Запись списка в файл с помощью python
Содержание:
Работа с файлами
После закрытия программы или по окончании работы скрипта все данные, которые мы получили, исчезают. Иногда, впрочем, нам нужно, чтобы они куда-то сохранились. Python предоставляет возможности для работы с файлами, как для их чтения, так и записи.
Попробуем сгенерировать 10 случайных целых чисел от 1 до 100 и записать их в текстовый файл «random.txt», а затем выведем их на печать в консоль из этого документа.
Нам понадобится контекстный менеджер with и функция open, а также знакомая функция print, которая умеет заносить данные в файл.
Познакомимся с двумя режимами работы open: «r» — чтение, «w» – запись.
Итак, контекстный менеджер with автоматически закрывает файл после своей работы (чтобы он не оставался в памяти).
В функцию open хорошей практикой считается не только передача названия файла и режима работы, но и кодировки (чтобы при записи букв российского алфавита, например, мы не получили кракозябры).
Функция print может принимать дополнительный аргумент file, в котором указывается файл на запись.
Переменные в Python
Любой язык программирования оперирует переменными. Это некие значения, которым мы дали имена. Их можно использовать любое количество раз в коде.
Пример плохих или неверных наименований:
- abswqw – не понятно, какой смысл у данной переменной;
- 12Q – имена не могут начинаться с цифры;
- myname – два слова, не отделенные нижним подчеркиванием;
- nomer_telefona – не нужно транслита, следует использовать английские слова, чтобы ваш код понял программист из любой точки планеты.
Правильные переменные:
- name – понятно и отражает суть;
- birth_year – используем змеиную нотацию.
Реализуем простую задачу для новичков на Питоне, которая иногда встречается на собеседованиях!
Получим от пользователя следующие сведения: его имя и страну, в которой бы он хотел побывать. Выведем на печать сообщение: «Доброго дня, {ИМЯ}. {СТРАНА} – интересная страна!». А после этого продемонстрируем пользователю еще одну фразу: «Было приятно с вами поболтать, {ИМЯ}».
Данный проект показывает не только умение начинающего работать с базовыми возможностями языка, но и демонстрирует его умение пользоваться переменными.
Чтобы передать в функцию print переменную вместе с текстом, удобно пользоваться так называемыми f-строками. Синтаксис следующий: print(f’Вы передали переменную {variable}’).
Как видим, переменная может использоваться в разных участках кода после того, как ей присвоено значение.
Python работа с файлами — основные методы
Ниже приводится полный список методов для работы с файлами в текстовом режиме.
| Python работа с файлами — методы | |
| Метод | Описание |
| close() | Закрытие файла. Не делает ничего, если файл закрыт. |
| detach() | Отделяет бинарный буфер от TextIOBase и возвращает его. |
| fileno() | Возвращает целочисленный дескриптор файла. |
| flush() | Вызывает сброс данных (запись на диск) из буфера записи файлового потока. |
| isatty() | Возвращает значение True, если файловый поток интерактивный. |
| read(n) | Читает максимум n символов из файла. Читает до конца файла, если значение отрицательное или None. |
| readable() | Возвращает значение True, если из файлового потока можно осуществить чтение. |
| readline(n=-1) | Читает и возвращает одну строку из файла. Читает максимум n байт, если указано соответствующее значение. |
| readlines(n=-1) | Читает и возвращает список строк из файла. Читает максимум n байт/символов, если указано соответствующее значение. |
| seek(offset,from=SEEK_SET) | Изменяет позицию курсора. |
| seekable() | Возвращает значение True, если файловый поток поддерживает случайный доступ. |
| tell() | Возвращает текущую позицию курсора в файле. |
| truncate(size=None) | Изменяет размер файлового потока до size байт. Если значение size не указано, размер изменяется до текущего положения курсора. |
| writable() | Возвращает значение True, если в файловый поток может производиться запись. |
| write(s) | Записывает строки s в файл и возвращает количество записанных символов. |
| writelines(lines) | Записывает список строк lines в файл. |
Списки, кортежи, множества и словари
Списки, кортежи, множества и словари – еще 4 типа данных в Питоне, включающие в себя несколько значений и являющиеся итерируемыми (перебираемыми, как строки).
Особенности показаны в таблице 3.
| Список (list) | Кортеж (tuple) | Множество (set) | Словарь (dict) |
| Изменяемый | Неизменяемый | Изменяемое | Изменяемый |
| Значения могут дублироваться | Значения могут дублироваться | Значения не могут дублироваться | Ключи не могут дублироваться |
| Доступ по индексу возможен | Доступ по индексу возможен | Доступ по индексу невозможен | Есть доступ к ключам и значениям |
Таблица 3 – Коллекции данных в Python
Список – последовательность произвольных элементов, разделенных запятой. Обозначается квадратными скобками. Можно доставать отдельные составляющие через индекс, добавить в начало списка или конец те или иные значения, удалить элементы, узнать длину, отсортировать.
Рассмотрим часть функционала.
Результат работы скрипта:
Когда необходимо запретить изменение коллекции, ее удобно представлять в виде кортежа. Более того, он занимает меньшее количество в памяти. Записывается в круглых скобках.
На их основании также возможны срезы, доступ по индексу, нахождение максимума или минимума (если элементы представлены числами), поиск количества вхождений значений.
Результат работы скрипта:
Множества хороши в ситуациях, когда нужна гарантия уникальности всех элементов. Задаются фигурными скобками. При добавлении дубликата размер сета никак не меняется
Важно и то, что порядок объектов внутри множества не гарантирован, что исключает доступ по индексу
Результат работы скрипта:
Словарь – особый тип коллекций. Все его элементы состоят из пар «ключ: значение». Ключ должен быть уникальным, а значения могут повторяться. Обозначается фигурными скобками.
Рассмотрим некоторые операции со словарями.
Результат работы скрипта:
Таким образом, в зависимости от ситуации применяется тот или иной тип коллекций. Чаще всего это списки и словари.
Чтение прогонов
Прогон в текстовом документе представляет собой непрерывную последовательность слов, имеющих схожие свойства. Например, одинаковые размеры шрифта, формы шрифта и стили шрифта.
Вторая строка файла my_word_file.docx содержит текст «Welcome to stackabuse.com». Слова «Welcome to» написаны простым шрифтом, а текст «stackabuse.com» — жирным. Следовательно, текст «Welcome to» считается одним прогоном, а текст, выделенный жирным шрифтом «stackabuse.com», считается другим прогоном.
Чтобы получить все прогоны в абзаце, можно использовать свойство run атрибута paragraphобъекта doc.
Считаем все прогоны из абзаца №5 (четвертый указатель) в тексте:
single_para = doc.paragraphs
for run in single_para.runs:
print(run.text)
Вывод:
The best site for learning Python and Other Programming Languages
Аналогичным образом приведенный ниже скрипт выводит все прогоны из 6-го абзаца файла my_word_file.docx:
second_para = doc.paragraphs
for run in second_para.runs:
print(run.text)
Вывод:
Learn to program and write code in the most efficient manner
Как читать файл по частям
Самый простой способ для выполнения этой задачи – использовать цикл. Сначала мы научимся читать файл строку за строкой, после этого мы будем читать по килобайту за раз. В нашем первом примере мы применим цикл:
Python
handle = open(«test.txt», «r»)
for line in handle:
print(line)
handle.close()
|
1 2 3 4 5 6 |
handle=open(«test.txt»,»r») forline inhandle print(line) handle.close() |
Таким образом мы открываем файл в дескрипторе в режиме «только чтение», после чего используем цикл для его повторения
Стоит обратить внимание на то, что цикл можно применять к любым объектам Python (строки, списки, запятые, ключи в словаре, и другие). Весьма просто, не так ли? Попробуем прочесть файл по частям:
Python
handle = open(«test.txt», «r»)
while True:
data = handle.read(1024)
print(data)
if not data:
break
|
1 2 3 4 5 6 7 8 |
handle=open(«test.txt»,»r») whileTrue data=handle.read(1024) print(data) ifnotdata break |
В данном примере мы использовали Python в цикле, пока читали файл по килобайту за раз. Как известно, килобайт содержит в себе 1024 байта или символов. Теперь давайте представим, что мы хотим прочесть двоичный файл, такой как PDF.
Запись прогонов
Вы также можете записать прогоны с помощью модуля python-docx. Для этого нужно создать дескриптор абзаца, к которому хотите добавить прогон:
third_para = mydoc.add_paragraph("This is the third paragraph.")
third_para.add_run(" this is a section at the end of third paragraph")
mydoc.save("E:/my_written_file.docx")
В приведенном выше скрипте записывается абзац с помощью метода add_paragraph()объекта mydoc класса Document. Метод add_paragraph() возвращает дескриптор для вновь добавленного пункта.
Чтобы добавить прогон к новому абзацу, необходимо вызвать метод add_run() для дескриптора абзаца. Текст прогона передается в виде строки в метод add_run(). Затем необходимо вызвать метод save() для создания фактического файла.
Альтернатива для модуля glob
Помимо модулей , в Python также доступен модуль , что предоставляет путь связанных утилит. Функция модуля используется для нахождения файлов, соответствующих шаблону.
Python
from glob import glob
top_xlsx_files = glob(‘*.xlsx’) # Все файлы с расширением .xlsx
all_xlsx_files = glob(‘**/*.xlsx’, recursive=True)
|
1 2 3 4 |
fromglobimportglob top_xlsx_files=glob(‘*.xlsx’)# Все файлы с расширением .xlsx all_xlsx_files=glob(‘**/*.xlsx’,recursive=True) |
Pathlib предоставляет свою реализацию :
Python
from pathlib import Path
top_xlsx_files = Path.cwd().glob(‘*.xlsx’)
all_xlsx_files = Path.cwd().rglob(‘*.xlsx’)
|
1 2 3 4 |
frompathlib importPath top_xlsx_files=Path.cwd().glob(‘*.xlsx’) all_xlsx_files=Path.cwd().rglob(‘*.xlsx’) |
Функциональность glob доступна с объектами . Следовательно, модуль Pathlib упрощают сложные задачи.
Пишем в файлах в Python
Как вы могли догадаться, следуя логике написанного выше, режимы написания файлов в Python это “w” и “wb” для write-mode и write-binary-mode соответственно
Теперь давайте взглянем на простой пример того, как они применяются.ВНИМАНИЕ: использование режимов “w” или “wb” в уже существующем файле изменит его без предупреждения. Вы можете посмотреть, существует ли файл, открыв его при помощи модуля ОС Python
Python
handle = open(«output.txt», «w»)
handle.write(«This is a test!»)
handle.close()
|
1 2 3 |
handle=open(«output.txt»,»w») handle.write(«This is a test!») handle.close() |
Вот так вот просто. Все, что мы здесь сделали – это изменили режим файла на “w” и указали метод написания в файловом дескрипторе, чтобы написать какой-либо текст в теле файла. Файловый дескриптор также имеет метод writelines (написание строк), который будет принимать список строк, который дескриптор, в свою очередь, будет записывать по порядку на диск.
Запись информации в файл
Теперь давайте
посмотрим, как происходит запись информации в файл. Во-первых, нам нужно
открыть файл на запись, например, так:
file = open("out.txt", "w")
и далее вызвать
метод write:
file.write("Hello World!")
В результате у
нас будет создан файл out.txt со строкой «Hello World!». Причем, этот
файл будет располагаться в том же каталоге, что и файл с текстом программы на Python.
Далее сделаем
такую операцию: запишем метод write следующим
образом:
file.write("Hello")
И снова выполним
эту программу. Смотрите, в нашем файле out.txt прежнее
содержимое исчезло и появилось новое – строка «Hello». То есть,
когда мы открываем файл на запись в режимах
w, wt, wb,
то прежнее
содержимое файла удаляется. Вот этот момент следует всегда помнить.
Теперь
посмотрим, что будет, если вызвать метод write несколько раз
подряд:
file.write("Hello1")
file.write("Hello2")
file.write("Hello3")
Смотрите, у нас
в файле появились эти строчки друг за другом. То есть, здесь как и со
считыванием: объект file записывает информацию, начиная с текущей файловой
позиции, и автоматически перемещает ее при выполнении метода write.
Если мы хотим
записать эти строчки в файл каждую с новой строки, то в конце каждой пропишем
символ переноса строки:
file.write("Hello1\n")
file.write("Hello2\n")
file.write("Hello3\n")
Далее, для
дозаписи информации в файл, то есть, записи с сохранением предыдущего
содержимого, файл следует открыть в режиме ‘a’:
file = open("out.txt", "a")
Тогда, выполняя
эту программу, мы в файле увидим уже шесть строчек. И смотрите, в зависимости
от режима доступа к файлу, мы должны использовать или методы для записи, или
методы для чтения. Например, если вот здесь попытаться прочитать информацию с
помощью метода read:
file.read()
то возникнет
ошибка доступа. Если же мы хотим и записывать и считывать информацию, то можно воспользоваться
режимом a+:
file = open("out.txt", "a+")
Так как здесь
файловый указатель стоит на последней позиции, то для считывания информации,
поставим его в самое начало:
file.seek() print( file.read() )
А вот запись
данных всегда осуществляется в конец файла.
Следующий
полезный метод для записи информации – это writelines:
file.writelines("Hello1\n", "Hello2\n")
Он записывает
несколько строк, указанных в коллекции. Иногда это бывает удобно, если в
процессе обработки текста мы имеем список и его требуется целиком поместить в
файл.
Открыть файл VCF на ПК
Если у вас есть файл VCF и вы хотите импортировать его на свой компьютер, используя свой любимый почтовый клиент, следуйте приведенным ниже инструкциям.
Microsoft Outlook (Windows / Mac)
Вы используете Microsoft Outlook в качестве почтового клиента по умолчанию? Тогда знайте, что вы можете импортировать контакты, содержащиеся в файле VCF, непосредственно в адресную книгу программы. Всё, что вам нужно сделать, это нажать кнопку Файл, расположенную в левом верхнем углу, перейти в меню «Открыть и экспортировать» и нажать кнопку Импорт / экспорт.
В открывшемся окне выберите параметр Импорт файла vCard (.vcf), нажмите Далее и выберите файл vcf, из которого необходимо импортировать контакты.
Процедура, которую я только что проиллюстрировал, касается Outlook 2019, но может быть применена с очень небольшими изменениями и в предыдущих версиях программного обеспечения.
Mozilla Thunderbird (Windows / Mac / Linux)
Вы предпочитаете использовать Mozilla Thunderbird для управления своей электронной почтой? Отлично. Даже в этом случае достаточно нескольких щелчков мыши, чтобы открыть файлы VCF и импортировать контакты в адресную книгу.
Всё, что вам нужно сделать, это вызвать адресную книгу, нажав соответствующую кнопку на панели инструментов Thunderbird (вверху слева) и выбрать Инструменты → Импорт из меню, доступного в открывшемся окне.
На этом этапе установите флажок рядом с элементом «Адресные книги», нажмите Далее, выберите запись файла vCard (.vcf) и снова нажмите Далее, чтобы выбрать файл VCF, из которого необходимо импортировать имена и адреса электронной почты.
Apple Mail (Mac)
Если двойной щелчок не открывает автоматически приложение «Контакты» на Mac, запустите его вручную (найдите его значок на первом экране панели запуска), выберите пункт «Файл» → «Импорт» в меню слева вверху и выберите файл VCF с контактами для импорта. Вас могут попросить подтвердить данные некоторых контактов для завершения операции.
Бесплатный конвертер VCF файлов в CSV
Если вы хотите просмотреть содержимое CSV-файла, импортировать его в адресную книгу на вашем компьютере или почтовом клиенте, вы можете положиться на Free VCF file to CSV Converter. Это макрос для Microsoft Excel, который позволяет просматривать содержимое VCF-файлов в виде электронной таблицы и экспортировать их в форматы, подобные CSV (что принято большинством почтовых клиентов и онлайн-служб электронной почты).
Чтобы использовать макрос, загрузите его на свой компьютер, подключившись к странице SourceForge, на которой он находится, и нажав зеленую кнопку Загрузить. После завершения загрузки откройте файл VCF Import v3.xlsm, нажмите кнопку Включить содержимое, чтобы авторизовать выполнение сценариев в документе, и выберите файл VCF для отображения. Подождите несколько секунд, и все данные в файле (имена, адреса электронной почты, номера телефонов, адреса и т.д.) должны появиться в Excel. Вас могут спросить, хотите ли вы удалить пустые строки.
Чтобы экспортировать документ в виде файла CSV или листа Excel, перейдите в меню «Файл» → «Сохранить как» и выберите тип файла, который вы предпочитаете, в раскрывающемся меню «Сохранить как»
Чтение и запись в бинарном режиме доступа
Что такое
бинарный режим доступа? Это когда данные из файла считываются один в один без
какой-либо обработки. Обычно это используется для сохранения и считывания
объектов. Давайте предположим, что нужно сохранить в файл вот такой список:
books =
("Евгений Онегин", "Пушкин А.С.", 200),
("Муму", "Тургенев И.С.", 250),
("Мастер и Маргарита", "Булгаков М.А.", 500),
("Мертвые души", "Гоголь Н.В.", 190)
Откроем файл на
запись в бинарном режиме:
file = open("out.bin", "wb")
Далее, для работы
с бинарными данными подключим специальный встроенный модуль pickle:
import pickle
И вызовем него
метод dump:
pickle.dump(books, file)
Все, мы
сохранили этот объект в файл. Теперь прочитаем эти данные. Откроем файл на
чтение в бинарном режиме:
file = open("out.bin", "rb")
и далее вызовем
метод load модуля pickle:
bs = pickle.load(file)
Все, теперь
переменная bs ссылается на
эквивалентный список:
print( bs )
Аналогичным
образом можно записывать и считывать сразу несколько объектов. Например, так:
import pickle
book1 = "Евгений Онегин", "Пушкин А.С.", 200
book2 = "Муму", "Тургенев И.С.", 250
book3 = "Мастер и Маргарита", "Булгаков М.А.", 500
book4 = "Мертвые души", "Гоголь Н.В.", 190
try:
file = open("out.bin", "wb")
try:
pickle.dump(book1, file)
pickle.dump(book2, file)
pickle.dump(book3, file)
pickle.dump(book4, file)
finally:
file.close()
except FileNotFoundError:
print("Невозможно открыть файл")
А, затем,
считывание в том же порядке:
file = open("out.bin", "rb")
b1 = pickle.load(file)
b2 = pickle.load(file)
b3 = pickle.load(file)
b4 = pickle.load(file)
print( b1, b2, b3, b4, sep="\n" )
Вот так в Python выполняется
запись и считывание данных из файла.
Запись докуменов MS Word
Добавление абзацев осуществляется вызовом метода объекта . Для добавления текста в конец существующего абзаца, надо вызвать метод объекта :
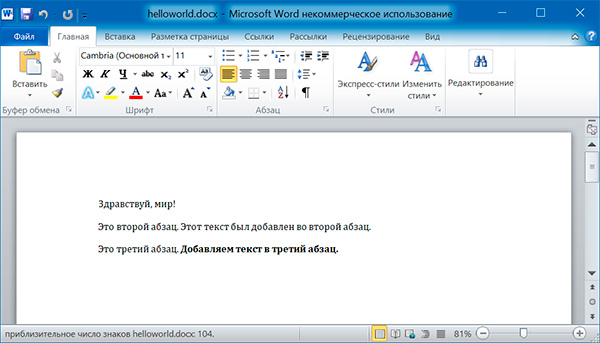
import docx
doc = docx.Document()
# добавляем первый параграф
doc.add_paragraph('Здравствуй, мир!')
# добавляем еще два параграфа
par1 = doc.add_paragraph('Это второй абзац.')
par2 = doc.add_paragraph('Это третий абзац.')
# добавляем текст во второй параграф
par1.add_run(' Этот текст был добавлен во второй абзац.')
# добавляем текст в третий параграф
par2.add_run(' Добавляем текст в третий абзац.').bold = True
doc.save('helloworld.docx')
Оба метода, и принимают необязательный второй аргумент, содержащий строку стиля, например:
doc.add_paragraph('Здравствуй, мир!', 'Title')
Добавление заголовков
Вызов метода приводит к добавлению абзаца, отформатированного в соответствии с одним из возможных стилей заголовков:
doc.add_heading('Заголовок 0', )
doc.add_heading('Заголовок 1', 1)
doc.add_heading('Заголовок 2', 2)
doc.add_heading('Заголовок 3', 3)
doc.add_heading('Заголовок 4', 4)
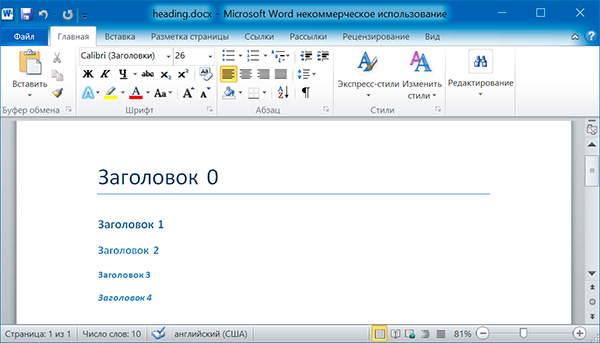
Аргументами метода являются строка текста и целое число от 0 до 4. Значению 0 соответствует стиль заголовка .
Добавление разрывов строк и страниц
Чтобы добавить разрыв строки (а не добавлять новый абзац), нужно вызвать метод объекта . Если же требуется добавить разрыв страницы, то методу надо передать значение в качестве единственного аргумента:
import docx
doc = docx.Document()
doc.add_paragraph('Это первая страница')
doc.paragraphs.runs.add_break(docx.enum.text.WD_BREAK.PAGE)
doc.add_paragraph('Это вторая страница')
doc.save('pages.docx')
Добавление изображений
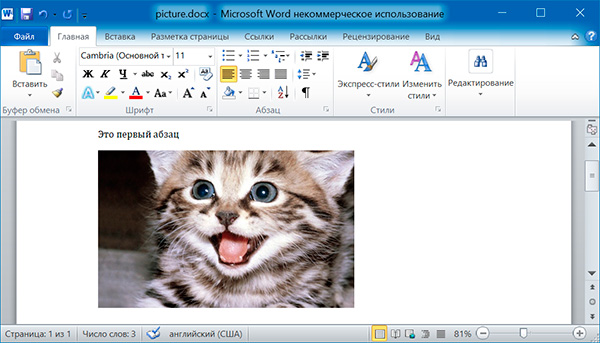
Метод объекта позволяет добавлять изображения в конце документа. Например, добавим в конец документа изображение шириной 10 сантиметров:
import docx
doc = docx.Document()
doc.add_paragraph('Это первый абзац')
doc.add_picture('kitten.jpg', width = docx.shared.Cm(10))
doc.save('picture.docx')
Именованные аргументы и задают ширину и высоту изображения. Если их опустить, то значения этих аргументов будут определяться размерами самого изображения.
