Utf-8 general punctuation
Содержание:
Указание кодировки символов документа
Есть несколько способов указать, какая кодировка символов используется в документе. Во-первых, веб-сервер может включать кодировку символов или » » в заголовок протокола передачи гипертекста (HTTP) , который обычно выглядит следующим образом:
Content-Type: text/html; charset=utf-8
Этот метод дает HTTP-серверу удобный способ изменить кодировку документа в соответствии с согласованием содержимого ; определенное программное обеспечение HTTP-сервера может это сделать, например Apache с модулем .
Для HTML можно включить эту информацию внутри элемента в верхней части документа:
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
HTML5 также позволяет следующему синтаксису означать то же самое:
<meta charset="utf-8">
У документов XHTML есть третий вариант: выразить кодировку символов через объявление XML следующим образом:
<?xml version="1.0" encoding="ISO-8859-1"?>
Поскольку кодировка символов не может быть известна до тех пор, пока это объявление не будет проанализировано, может возникнуть проблема, зная, какая кодировка используется для самого объявления. Главный принцип заключается в том, что объявление должно быть закодировано в чистом ASCII, и поэтому (если объявление находится внутри файла) кодировка должна быть расширением ASCII . Для того чтобы кодировки не были обратно совместимы с ASCII, браузеры должны иметь возможность анализировать объявления в таких кодировках. Примеры таких кодировок — UTF-16BE и UTF-16LE .
Начиная с HTML5, рекомендуемая кодировка — UTF-8 . В спецификации определен «алгоритм сниффинга кодирования» для определения кодировки символов документа на основе нескольких источников ввода, включая:
- Явная инструкция пользователя
- Явный метатег в первых 1024 байтах документа.
- Отметка порядка байтов в течение первых трех байтов документа
- HTTP Content-Type или другая информация транспортного уровня
- Анализ байтов документа в поисках определенных последовательностей или диапазонов значений байтов и другие механизмы предварительного обнаружения.
Для ASCII-совместимых кодировок символов следствием неправильного выбора является то, что символы за пределами печатаемого диапазона ASCII (от 32 до 126) обычно отображаются неправильно. Это создает несколько проблем для английских -speaking пользователей, но и другие языки регулярно , в некоторых случаях, всегда требуют-символы за пределами этого диапазона. В средах CJK, где используется несколько различных многобайтовых кодировок, также часто используется автоматическое обнаружение. Наконец, браузеры обычно позволяют пользователю вручную переопределить неправильную метку кодировки.
Для многоязычных веб-сайтов и веб-сайтов на незападных языках все чаще используется UTF-8 , который позволяет использовать одну и ту же кодировку для всех языков. UTF-16 или UTF-32 , которые также могут использоваться для всех языков, менее широко используются, потому что их может быть труднее обрабатывать в языках программирования, которые предполагают байтовую кодировку расширенного набора ASCII, и они менее эффективны для текста с высокая частота символов ASCII, что обычно характерно для документов HTML.
Успешный просмотр страницы не обязательно означает, что ее кодировка указана правильно. Если создатель страницы и читатель оба предполагают некоторую кодировку символов, зависящую от платформы, и сервер не отправляет никакой идентифицирующей информации, то читатель, тем не менее, будет видеть страницу так, как задумал создатель, но другие читатели на разных платформах или с разными родными языками не увидит страницу должным образом.
Принципы работы
UTF-8 является лишь представлением Unicode в 8-битном виде. Символы с кодами меньше 128 представляются одним байтом (Латинский алфавит, простейшие знаки препинания и арабские цифры), а так как в Unicode они повторяют ASCII, то текст написанный только этими символами будет являться текстом в ASCII.
Символы с кодами от:
- 128 — 2-мя байтами.(Кириллица, расширенная латиница, арабский, армянский, греческий, еврейский и коптский алфавит, сирийское письмо, некоторые знаки препинания).
- 2048 — 3-мя байтами (Все другие современные формы письменности, сложные знаки препинания; математические и другие специальные символы).
- 65536 — 4-мя байтами (Музыкальные символы, смайлы, редкие китайские иероглифы, вымершие формы письменности).
5 и 6 байтов не используется в Unicode.
Атрибуты
| Атрибут | Значение | Описание |
|---|---|---|
| charset | character_set | Задает кодировку символов для HTML документа. |
| content | text | Задает значение, связанное с атрибутами name и http-equiv, в зависимости от контекста. |
| http-equiv | content-security-policycontent-typedefault-stylerefresh | Фактически эквивалентен гипертекстовому заголовку (имитация http-заголовка), формируют заголовок страницы и определяют его обработку. Как правило, они управляют действиями браузеров и используются для формирования информации, выдаваемой обычными http-заголовками. |
| name | application-nameauthordescriptiongeneratorkeywords | Определяет имя документа на уровне метаданных. |
| scheme | format/URI (универсальный идентификатор ресурса) | Не поддерживается в HTML 5. Указывает полезную информацию о схеме или названии самой схемы, которая должна быть использована для уточнения значения свойства атрибута content. |
Как установить UTF-8 кодировку в PHP
В PHP скрипте для установки кодировки используется header, например:
header('Content-Type: charset=utf-8');
Обычно вместе с кодировкой также указывают тип содержимого (в примере вариант для HTML страницы):
header('Content-Type: text/html; charset=utf-8');
Ещё один вариант для RSS ленты:
header('Content-type: text/xml; charset=utf-8');
Помните, что функция header должна быть вызвана перед любым выводом в браузер. В противном случае (если вывод в браузер уже был сделан), то уже были отправлены и заголовки. Очевидно, что в этом случае их уже невозможно поменять. Если в браузер было выведено сообщение об ошибке, то заголовки также уже были отправлены и использование header вызовет ошибку. Для проверки, были ли уже отправлены заголовки, используйте headers_sent.
Описанный способ работает только когда PHP скрипт полностью генерирует содержимое страницы. Статические страницы (такие как html) вы должны сохранять в кодировке utf-8
Большинство веб серверов обратят внимание на кодировку файла и добавят соответствующий заголовок. На самом деле, сохранение PHP файла в кодировке utf-8 приведёт к такому же результату.
Переход к Unicode
Развитие интернета, увеличение количества компьютеров и удешевление памяти привели к тому, что проблемы, которые доставляла путаница в кодировках, стали перевешивать некоторую экономию памяти. Особенно ярко это проявлялось в интернете, когда текст написанный на одном компьютере должен был корректно отображаться на многих других устройствах. Это доставляло огромные проблемы как программистам, которые должны были решать какую кодировку использовать, так и конечным пользователям, которые не могли получить доступ к интересующим их текстам.
В результате в октябре 1991 года появилась первая версия одной общей таблицы символов, названной Unicode. Она включала в себя на тот момент 7161 различный символ из 24 письменностей мира.
В Unicode постепенно добавлялись новые языки и символы. Например, в версию 1.0.1 в середине 1992 года добавили более 20 000 идеограмм китайского, японского и корейского языков. В актуальной на текущий момент версии содержится уже более 143 000 символов.
Ссылки на символы
Помимо собственных кодировок символов, символы также могут быть закодированы как ссылки на символы , которые могут быть ссылками на числовые символы ( десятичные или шестнадцатеричные ) или ссылками на символьные сущности . Ссылки на символьные сущности также иногда называют именованными сущностями или сущностями HTML для HTML. Использование символьных ссылок в HTML происходит от SGML .
Ссылки на символы HTML
Цифровая ссылка на символ в HTML относится к символу его универсальный набор символов / Unicode точки коды , и использует формат
или же
где nnnn — это кодовая точка в десятичной форме, а hhhh — это кодовая точка в шестнадцатеричной форме. В XML-документах x должен быть в нижнем регистре. Нннн или хххх может быть любое количество цифр и может включать в себя ведущие нули. В hhhh могут смешиваться прописные и строчные буквы, хотя прописные буквы являются обычным стилем.
Не все веб-браузеры или почтовые клиенты, используемые получателями HTML-документов, или текстовые редакторы, используемые авторами HTML-документов, смогут отображать все символы HTML. Большинство современных программ способно отображать большинство или все символы языка пользователя, а также рисовать прямоугольник или другой четкий индикатор для символов, которые они не могут отобразить.
Для кодов от 0 до 127, исходного 7-битного стандартного набора ASCII , большинство этих символов можно использовать без ссылки на символ. Все коды от 160 до 255 могут быть созданы с использованием символьных имен сущностей . Только несколько кодов с более высокими номерами могут быть созданы с использованием имен сущностей, но все они могут быть созданы с помощью ссылки на символ десятичного числа.
Ссылки на символьные сущности также могут иметь формат, в котором имя — это буквенно-цифровая строка с учетом регистра. Например, «λ» можно также закодировать, как в документе HTML. Упоминания характер сущности , , и предопределены в HTML и SGML, потому что , , и уже используются для разделения разметки. В частности, это не включало сущность XML (‘) до HTML5 . Список всех именованных ссылок на символьные сущности HTML вместе с версиями, в которых они были представлены, см. В разделе Список ссылок на символьные сущности XML и HTML .
Излишнее использование ссылок на символы HTML может значительно снизить удобочитаемость HTML. Если кодировка символов для веб — страницы выбрана правильно, то ссылки HTML характер, как правило , требуется только для разметки символов разделителей , как упоминалось выше, и в течение нескольких специальных символов (или вообще если родной Unicode не кодирующая как UTF-8 используется ). Неправильное экранирование HTML-объекта может также открыть уязвимости безопасности для атак с использованием инъекций, таких как межсайтовый скриптинг . Если атрибуты HTML не заключены в кавычки, некоторые символы, особенно пробелы , такие как пробел и табуляция, должны быть экранированы с помощью сущностей. В других языках, связанных с HTML, есть собственные методы экранирования символов.
Ссылки на символы XML
В отличие от традиционного HTML с его большим диапазоном ссылок на символьные сущности, в XML есть только пять предопределенных символьных ссылок на сущности. Они используются для экранирования символов, чувствительных к разметке в определенных контекстах:
- → & ( амперсанд , U + 0026)
- → <(знак «меньше», U + 003C)
- →> (знак больше, U + 003E)
- → «(кавычка, U + 0022)
- → ‘(апостроф, U + 0027)
Все остальные ссылки на символьные сущности должны быть определены до того, как их можно будет использовать. Например, использование (что дает é, латинское строчное E с острым ударением, U + 00E9 в Unicode) в XML-документе приведет к ошибке, если объект еще не был определен. XML также требует, чтобы в шестнадцатеричных числовых ссылках были строчные буквы: например, а не . XHTML , являющийся приложением XML, поддерживает набор сущностей HTML вместе с предопределенными сущностями XML.
Разрешенные кодировки
WHATWG Encoding Standard, на который ссылается последними стандарты HTML (текущий WHATWG HTML Living Standard, а также ранее конкурирующий W3C HTML 5.0 и 5.1) определяет список кодировок , которые должны поддерживать браузеры. Стандарты HTML запрещают поддержку других кодировок. Стандарт кодирования также предусматривает, что новые форматы, новые протоколы (даже когда используются существующие форматы) и авторы новых документов должны использовать исключительно UTF-8 .
Помимо UTF-8, следующие кодировки явно перечислены в самом стандарте HTML со ссылкой на стандарт кодирования:
- ISO-8859-2
- ISO-8859-7
- ISO-8859-8
- Окна-874
- Окна-1250
- Окна-1251
- Окна-1252
- Окна-1254
- Окна-1255
- Окна-1256
- Окна-1257
- Окна-1258
- GB18030
- Big5
- Shift JIS
- ISO-2022-JP
- EUC-KR
- UTF-16BE
- UTF-16LE
- x-определяемый пользователем
Следующие дополнительные кодировки перечислены в Стандарте кодирования, и поэтому также требуется их поддержка:
- Кодовая страница 866
- ISO-8859-3
- ISO-8859-4
- ISO-8859-5
- ISO-8859-6
- ISO-8859-8- I
- ISO-8859-10
- ISO-8859-13
- ISO-8859-14
- ISO-8859-15
- ISO-8859-16
- КОИ8-Р
- КОИ8-У / КОИ8-РУ
- Mac OS Роман
- Окна-1253
- Mac OS кириллица
- ГБК
- EUC-JP
Следующие кодировки указаны как явные примеры запрещенных кодировок:
- ЦЭСУ-8
- UTF-7
- BOCU-1
- ГКГУ
- EBCDIC
- UTF-32
Стандарт также определяет «замещающий» декодер, который отображает весь контент, помеченный как определенные кодировки, на заменяющий символ ( ), вообще отказываясь его обрабатывать. Это предназначено для предотвращения атак (например, межсайтовых сценариев ), которые могут использовать разницу между клиентом и сервером в поддерживаемых кодировках, чтобы замаскировать вредоносный контент. Хотя та же проблема безопасности относится к ISO-2022-JP и UTF-16 , которые также позволяют по-разному интерпретировать последовательности байтов ASCII, этот подход не рассматривался для них как выполнимый, поскольку они сравнительно чаще используются в развернутом контенте. Следующие кодировки обрабатываются так:
- ISO-2022-KR
- ISO-2022-CN
- ISO-2022-CN-EXT
- HZ-GB-2312
Теперь рассмотрим коротко POST.
