, без склонения или разбавления другими словами. Поисковые системы прекрасно распознают морфологию, даже если фраза указана не в прямом вхождении.
[править] Основные задачи, факторы и функции LSI-копирайтинга
Отличие LSI-копирайтинга от SEO-копирайтинга
Если для SEO-копирайтинга основой являются ключевые слова (ключевики), их плотность (частота применения и расположение) и виды вхождения в текст, то по методике LSI релевантность текстового контента напрямую зависит от вариантов использования ключевиков и слов из их окружения, соответствия контексту, уместности применения. Не меньшее значение при этом имеет качество самого текста, а также тематические предпочтения и потребности читателей. Последнее определяется по индексу отказов: после загрузки страницы читатель задерживается на ней не более 15 секунд. Это значит, что релевантность контента в большей степени зависит от содержания и смысла текста, чем от ключевых слов и фраз, вписанных в текстовый материал. (Примечание №3)
Виды LSI-ключей
Синонимичные (sLSI) – это слова-синонимы основного запроса, на которые прежде всего делают упор при оптимизации.
Релевантные (rLSI) – это слова из окружения главного ключевика, характеризующие и дополняющие его, а также другие слова и фразы, имеющие прямое отношение к теме статьи. По ним поисковый робот определяет, насколько хорошо раскрыта тема текста.
Основные требования к созданию LSI-текстов
Польза. Автор или автор текста должен знать свою целевую аудиторию, ее потребности и предпочтения, а LSI-текст во всем отвечать требованиям читателя.
Простота изложения. Простой, увлекательный, понятный текстовой материал хорошо воспринимается целевой аудиторией. С учетом этого подбираются стиль его написания и терминология.
Структура текста
Необходимо уделять внимание визуализации информации. Меткий, привлекающий внимание заголовок и подзаголовки, нумерованные и маркированные списки способствуют лучшей зрительной рецепции текста.
Ритм текста
Нужно следить за ритмом контента. Чередование коротких и длинных предложений придаст тексту динамику.
Распределение и плотность ключевых слов
Это важно не только для SEO-продвижения, но и для LSI-копирайтинга.
Достоверность информации. Раскрывать тему текста на уровне эксперта, а не любителя.
Недопустимость ошибок
Грамматика, синтаксис и структура предложений должны соответствовать нормам и правилам того языка, на котором пишется LSI-текст.
Лишь при выполнении всех перечисленных требований в их совокупности можно создавать тексты с высокой релевантностью.
Будущее LSI-копирайтинга
- повышать релевантность текстов поисковым запросам;
- улучшать ранжирование;
- увеличивать посещаемость;
- повышать привлекательность сниппета;
- опережать конкурентов.
Эффективность LSI-текстов согласно результатам эксперимента, проведенного канадским маркетинговым агентством New Media Sources. (Примечание №2)
Как подбирать LSI-ключи?
Повторюсь, LSI-запросы – это не только синонимы, но и словоформы, сопутствующие заданной теме. Для поиска таких запросов есть масса инструментов, как платных, так и бесплатных. Начнём с халявы.
Бесплатные инструменты
- Подсказки Яндекса и Google.

Поисковые подсказки Яндекса
- Яндекс.Вордстат
Смотрите правую колонку сервиса – «Запросы, похожие на …» Отсюда выбираются словосочетания, подходящие по теме.

Яндекс.Вордстат «Запросы, похожие на …»
- Сервис Арсенкина
На портале много инструментов, но в данном случае нас интересует «Парсинг подсветок Yandex и сбор тематических слов». Правда в бесплатной версии есть ограничения.

Парсинг подсветок Яндекса и сбор тематических слов от Арсенкина
- Pixel Tools
Вводите продвигаемый запрос. В соответствующем окне вы получаете список слов, задающих тематику.

Техническое задание для копирайтера от Pixel Tools
- Slovoeb.
Отличный бесплатный инструмент – аналог Key Collector. Программу нужно скачивать. Она автоматически парсит запросы с Яндекс.Вордстата, Директа и других сервисов для расширения семантического ядра.

Интерфейс программы Slovoeb
Платные инструменты
- Rush Analytics.
Парсер собирает подсказки из Google, YouTube и Яндекса, автоматически отсеивает мусорные запросы.

Сбор поисковых подсказок от Rush Analytics
- Serpstat.
Многофункциональный сервис, в котором также есть инструменты по анализу ключевых фраз – суммарный отчёт, подбор фраз, поисковые подсказки, похожие фразы.