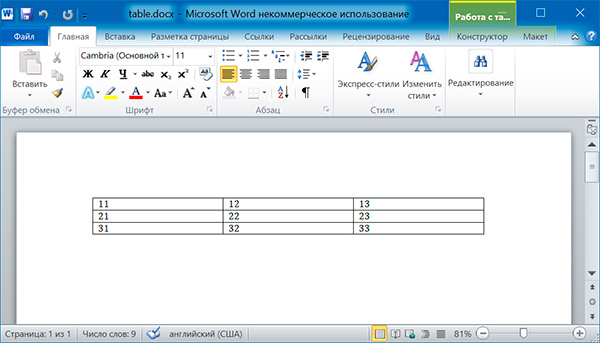
Добавление таблицы
import docx
doc = docx.Document()
# добавляем таблицу 3x3
table = doc.add_table(rows = 3, cols = 3)
# применяем стиль для таблицы
table.style = 'Table Grid'
# заполняем таблицу данными
for row in range(3)
for col in range(3)
# получаем ячейку таблицы
cell = table.cell(row, col)
# записываем в ячейку данные
cell.text = str(row + 1) + str(col + 1)
doc.save('table.docx')
import docx
doc = docx.Document('table.docx')
# получаем первую таблицу в документе
table = doc.tables
# читаем данные из таблицы
for row in table.rows
string = ''
for cell in row.cells
string = string + cell.text + ' '
print(string)
11 12 13 21 22 23 31 32 33
Извлечение текста с помощью PyPDF2
Начнём с . Ниже приведен скрипт, который позволяет извлечь из PDF‑файла текст и вывести него в консоль.
Сначала импортируем , помня о том, что пакет уже установлен. Задаём имя файла из папки (можете загрузить туда свой файл и поменять в скрипте на имя загруженного файла), открывает документ и получаем информацию о документе, используя метод и общее количество страниц . Далее в цикле читаем каждую страницу, получаем содержимое и печатаем в .
Обратите внимание, что PyPDF2 начинает считать страницы с 0, и поэтому вызов при извлекает первую страницу документа
from PyPDF2 import PdfFileReader
pdf_document = "source/Computer-Vision-Resources.pdf"
with open(pdf_document, "rb") as filehandle:
pdf = PdfFileReader(filehandle)
info = pdf.getDocumentInfo()
pages = pdf.getNumPages()
print("Количество страниц в документе: %i\n\n" % pages)
print("Мета-описание: ", info)
for i in range(pages):
page = pdf.getPage(i)
print("Стр.", i, " мета: ", page, "\n\nСодержание;\n")
print(page.extractText())
 Извлечение текста с помощью PyPDF2
Извлечение текста с помощью PyPDF2
Как видите, извлеченный текст печатается сплошным потоком. Здесь нет ни абзацев, ни разделений предложений. Как указано в документации по PyPDF2, все текстовые данные возвращаются в том порядке, в котором они представлены на странице. В основном, это зависит от внутренней структуры документа PDF и от того, как поток инструкций, создан во время его записи, поэтому их использование может привести к неожиданностям, надо дополнительно «парсить», не очень удобно.
Как закрыть файл в Python?
Закрытие освободит ресурсы, которые были связаны с файлом. Это делается с помощью метода close(), встроенного в язык программирования Python.
В Python есть сборщик мусора, предназначенный для очистки ненужных объектов, Но нельзя полагаться на него при закрытии файлов.
f = open("test.txt",encoding = 'utf-8')
# выполнение операций с файлом
f.close()
Этот метод не полностью безопасен. Если при операции возникает исключение, выполнение будет прервано без закрытия файла.
