15 полезных команд postgresql
Содержание:
Установка и настройка
В данном разделе представлена инструкция по установки и настройке PostgreSQL для разных ОС
Установка
Если установка происходит на macOS, то процесс установки можно запустить командой:
brew install postgresql
На Linux СУБД устанавливается так:
sudo apt-get install postgresql postgresql-contrib
После того, как все загружено и установлено, можно проверить, все ли в порядке, и какая стоит версия PostgreSQL. Для этого выполните следующую команду:
postgres --version
Инструкция по установке в цифровом формате
Настройка
Работа с PostgreSQL может быть произведена через командную строку (терминал) с использованием утилиты psql – инструмент командной строки PostgreSQL.
Необходимо ввести следующую команду:
psql postgres (для выхода из интерфейса используйте \q)
Этой командой запускается утилита psql. Хотя есть много сторонних инструментов для администрирования PostgreSQL, нет необходимости их устанавливать, т. к. psql удобен и отлично работает.
Если нужна помощь, введите (или ) в psql-терминале. Появится список всех доступных параметров справки. Вы можете ввести , если вам нужна помощь по конкретной команде. Например, если ввести в консоли psql, отобразится синтаксис команды .
1 Description update rows of a table
2 WITH RECURSIVE with_query [,
3 UPDATE ONLY table_name * AS alias
4 SET { column_name = { expression | DEFAULT } |
5 ( column_name [, ) = ( { expression | DEFAULT } [, ) |
6 ( column_name [, ) = ( sub-SELECT )
7 } [,
8 FROM from_list
9 WHERE condition | WHERE CURRENT OF cursor_name
10 RETURNING * | output_expression AS output_name [,
Для начала необходимо проверить наличие существующих пользователей и баз данных. Выполните следующую команду, чтобы вывести список всех баз данных:
\list или \l
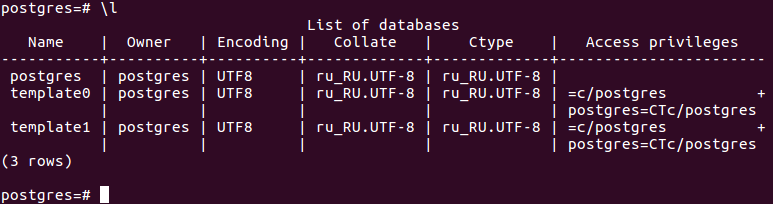 Рисунок 1 — Результат выполнения операции \l
Рисунок 1 — Результат выполнения операции \l
На рисунке выше вы видите три базы данных по умолчанию и суперпользователя postgres, которые создаются при установке PostgreSQL.
Чтобы вывести список всех пользователей, выполните команду . Атрибуты пользователя postgres говорят нам, что он суперпользователь.
 Рисунок 2 — Результат выполнения операции \du
Рисунок 2 — Результат выполнения операции \du
История успеха «Яндекс.Почты» с PostgreSQL
Владимир Бородин (на «Хабре» dev1ant), системный администратор группы эксплуатации систем хранения данных в «Яндекс.Почте», знакомит со сложностями миграции крупного проекта с Oracle Database на PostgreSQL. Это — расшифровка доклада с конференции HighLoad++ 2016.
Всем привет! Меня зовут Вова, сегодня я буду рассказывать про базы данных «Яндекс.Почты».
Сначала несколько фактов, которые будут иметь значение в будущем. «Яндекс.Почта» — сервис достаточно старый: он был запущен в 2000 году, и потому мы накопили много legacy. У нас — как это принято и модно говорить — вполне себе highload-сервис, больше 10 миллионов пользователей в сутки, какие-то сотни миллионов всего. В бэкенд нам прилетает более 200 тысяч запросов в секунду в пике. Мы складываем более 150 миллионов писем в сутки, прошедших проверки на спам и вирусы. Суммарный объём писем за все 16 лет — больше 20 петабайт.
О чем пойдет речь? О том, как мы перевезли метаданные из Oracle в PostgreSQL. Метаданных там не петабайты — их чуть больше трехсот терабайт. В базы влетает более 250 тысяч запросов в секунду. Надо иметь в виду, что это маленькие OLTP-запросы, по большей части чтение (80%).
Это — не первая наша попытка избавиться от Oracle. В начале нулевых была попытка переехать на MySQL, она провалилась. В 2007 или 2008 была попытка написать что-то своё, она тоже провалилась. В обоих случаях был провал не столько по технически причинам, сколько по организационным.
Создание резервной копии и восстановление из бэкапа
Для создания резервной копии базы данных используется сложная команда:
pg_dump -h хост -U имя_роли -F формат_дампа -f путь_к_дампу имя_БД
Чтобы было проще разобраться, рассмотрим каждый параметр:
- хост – сервер, на котором располагается БД. Например, можно указать localhost, домен, IP-адрес.
- имя_роли – имя пользователя PostgreSQL, под которым мы работаем с базой данных.
- формат_дампа – формат, в котором дамп сохранится на сервере. Доступны следующие форматы: c (custom) – архив .tar.gz, t (tar) – архив .tar, p (plain) – текст без сжатия, обычно .sql.
- путь_к_дампу – путь, по которому будет сохранена резервная копия.
- имя_БД – название БД, для которой будет создана резервная копия.
Выглядит это примерно так:
pg_dump -h localhost -U mybase -F c -f /home/user/backups/dump.tar.gz mybase
Для выполнения этой команды нужно ввести пароль, который используется при входе в psql от имени указанной роли (mybase в приведенном примере).
Восстановление из резервной копии выполняется аналогичным образом:
pg_restore -h хост -U имя_роли -F формат_дампа -d имя_базы путь_к_дампу
Параметры похожие, отличия минимальные
Важно знать хост, помнить формат и путь к бэкапу
Мы разобрались с основными действиями и настройками PostgreSQL. На этом все!
Настройки на Master
В данной статье мы будем настраивать серверы с IP-адресами 192.168.1.10 (первичный или master) и 192.168.1.11 (вторичный или slave).
Переходим на сервер, с которого будем реплицировать данные (мастер) и выполняем следующие действия.
Создаем пользователя в PostgreSQL
Входим в систему под пользователем postgres:
su — postgres
Создаем нового пользователя для репликации:
createuser —replication -P repluser
* система запросит пароль — его нужно придумать и ввести дважды. В данном примере мы создаем пользователя repluser.
Выходим из оболочки пользователя postgres:
exit
Настраиваем postgresql
Смотрим расположение конфигурационного файла postgresql.conf командой:
su — postgres -c «psql -c ‘SHOW config_file;'»
В моем случае система вернула строку:
/etc/postgresql/9.6/main/postgresql.conf
* конфигурационный файл находится по пути /etc/postgresql/9.6/main/postgresql.conf.
Открываем конфигурационный файл postgresql.conf.
vi /etc/postgresql/9.6/main/postgresql.conf
* мы открываем файл, который получили sql-командой SHOW config_file;.
Редактируем следующие параметры:
listen_addresses = ‘localhost, 192.168.1.10’
wal_level = replica
max_wal_senders = 2
max_replication_slots = 2
hot_standby = on
hot_standby_feedback = on
* где
- 192.168.1.10 — IP-адрес сервера, на котором он будем слушать запросы Postgre;
- wal_level указывает, сколько информации записывается в WAL (журнал операций, который используется для репликации);
- max_wal_senders — количество планируемых слейвов;
- max_replication_slots — максимальное число слотов репликации (данный параметр не нужен для postgresql 9.2 — с ним сервер не запустится);
- hot_standby — определяет, можно или нет подключаться к postgresql для выполнения запросов в процессе восстановления;
- hot_standby_feedback — определяет, будет или нет сервер slave сообщать мастеру о запросах, которые он выполняет.
Открываем конфигурационный файл pg_hba.conf — он находитсяч в том же каталоге, что и файл postgresql.conf:
vi /etc/postgresql/9.6/main/pg_hba.conf
Добавляем следующие строки:
host replication repluser 127.0.0.1/32 md5
host replication repluser 192.168.1.10/32 md5
host replication repluser 192.168.1.11/32 md5
* данной настройкой мы разрешаем подключение к базе данных replication пользователю repluser с локального сервера (localhost и 192.168.1.10) и сервера 192.168.1.11.
Перезапускаем службу postgresql:
systemctl restart postgresql
* обратите внимание, что название для сервиса в системах Linux может различаться
Плохому танцору…
Многие из вас читали о последних эстонских выборах. И вот интересные факты.
Эстонское правительство наняло IT-вендора Helmes для создания системы представления оперативных данных в течение последних эстонских парламентских выборов. Они (Helmes) построили совершенно новую систему, и по-видимому, не проверили ее в преддверии выборов. Неудивительно, что система упала, и статистика подавалась с задержкой на час.
Почему я пишу об этом? Потому, что Helmes обвиняет СУБД PostgreSQL в задержке. Это все равно, что водитель после попадания в автомобильную аварию обвинит изготовителя двигателя, хотя сам мчался на красный свет. «Если бы только двигатель был чуточку мощнее», — жалуется Helmes, «мы бы проскочили этот чертов перекресток еще до того момента, как другие машины тронутся с места!»
Предполагая, что Google Translate адекватен в своем переводе, Helmes предоставил поистине причудливое объяснение отсутствия тестирования:
«Единственным способом предотвратить эту ситуацию была бы предварительная загрузка данных с тем же объемом информации, что и в разгар выборов. Это не нормально, так как запуск системы не должен зависеть от какого-либо объема псевдо-данных.»
Два важных момента
Хочу обратить еще внимание на два небольших досадных недоразумения, которые пока есть еще в Postgres. Первое недоразумение – это такой параметр по настройке default_statistics_target
Это своеобразный множитель количества страниц, который берет Postgres для расчета статистики. Он этот множитель умножает на 300 и берет такое количество страниц. Множитель может иметь значение от 1 до 10 тысяч, по умолчанию 100. Все хорошо работает при сотке. Но как только мы ставим 10 тысяч, Postgres, действительно, берет много страниц, считает статистику, но потом запросы к базе начинают резко тормозить. К разработчикам мы еще с этим не обращались, вот-вот обратимся, думаю, победим и разберемся.

Второй момент – это репликация
Просто обращу ваше внимание. Разработчики говорят: репликации – это не бэкап
Это действительно так. Кроме того, репликация может отставать на часы и дни. Потому что она однопоточная. Все, что мастер-сервер удалил, создал, обновил в сотне своих потоков, все это придется догонять в один поток. Поэтому реплика это хорошо, мы, например, с нее бэкапы льем, но перед тем, как слить бэкап с реплики, мы проверяем какое отставание. Если отставание не больше секунды, то делаем бэкап с нее, а если больше – то с мастера.
В завершение хочу сказать, что, привлекая компетентных специалистов, вы можете зарабатывать золотые медали любых тестов 1С. Даже на таком новичке в мире 1С, как Postgres, выбирая правильную инфраструктуру.

****************
Данная статья написана по итогам доклада, прочитанного на конференции INFOSTART EVENT 2018 EDUCATION. Больше статей можно прочитать здесь.
В 2020 году приглашаем всех принять участие в 7 региональных митапах, а также юбилейной INFOSTART EVENT 2020 в Москве.
Получение информации о базе данных
Размер базы данных
Чтобы получить физический размер файлов (хранилища) базы данных, используем следующий запрос:
Результат будет представлен как число вида .
— функция, которая возвращает имя текущей базы данных. Вместо неё можно ввести имя текстом:
Для того, чтобы получить информацию в человекочитаемом виде, используем функцию :
В результате получим информацию вида .
Перечень таблиц
Иногда требуется получить перечень таблиц базы данных. Для этого используем следующий запрос:
— стандартная схема базы данных, которая содержит коллекции представлений (views), таких как таблицы, поля и т.д. Представления таблиц содержат информацию обо всех таблицах баз данных.
Запрос, описанный ниже, выберет все таблицы из указанной схемы текущей базы данных:
В последнем условии можно указать имя определенной схемы.
Размер таблицы
По аналогии с получением размера базы данных размер данных таблицы можно вычислить с помощью соответствующей функции:
Функция возвращает объём, который занимает на диске указанный слой заданной таблицы или индекса.
Имя самой большой таблицы
Для того, чтобы вывести список таблиц текущей базы данных, отсортированный по размеру таблицы, выполним следующий запрос:
Для того, чтобы вывести информацию о самой большой таблице, ограничим запрос с помощью :
— имя таблицы, индекса, представления и т.п. — размер представления этой таблицы на диске в количествах страниц (по умолчанию одна страницы равна 8 Кб). — системная таблица, которая содержит информацию о связях таблиц базы данных.
Microsoft Access
for TT in $(mdb-tables file.mdb); do
mdb-export -Q -d '\t' -D '%Y-%m-%d %H:%M:%S' file.mdb "$TT" > "${TT}.tsv"
done
for TT in $(mdb-tables file.mdb); do
mdb-export -D '%Y-%m-%d %H:%M:%S' file.mdb "$TT" > "${TT}.csv"
done
If the tablenames have embedded spaces…
mdb-tables -1 file.mdb| while read TT
do
mdb-export -D '%Y-%m-%d %H:%M:%S' file.mdb "$TT" > "${TT}.csv"
done
A shell script that may be useful for converting entire databases:
#!/bin/sh -e
mdbfn=$1
schemafn=$2
fkfn=$3
datafn=$4
schema=$5
tf=$(tempfile)
pre=""
&& pre="\"${schema}\"."
mdb-schema "${mdbfn}" postgres > "${tf}"
# Schema file
echo "BEGIN;\n" > "${schemafn}"
sp=""
&& echo "CREATE SCHEMA \"${schema}\";\n" >> "${schemafn}"
&& sp="SET search_path = \"${schema}\", pg_catalog;\n"
echo ${sp} >> "${schemafn}"
awk '($0 !~ /^ALTER TABLE.*FOREIGN KEY.*REFERENCES/) {print;}' "${tf}" >> "${schemafn}"
echo "\nEND;" >> "${schemafn}"
# Foreign keys file
echo "BEGIN;\n" > "${fkfn}"
echo ${sp} >> "${fkfn}"
awk '($0 ~ /^ALTER TABLE.*FOREIGN KEY.*REFERENCES/) {print;}' "${tf}" >> "${fkfn}"
echo "\nEND;" >> "${fkfn}"
# Data file
echo "BEGIN;\n" > "${datafn}"
echo "SET CONSTRAINTS ALL DEFERRED;\n" >> "${datafn}"
mdb-tables -1 "${mdbfn}" | while read TT
do
mdb-export -Q -d '\t' -D '%Y-%m-%d %H:%M:%S' "${mdbfn}" "$TT" > "${tf}"
awk -v pre="${pre}" -v TT="${TT}" \
'(NR==1) {gsub(/\t/,"\",\""); print "COPY " pre "\"" TT "\"(\"" $0 "\") FROM stdin;";}' "${tf}" >> "${datafn}"
awk '(NR>1) {gsub(/\t\t/,"\t\\N\t"); gsub(/\t$/,"\t\\N"); gsub(/\t\t/,"\t\\N\t"); print;}' "${tf}" >> "${datafn}"
echo "\\.\n" >> "${datafn}"
done
echo "END;" >> "${datafn}"
rm -f "${tf}"
If this script is saved to the file access2psql.sh and made executable, then it would be used as follows:
access2psql.sh file.mdb schema.sql foreignkeys.sql data.sql pg_schema_name psql -f schema.sql pg_db_name psql -f data.sql pg_db_name psql -f foreignkeys.sql pg_db_name
This script won’t work properly if there are tab characters in text columns, though the call to mdb-export could be modified to export INSERT statements to fix this. Also, mdb-schema has trouble representing multi-column foreign keys, so foreignkeys.sql may need some manual editing.
- Microsoft Access to PostgreSQL Conversion by Jon Hutchings (2001-07-20)
Первый опыт работы с PostgreSQL на Windows
С чего мы начали? В 2014 году рискнули перевести 5 баз 1С общим объемом порядка 100 гигабайт на Postgres. Не сразу стали перепрыгивать бездну нашего незнания между Windows и Linux, а мир 1С, мне кажется, до сих пор на 80% это мир Windows. Поэтому сначала решили перепрыгнуть пропасть незнания между двумя базами данных: MS SQL и PostgreSQL.
Мы запустили Postgres на Windows. Сначала сильно удивились, что оно заработало. В целом все завелось, заработало, даже база открылась. Правда, потом начались бессонные ночи и дни без обеденного перерыва в попытках настроить Postgres так, чтобы он работал хорошо.
На момент 2014 года информации никакой нет. Есть английская документация, а в мире 1С английский язык не в почете: вы даже код пишете на русском. Поэтому читать тяжело, понимать еще тяжелее. И по сравнению с дружественным интерфейсным MS SQL, где вся настройка – это 5 галочек и 2 цифры, настройки в Postgres – это сотни параметров, слишком непонятно, как и на что отреагирует система, отреагирует ли вообще. Менять приходилось по одному параметру, потому что иначе вообще не поймешь, на что была реакция. А очень часто смена одного параметра не давала никакой реакции. Вот так мы и жили примерно полгода до момента обнаружения той самой ошибки, которая сейчас уже исправлена. О ней рассказывал Олег Бартунов.
Это была фантастика. Я на прошлой конференции по Postgres в Москве рассказывал об этом отдельно. Мы долго не верили своим глазам, будучи уверенными, что это мы неопытные и неправильно настроили систему. Потому что не может так база данных себя вести.
Там происходило очень чудесная вещь: у Postgres есть много файлов статистики. Один из них на весь сервер, и он переименовывается несколько десятков, может быть, сотен, может быть, тысяч раз в секунду. Так построена система: она создает рядом новый файл статистики, переименовывая его в действующий. А наша любимая Windows не дает так работать с файлами в своей файловой системе. Если файл кто-то читает, переименовать его нельзя. Postgres по-честному пишет, что у него нет доступа к статистике, поэтому он будет использовать старые файлы. Ладно, используй. Но нет, происходило 15-ти секундное торможение всего сервера, просто на 15 секунд останавливались все транзакции.