Суммарный отчет от SerpStat

Поисковые подсказки в SerpStat
- Click.ru.
Помимо стандартных инструментов для парсинга вы получаете опции, позволяющие автоматизировать и упростить сам процесс.

Функционал подбора ключевых слов от Click.ru
Цена LSI-копирайтинга
Цена качественного LSI-копирайтинга даже по минимуму не может быть ниже 5-10 у.е./1000 знаков с пробелами. Слишком объемна работа, которую нужно поделать LSI-копирайтеру.
Если вам предлагают дешевле, скорее всего, это обман, и работа будет неполной. В LSI-копирайтинге автор предоставляет список LSI-ключей, которые умышленно использовал в тексте. И разные ключи в идеале должны присутствовать в каждом предложении текста.
Кстати, LSI-копирайтинг в народе зовется «текстами нового поколения». В ближайшие 2-3 года точно услуга будет мега-востребована и популярна. Вероятно, скоро появятся и онлайн-инструменты по оценке LSI-текстов.
2. Плотность ключевых слов: предшественник ключевых слов LSI
Плотность ключевых слов показывает, сколько раз слово появляется в тексте. Плотность ключевых слов измеряют в процентах. Процент рассчитывают делением количества раз, когда термин встречается на веб-странице на общее количество слов на этой странице. Чем больше этот процент, тем выше шансы на более высокий рейтинг в Google по выбранным ключевым словам.Это было до «Panda» / «Панда» и «Hummingbird» / «Колибри». Это были более простые времена.Когда-то плотность ключевых слов была ЕДИНСТВЕННЫМ способом, которым Google мог определить, может ли быть релевантна определенная веб-страница. Веб — мастера и блогеры научились, с выгодой, использовать этот показательИнтернет заполнили бессмысленные страницы, с нечитабельным текстом. Вот как была изобретена набивка рейтинга по ключевым словам.
Как влияет LSI-контент на SEO?
LSI можно назвать младшим, но более перспективным братом SEO. Текст, сделанный этим способом, включает в себя не только вариации ключевой фразы, но и близкие по смыслу слова. Например, в LSI-материале про смартфон, который можно заказать онлайн, вы наверняка встретите понятия «дисплей», «камера», «сенсорный», «мультитач» и т. д. Поисковые системы реагируют на такие мелочи. Статья, насыщенная популярными запросами, будет выше в выдаче, нежели глава художественного романа, где смартфон упомянут невзначай.
Писать LSI-тексты одновременно и сложнее, и легче, чем SEO. С одной стороны, нужно потратить время на то, чтобы органично вплести ансамбль ключевых слов в материал. С другой – вам не придется наступать на горло здравому смыслу, совмещая ультрасовременные микроволновки и Камасутру. Латентное семантическое индексирование можно сравнить со строительством, когда из множества кирпичиков опытный мастер создает крепкий дом. Это затратно по времени, но интересно.

