Как (и зачем) бесплатно парсить ключи и объявления конкурентов из яндекс.директ и google ads
Содержание:
Плюсы парсинга
У автоматического сбора информации куча преимуществ (по сравнению с ручным методом):
- Программа работает самостоятельно. Не приходится тратить время на поиск и сортировку данных. К тому же собирает она информацию куда быстрее человека. Да еще и делает это 24 на 7, если понадобится.
- Парсеру можно «скормить» столько параметров, сколько потребуется, и идеально отстроить его для поиска только необходимого контента. Без мусора, ошибок и нерелеватной информации с неподходящих страниц.
- В отличие от человека, парсер не будет допускать глупых ошибок по невнимательности. И не устанет.
- Утилита для парсинга может подавать найденные данные в удобном формате по запросу пользователя.
- Парсеры умеют грамотно распределять нагрузку на сайт. Это значит, что он случайно не «уронит» чужой ресурс, а вас не обвинят в незаконной DDoS-атаке.
Так что нет никакого смысла «парсить» руками, когда можно доверить эту операцию подходящему ПО.
Как пользоваться парсером Wordstat от Click.ru
В числе инструментов Click.ru как раз есть функциональный и недорогой парсер Wordstat. Он быстро выдает частотность даже по большому списку запросов. При этом учитывает типы соответствия и региональность. Еще не требует капчу и прокси-серверы, а отчеты позволяет выгружать в Excel и хранить в «облаке».
Для начала работы зарегистрируйтесь в системе Click.ru. После входа в свой аккаунт на главной странице выберите раздел «Парсер частоты Wordstat» и приступайте к работе.
 Для начала парсинга перейдите в соответствующий раздел
Для начала парсинга перейдите в соответствующий раздел
Как работать с парсером Wordstat после регистрации в Click.ru:
Загрузите список запросов.
Есть два способа: скопировать и вставить ключи в специальное поле или же загрузить XLSX-файл с ними.
При копировании списка учитывайте, что каждый ключ должен идти с новой строки. А в эксель-файле смотрите, чтобы не было вспомогательной информации (названий столбцов, лишних цифр и т. д.). Система берет запросы из первого листа .XLSX по принципу «одна ячейка – один ключ».
 Этап загрузки запросов
Этап загрузки запросов
Выберите регионы.
В системе доступны все регионы Яндекса. Можно посчитать общую частотность по нескольким регионам или получить статистику отдельно по каждому.
Разделять регионы в отчете нужно, если вы планируете продвигать бизнес отдельными региональными поддоменами и посадочными страницами, привязанными к географии. В остальных случаях галочка не ставится.
 Выбираем регионы
Выбираем регионы
Укажите тип соответствия.
Широкое соответствие – когда фразы пробиваются как есть – часто показывает обманчивую частотность. Все из-за того, что учитываются все вложенные ключи, в том числе нерелевантные (как в примере с игрушками). То есть всегда лучше перепроверять частоту запроса с помощью специальных операторов.
Кавычки позволяют уточнять статистику по конкретной фразе, без учета вложенных ключей.
Пример
| скачать видео бесплатно – 1 111 285 показов | “скачать видео бесплатно” – 8 493 показа |
Кавычки с восклицательными знаками показывают частотность по заданным словоформам.
Пример
| “!купить !телефон” – 37 909 показов | “!купить !телефоны” – 2 798 показов |
Квадратные скобки – фиксируют порядок слов, что особенно важно в туристическом бизнесе
Пример
| – 4 213 показов | – 1 814 показов |
 Все варианты типов соответствия
Все варианты типов соответствия
Запустите проверку.
Время сбора частотностей зависит от количества запросов, регионов и типов соответствия. Если запросов меньше 1 000, процесс займет 1–2 минуты.
Результат будет доступен в списке задач. Можно открыть отчет в браузере или скачать его в формате XLSX.
 Здесь будут появляться отчеты со статистикой
Здесь будут появляться отчеты со статистикой
Цели и задачи новой программы Slovoeb
Создатель софта и ее предназначение
Словоеб (по английски slovoeb) — уникальный seo-инструмент для эффективного сбора и анализа поисковых фраз, не требующий материальных вложений со стороны веб-мастера (бесплатен). Он является младшим братом профессиональной программы по сбору семантического ядра Key Collector, с идентичным интерфейсом и базовым набором парсинга. Парсинг — это процесс сбора поисковых запросов из различных источников (статистика поисковых систем, анализ конкурентов, данные по веб аналитике и т.д.). Словоеб использует для своего парсинга статистику Яндекса — WordStat и данные системы LiveInternet.
Программу slovoeb придумал известный индивидуальный предприниматель и специалист Александр Люстик, автор блога seom.info. Он хотел найти эффективный способ обработки и анализа поисковых запросов. Ориентация конечно была сделана в первую очередь для платной Key Collector, но все базовые функции для хорошего сбора семантики прекрасно реализованы и в бесплатном аналоге.
Как бесплатно скачать программу Словоеб
Последнюю версию Словоеба от 21 октября 2013 года можно скачать здесь. Для ее работы обязательным условием является наличие дополнительного расширения — Microsoft .NET Framework 4.0 Full.
Итак, что же умеет делать Словоеб, чем он будет полезен блоггеру для продвижения его блога в поисковых системах.
Основные инструменты программы slovoeb
- Парсинг сервиса Вордстат поисковика Яндекс. Словоеб умеет собирать все поисковые фразы, которые предоставляет статистика WordStat на каждый запрос своего посетителя. Сбор идет как из основной левой колонки сервиса, так и с правой. Никаких ограничений не существует — пользователь программы видит то же самое, что и любой веб-мастер, использующий статистику Яндекса вручную.
- Статистика сервиса Ливинтернет. Slovoeb предоставляет своему пользователю подробную раскладку по популярности поисковых запросов, которые он может использовать для сбора семантического ядра.
- Определение конкурентности запроса. Словоеб может показать пользователю число сайтов в сети Интернет (которые находятся в индексе поисковой системы Яндекс и Гугл) по заданному запросу. На основе этих данных можно приблизительно оценить конкуренцию (но только приблизительно!).
- Определение целевой страницы в Яндексе и Гугле. Софт определяет для каждого запроса самую релевантную страницу, которая находится на блоге или сайте веб-мастера. Критично для выполнения правильной внутренней перелинковки веб-ресурса.
Букварикс
Букварикс помогает подбирать ключевые слова по запросу / запросам или по домену / доменам сайтов.
Причем при подборе по списку запросов можно задавать минус-слова, чтобы сразу исключать из результатов нецелевые фразы.
Дополнительно есть опция «Анализ доменов», благодаря которой вы можете:
- Выяснить, какие слова подойдут для заданного вами сайта;
- Подсмотреть, какие ключи используют ваши конкуренты, но не используете вы.
Еще одна фишка сервиса – бесплатная база 40+ миллионов уникальных рекламных объявлений Яндекс.Директ по России, Украине, Беларуси, Казахстану, которые можно использовать для вдохновения.
На выбор есть бесплатный онлайн-инструмент, бесплатная десктоп-версия и платный бизнес-аккаунт за 995 рублей.
Виды парсеров по сферам применения
Для организаторов СП (совместных покупок)
Есть специализированные парсеры для организаторов совместных покупок (СП). Их устанавливают на свои сайты производители товаров (например, одежды). И любой желающий может прямо на сайте воспользоваться парсером и выгрузить весь ассортимент.
Чем удобны эти парсеры:
- интуитивно понятный интерфейс;
- возможность выгружать отдельные товары, разделы или весь каталог;
- можно выгружать данные в удобном формате. Например, в Облачном парсере доступно большое количество форматов выгрузки, кроме стандартных XLSX и CSV: адаптированный прайс для Tiu.ru, выгрузка для Яндекс.Маркета и т. д.
Популярные парсеры для СП:
- SPparser.ru,
- Облачный парсер,
- Турбо.Парсер,
- PARSER.PLUS,
- Q-Parser.
Вот три таких инструмента:
- Marketparser,
- Xmldatafeed,
- ALL RIVAL.
Парсеры для быстрого наполнения сайтов
Такие сервисы собирают названия товаров, описания, цены, изображения и другие данные с сайтов-доноров. Затем выгружают их в файл или сразу загружают на ваш сайт. Это существенно ускоряет работу по наполнению сайта и экономят массу времени, которое вы потратили бы на ручное наполнение.