Мы долго не верили своим глазам, мы боялись рассказать это разработчикам. Что они бы подумали? Что какие-то дураки взялись за систему, и теперь непонятно, что от нас хотят. В итоге мы боролись-боролись, но не побороли. И все-таки написали письмо в Postgres Pro. Там тоже долго удивлялись, не верили, что такое может быть. Потом подтвердили, что, действительно, есть косяк. Пообещали исправить.
DevConf: переход Uber с PostgreSQL на MySQL
18 мая 2018 года в Digital October состоится DevConf 2018. И мы решили пересказать некоторые интересные доклады с прошлогодней конференции. Там был доклад с несколько холиварным заголовком: «О чём молчит политрук: к дискуссии о переходе Uber с PostgreSQL на MySQL». В нем разработчик MySQL Алексей Копытов рассмотрел различия InnoDb и PostgreSQL на самом низком уровне, включая организацию данных, памяти и репликаций. Предлагаем вашему вниманию краткий пересказ доклада.
История вопроса
Uber перешел с MySQL на Postgres в 2013 году и причины, которые они перечисляют, были во-первых: PostGIS — это геоинформационное расширение для PostgreSQL и хайп. То есть, у PostgreSQL есть некий ореол серьезный, солидная СУБД, совершенный, без недостатков. По крайней мере, если сравнивать с MySQL. Они мало что знали о PostgreSQL, но повелись на весь этот хайп и перешли, а через 3 года пришлось переезжать обратно. И основные причины, если просуммировать их доклад — это плохие эксплуатационные характеристики при эксплуатации в production.
PostgreSQL 11.0 -> 12.0
Фича
Риск
Кому обратить внимание
Комментарий
Изменение поведения функции , вызываемой в стиле SQL, на соответствующее стандарту, «жадное» (Том Лейн)
В случаях, когда искомый шаблон может быть выбран в строке несколькими способами, начальному сегменту шаблона сопоставляется не наибольшая, а наименьшая подстрока; например, шаблон теперь выбирает из входной строки не последнее, а первое вхождение ряда a.
Нарушение работы приложения
Разработчик
Серьезное нарушение совместимости, которое может быть оправдано только тем, что привели функциональность в соответствие со стандартом SQL. Если кто-то использует функцию с паттернами, то необходимо вдумчиво проверить, так как это может привести к труднопредсказуемым последствиям
Проблемы могут оказаться как на стороне БД, так и в запросах со стороны клиента.
Перенос параметров в (Масао Фудзии, Саймон Риггс, Абхиджит Менон-Сен, Сергей Корнилов)
Файл более не используется, и сервер не запустится, если обнаружит его. Теперь для переключения сервера из режима ведущего используются файлы и . Параметр был переименован в , а параметр удалён.
Нарушение работы приложения
Системный администратор
Недопущение конфликта множественных указаний (Питер Эйзентраут)
А именно, допускается только одно из указаний , , , или . Ранее в конфигурации могли присутствовать несколько этих параметров, а действовало только последнее вхождение. Сейчас может задаваться только один, хотя если он задаётся неоднократно, действует так же только последнее указание.
Нарушение работы приложения
Системный администратор
Переход в процессе восстановления по умолчанию к последней линии времени (Питер Эйзентраут)
То есть параметр теперь имеет значение по умолчанию . Ранее подразумевалось значение .
Нарушение работы приложения
Системный администратор
Переименование утилиты командной строки в (Микаэль Пакье)
Нарушение работы приложения
Системный администратор
Добавление в требования ключа — для получения содержимого дампа через стандартное устройство вывода (Эйлер Тавейра)
Ранее дамп выводился в стандартное устройство вывода и тогда, когда назначение не указывалось, но это было признано нежелательным поведением.
Нарушение работы приложения
Системный администратор
Недопущение неоднозначных сокращений в команде утилиты psql (Даниэль Верите)
Ранее, например, при вводе команды выбирался вариант ; однако возможен и вариант , поэтому теперь не будет выбираться никакой.
Нарушение работы приложения
Системный администратор
Изменения в формате внутри команды . Теоретически, это может коснуться системных администраторов или тех, кто работает с БД через и использует .
В новых индексах btree максимальный размер записи индекса сокращён на 8 байт с целью усовершенствования обработки повторяющихся элементов (Питер Гейган)
Вследствие этого при выполнении с индексом, полученным в результате обновления предыдущей версии с применением , может возникнуть ошибка.
