Php regular expressions
Содержание:
Строковые методы, поиск и замена
Следующие методы работают с регулярными выражениями из строк.
Все методы, кроме replace, можно вызывать как с объектами типа regexp в аргументах, так и со строками, которые автоматом преобразуются в объекты RegExp.
Так что вызовы эквивалентны:
var i = str.search(/\s/)
var i = str.search("\\s")
При использовании кавычек нужно дублировать \ и нет возможности указать флаги. Если регулярное выражение уже задано строкой, то бывает удобна и полная форма
var regText = "\\s" var i = str.search(new RegExp(regText, "g"))
Возвращает индекс регулярного выражения в строке, или -1.
Если Вы хотите знать, подходит ли строка под регулярное выражение, используйте метод (аналогично RegExp-методы ). Чтобы получить больше информации, используйте более медленный метод (аналогичный методу ).
Этот пример выводит сообщение, в зависимости от того, подходит ли строка под регулярное выражение.
function testinput(re, str){
if (str.search(re) != -1)
midstring = " contains ";
else
midstring = " does not contain ";
document.write (str + midstring + re.source);
}
Если в regexp нет флага , то возвращает тот же результат, что .
Если в regexp есть флаг , то возвращает массив со всеми совпадениями.
Чтобы просто узнать, подходит ли строка под регулярное выражение , используйте .
Если Вы хотите получить первый результат — попробуйте r.
В следующем примере используется, чтобы найти «Chapter», за которой следует 1 или более цифр, а затем цифры, разделенные точкой. В регулярном выражении есть флаг , так что регистр будет игнорироваться.
str = "For more information, see Chapter 3.4.5.1"; re = /chapter (\d+(\.\d)*)/i; found = str.match(re); alert(found);
Скрипт выдаст массив из совпадений:
- Chapter 3.4.5.1 — полностью совпавшая строка
- 3.4.5.1 — первая скобка
- .1 — внутренняя скобка
Следующий пример демонстрирует использование флагов глобального и регистронезависимого поиска с . Будут найдены все буквы от А до Е и от а до е, каждая — в отдельном элементе массива.
var str = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"; var regexp = //gi; var matches = str.match(regexp); document.write(matches); // matches =
Метод replace может заменять вхождения регулярного выражения не только на строку, но и на результат выполнения функции. Его полный синтаксис — такой:
var newString = str.replace(regexp/substr, newSubStr/function)
- Объект RegExp. Его вхождения будут заменены на значение, которое вернет параметр номер 2
- Строка, которая будет заменена на .
- Строка, которая заменяет подстроку из аргумента номер 1.
- Функция, которая может быть вызвана для генерации новой подстроки (чтобы подставить ее вместо подстроки, полученной из аргумента 1).
Метод не меняет строку, на которой вызван, а просто возвращает новую, измененную строку.
Чтобы осуществить глобальную замену, включите в регулярное выражение флаг .
Если первый аргумент — строка, то она не преобразуется в регулярное выражение, так что, например,
var ab = "a b".replace("\\s","..") // = "a b"
Вызов replace оставил строку без изменения, т.к искал не регулярное выражение , а строку «\s».
В строке замены могут быть такие спецсимволы:
| Pattern | Inserts |
| Вставляет «$». | |
| Вставляет найденную подстроку. | |
| Вставляет часть строки, которая предшествует найденному вхождению. | |
| Вставляет часть строки, которая идет после найденного вхождения. | |
| or | Где или — десятичные цифры, вставляет подстроку вхождения, запомненную -й вложенной скобкой, если первый аргумент — объект RegExp. |
Если Вы указываете вторым параметром функцию, то она выполняется при каждом совпадении.
В функции можно динамически генерировать и возвращать строку подстановки.
Первый параметр функции — найденная подстрока. Если первым аргументом является объект , то следующие параметров содержат совпадения из вложенных скобок. Последние два параметра — позиция в строке, на которой произошло совпадение и сама строка.
Например, следующий вызов возвратит XXzzzz — XX , zzzz.
function replacer(str, p1, p2, offset, s)
{
return str + " - " + p1 + " , " + p2;
}
var newString = "XXzzzz".replace(/(X*)(z*)/, replacer)
Как видите, тут две скобки в регулярном выражении, и потому в функции два параметра , .