В отличие от GET запросов, в POST передается Content-type, который сообщает серверному скрипту информацию, о том с какими данными он работает и возможность указания кодировки. Например, в Jquery по умолчанию AJAX передает «application/x-www-form-urlencoded; charset=utf-8», но даже если вы укажите “text/html; charset=utf-8”, то данные приходящие будут в utf-8, так как при передачи данных, Jquery формирует escape-последовательность, функцией, о которой писалось выше.
Но это не так страшно, потому что у нас есть всегда возможность перевести кодировку и уже работать с данными. При этом отдавать результаты мы можем в нашей любимой кодировке, главное не забывайте ставить заголовок, с указанием кодировки, если вдруг вы обратно получаете «каказябры».
Например:
header('Content-type: text/html; charset=utf-8');
или:
header('Content-type: text/html; charset=utf-8');
Вывод: для того что бы не было проблем с кодировками, при передачи данных через AJAX, нужно использовать encodeURIComponent(). Если ваш серверный скрипт, который принимает запросы, работает в другой кодировке, отличной от utf-8, то надо пользоваться php функцией iconv и устанавливать заголовок header.
Характеристики хорошего мета-описания
Почти каждая статья о мета-описаниях будет содержать некоторые из приведенных характеристик. Но здесь собраны все характеристики, которые имеют весомое значение для правильного составления мета-описания:
1. Длина до 155 символов, а иногда и больше
Правильная, или конкретная длина на самом деле не существует; это зависит от вида сообщения, которое вы хотите передать. Вы должны использовать достаточно места, чтобы донести сообщение при помощи символов, но в то же время ваше сообщение должно быть кратким и емким.
Время от времени Google меняет длину. В настоящее время вы в основном увидите мета-описания длиной до 155 символов, с некоторыми выбросами ― в 300 символов. По крайней мере, постарайтесь включить важную информацию в первые 155 символов вашего мета-описания.
2. Требующее конкретных действий и написанное в активном стиле
Конечно ваше мета-описание должно соответствовать данным характеристикам. Если вы считаете, что мета-описание ― это приглашение на страницу, то вы не можете просто сделать его «смешанной метафорой, описывающей несуществующий, но неявно высокий уровень квалификации».
Это скучное описание, и люди не будут знать, что они получат. Но об этом чуть позже, подкрепив некоторыми примерами из практики.
3. Включающий призыв к действию
«Здравствуйте, у нас есть такой-то новый продукт, и вы его хотите
Узнайте больше!» Это совпадает с тем, что я сказал об активном стиле, о котором уже шла речь, но я лишь хотел заострить на этом моменте особое внимание. Это ваш рекламный текст, где вашим продуктом является связанная страница, а не продукт на этой странице
Приглашения типа: «Узнай больше», «Получи сейчас», «Попробуй бесплатно» очень пригодятся здесь и будут как нельзя к месту.
4. Содержать ключевое слово с определенным акцентом
Если ключевое слово поиска соответствует части текста в мета-описании, Google будет более склонен использовать это мета-описание и выделять его в результатах поиска. Это сделает ссылку на ваш сайт еще более привлекательной.
5. По возможности показать спецификацию
Например, если у вас есть продукт для технически подкованных пользователей, то конечно же стоит обратить внимание на технические характеристики продукта ― производитель, размеры, мощность, цена и тому подобное. Если посетитель ищет именно этот продукт, скорее всего, вам не придется его убеждать, а наличие информации, такой как цена, вызовет клик
Обратите внимание, что вы можете, конечно, попытаться получить и более «богатые» на контент фрагменты.
6. Соответствие содержания
Это важно. Google узнает, когда мета-описания обманом заставляют посетителей нажимать, и может даже оштрафовать сайты, которые делают это
Но кроме этого, вводящие в заблуждение описания, вероятно, увеличат показатель отказов. Это плохая идея хотя бы только по этой причине. Нам же надо, чтобы мета-описание соответствовало содержанию на странице.
7. Уникальность описания
Если ваше мета-описание такое же, как и для других страниц, то взаимодействие с пользователем в Google будет затруднено. Хотя заголовки страниц могут различаться, но все страницы будут выглядеть одинаково, потому, что все описания одинаковы. Если вы намеренно хотите создать дублированное мета-описание, лучше оставить описание пустым. Google сам выберет фрагмент страницы, содержащий ключевое слово, используемое в запросе.
Посетите Инструменты Google для веб-мастеров > Улучшения HTML или используйте Screaming Frog SEO Spider, чтобы найти дубликаты мета-описаний.
Неправильная кодировка HTML страниц
Создадим тестовый файлик:
sudo gedit /var/www/html/encoding.html
Скопируем в него следующий HTML код, в котором отсутствует указание кодировки и посмотрим, какие проблемы могут с ним возникнуть и как их решить:
<html>
<head>
<title>Проверка кодировки</title>
</head>
<body>
<h1>Тестовый файл для проверки кодировки</h1>
</body>
</html>
Откроем этот файл в браузере http://localhost/encoding.html
Как можно видеть, кодировка браузером определена неправильно:
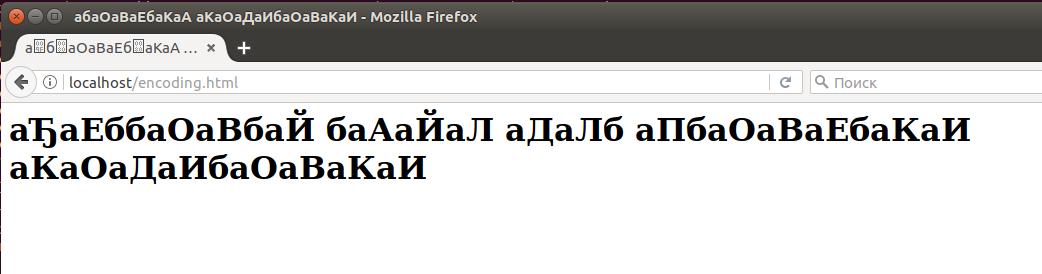
Имеется несколько способов исправить эту ситуацию. Начнём с самого простого – явно указать кодировку для веб-страницы. Это делается метатегом, который должен быть расположен внутри тэга head:
<meta http-equiv="content-type" content="text/html; charset=utf-8" />
Добавим эту строку к нашему тестовому файлику, чтобы получилось так:
<html>
<head>
<title>Проверка кодировки</title>
<meta http-equiv="content-type" content="text/html; charset=utf-8" />
</head>
<body>
<h1>Тестовый файл для проверки кодировки</h1>
</body>
</html>
Как мы можем убедиться на следующем скриншоте, проблема решена:

Если кодировка вашего файла отличается от UTF-8, то вместо неё поставьте windows-1251 или ту, которая соответствует кодировке веб-страницы. Чтобы научиться определять кодировку файлов, посмотрите эту инструкцию.
Это был самый простой способ исправления проблемы с кодировкой – без изменения настроек сервера.
Вернём наш тестовый файл в исходное состояние и продолжим изучение способов указания кодировки.
Если файлы .htaccess включены настройками Apache, то эти файлы можно использовать чтобы указывать кодировку отправляемых веб-сервером страниц. Чтобы включить поддержку файлов .htaccess в конфигурационном файле Apache ( /etc/apache2/apache2.conf ) найдите группу строк
<Directory /var/www/> Options Indexes FollowSymLinks AllowOverride None Require all granted </Directory>
И в ней замените
AllowOverride None
на
AllowOverride All
После этого сервер нужно перезапустить.
sudo systemctl restart apache2.service
Файл .htaccess должен быть размещён в той же директории, что и сайт. Мой сайт размещён в корневой директории веб-сервера. Если у вас также, то теперь в папке /var/www/html/ создайте файл .htaccess и добавьте в него директиву AddDefaultCharset после которой укажите желаемую кодировку. Примеры
AddDefaultCharset UTF-8
ИЛИ
AddDefaultCharset windows-1251
Можно указать кодировку, которая будет применена только к файлам определённого формата:
AddCharset utf-8 .atom .css .js .json .rss .vtt .xml
Набор файлов может быть любым, например:
AddCharset utf-8 .html .css .php .txt .js
Следующий вариант является альтернативным и также позволяет устанавливать кодировку для файлов определённого типа, для него нужно, чтобы был включён mod_headers:
<Files ~ "\.html?$">
Header set Content-Type "text/html; charset=utf-8"
</Files>
Ещё один вариант, который также можно использовать в файле .htaccess для установки кодировки UTF-8:
IndexOptions +Charset=utf-8
Если сайт на PHP, то дополнительно может понадобиться продублировать кодировку с php_value default_charset:
AddDefaultCharset windows-1251 php_value default_charset "cp1251"
Можно вместо создания файла .htaccess установить кодировку в конфигурационном файле веб-сервера. Для Apache CentOS/Fedora это файл httpd.conf, а на Debian/Ubuntu это файл apache2.conf. Добавьте следующую строку для установки кодировки и перезапустите веб-сервер, чтобы изменения вступили в силу:
AddDefaultCharset UTF-8
Кодирование и декодирование
Кодирование— это процесс формирования определенного представления информации,переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки.То есть любой символ, который мы видим или вводим, для компьютера в реальности — всего лишь набор битов (набор нулей и единиц). Именно эти биты и перегоняются от устройства к устройству. А чтобы показать результат этих перегонок человеку, компьютер преобразует с помощью таблицы (той самой кодировки) код символа в соответствующий внешний вид.
UTF-32LE в UTF-8
Схемой можете воспользоваться при кодировании и раскодировании.
Эта схема сделана так, чтобы вы видели какие биты куда попадают как при кодировании, так и раскодировании.
По ней видно что при этих обоих процессах просто нужные биты выставляются на нужные позиции при нужных значениях контрольных бит.
Можно заметить что компоновка в больших байтовых последовательностях осуществляется по 6 бит (в так называемых лидирующих байтах).
При этом старшие биты предусматриваемого кода будут в первых байтах (схоже с порядком Big-Endian).

Кодирование
Порядок действий такой:
- Каждый символ превращаем в Unicode.
- Проверяем из какого диапазона символ.
- Если код символа меньше 128, то к результату добавляем его в неизменном виде.
- Если код символа меньше 2048, то берем последние 6 бит и первые 5 бит кода символа. К первым 5 битам добавляем 0xC0 и получаем первый байт последовательности, а к последним 6 битам добавляем 0x80 и получаем второй байт. Конкатенируем и добавляем к результату.
- Похожим образом можем продолжить и для больших кодов, но если символ за пределами U+FFFF придется иметь дело с UTF-16 суррогатами.
Function EncodeUTF8(s)
Dim i, c, utfc, b1, b2, b3
For i=1 to Len(s)
c = ToLong(AscW(Mid(s,i,1)))
If c < 128 Then
utfc = chr( c)
ElseIf c < 2048 Then
b1 = c Mod &h40
b2 = (c - b1) &h40
utfc = chr(&hC0 + b2) & chr(&h80 + b1)
ElseIf c < 65536 And (c < 55296 Or c > 57343) Then
b1 = c Mod &h40
b2 = ((c - b1) &h40) Mod &h40
b3 = (c - b1 - (&h40 * b2)) &h1000
utfc = chr(&hE0 + b3) & chr(&h80 + b2) & chr(&h80 + b1)
Else
' Младший или старший суррогат UTF-16
utfc = Chr(&hEF) & Chr(&hBF) & Chr(&hBD)
End If
EncodeUTF8 = EncodeUTF8 + utfc
Next
End Function
Function ToLong(intVal)
If intVal < Then
ToLong = CLng(intVal) + &H10000
Else
ToLong = CLng(intVal)
End If
End Function
Декодирование
Декодирование — преобразование зашифрованной информации в понятный, пригодный для непосредственного использования вид.