Приведем еще два различия между LSI и SEO:
1. В SEO главное – наличие ключей в тексте. LSI ориентируется на суть написанного. Его цель – легко провести читателя по материалу и дать ему ответы на все вопросы.
2. Для SEO первична техническая уникальность. LSI может пренебречь процентами антиплагиата в пользу удобоваримости.
Стоит ли специально осваивать LSI? Зависит от ваших личных предпочтений и целей в профессии. Но если вы работаете с SEO, знание латентного семантического индексирования пойдет вам на руку. Последнее гораздо больше котируется среди толковых заказчиков, а также выше оплачивается. Фетишизм, связанный с Advego и прочими количественными показателями, пока еще встречается на биржах, но в целом мир копирайтинга отходит от этих стандартов. Классическое SEO преобразуется и становится более отзывчивым к современным тенденциям.
Почему LSI-копирайтинг?
Главная ценность ресурса в пользователях, которые не закрывают сайт через 2 секунды, а сразу находят именно то, что нужно.
Вспомним, как появлялись первые фильтры от Google. Например, Панда. Его задача была в проверке поведения пользователей на странице. Если человек быстро закрывает текст, не осмотрев сайт даже 30 секунд, то вебсайту грозит Панда.
Не читают слишком маленькие статьи, даже Яндекс в последнее время их не показывает в выдаче. Информационные статьи теперь минимум начинают с 8000 до 10000 символов без пробелов. Что полезного можно написать в 1000 знаков с 5 СЕО ключами?
Даже правильно создавая структуру сайта, сложно осветить по любой теме суть в ограниченные рамки. Сайты с маленькими статьями опускаются в выдаче, уходят под Панду, теряя доходы.
Мета-теги для страниц на сайте
Хотя SEO-тексты постепенно отходят в прошлое, их наличие на сайтах может помочь в улучшении его позиций в поисковой выдаче
При этом важно не только хорошо написать сам текст, но и правильно проработать мета-теги. Для них действуют следующие правила:
- Ключевое слово должно быть в <Title>.
- Уникальный, «продающий» <Description> с ключевым словом.
- Правильная структура страницы: H1 – единственный, использование H2, H3, H4 для подзаголовков.
- Ключевые слова в alt и title картинок.
Все эти пункты может прописать как SEO-специалист, так и автор статьи, если он знаком с основами продвижения сайтов. Делать это необходимо основываясь на изучении страниц конкурентов. При этом не нужно как-то выделять ключевые слова. Это даже вредно, так как может привести к попаданию под фильтры поисковых систем. При этом использование средств для выделения в тексте не является запретным. Просто лучше курсивом или полужирным выделять какие-то термины или важные мысли, а не отдельные ключевые слова и фразы.
LSI в алгоритмах поисковых систем
Первое упоминание LSA в поисковых системах связано с алгоритмом Panda от Google. Обновление ставило себе цель — найти и снизить количество контента низкого качества, который был создан с целью манипуляции поисковой выдачей. Алгоритм был запущен в феврале 2011, а уже в 2012 году появились первые упоминания об LSI-копирайтинге.
Окончательно новые требования к качеству текстов сформировались к 2013 году. В это время Google запустил новый алгоритм — Hummingbird («Колибри»). Главное отличие нового алгоритма — поиск стал понимать поисковые запросы разговорного типа. Google научился отыскивать нужные документы, исходя из семантических связей, а не просто по запросам.
Яндекс подхватил эстафету в ноябре 2016 года — запустил алгоритм «Палех». Его задача — распознавать низкочастотные и сложные запросы из «длинного хвоста». То есть понимать запросы в разговорном ключе. Общая масса таких запросов составляет порядка 40% от объема текста.
Для работы алгоритма были использованы нейросети и машинное обучение. Подробнее о механике и принципах работы алгоритма можно прочитать в блоге Яндекса на Хабрахабре. Введение в работу «Палеха» подогрело интерес к LSI-текстам в русскоязычном интернете.
Весной 2017 года Яндекс вводит «Баден-Баден» — новый алгоритм определения текстов, которые перенасыщены ключевыми словами. Тысячи сайтов попадают под фильтр и понижаются в выдаче, условием возврата трафика называется отказ от SEO-текстов.
Осенью 2017 Яндекс запускает «Королев» — алгоритм поиска на основе нейросетей. По заявлению Яндекса, алгоритм «…сопоставляет смысл запросов и веб-страниц…». Новый алгоритм работает на нейросетях, но при этом не отменяет LSI, а усиливает сложившиеся тенденции. Теперь писать SEO-тексты нет никакого смысла — вместо ТОПа можно получить фильтр за переоптимизацию.
Выводы
LSI копирайтинг однозначно наиболее эффективный метод продвижения информационных сайтов, за LSI будущее алгоритмов ранжирования Яндекс и Google, которые продолжают внедрять принципы LSA/LSI.
Итак, подытожим, что даст нам использование LSI:
- с LSI вы сможете избавиться от переспама (например, «Баден-Баден») и воды, задать нужный ритм в тексте — он будет содержательным, пользователь найдет то, что искал;
- видимость и позиции вашего сайта будут улучшаться по ряду низко- и высокочастотных запросов (LSI лонгриды будут усиливать основное ключевое слово, то есть высокочастотный маркерный запрос), страница будет отображаться в результатах поиска как для вашего основного ключевого слова, так и для всех его “хвостов”.
- вы будете получать стабильный трафик по LSI-оптимизированным страницам;
- благодаря релевантности, которую внесут LSI-ключи — поведенческие факторы будут улучшаться, а процент отказов уменьшится. В итоге вырастет траст вашего сайта, вместе с такими показателями как ИКС и PageRank, сайт с большей вероятностью попадет в ТОП;
Благодаря LSI, ваш текст будет полностью целостным и органичным, отвечающий на запрос пользователя, а значит и требованиям поисковика.
Если у вас есть свои советы по SEO или замечания — пишите нам на электронную почту: support@rush-analytics.ru. Также рекомендуем воспользоваться автоматической кластеризацией запросов в Rush Analytics.
Интересно прочитать: