Python 3
Содержание:
Реентерабельные замки (RLock)
Класс RLock – это версия замка, который выполняет функцию блокировки только в том случае, если замок удерживает другой поток. В то время как обычные замки блокируют тогда, когда тот же поток пытается получить к одному и тому же замку дважды, реентерабельный замок блокирует только в том случае, если другой поток уже держит замок. Если нынешний поток пытается получить доступ к замку, который и так удерживается, осуществление данной операции проходит в привычном порядке.
Python
lock = threading.Lock()
lock.acquire()
lock.acquire() # заблокирует
lock = threading.RLock()
lock.acquire()
lock.acquire() # не будет блокировать
|
1 2 3 4 5 6 7 |
lock=threading.Lock() lock.acquire() lock.acquire()# заблокирует lock=threading.RLock() lock.acquire() lock.acquire()# не будет блокировать |
В основном это используется для вложенного доступа к общим ресурсам, как показано в предыдущем примере. Для того, чтобы наладить методы доступа в нашем примере, просто замените обычный Lock на RLock и вложенные вызовы заработают так, как надо.
Python
import threading
lock = threading.RLock()
def get_first_part():
lock.acquire()
try:
# берем данные для первой части из общих ресурсах.
finally:
lock.release()
return data
def get_second_part():
lock.acquire()
try:
# берем данные для второй части из общих ресурсах.
finally:
lock.release()
return data
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
importthreading lock=threading.RLock() defget_first_part() lock.acquire() try # берем данные для первой части из общих ресурсах. finally lock.release() returndata defget_second_part() lock.acquire() try # берем данные для второй части из общих ресурсах. finally lock.release() returndata |
При этом вы можете выбрать отдельные части, или обе за раз, не застревая и не получая взаимоисключающих данных
Обратите внимание на то, что этот замок отслеживает уровень рекурсии, так что вам все раз нужно вызвать release по одному разу для каждого вызова для получения доступа
Многопоточность (многозадачность)
multitasking
multitasking — очень удобная библиотека, которая позволяет только лишь при помощи обертки одним декоратором создавать асинхронные, неблокирующие методы. Эту библиотеку удобно использовать, когда возникает необходимость вызвать в отдельном потоке какой-либо неблокирующий метод, например, при обращении к БД или при ожидании какого-либо ответа от системы, но при этом не очень хочется городить кучу вызовов потоков и т.д..
Достаточно выполнить простую установку: pip install multitasking и далее оборачивать метод декоратором @task
И если удалить @multitasking.task, код выполнится последовательно:
Каковы преимущества многопоточности в Python?
У создания многопоточных приложений есть немало преимуществ. Давайте посмотрим на некоторые преимущества:
- Эффективное использование ресурсов;
- Более отзывчивый;
- Совместное использование ресурсов делает его более экономичным;
- Эффективное использование многопроцессорной архитектуры за счет параллелизма;
- Экономит время;
- Потоки (поскольку они являются частью одного процесса) легче взаимодействуют друг с другом, чем если бы они были отдельными процессами;
- Они не требуют больших затрат памяти;
- Многопоточные серверы и интерактивные графические интерфейсы используют исключительно многопоточность.
Многопоточность используется случаях:
- Когда выходы подпрограмм нужно объединить с основной программой.
- Если основная программа содержит фрагмент кода, который относительно независим друг от друга.
- Когда выходы подпрограмм нужно объединить с основной программой.
- Основная программа содержит фрагмент кода, который относительно независим друг от друга.
Модуль Threading определяет множество функций, которые используются для получения данных, связанных с потоками, и эти функции выполняются автоматически.
threading.active_count()
Эта функция возвращает количество объектов Thread, которые в данный момент живы. Здесь возвращаемое количество равно длине списка, возвращаемого enumerate().
threading.current_thread()
Эта функция возвращает текущий объект Thread, и он соответствует потоку управления вызывающей стороны.
threading.get_ident()
Эта функция возвращает «идентификатор потока» текущего потока. Это ненулевое целое число.
threading.enumerate()
Эта функция возвращает список всех текущих объектов Thread, включая демонические потоки, функция current_thread() создает фиктивный поток и основной поток и исключает завершенные потоки и потоки, которые еще не были запущены.