Нарушение работы приложения
Системный администратор
Касается только системных администраторов
Важное замечание, которое обязательно должно быть учтено. Подробнее мы написали в начале, когда рассуждали о разных способах апгрейда
Еще один аргумент не в пользу .
Удаление возможности отключения динамической общей памяти (Кётаро Хоригути)
Таким образом, параметр теперь не может принимать значение none.
Нарушение работы приложения
Системный администратор
Автоматическое встраивание в запрос общих табличных выражений (CTE), с возможностью переопределения этого поведения
Падение производительности
Разработчик
В официальной документации эта фича не помечена как несовместимая. Но, как мудро заметил Олег Бартунов, тут возможны проблемы при портировании, только не функциональные, а связанные с производительностью. В 12-й версии обычные CTE из старых версий будут больше подвержены оптимизации планировщика. Теоретически это только в плюс, и производительность, скорее всего, вырастет. Но если планировщик не отрабатывает должным образом, это сможет привести к драматическому падению производительности.Для контроля и быстрого реагирования на проблемы производительности желательно, чтобы был установлен заранее на все БД. Удобнее всего это сделать, добавив его в .
Установка PostgreSQL
Я достаточно долго думал над вопросом, какую систему управления базами данных (СУБД) выбрать для своих статей и решил остановиться на PostgreSQL.
Выбор обусловлен несколькими причинам:
- Бесплатная СУБД
- Простота установки.
- Поддержка основных операционных систем
- Удобная програма pgAdmin для работы с базами
- Это современная СУБД с хорошими возможностями
В принципе в JDK есть встроенная база данных — Derby. Но пользоваться ей, на мой взгляд, очень неудобно. MySQL в общем тоже неплохо, но в нем достаточно неудобная утилита для ввода команд. Остальные базы либо платные, либо малоизвестные. Само собой, после прочтения моих статей вам никто не мешает попробовать поработать с этими базами данных самостоятельно.
Загрузить нужную версию PostgreSQL можно с этой страницы: Download PostgreSQL.
На данный момент я использовал версию 9.5.2. Какая версия будет на момент чтения статьи вами — не знаю. Но надеюсь, что в ближайшие годы что-то кардинально не поменяется.
Будьте внимательны — загружайте версию для вашей операционной системы. Дальше запускаете установку. По экранам она выглядит вот так.

На втором экране вам надо выбрать директорию для установки. Я не рекомендую устанавливать в каталог “Program Files” по умолчанию, т.к. на Windows серверных платформ это бывает чревато. На домашних системах скорее всего проблем не будет, но как говорится, “обэегшись на молоке, дуешь на воду”. Посему я обычно ставлю директорию “C:\PostgreSQL\”
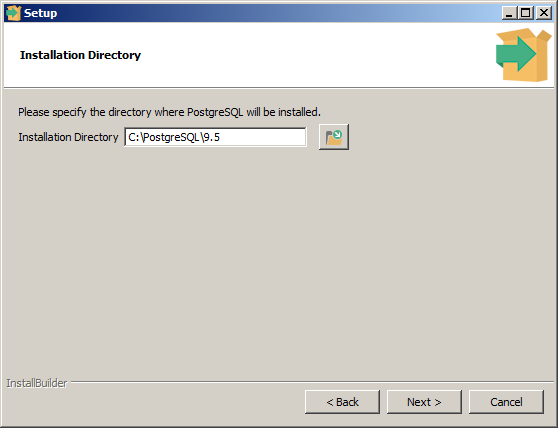
Далее вам предложат дирекотрию для хранения файлов для баз данных — оставляйте как есть.
На следующем экране вам надо ввести парль для пользователя “postgres”. Для разработки я выбираю такой же пароль: “postgres”.
На следующем экране запрашивается порт, на котором будет “висеть” PostgreSQL. Если у вас не установлен PostgreSQL, то можно оставить по умолчанию “5432”.
Локализацию можно оставить как есть. Кому интересно, может выбрать что-нибудь конкретное. Я в принципе проблем не имел при выборе по-умолчанию.
Запускаем установку …
и ждем, пока она закончится.
По окончанию вам предложат установить дополнительную утилиты Stack Builder — я ее обычно не ставлю, так что “галочку” можно снять и нажать “Finish”.
В общем установка закончилась. Теперь в списке сервисов Windows можно увидеть PostgreSQL

Я нередко устанавливаю ручной запуск сервиса, но это уже как вам будет удобно.