Если бы были три скобки, то в функцию пришлось бы добавить параметр .
Следующая функция заменяет слова типа на :
function styleHyphenFormat(propertyName)
{
function upperToHyphenLower(match)
{
return '-' + match.toLowerCase();
}
return propertyName.replace(//, upperToHyphenLower);
}
Буквы, цифры, символы
В регулярных выражениях существуют два вида символов: обозначающие сами себя и символы, которые называют командами (спецсимволы).
Цифры и буквы обозначают сами себя, зато точка — спецсимвол, обозначающий «любой символ». Смотрим примеры:

По сути, в коде выше не существует разницы между функциями preg_replace и str_replace – функционируют они одинаково, разница заключается лишь в ограничителях.
В следующем примере можно увидеть, как использовался спецсимвол «точка» — такое уже нельзя сделать с помощью str_replace:

Раз точка — любой символ, то под регулярку подпадут все подстроки, причем по следующему шаблону: буква ‘x’, потом любой символ, потом снова ‘x’. Первые четыре подстроки попали под данный шаблон (xax xsx x&x x-x), поэтому они заменились на ‘!’. Последняя подстрока (xaax) не подпала по той причине, что внутри (между буквами ‘x’) находится не один, а два символа.
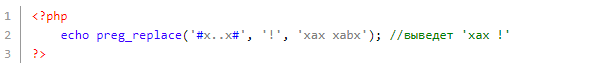
Раз точка — любой символ, а в регулярке мы видим 2 точки подряд, то под регулярку подпадут все подстроки по следующему шаблону: буква ‘x’, потом 2 любых символа, потом снова ‘x’. Первая подстрока не подпадет, т. к. она содержит лишь один символ между буквами ‘x’, в то время как последняя подстрока (xabx) шаблону соответствует.
Что тут важно запомнить: цифры и буквы обозначают сами себя, точка же заменяет любой символ. Также важно следующее: для функции preg_match точка на деле обозначает любой символ за исключением перевода строки
Дабы точка обозначала и его, необходим модификатор s.
Методы класса PatternSyntaxException
PatternSyntaxException — это непроверенное исключение, которое указывает на синтаксическую ошибку в шаблоне. Класс PatternSyntaxException предоставляет следующие методы, чтобы помочь вам определить, что пошло не так:
| № | метод и описание |
|---|---|
| 1 | public String getDescription()
Получает описание ошибки. |
| 2 | public int getIndex()
Получает индекс ошибки. |
| 3 | public String getPattern()
Извлекает ошибочный шаблон регулярного выражения. |
| 4 | public String getMessage()
Возвращает многострочную строку, содержащую описание синтаксической ошибки и ее индекс, ошибочный шаблон регулярного выражения и визуальную индикацию индекса ошибки в шаблоне. |
Примеры
Напишите регулярное выражение, которое соответствует любому номеру телефона.
Телефонный номер в этом примере состоит либо из 7 номеров подряд, либо из 3 номеров, пробела или тире, а затем из 4 номеров.
package regex.phonenumber;
import org.junit.Test;
import static org.junit.Assert.assertFalse;
import static org.junit.Assert.assertTrue;
public class CheckPhone {
@Test
public void testSimpleTrue() {
String pattern = "\\d\\d\\d()?\\d\\d\\d\\d";
String s= "1233323322";
assertFalse(s.matches(pattern));
s = "1233323";
assertTrue(s.matches(pattern));
s = "123 3323";
assertTrue(s.matches(pattern));
}
}
В следующем примере проверяется, содержит ли текст число из 3 цифр.
package regex.numbermatch;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.junit.Test;
import static org.junit.Assert.assertFalse;
import static org.junit.Assert.assertTrue;
public class CheckNumber {
@Test
public void testSimpleTrue() {
String s= "1233";
assertTrue(test(s));
s= "0";
assertFalse(test(s));
s = "29 Kasdkf 2300 Kdsdf";
assertTrue(test(s));
s = "99900234";
assertTrue(test(s));
}
public static boolean test (String s){
Pattern pattern = Pattern.compile("\\d{3}");
Matcher matcher = pattern.matcher(s);
if (matcher.find()){
return true;
}
return false;
}
}
В следующем примере показано как извлечь все действительные ссылки с веб-страницы. Не учитывает ссылки, начинающиеся с «javascript:» или «mailto:».
package regex.weblinks;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class LinkGetter {
private Pattern htmltag;
private Pattern link;
public LinkGetter() {
htmltag = Pattern.compile("<a\\b*href=\"*>(.*?)");
link = Pattern.compile("href=\"*\">");
}
public List getLinks(String url) {
List links = new ArrayList();
try {
BufferedReader bufferedReader = new BufferedReader(
new InputStreamReader(new URL(url).openStream()));
String s;
StringBuilder builder = new StringBuilder();
while ((s = bufferedReader.readLine()) != null) {
builder.append(s);
}
Matcher tagmatch = htmltag.matcher(builder.toString());
while (tagmatch.find()) {
Matcher matcher = link.matcher(tagmatch.group());
matcher.find();
String link = matcher.group().replaceFirst("href=\"", "")
.replaceFirst("\">", "")
.replaceFirst("\"?target=\"*", "");
if (valid(link)) {
links.add(makeAbsolute(url, link));
}
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return links;
}
private boolean valid(String s) {
if (s.matches("javascript:.*|mailto:.*")) {
return false;
}
return true;
}
private String makeAbsolute(String url, String link) {
if (link.matches("http://.*")) {
return link;
}
if (link.matches("/.*") && url.matches(".*$")) {
return url + "/" + link;
}
if (link.matches(".*") && url.matches(".*")) {
return url + "/" + link;
}
if (link.matches("/.*") && url.matches(".*[/]")) {
return url + link;
}
if (link.matches("/.*") && url.matches(".*")) {
return url + link;
}
throw new RuntimeException("Cannot make the link absolute. Url: " + url
+ " Link " + link);
}
}
Поиск дублированных слов. \b является границей слова и \1 ссылается на совпадение первой группы, то есть первого слова. (?!-in)\b(\w+) \1\b находит повторяющиеся слова, если они не начинаются с «-in». Добавьте (?S) для поиска по нескольким строкам.
Поиск элементов, которые начинаются с новой строки.
Также можете посмотреть официальную документацию тут.
Оцени статью
Оценить
Средняя оценка / 5. Количество голосов:
Видим, что вы не нашли ответ на свой вопрос.
Помогите улучшить статью.
Спасибо за ваши отзыв!
Регулярные выражения в PHP
PHP имеет встроенные функции, которые позволяют нам работать с регулярными выражениямии. Давайте теперь посмотрим на часто используемые функции регулярных выражений в PHP.
— эта функция используется для сопоставления с образцом в строке. Она возвращает истину, если совпадение найдено, и ложь, если совпадение не найдено. — эта функция используется для сопоставления с образцом в строке, а затем разбивает результаты в числовой массив. — эта функция используется для сопоставления с образцом строки и затем замены совпадения указанным текстом.Ниже приведен синтаксис функции регулярного выражения, такой как , или :
<?php
function_name('/pattern/',subject);
?>
«function_name (…)» это либо , , либо . «/…/» Косая черта обозначает начало и конец нашего регулярного выражения. «/ pattern /» — это шаблон, который нам нужен. «subject» — текстовая строка, с которой нужно сопоставить.
Давайте теперь посмотрим на практические примеры, которые реализуют вышеупомянутые функции регулярных выражений в PHP.
str.replace(str|regexp, str|func)
Это универсальный метод поиска-и-замены, один из самых полезных. Этакий швейцарский армейский нож для поиска и замены в строке.
Мы можем использовать его и без регулярных выражений, для поиска-и-замены подстроки:
Хотя есть подводный камень.
Когда первый аргумент является строкой, он заменяет только первое совпадение.
Вы можете видеть это в приведённом выше примере: только первый заменяется на .
Чтобы найти все дефисы, нам нужно использовать не строку , а регулярное выражение с обязательным флагом :
Второй аргумент – строка замены. Мы можем использовать специальные символы в нем:
| Спецсимволы | Действие в строке замены |
|---|---|
| вставляет | |
| вставляет всё найденное совпадение | |
| вставляет часть строки до совпадения | |
| вставляет часть строки после совпадения | |
| если это 1-2 значное число, то вставляет содержимое n-й скобки | |
| вставляет содержимое скобки с указанным именем |
Например:
Для ситуаций, которые требуют «умных» замен, вторым аргументом может быть функция.
Она будет вызываться для каждого совпадения, и её результат будет вставлен в качестве замены.
Функция вызывается с аргументами :
- – найденное совпадение,
- – содержимое скобок (см. главу Скобочные группы).
- – позиция, на которой найдено совпадение,
- – исходная строка,
- – объект с содержимым именованных скобок (см. главу Скобочные группы).
Если скобок в регулярном выражении нет, то будет только 3 аргумента: .
Например, переведём выбранные совпадения в верхний регистр:
Заменим каждое совпадение на его позицию в строке:
В примере ниже две скобки, поэтому функция замены вызывается с 5-ю аргументами: первый – всё совпадение, затем два аргумента содержимое скобок, затем (в примере не используются) индекс совпадения и исходная строка:
Если в регулярном выражении много скобочных групп, то бывает удобно использовать остаточные аргументы для обращения к ним:
Или, если мы используем именованные группы, то объект с ними всегда идёт последним, так что можно получить его так:
Использование функции даёт нам максимальные возможности по замене, потому что функция получает всю информацию о совпадении, имеет доступ к внешним переменным и может делать всё что угодно.
Статичные регэкспы
В некоторых реализациях javascript регэкспы, заданные коротким синтаксисом /…/ — статичны. То есть, такой объект создается один раз в некоторых реализациях JS, например в Firefox. В Chrome все ок.
function f() {
// при многократных заходах в функцию объект один и тот же
var re = /lalala/
}
По стандарту эта возможность разрешена ES3, но запрещена ES5.
Из-за того, что при глобальном поиске меняется, а сам объект регэкспа статичен, первый поиск увеличивает , а последующие — продолжают искать со старого , т.е. могут возвращать не все результаты.
При поиске всех совпадений в цикле проблем не возникает, т.к. последняя итерация (неудачная) обнуляет .
«Петя любит Дашу».replace(/Дашу|Машу|Сашу/, «Катю») ¶
Не трудно догадаться, что результатом работы js-выражения выше будет текст . Даже, если Петя неровно дышит к Маше или Саше, то результат всё равно не изменится.
Рассмотрим базовые спец. символы, которые можно использовать в шаблонах:
| Символ | Описание | Пример использования | Результат |
|---|---|---|---|
| \ | Символ экранирования или начала мета-символа | /путь\/к\/папке/ | Надёт текст |
| ^ | Признак начала строки | /^Дом/ | Найдёт все строки, которые начинаются на |
| $ | Признак конца строки | /родной$/ | Найдёт все строки, которые заканчиваются на |
| . | Точка означает любой символ, кроме перевода строки | /Петя ..бит Машу/ | Найдёт как , так и |
| | | Означает ИЛИ | /Вася|Петя/ | Найдёт как Васю, так и Петю |
| ? | Означает НОЛЬ или ОДИН раз | /Вжу?х/ | Найдёт и |
| * | Означает НОЛЬ или МНОГО раз | /Вжу*х/ | Найдёт , , , и т.д. |
| + | Означает ОДИН или МНОГО раз | /Вжу+х/ | Найдёт , , и т.д. |
Помимо базовых спец. символов есть мета-символы (или мета-последовательности), которые заменяют группы символов:
| Символ | Описание | Пример использования | Результат |
|---|---|---|---|
| \w | Буква, цифра или _ (подчёркивание) | /^\w+$/ | Соответствует целому слову без пробелов, например |
| \W | НЕ буква, цифра или _ (подчёркивание) | /\W\w+\W/ | Найдёт полное слово, которое обрамлено любыми символами, например |
| \d | Любая цифра | /^\d+$/ | Соответствует целому числу без знака, например |
| \D | Любой символ НЕ цифра | /^\D+$/ | Соответствует любому выражению, где нет цифр, например |
| \s | Пробел или табуляция (кроме перевода строки) | /\s+/ | Найдёт последовательность пробелов от одного и до бесконечности |
| \S | Любой символ, кроме пробела или табуляции | /\s+\S/ | Найдёт последовательность пробелов, после которой есть хотя бы один другой символ |
| \b | Граница слова | /\bдом\b/ | Найдёт только отдельные слова , но проигнорирует |
| \B | НЕ граница слова | /\Bдом\b/ | Найдёт только окночние слов, которые заканчиваются на |
| \R | Любой перевод строки (Unix, Mac, Windows) | /.*\R/ | Найдёт строки, которые заканчиваются переводом строки |
Нужно отметить, что спец. символы \w, \W, \b и \B не работают по умолчанию с юникодом (включая кириллицу). Для их правильной работы нужно указывать модификатор . К сожалению, на окончание 2019 года JavaScript не поддерживает регулярные выражения для юникода даже с модификатором, поэтому в js эти мета-символы работают только для латиницы.