threading.main_thread()
Эта функция возвращает основной объект Thread.
threading.settrace (Func)
Когда все потоки запускаются из модуля потоков, установите функцию трассировки. Перед вызовом метода run() эта функция передается в sys.settrace() для каждого потока.
threading.setprofile (FUNC)
Когда все потоки запускаются из модуля потоков, установите функцию профиля. Перед вызовом метода run() эта функция передается в sys.setprofile() для каждого потока.
threading.stack_size ()
Эта функция возвращает размер стека потоков и используется при создании новых потоков.
import threading
def trace_function():
print("Passing the trace function")
def profile():
print("PROFILE THREAD: " + str(threading.current_thread().getName()))
class mythread(threading.Thread):
def __init__(self, thread_name, thread_ID):
threading.Thread.__init__(self)
self.thread_name = thread_name
self.thread_ID = thread_ID
def run(self):
print(str(self.thread_ID));
print("ACTIVE THREADS ARE: "+ str(threading.active_count()))
print("CURRENT THREAD IS: " + str(threading.current_thread().getName()))
my_thread1 = mythread("PP", 500)
my_thread2 = mythread("PythonProgram", 1000);
print("NAME OF THE MAIN THREAD: " + str(threading.main_thread().getName()))
print("IDENTIFICATION OF MAIN THREAD: "+ str(threading.get_ident()))
print("STACK SIZE = " + str(threading.stack_size()))
print(threading.settrace(trace_function()))
threading.setprofile(profile())
my_thread1.start()
my_thread2.start()
print("LIST OF ENUMERATION: ")
print(threading.enumerate())
print("EXIT")
Эта константа имеет максимальное значение, допустимое для параметра времени ожидания функций блокировки (Lock.acquire(), RLock.acquire(), Condition.wait() и т. д.).
NAME OF THE MAIN THREAD: MainThread IDENTIFICATION OF MAIN THREAD: 5436 STACK SIZE = 0 Passing the trace function None PROFILE THREAD: MainThread 500 1000LIST OF ENUMERATION: ACTIVE THREADS ARE: 6 EXIT CURRENT THREAD IS: Thread-8 ACTIVE THREADS ARE: 5 CURRENT THREAD IS: Thread-9
Перейдем к созданию нашего первого многопоточного приложения.
Threading module
Probably one of the largest drawbacks to the Python programming languages is that it is single-threaded. This means that Python will only run on a single thread naturally. If you have a large computational task, you might have already found that it takes Python a very long time to reach a solution, and yet, your processor might sit at 5% usage or even less. There are quite a few solutions to this problem, like threading, multiprocessing, and GPU programming. All of these are possible with Python, and today we will be covering threading. So, what is threading within the frame of Python? Threading is making use of idle processes, to give the appearance of parallel programming. With threading alone in Python, this is not really the case, but we can indeed use threading to make use of idle times and still gain some significant performance increases.
Along with the video above, here is some explained sample code for threading in Python 3:
import threading from queue import Queue import time
So far, we’ve imported threading, queue and time. Threading is for, well, threading, queue is going to help us make, you guessed it, a queue! Finally, we import time. Our only reason for importing time here is to simulate some idle time with a time.sleep() function.
Next, we’re going to define a thread lock. The idea of a threading lock is to prevent simultaneous modification of a variable. So, if two processes begin interaction with a variable with it is, say, 5, and one operation adds 2, and the other adds 3, we’re going to end with either 7 or 8 as the variable, rather than having it be 5+2+3, which would be 10. A lock will force an operation to wait until the variable is unlocked in order to access and modify it. Another use for a lock is to aid in input/output. With threading, it becomes quite easy to have two processes modifying the same file, and the data will literally just run over each other. So say you are meaning to save two values, like «Monday» and «Tuesday» to a file, you are intending for the file to just read: «Monday Tuesday,» but instead it winds up looking like «MoTunedsadyay.» A lock helps this.
print_lock = threading.Lock()
Here, we’re looking to use the lock to stop print functions from running over each other in their output.