- Ищем первый символ вида 11xxxxxx
- Считаем все последующие байты вида 10xxxxxx
- Если последовательность из двух байт и первый байт вида 110xxxxx, то отсекаем приставки и складываем, умножив первый байт на 0x40.
- Аналогично для более длинных последовательностей.
- Заменяем всю последовательность на нужный символ Unicode.
Function DecodeUTF8(s)
Dim i, c, n, b1, b2, b3
i = 1
Do While i <= len(s)
c = asc(mid(s,i,1))
If (c and &hC0) = &hC0 Then
n = 1
Do While i + n <= len(s)
If (asc(mid(s,i+n,1)) and &hC0) <> &h80 Then
Exit Do
End If
n = n + 1
Loop
If n = 2 and ((c and &hE0) = &hC0) Then
b1 = asc(mid(s,i+1,1)) and &h3F
b2 = c and &h1F
c = b1 + b2 * &h40
Elseif n = 3 and ((c and &hF0) = &hE0) Then
b1 = asc(mid(s,i+2,1)) and &h3F
b2 = asc(mid(s,i+1,1)) and &h3F
b3 = c and &h0F
c = b3 * &H1000 + b2 * &H40 + b1
Else
' Символ больше U+FFFF или неправильная последовательность
c = &hFFFD
End if
s = left(s,i-1) + chrw( c) + mid(s,i+n)
Elseif (c and &hC0) = &h80 then
' Неожидаемый продолжающий байт
s = left(s,i-1) + chrw(&hFFFD) + mid(s,i+1)
End If
i = i + 1
Loop
DecodeUTF8 = s
End Function
UTF-8 Basic Latin
| Char | Dec | Hex | Entity | Name |
|---|---|---|---|---|
| 32 | 0020 | SPACE | ||
| ! | 33 | 0021 | EXCLAMATION MARK | |
| « | 34 | 0022 | " | QUOTATION MARK |
| # | 35 | 0023 | NUMBER SIGN | |
| $ | 36 | 0024 | DOLLAR SIGN | |
| % | 37 | 0025 | PERCENT SIGN | |
| & | 38 | 0026 | & | AMPERSAND |
| ‘ | 39 | 0027 | APOSTROPHE | |
| ( | 40 | 0028 | LEFT PARENTHESIS | |
| ) | 41 | 0029 | RIGHT PARENTHESIS | |
| * | 42 | 002A | ASTERISK | |
| + | 43 | 002B | PLUS SIGN | |
| , | 44 | 002C | COMMA | |
| — | 45 | 002D | HYPHEN-MINUS | |
| . | 46 | 002E | FULL STOP | |
| 47 | 002F | SOLIDUS | ||
| 48 | 0030 | DIGIT ZERO | ||
| 1 | 49 | 0031 | DIGIT ONE | |
| 2 | 50 | 0032 | DIGIT TWO | |
| 3 | 51 | 0033 | DIGIT THREE | |
| 4 | 52 | 0034 | DIGIT FOUR | |
| 5 | 53 | 0035 | DIGIT FIVE | |
| 6 | 54 | 0036 | DIGIT SIX | |
| 7 | 55 | 0037 | DIGIT SEVEN | |
| 8 | 56 | 0038 | DIGIT EIGHT | |
| 9 | 57 | 0039 | DIGIT NINE | |
| 58 | 003A | COLON | ||
| ; | 59 | 003B | SEMICOLON | |
| < | 60 | 003C | < | LESS-THAN SIGN |
| = | 61 | 003D | EQUALS SIGN | |
| > | 62 | 003E | > | GREATER-THAN SIGN |
| ? | 63 | 003F | QUESTION MARK | |
| @ | 64 | 0040 | COMMERCIAL AT | |
| A | 65 | 0041 | LATIN CAPITAL LETTER A | |
| B | 66 | 0042 | LATIN CAPITAL LETTER B | |
| C | 67 | 0043 | LATIN CAPITAL LETTER C | |
| D | 68 | 0044 | LATIN CAPITAL LETTER D | |