В подобных парсерах можно автоматически добавлять свою наценку (например, если вы парсите данные с сайта поставщика с оптовыми ценами). Также можно настраивать автоматический сбор или обновление данных по расписания.
Примеры таких парсеров:
- Catalogloader,
- Xmldatafeed,
- Диггернаут.
Как пользоваться пересекатором для создания ключевых слов и фраз?
Пересекатор максимально прост и интуитивно понятен в использовании. Достаточно следовать инструкции:
- Установите желаемое количество столбцов от 1 до 8 включительно.
- В каждый столбец внесите слова, предназначенные для пересечения. Обычно это тематические слова, которые в сочетании дают продающий эффект.
- Если есть необходимость исключить часть столбцов, это можно сделать при помощи кнопки внизу. Изменение цвета показывает, что лишние элементы убраны из генератора.
- По завершению процесса добавления в комбинатор нужных ключевиков, можно запустить их пересечение при помощи специальной кнопки. Запуск производится в один клик по элементу интерфейса над столбцами.
- Пересекатор произведет работу и выдаст результат в виде скрещения слов.
Пользоваться сервисом легко и удобно. Благодаря онлайн-режиму создания новых ключевых слов и фраз, что раньше занимало долгие часы, то происходит сейчас в кратчайшие сроки.
Быстрый парсинг всех ключевых слов и объявлений для указанных доменов
Создайте аккаунт в системе PromoPult (или авторизуйтесь, если у вас уже есть аккаунт). Откройте инструмент «Слова и объявления конкурентов». В блоке «Добавить задачу» укажите домены конкурентов или загрузите их с помощью XLSX-файла.

Блок профессиональных настроек пока не трогаем (мы еще разберем его).

В блоке «Поисковые системы» можно выбрать, в какой поисковой системе проверять домены. По умолчанию это Яндекс и Google. Также по умолчанию стоит галочка на пункте «Результаты на едином листе XLS» – в таблице с результатами данные по всем доменам будут сведены на одном листе.
Если вы проверяете небольшое количество доменов (до 5), можете ничего не менять здесь. Если же доменов больше, уберите галочку с этого пункта. В результатах парсинга под каждый домен будет создан отдельный лист – это удобнее для анализа большого количества данных.
Жмем «Запустить проверку». Система начнет парсинг доменов (в нашем случае на это ушло 5 минут). Если у вас нет времени ждать, вы можете закрыть страницу с инструментом – все работы проводятся в фоновом режиме.
После окончания проверки вам на почту придет уведомление:

Раскройте блок «Список задач» и кликните по пиктограмме Excel-таблицы, чтобы скачать отчет. Также здесь можно удалить отчет или запустить повторный парсинг.

В настройках парсинга есть возможность выбрать отображение отчета: отдельный лист для каждого домена или все на одном листе.
В зависимости от этой настройки отчет будет выглядеть по-разному.
Отчет по каждому домену на разных листах
В нашем примере мы получили именно такой отчет. При скачивании загружается архив с файлами в формате CSV:
Что содержит архив:
Файл с уникальными ключевиками для всех конкурентов. Для пяти доменов, которые мы добавляли в проверку, парсер собрал почти 32 000 ключей.

Общие результаты – данные по количеству объявлений на поиске Google и Яндекс. Для каждого домена данные указаны в разрезе регионов.
Технический файл, в котором указаны настройки парсинга.

Файлы с названиями доменов. Содержат ключевые слова конкурентов, заголовки и тексты объявлений. Данные указаны в разрезе поисковых систем и регионов. Например, вы можете посмотреть, какие объявления показывает конкурент в Яндексе в Санкт-Петербурге.
Обратите внимание! При парсинге объявления собираются из результатов поисковой выдачи в таком виде, в котором они отображаются. Кроме основного текста и заголовка могут собираться уточнения, быстрые ссылки и другие расширения (если они есть в объявлении)
Данные по доменам на одном листе
При таком способе отображения отчета загружается один XLSX-файл с четырьмя листами. Даже если вы парсите 50 доменов, листов в файле все равно будет четыре. Какие это листы:
«Результаты общие» – количество уникальных объявлений по всем доменам. Данные указаны в разрезе регионов и поисковых систем.