Ещё регулярные выражения поддерживают разные виды скобочек:
| Выражение | Описание | Пример использования | Результат |
|---|---|---|---|
| (…) | Круглые скобки означают под-шаблон, который идёт в результат поиска | /(Петя|Вася|Саша) любит Машу/ | Найдёт всю строку и запишет воздыхателя Маши в результат поиска под номером 1 |
| (?:…) | Круглые скобки с вопросом и двоеточием означают под-шаблон, который НЕ идёт в результат поиска | /(?:Петя|Вася|Саша) любит Машу/ | Найдёт только полную строку, воздыхатель останется инкогнито |
| (?P<name>…) | Задаёт имя под-шаблона | /(?P<воздыхатель>Петя|Вася|Саша) любит Машу/ | Найдёт полную строку, а воздыхателя запишет в результат под индексом 1 и ‘воздыхатель’ |
| Квадратные скобки задают ЛЮБОЙ СИМВОЛ из последовательности (включая спец. символы \w, \d, \s и т.д.) | /^+$/ | Соответствует любому выражению , но не | |
| Если внутри квадратных скобок указать минус, то это считается диапазоном | /+/ | Аналог /\w/ui для JavaScript | |
| Если минус является первым или последним символом диапазона, то это просто минус | /+/ | Найдёт любое целое числое с плюсом или минусом (причём не обязательно, чтобы минус или плюс были спереди) | |
| Квадратные скобки с «крышечекой» означают любой символ НЕ входящий в диапазон | //i | Найдёт любой символ, который не является буквой, числом или пробелом | |
| ] | Квадратные скобки в квадратных скобках задают класс символов (alnum, alpha, ascii, digit, print, space, punct и другие) | /]+/ | Найдёт последовательность непечатаемых символов |
| {n} | Фигурные скобки с одним числом задают точное количество символов | /\w+н{2}\w+/u | Найдёт слово, в котором две буквы н |
| {n,k} | Фигурные скобки с двумя числами задают количество символов от n до k | /\w+н{1,2}\w+/u | Найдёт слово, в котором есть одна или две буквы н |
| {n,} | Фигурные скобки с одним числом и запятой задают количество символов от n до бесконечности | /\w+н{3,}\w+/u | Найдёт слово, в котором н встречается от трёх и более раз подряд |
Практические примеры сложных регулярных выражений
Теперь, когда вы знаете теорию и основной синтаксис регулярных выражений в PHP, пришло время создать и проанализировать некоторые более сложные примеры.
1) Проверка имени пользователя с помощью регулярного выражения
Начнем с проверки имени пользователя. Если у вас есть форма регистрации, вам понадобится проверять на правильность имена пользователей. Предположим, вы не хотите, чтобы в имени были какие-либо специальные символы, кроме «» и, конечно, имя должно содержать буквы и возможно цифры. Кроме того, вам может понадобиться контролировать длину имени пользователя, например от 4 до 20 символов.
Сначала нам нужно определить доступные символы. Это можно реализовать с помощью следующего кода:
После этого нам нужно ограничить количество символов следующим кодом:
{4,20}
Теперь собираем это регулярное выражение вместе:
^{4,20}$
В случае Perl-совместимого регулярного выражения заключите его символами ‘‘. Итоговый PHP-код выглядит так:
<?php
$pattern = '/^{4,20}$/';
$username = "demo_user-123";
if (preg_match($pattern, $username)) {
echo "Проверка пройдена успешно!";
} else {
echo "Проверка не пройдена!";
}
?>
2) Проверка шестнадцатеричного кода цвета регулярным выражением
Шестнадцатеричный код цвета выглядит так: , также допустимо использование краткой формы, например . В обоих случаях код цвета начинается с и затем идут ровно 3 или 6 цифр или букв от a до f.