| E | 69 | 0045 | LATIN CAPITAL LETTER E | |
| F | 70 | 0046 | LATIN CAPITAL LETTER F | |
| G | 71 | 0047 | LATIN CAPITAL LETTER G | |
| H | 72 | 0048 | LATIN CAPITAL LETTER H | |
| I | 73 | 0049 | LATIN CAPITAL LETTER I | |
| J | 74 | 004A | LATIN CAPITAL LETTER J | |
| K | 75 | 004B | LATIN CAPITAL LETTER K | |
| L | 76 | 004C | LATIN CAPITAL LETTER L | |
| M | 77 | 004D | LATIN CAPITAL LETTER M | |
| N | 78 | 004E | LATIN CAPITAL LETTER N | |
| O | 79 | 004F | LATIN CAPITAL LETTER O | |
| P | 80 | 0050 | LATIN CAPITAL LETTER P | |
| Q | 81 | 0051 | LATIN CAPITAL LETTER Q | |
| R | 82 | 0052 | LATIN CAPITAL LETTER R | |
| S | 83 | 0053 | LATIN CAPITAL LETTER S | |
| T | 84 | 0054 | LATIN CAPITAL LETTER T | |
| U | 85 | 0055 | LATIN CAPITAL LETTER U | |
| V | 86 | 0056 | LATIN CAPITAL LETTER V | |
| W | 87 | 0057 | LATIN CAPITAL LETTER W | |
| X | 88 | 0058 | LATIN CAPITAL LETTER X | |
| Y | 89 | 0059 | LATIN CAPITAL LETTER Y | |
| Z | 90 | 005A | LATIN CAPITAL LETTER Z | |
| 91 | 005B | LEFT SQUARE BRACKET | ||
| \ | 92 | 005C | REVERSE SOLIDUS | |
| 93 | 005D | RIGHT SQUARE BRACKET | ||
| ^ | 94 | 005E | CIRCUMFLEX ACCENT | |
| _ | 95 | 005F | LOW LINE | |
| ` | 96 | 0060 | GRAVE ACCENT | |
| a | 97 | 0061 | LATIN SMALL LETTER A | |
| b | 98 | 0062 | LATIN SMALL LETTER B | |
| c | 99 | 0063 | LATIN SMALL LETTER C | |
| d | 100 | 0064 | LATIN SMALL LETTER D | |
| e | 101 | 0065 | LATIN SMALL LETTER E | |
| f | 102 | 0066 | LATIN SMALL LETTER F | |
| g | 103 | 0067 | LATIN SMALL LETTER G | |
| h | 104 | 0068 | LATIN SMALL LETTER H | |
| i | 105 | 0069 | LATIN SMALL LETTER I | |
| j | 106 | 006A | LATIN SMALL LETTER J | |
| k | 107 | 006B | LATIN SMALL LETTER K | |
| l | 108 | 006C | LATIN SMALL LETTER L | |
| m | 109 | 006D | LATIN SMALL LETTER M | |
| n | 110 | 006E | LATIN SMALL LETTER N | |
| o | 111 | 006F | LATIN SMALL LETTER O | |
| p | 112 | 0070 | LATIN SMALL LETTER P | |
| q | 113 | 0071 | LATIN SMALL LETTER Q | |
| r | 114 | 0072 | LATIN SMALL LETTER R | |
| s | 115 | 0073 | LATIN SMALL LETTER S | |
| t | 116 | 0074 | LATIN SMALL LETTER T | |
| u | 117 | 0075 | LATIN SMALL LETTER U | |
| v | 118 | 0076 | LATIN SMALL LETTER V | |
| w | 119 | 0077 | LATIN SMALL LETTER W | |
| x | 120 | 0078 | LATIN SMALL LETTER X | |
| y | 121 | 0079 | LATIN SMALL LETTER Y | |
| z | 122 | 007A | LATIN SMALL LETTER Z | |
| { | 123 | 007B | LEFT CURLY BRACKET | |
| | | 124 | 007C | VERTICAL LINE | |
| } | 125 | 007D | RIGHT CURLY BRACKET | |
| ~ | 126 | 007E | TILDE |