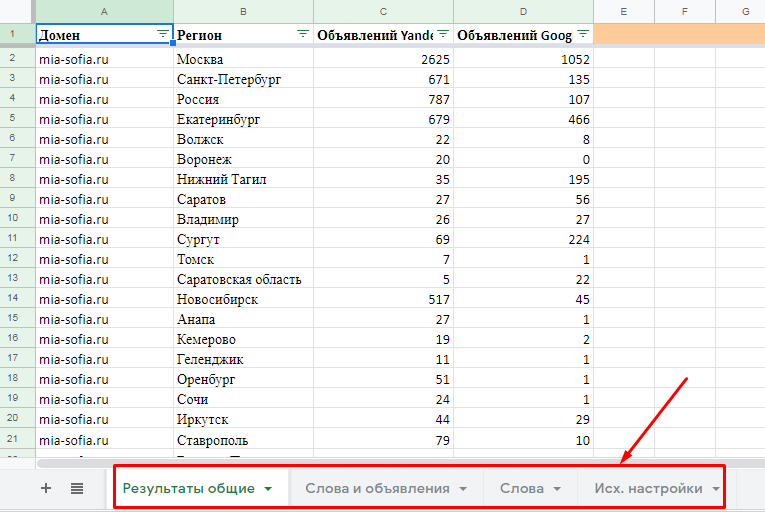
- «Слова и объявления». На этом листе собрана семантика по всем конкурентам и тексты объявлений. Данные указаны по каждому региону и поисковой системе. Если доменов много, работать с такой таблицей будет неудобно.
- «Слова». Собраны уникальные ключевики по всем доменам.
- «Исх. настройки». Указаны настройки парсинга.
Key Collector
KeyCollector – это платная программа, позволяющая разработать эффективную стратегию продвижения сайта, сформировать качественное семантическое ядро, скорректировать внутреннюю перелинковку и т.д.
Возможности Key Collector:
- Упрощение процесса подбора семантического ядра в целом и получение более качественного результата для вашего сайта;
- Сбор информации напрямую с сервисов вместо готовых баз данных или генерации ключевиков;
- Получение информации, как с отечественных, так и с зарубежных источников;
- Получение полной выборки ключевиков с разной частотностью;
- Установка глубины поиска, исключение ненужных слов;
- Оценка полученных результатов по различным параметрам;
- Выгрузка результатов разных форматов;
- Экспресс-анализ позиций в поиске;
- Формирование рекомендаций по внутренней перелинковке сайта.
СтоимостьKeyCollector
При электронном расчете:
- Первая лицензия – 1800 рублей;
- Вторая-десятая лицензия – 1400 рублей;
- Одиннадцатая-двадцатая лицензия – 1300 рублей;
- Покупка оптом – 1300 рублей.
При безналичном расчете (для организаций):
- Первая лицензия – 1900 рублей;
- Вторая-десятая лицензия – 1400 рублей;
- Одиннадцатая-двадцатая лицензия – 1300 рублей;
- Покупка оптом – 1300 рублей.
Персональные данные
Месяц назад мне пришлось бы долго рассуждать на тему общедоступных персональных данных. С 1 марта 2021 года всё стало просто: чтобы законно собирать персональные данные из интернета, нужно получить согласие каждого человека, чьи данные собираются. То, что человек сам разместил свои данные в открытом доступе, больше не имеет значения. На Хабре есть статья о законе, который де-факто запретил парсинг общедоступных персональных данных, поэтому долго рассуждать на эту тему не буду. Кроме того, есть статья на Roem.ru, где объясняются возможные причины принятия этого закона.
Есть один вариант, при котором собирать общедоступные персональные данные всё же можно без согласия каждого конкретного человека: сайт, на котором размещены такие данные, взял у человека согласие на распространение. Иначе говоря, если условный «ВКонтакте» попросит у всех пользователей согласие не только на обработку, но и на распространение персональных данных, то парсинг профилей ВКонтакте снова станет законным — во всяком случае, с точки зрения персональных данных. Однако вряд ли ВКонтакте станет так делать: по делу «ВК против Дабл» можно сделать вывод, что социальная сеть, наоборот, была бы рада максимально затруднить парсинг.
SpyWords
Сервис SpyWords позволяет определить нишу своего сайта, подобрать нужные ключевые слова, а также отслеживать показатели конкурентов.