Более безопасный способ – использование блока try…finally.
try:
f = open("test.txt",encoding = 'utf-8')
# выполнение операций с файлом
finally:
f.close()
Это гарантирует правильное закрытие файла даже после возникновения исключения, прерывающего выполнения программы.
Также для закрытия файла можно использовать конструкцию with. Оно гарантирует, что файл будет закрыт при выходе из блока with. При этом не нужно явно вызывать метод close(). Это будет сделано автоматически.
with open("test.txt",encoding = 'utf-8') as f:
# выполнение операций с файлом
Запись файлов Excel
>>> import openpyxl
>>> wb = openpyxl.Workbook()
>>> wb.sheetnames
>>> wb.create_sheet(title = 'Первый лист', index = 0)
<Worksheet "Первый лист">
>>> wb.sheetnames
>>> wb.remove(wb)
>>> wb.sheetnames
>>> wb.save('example.xlsx')
Метод возвращает новый объект , который по умолчанию становится последним листом книги. С помощью именованных аргументов и можно задать имя и индекс нового листа.
Метод принимает в качестве аргумента не строку с именем листа, а объект . Если известно только имя листа, который надо удалить, используйте . Еще один способ удалить лист — использовать инструкцию .
Не забудьте вызвать метод , чтобы сохранить изменения после добавления или удаления листа рабочей книги.
Запись значений в ячейки напоминает запись значений в ключи словаря:
>>> import openpyxl >>> wb = openpyxl.Workbook() >>> wb.create_sheet(title = 'Первый лист', index = 0) >>> sheet = wb >>> sheet = 'Здравствуй, мир!' >>> sheet.value 'Здравствуй, мир!'
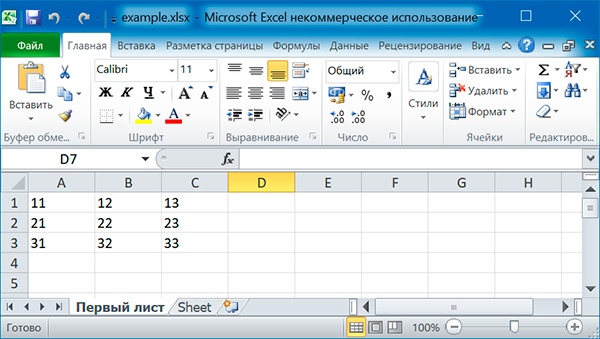
Заполняем таблицу 3×3:
import openpyxl
# создаем новый excel-файл
wb = openpyxl.Workbook()
# добавляем новый лист
wb.create_sheet(title = 'Первый лист', index = )
# получаем лист, с которым будем работать
sheet = wb'Первый лист'
for row in range(1, 4)
for col in range(1, 4)
value = str(row) + str(col)
cell = sheet.cell(row = row, column = col)
cell.value = value
wb.save('example.xlsx')
Можно добавлять строки целиком:
sheet.append('Первый', 'Второй', 'Третий')
sheet.append('Четвертый', 'Пятый', 'Шестой')
sheet.append('Седьмой', 'Восьмой', 'Девятый')
Способ 2
В качестве хитрого способа создать список в одну строку можно использовать генераторы.
import os
import shutil
import glob
# перейти в папаку RandomFiles
os.chdir('./RandomFiles')
# добавить все файлы в данной папке в список
all_files =
# создать множество расширений имен файлов в этой папке
file_types = set((os.path.splitext(f) for f in all_files))
for ftype in file_types:
new_directory = ftype.replace(".", '')
os.mkdir(new_directory)
for fname in glob.glob(f'*.{ftype}'):
shutil.move(fname, new_directory)
Оба варианта сработают, и все ваши файлы будут отсортированы по расширению.
ManageFiles/
|
|_create_random_files.py
|_RandomFiles/
|_doc
|_docx
|_html
|_md
|_odt
|_ppt
Вот и все. Если вам когда-либо понадобится отсортировать файлы таким образом, вы сэкономите немало времени . Код упражнения доступен здесь.
Шаг 4 — Запись файла
На этом этапе мы запишем новый файл, который включает в себя название «Days of the Week», и дни недели. Сначала создадим переменную title.
files.py
title = 'Days of the Weekn'
Также нужно сохранить дни недели в строковой переменной days. Открываем файл в режиме чтения, считываем файл и сохраняем вывод в новую переменную days.
files.py
path = '/users/sammy/days.txt' days_file = open(path,'r') days = days_file.read()
Теперь, когда у нас есть переменные для названия и дней недели, запишем их в новый файл. Сначала нужно указать расположение файла. Мы будем использовать каталог /users/sammy/. Также нужно указать новый файл, который мы хотим создать. Фактический путь будет /users/sammy/new_days.txt. Мы записываем его в переменную new_path. Затем открываем новый файл в режиме записи, используя функцию open() с режимом w.
files.py
new_path = '/users/sammy/new_days.txt' new_days = open(new_path,'w')
Если файл new_days.txt уже существовал до открытия, его содержимое будет удалено, поэтому будьте осторожны при использовании режима «w».