Осталось только узнать, что в комплекте PostgreSQL устанавливается весьма удобная и легко понятная программа для управления СУБД — pgAdmin III. Ее можно найти в стартовом меню Windows (если вы работаете под другой ОС — поищите, наверняка найдете).
Запускайте и дальше все достаточно просто.
Кликаем дважды на PostgreSQL 9.5 слева — вас могу попросить ввести пароль.
Дальше вы увидите слева струткуру вашей СУБД.
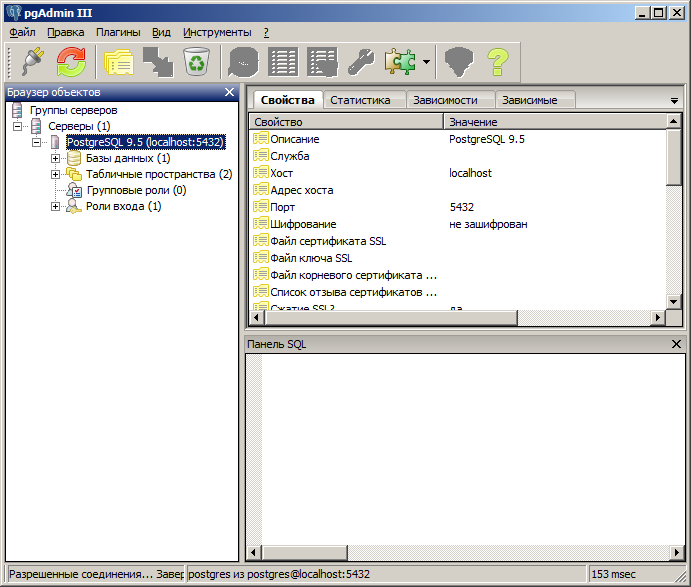
Открываем слева раздел “Базы данных” и видим уже заранее созданную базу “postgres”.
Щелкните правой кнопкой мыши на пункте “Базы данных” и в выпадающем меню выберите “Новая база данных…”. Появится форма для ввода — для начала достаточно ввести имя базы данных — я назвал ее “contactdb”
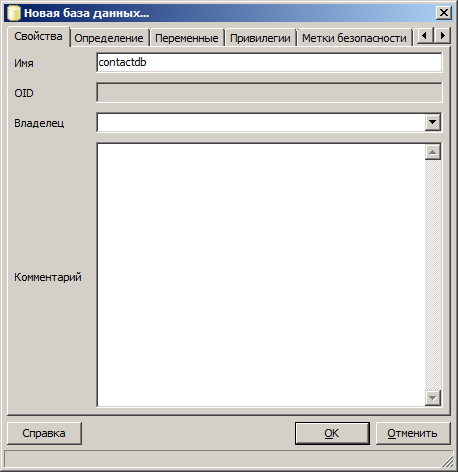
Выделите мышкой вновь созданную базу данных и получите возможность делать с ней, что хотите.
Для запуска команд вам надо открыть SQL-редактор. Проще всего — нажать кнопку на верхней панели.
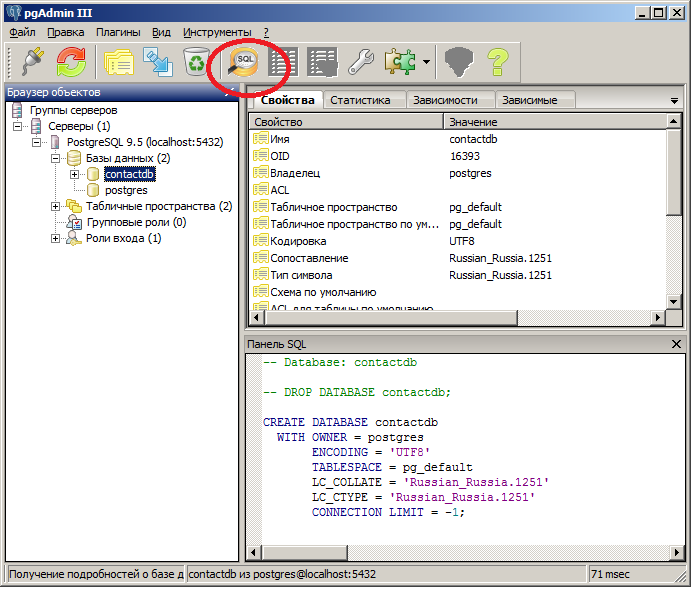
В открытом окне можно набирать команды SQL.
В общем все готово. Мы можем запускать SQL-скрипт, который создаст нужную нам таблицу для контактов и вставит туда тестовые данные.