Возможности SpyWords:
- Определение перспективных продуктов и ниш для запуска рекламы;
- Определение перечня конкурентов по конкретному запросу;
- Анализ конкурентов по контексту и поиску;
- Определение списка ключевых слов конкурентов;
- Просмотр преимуществ, которые конкуренты указывают в рекламе;
- Получение семантического ядра по заданному ключевому слову;
- Получение семантического ядра конкурентов.
Тарифы:
|
Период |
Business |
PRO |
Unlim |
|
12 месяцев (3 бесплатных месяца) |
312 долларов |
387 долларов |
780 долларов |
|
6 месяцев (1 бесплатный месяц) |
173 доллара |
215 долларов |
434 доллара |
|
1 месяц |
35 долларов |
43 доллара |
87 долларов |
|
1 сутки |
7 долларов |
9 долларов |
18 долларов |
Возможности и преимушества#
Многопоточность и производительность
- A-Parser работает на основе последних версий NodeJS и JavaScript движка V8
- AsyncHTTPX — собственная реализация HTTP движка с поддержкой HTTP/1.1 и HTTP/2, HTTPS/TLS, поддержка прокси HTTP/SOCKS4/SOCKS5 с опциональной авторизацией
- в зависимости от конфигурации компьютера и решаемой задачи
- Каждое задание(набор запросов) парсится в указанное число потоков
- При использовании нескольких парсеров в одном задании каждый запрос к разным парсерам выполняется в разных потоках одновременно
- Парсер умеет запускать несколько заданий параллельно
- также проходит в многопоточном режиме
Создание собственных парсеров
- Возможность создания парсеров без написания кода
- Использование регулярных выражений
- Поддержка многостраничного парсинга
- Вложенный парсинг — возможность
- Полноценная : разбор и формирование
- их для обработки полученных результатов прямо в парсере
Создание парсеров на языке JavaScript
- Богатое встроенное API на основе async/await
- Поддержка
- Возможность подключения любых NodeJS модулей
- Управление Chrome/Chromium через puppeteer с поддержкой раздельных прокси для каждой вкладки
Мощные инструменты для формирования запросов и результатов
- Конструктор запросов и результатов — позволяет видоизменять данные(поиск и замена, выделение домена из ссылки, преобразования по регулярным выражениям, XPath…)
- : из файла; перебор слов, символов и цифр, в том числе с заданным шагом
- Фильтрация результатов — по вхождению подстроки, равенству, больше\меньше
- Уникализация результатов — по строке, по домену, по главному домену(A-Parser знает все домены верхнего уровня, в т.ч. такие как co.uk, msk.ru)
- Мощный шаблонизатор результатов на основе — позволяет выводить результаты в любом удобном виде(текстом, csv, html, xml, произвольный формат)
- В парсере используется система пресетов — для каждого парсера можно создать множество предустановленных настроек для различных ситуаций
- Настроить можно все — никаких рамок и ограничений
- и настроек позволяет легко обмениваться опытом с другими пользователями
API
- Возможность интегрировать и управлять парсером из своих программ и скриптов
- Полная автоматизация бизнес-процессов
- Клиенты для PHP, NodeJs, Perl и Python
Значение ключевых слов для продвижения сайта
Оптимизация сайта и его раскрутка строится на анализе ключевых слов. С помощью ключевого слова «опознают» тему и направление веб-ресурса, а также его содержимое. Поисковые запросы в виде ключевиков выдают пользователям нужную страницу. Грамотно подобранные путем анализа семантики варианты ключевых слов заводят людей на сайт, удовлетворяют их любопытство и тем самым подталкивают к покупке.
Можно подобрать ключевые слова без семантического анализа. Но в этом случае велик шанс, что запрос не «выстрелит», соответственно, такой ключевик прибыли не принесет. Чтобы слова были эффективны, нужно понимать принципы работы с ними.
Ключевое слово – что это такое?
Ключевое слово используется в двух случаях:
- во-первых, для поиска в интернете фразы;
- во-вторых, для описания товаров на сайте.
Ключевые слова в первом и втором случае обычно совпадают. При этом запросы пользователей – штука тонкая, тут обязательно нужен анализ. Иногда они бывают совсем не такими, какими их видят специалисты по сео-продвижению или владельцы веб-ресурсов. Из-за этого несоответствия в итоге продукт на сайте не покупают. Поэтому анализ ключевых слов сайта полезен тем, что он максимально устраняет различия между запросами пользователей и описаниями на интернет-площадке.