Когда новый файл будет открыт, поместим в него данные, используя <file>.write(). Операция write принимает один параметр, который должен быть строкой, и записывает эту строку в файл.
Если хотите записать новую строку в файл, нужно указать символ новой строки. Мы записываем в файл заголовок, за которым следуют дни недели.
iles.py
new_days.write(title) print(title) new_days.write(days) print(days)
Всякий раз, когда мы заканчиваем работу с файлом, нужно его закрыть. Мы покажем это в заключительном шаге.
The file Object Attributes
Once a file is opened and you have one file object, you can get various information related to that file.
Here is a list of all attributes related to file object −
| Sr.No. | Attribute & Description |
|---|---|
| 1 |
file.closed Returns true if file is closed, false otherwise. |
| 2 |
file.mode Returns access mode with which file was opened. |
| 3 |
file.name Returns name of the file. |
| 4 |
file.softspace Returns false if space explicitly required with print, true otherwise. |
Example
#!/usr/bin/python
# Open a file
fo = open("foo.txt", "wb")
print "Name of the file: ", fo.name
print "Closed or not : ", fo.closed
print "Opening mode : ", fo.mode
print "Softspace flag : ", fo.softspace
This produces the following result −
Name of the file: foo.txt Closed or not : False Opening mode : wb Softspace flag : 0
Ответы на вопросы читателей
Насколько сложно выучить Python? Азы Питона изучаются достаточно просто. Чтобы стать экспертом и высококлассным специалистом потребуется практика и решение реальных задач. Быстро выучить можно, было бы желание.
Какие программы можно создавать, овладев Питоном? Перечень программ органичен лишь фантазией. Разработчики создают порталы и многофункциональные сайты, парсеры, менеджеры баз данных, системы управления ресурсами, чат-боты, программные интерфейсы, сервисы анализа данных, графические оболочки.
Сколько времени потребуется на изучение Питона? Стандартных временных рамок не существует. Однако уже через 1-2 месяца при интенсивной самостоятельной работе с языком можно создавать простые парсеры, небольшие игры, автоматизаторы рутинных задач. А вообще, есть правило 10 тыс. часов – именно столько времени практики потребуется, чтобы посчитать себя специалистом хорошего уровня.
Есть ли слабые стороны у Питона? У любого языка программирования они имеются. Во-первых, скорость работы несколько ниже, чем у компилируемых языков (С++, Java), но ее обычно хватает. Во-вторых, работа с 3d-графикой ограничена. В-третьих, отсутствует проверка типа переменной в момент компиляции.
Какая зарплата у Python-разработчика начинающего уровня? В зависимости от региона она варьируется, но даже Junior-разработчик вполне может рассчитывать на 30-50 тыс. руб. в первые месяцы работы. По мере роста количества навыков лимиты повышаются в разы, а то и десятки раз.
Как лучше учить Python? В наше время методик обучения бесчисленное количество: видеокурсы, книги, игровые платформы, буткампы и пр. Поэтому можно выбрать тот способ, что подходит именно вам. Главное помнить: постоянная практика закрепляет пройденный материал. Простая зубрежка материала не даст никаких видимых результатов.
Где можно посмотреть задачи для новичков, простые проекты? Чтобы попрактиковаться в навыках, необходимо решать разные задачи и сравнивать результаты с другими программистами. Для этого подойдут следующие ресурсы: https://www.codingame.com/, https://www.codewars.com/, https://www.hackerrank.com/. Здесь имеются задания для специалистов любого уровня.
Основа
Python может с относительной легкостью обрабатывать различные форматы файлов:
| Тип файла | Описание |
| Txt | Обычный текстовый файл хранит данные, которые представляют собой только символы (или строки) и не включает в себя структурированные метаданные. |
| CSV | Файл со значениями,для разделения которых используются запятые (или другие разделители). Что позволяет сохранять данные в формате таблицы. |
| HTML | HTML-файл хранит структурированные данные и используется большинством сайтов |
| JSON | JavaScript Object Notation — простой и эффективный формат, что делает его одним из часто используемых для хранения и передачи данных. |
В этой статье основное внимание будет уделено формату txt