Итак, проверяем начало кода:
^#
Затем проверяем диапазон допустимых символов:
После этого проверяем допустимую длину кода (она может быть либо 3, либо 6). Полный код регулярного выражения выйдет следующим:
^#(({3}$)|({6}$))
Здесь мы используем логический оператор, чтобы сначала проверить код вида , а затем код вида . Итоговый PHP-код проверки регулярным выражением выглядит так:
<?php
$pattern = '/^#(({3}$)|({6}$))/';
$color = "#1AA";
if (preg_match($pattern, $color)) {
echo "Проверка пройдена успешно!";
} else {
echo "Проверка не пройдена!";
}
?>
3) Проверка электронной почты клиента с использованием регулярного выражения
Теперь давайте посмотрим, как мы можем проверить адрес электронной почты с помощью регулярных выражений. Сначала внимательно рассмотрите следующие примеры адресов почты:
john.doe@test.com john@demo.ua john_123.doe@test.info
Как мы можем видеть, символ является обязательным элементом в адресе электронной почты. Помимо этого должен быть какой-то набор символов до и после этого элемента. Точнее, после него должно идти допустимое доменное имя.
Таким образом, первая часть должна быть строкой с буквами, цифрами или некоторыми специальными символами, такими как . В шаблоне мы можем написать это следующим образом:
^+
Доменное имя всегда имеет, скажем, имя и tld (top-level domain) – т.е, доменную зону. Доменная зона – это , , и тому подобное. Это означает, что шаблон регулярного выражения для домена будет выглядеть так:
+\.{2,5}$
Теперь, если мы соберем все в кучу, то получим полный шаблон регулярного выражения для проверки адреса электронной почты:
^+@+\.{2,5}$
В коде PHP эта проверка будет выглядеть следующим образом:
<?php
$pattern = '/^+@+\.{2,5}$/';
$email = "john_123.doe@test.info";
if (preg_match($pattern, $email)) {
echo "Проверка пройдена успешно!";
} else {
echo "Проверка не пройдена!";
}
?>
Надеемся, что сегодняшняя статья помогла вам при знакомстве с регулярными выражениями в PHP, а практические примеры пригодятся вам при использовании регулярных выражений в собственных PHP скриптах.
-
3204
-
35
-
Опубликовано 16/04/2019
-
PHP, Уроки программирования
PHP- функции Regexp POSIX
PHP в настоящее время предлагает семь функций для поиска строк с использованием регулярных выражений в стиле POSIX —
| Значение | Описание |
|---|---|
| ereg() | Функция ereg() ищет строку, указанную строкой для строки, заданной шаблоном, возвращает true, если шаблон найден, и false в противном случае. |
| ereg_replace () | Функция ereg_replace() ищет строку, указанную в шаблоне, и заменяет шаблон заменой, если найден. |
| eregi() | Функция eregi() выполняет поиск по всей строке, заданной шаблоном, для строки, указанной строкой. Поиск не чувствителен к регистру. |
| eregi_replace() | Функция eregi_replace() работает точно так же, как и ereg_replace(), за исключением того, что поиск шаблона в строке не чувствителен к регистру. |
| Split() | Функция split() будет разделять строку на различные элементы, границы каждого элемента на основе появления шаблона в строке. |
| spliti() | Функция spliti() работает точно так же, как и sibling split(), за исключением того, что она не чувствительна к регистру. |
| sql_regcase() | Функция sql_regcase() может рассматриваться как служебная функция, преобразующая каждый символ в строку входных параметров в выражение в квадратных скобках, содержащее два символа. |
preg_split()
Функция preg_split() аналогична split() за одним исключением — параметр шаблон может содержать регулярное выражение.
Синтаксис функции preg_split():
array preg_split(string шаблон, string строка ])
Необязательный параметр порог определяет максимальное количество элементов, на которые делится строка. В следующем примере функция preg_split() используется для выборки информации из переменной.
$user_info="+wj+++Gilmore+++++wjgi]more@hotmail.com+++++++Columbus+++OH";
$fields = preg_split("/\+{1.}/", $user_info);
while($x < sizeof($fields)):
print $fields. "<br>";
$x++;
endwhile;
Результат:
WJ Gilmore wjgilmore@hotmail.com Columbus OH