Примерно лет десять назад копирайтеры стремились как можно плотнее «напичкать» статьи ключевыми словами. В настоящее время акцент делается на качественном полезном контенте, который соответствует определенным потребительским запросам. В тренде уже новейший уровень поисковых запросов – с помощью голоса в мобильных устройствах, в частности с вопросительной интонацией.
Какие бывают ключевые слова
Существуют низкочастотные, среднечастотные и высокочастотные ключевики. В конкретной ситуации любая из этих категорий может быть результативной. Высокочастотные ключи, состоящие из одного-двух слов – носители наиболее объемного трафика, но в то же время они сильно конкурентны. Низкочастотники, состоящие из пяти и более слов, являются менее запрашиваемыми, но как раз именно они приводят целевых потребителей.
В зависимости от цели различают четыре формы запросов. Они могут быть направлены на физическое или виртуальное действие, на получение определенной информации, на посещение отдельно взятого веб-ресурса. На сайт приходят разные типы потребителей, каждый из которых совершает покупки. Поэтому в идеале сочетать все четыре формы запросов на сайте.
Первичные ключевые слова – как их найти?
Стартовая рабочая база ключевиков создается несколькими способами.
- Мозговой штурм – отличный метод в том случае, когда работники компании разбираются в своей нише деятельности и ориентируются в предпочтениях клиентов. В случае с новым товаром накидывается список идей, которые предполагают действия пользователей по поиску продукта.
- Анализ связанных слов проводится с помощью подсказок поисковых систем или в сервисе LSIGraph. Когда фраза вводится в Яндекс или Гугл, уже с первых букв поисковик выдает возможные словосочетания. Внизу поиска можно найти фразы, которые также использовались для запросов. Главное, сформулировать начальный запрос, а дальше уже выстраивается цепочка словосочетаний.
- Фиксация ключевиков, приводящих на веб-ресурс пользователей. Для анализа наиболее часто вводимых ключевых слов используются Google Analytics и Яндекс.Wordstat.
Искать ключевые фразы можно с помощью комментариев и хештегов в соцсетях и блогах, ссылок на геолокацию.
Специальные программы для работы с ключевыми словами
Специальные программы упрощают жизнь сео-оптимизаторам: они обрабатывают все слова и фразы, касающиеся продвигаемого товара. Существуют сервисы, которые давно и успешно зарекомендовали себя как отличный инструмент анализа ключей.
- Google Adwords – планировщик ключевиков. В нем каждый месяц формируются отчеты по статистике, в том числе локальной.
- Кластеризатор Seoquick формирует ключевые слова по темам, чтобы потом сделать работу с ними проще, что актуально, например, для разработки тех же рекламных объявлений.
- Яндекс.Wordstat иллюстрирует популярность тех или иных ключевых слов и помогает подобрать похожие фразы.
Данные инструменты бесплатные, несложные в применении, имеют дружественный интерфейс. Применяются как по отдельности, так и все вместе.
Использование ключевых фраз
Работа со скрупулезно сформированным семантическим ядром ведется осторожно, с использованием синонимов, без переспама и наложения ключевиков – словом, так, чтобы итоговый текст был качественный для ботов и интересный для обычных читателей.
Этапы работы с семантическим ядром
Теперь когда мы знаем, что такое семядро и для чего оно нужно, а также знакомы с основными классификациями запросов, давайте вкратце разберём основные этапы работы с ядром.
Сбор семантики
Подробные способы сбора семантики будут даны в части «», здесь же мы остановимся на основных моментах.
На этом этапе вы должны найти и выписать общие запросы (их ещё называют маркерными), которые характеризуют деятельность вашего бизнеса: как общие направления, так и отдельные услуги и товары.
Например, вы продаёте мотоциклы определённой компании. Вашими маркерными запросами могут являться «мотоциклы», «мотоциклы + бренд» , «как выбрать мотоцикл», «запчасти для мотоцикла + бренд», «как ухаживать за мотоциклом», «классические/спортивные/круизёры и другие типы мотоциклов», «ремонт мотоциклов + бренд» и т.д. То есть в зависимости от оказываемых услуг или имеющихся товаров выбираются соответствующие маркеры.