Для создания необходимых нам данных SQL-скрипт выглядит вот так:
DROP TABLE IF EXISTS JC_CONTACT;
SELECT * from JC_CONTACT;
|
1 |
DROP TABLE IFEXISTS JC_CONTACT; CREATE TABLE JC_CONTACT ( CONTACT_ID SERIAL, FIRST_NAME VARCHAR(50)NOTNULL, LAST_NAME VARCHAR(50)NOTNULL, PHONE VARCHAR(50)NOTNULL, EMAIL VARCHAR(50)NOTNULL, PRIMARY KEY(CONTACT_ID) ); INSERT INTO JC_CONTACT(FIRST_NAME,LAST_NAME,PHONE,EMAIL)VALUES(‘Peter’,’Belgy’,’+79112345678′,’peter@pisem.net’); INSERT INTO JC_CONTACT(FIRST_NAME,LAST_NAME,PHONE,EMAIL)VALUES(‘Helga’,’Forte’,’+79118765432′,’helga@pisem.net’); SELECT *from JC_CONTACT; |
Понимание джойнов сломано. Это точно не пересечение кругов, честно
Так получилось, что я провожу довольно много собеседований на должность веб-программиста. Один из обязательных вопросов, который я задаю — это чем отличается INNER JOIN от LEFT JOIN.
Чаще всего ответ примерно такой: «inner join — это как бы пересечение множеств, т.е. остается только то, что есть в обеих таблицах, а left join — это когда левая таблица остается без изменений, а от правой добавляется пересечение множеств. Для всех остальных строк добавляется null». Еще, бывает, рисуют пересекающиеся круги.
Я так устал от этих ответов с пересечениями множеств и кругов, что даже перестал поправлять людей.
Дело в том, что этот ответ в общем случае неверен. Ну или, как минимум, не точен.
Преимущества и особенности СУБД PostgreSQL
СУБД PostgreSQL использует для своих баз данных реляционную модель, поддерживая стандартный язык запросов SQL. При этом PostgreSQL предоставляет широкий спектр возможностей. Можно сказать, что Postgres обладает почти всеми возможностями, существующими в других базах данных (как коммерческих, так и Open Source), а также рядом дополнительных.
Сегодня СУБД PostgreSQL работает почти на всех UNIX-платформах, в том числе и на UNIX-подобных системах (FreeBSD и Linux). Вы сможете использовать эту базу данных и на Windows NT Server, и на Windows 2000 Server, и для разработки рабочих станций ME.
Рассмотрим краткий перечень преимуществ и функциональных возможностей СУБД PostgreSQL:
1. Надежность. Надёжность СУБД PostgreSQL проверена и доказана. Она обеспечивается соответствием принципам ACID (атомарность, изолированность, непротиворечивость, сохранность данных), многоверсионностью, наличием Write Ahead Logging (WAL) — общепринятого механизма протоколирования всех существующих транзакций. Сюда же стоит отнести и возможность восстановления базы данных Point in Time Recovery (PITR), репликацию, поддержку целостности данных на уровне схемы.
2. Производительность. В СУБД PostgreSQL она основана на применении индексов, наличии гибкой системы блокировок и интеллектуального планировщика запросов, использовании системы управления буферами памяти и кэширования. Не стоит забывать и про отличную масштабируемость при конкурентной работе.
3. Расширяемость. Для СУБД PostgreSQL это означает, что пользователь может настроить систему посредством определения новых функций, типов, языков, агрегатов, индексов и операторов. А объектная ориентированность СУБД PostgreSQL даёт возможность переносить логику приложения на уровень базы данных, а это, в свою очередь, заметно упрощает разработку клиентов, ведь вся бизнес-логика находится в БД. При этом функции в Postgres однозначно определяются названием, типами и числом аргументов.
4. Поддержка SQL. Её уже упоминали, однако кроме главных возможностей, которые присущи любой SQL-базе, PostgreSQL поддерживает схемы, подзапросы, внешние связки, правила, курсоры, наследование таблиц, триггеры и много чего ещё.
5. Поддержка многочисленных типов данных. СУБД PostgreSQL поддерживает численные (целые, денежные, с фиксированной/плавающей точкой), булевые, символьные, составные, сетевые типы данных, а также перечисление, типы «дата/время», геометрические примитивы, массивы, XML- и JSON-данные. Плюс можно создавать свои типы данных.
Конечно, это далеко не всё, но для общего понимания возможностей СУБД PostgreSQL вполне достаточно. Естественно, база данных заслуживает внимания, особенно если учесть, что она имеет открытый исходный код и распространяется свободно. Освоить эту СУБД вы cможете на курсе в OTUS.