После определения маркерных запросов проверяйте собранные ключевые слова в основных сервисах статистики запросов: Яндекс.Вордстат или Google Ads Планировщик ключевых слов. В них вы найдёте как частотность запросов, так и варианты других ключевых слов по вашей тематике. Собирайте всё, что как-то связано с вашим бизнесом.
Принципиальная разница между обозначенными сервисами заключается в следующем:
- Статистика в каждом актуальна только для родной поисковой системы. То есть если запрос «юридические услуги» смотреть в Вордстате, то показов будет более 100 000 именно в Яндекс. В Планировщике ключевых слов значения соответственно будут отличаться в Google.
- Плюс Вордстата в том, что он показывает точное значение показов запроса. Если у вас новый аккаунт в Google Ads, вместо точных значений запроса вы получите диапазоны типа 10–100, 100–1000 и т.д.
- Плюс Планировщика ключевых слов в том, что он даёт множество вариантов ключей сразу, чтобы учесть все варианты запросов для вашего сайта в продвижении и рекламе.
Если денег на платные инструменты нет, советуем использовать сразу 2 сервиса при сборе семантики. Но всё же рекомендуем купить Key Collector. Его основная задача — это автоматический сбор (парсинг) ключевых слов не только с Вордстата и Планировщика, но и с других сервисов и баз. Это не реклама данного инструмента, но уточним, что, кроме парсинга, сервис удобен для чистки и кластеризации ядра. Для многих SEO-специалистов Key Collector как швейцарский нож.
Интерфейс KeyCollector
Очистка
Когда все варианты запросов пользователей собраны в одной таблице, наступает время чистки от лишнего.
Лишними являются запросы, которые:
- слишком общие,
- не относятся к деятельности вашего сайта,
- не подходят по географии,
- включают в себя неактуальные цифры и даты,
- имеют брендовые составляющие конкурентов,
- состоят из 8 слов и более,
- затруднительно использовать на одной странице.
В качестве примера приведём подобранные ключи для одной из компаний, которая занимается продажей электрических каминов в Санкт-Петербурге:
Кластеризация и выбор страниц
Кластеризация — это группировка запросов по общности их смысловых значений в иерархическом порядке. То есть в одном кластере, или группе, должны быть запросы, описывающие одну сущность в глазах пользователя и поисковой системы. Делается это либо вручную, либо с помощью специальных сервисов.
Вернёмся к нашим каминам и возьмём следующие запросы:
- камин электрический с эффектом пламени;
- камины электрические с эффектом живого пламени;
- камины электрические фото;
- купить камин электрический;
- камин электрический купить в спб;
- угловой камин электрический;
- угловые камины электрические купить.
Первые два запроса можно объединить в один кластер и продвигать на одной странице. 3-й предполагает галерею или каталог, 4 и 5-й маркерные и достаточно общие, поэтому для них подойдёт главная страница или каталог. 6 и 7-й описывают категорию электрокаминов и под них стоит создать отдельную страницу на сайте.
Это пример ручной кластеризации, но мы указали, что запросы должны описывать одну сущность и в глазах пользователя, и поисковика. И вот тут начинаются проблемы, потому что часто можно столкнуться с тем, что схожие на первый взгляд запросы формируют разную поисковую выдачу. Чтобы избежать таких ошибок, используются специальные сервисы кластеризации, которые сравнивают выдачу и группируют кластеры.
Мониторинг
Важно не просто собрать ключевые слова и использовать их в создании контента для сайта, но и отслеживать рост позиций и трафика по этим запросам. О том, как это делать и какие сервисы можно использовать, читайте в нашей статье про проверку позиций
P. S. Помните о сезонности
Вордстат – и, следовательно, парсер тоже – показывает статистику за последние 30 дней. Если запрос сезонный, можно сделать неправильные выводы, если смотреть только один месяц. Сезонные ключи нужно дополнительно проверять на wordstat.yandex.ru в разделе «История запросов»:
Зарегистрируйтесь в Click.ru сейчас и получите доступ к парсеру Wordstat, а также бесплатным инструментам по созданию и управлению контекстной рекламой – умному подборщику слов, генератору объявлений, медиапланеру, автобиддеру. По промокоду key вы в течение месяца сможете апробировать все возможности сервиса и получать максимальное вознаграждение 8 % вне зависимости от суммы расходов на контекстную рекламу.