Now we’re ready to create some sort of task to show off threading with:
def exampleJob(worker):
time.sleep(.5) # pretend to do some work.
with print_lock:
print(threading.current_thread().name,worker)
So we define this exampleJob function, with a parameter of worker. With that job, we pretend to do something that will cause some idle, and that is just a time.sleep. After that, we use the print lock, which locks while we’re doing some output to prevent overlapping. Once the with statement completes, the lock will automatically unlock.
Now we need something that will assign tasks to our threads. Here, we’re calling our threads workers.
# The threader thread pulls an worker from the queue and processes it
def threader():
while True:
# gets an worker from the queue
worker = q.get()
# Run the example job with the avail worker in queue (thread)
exampleJob(worker)
# completed with the job
q.task_done()
I’ll let the commenting speak for how this one works, as it would be too confusing to split this one up. See the video as well for more explanation if you need it.
Now we’ve used this «q,» but we’ve not defined it, so we had better do that:
# Create the queue and threader q = Queue()
Now let’s create our threads, and put them to work!
# how many threads are we going to allow for
for x in range(10):
t = threading.Thread(target=threader)
# classifying as a daemon, so they will die when the main dies
t.daemon = True
# begins, must come after daemon definition
t.start()
start = time.time()
# 20 jobs assigned.
for worker in range(20):
q.put(worker)
# wait until the thread terminates.
q.join()
# with 10 workers and 20 tasks, with each task being .5 seconds, then the completed job
# is ~1 second using threading. Normally 20 tasks with .5 seconds each would take 10 seconds.
print('Entire job took:',time.time() - start)
And that’s all there is to it! Questions or comments? Leave them on the YouTube video!
The next tutorial: CX_Freeze Python Tutorial
Subclassing Thread
It is also possible to start a thread by subclassing threading.Thread. Depending on the design of your application, you may prefer this approach. Here, you extend threading.Thread and provide the implementation of your task in the run() method.
import threading
import random, time
class MyTask(threading.Thread):
def __init__(self, sleepFor):
self.secs = sleepFor
threading.Thread.__init__(self)
def run(self):
print self, 'begin sleep(', self.secs, ')'
time.sleep(self.secs)
print self, 'end sleep(', self.secs, ')'
And here is the usage of the class defined above.
tasks = []
for x in xrange(0, 5):
t = MyTask(random.randint(1, 10))
tasks.append(t)
t.start()
print 'joining ..'
while threading.active_count() > 1:
for t in tasks:
t.join()
print t, 'is done.'
print 'all done.'
Communicating With Worker QThreads
If you’re doing multithreaded programming with PyQt, then you might need to establish communication between your application’s main thread and your worker threads. This allows you to get feedback on the progress of worker threads and update the GUI accordingly, send data to your threads, allow the users to interrupt the execution, and so on.
PyQt’s signals and slots mechanism provides a robust and safe way of communicating with worker threads in a GUI application.
On the other hand, you might also need to establish communication between worker threads, such as sharing buffers of data or any other kind of resource. In this case, you need to make sure that you’re properly protecting your data and resources from concurrent access.
Using QThread to Prevent Freezing GUIs
A common use for threads in a GUI application is to offload long-running tasks to worker threads so that the GUI remains responsive to the user’s interactions. In PyQt, you use to create and manage worker threads.
According to Qt’s documentation, there are to create worker threads with :
- Instantiate directly and create a worker , then call on the worker using the thread as an argument. The worker must contain all the required functionality to execute a specific task.
- Subclass and reimplement . The implementation of must contain all the required functionality to execute a specific task.
Instantiating a provides a parallel event loop. An event loop allows objects owned by the thread to receive signals on their slots, and these slots will be executed within the thread. Subclassing allows the application to run parallel code without an event loop.
There’s some debate in the Qt community around which of these approaches is best for creating worker threads. However, the first approach is what Qt’s community and maintainers recommend.
The first approach for creating worker threads requires the following steps:
- Prepare a worker object by subclassing and put your long-running task in it.
- Create a new instance of the worker class.
- Create a new instance.
- Move the worker object into the newly created thread by calling .
- Connect the required signals and slots to guarantee interthread communication.
- Call on the object.
You can turn your Freezing GUI application into a Responsive GUI application using these steps:
First, you do some required imports. Then you run the steps that you saw before.
In step 1, you create , a subclass of . In , you create two signals, and . Note that you must create signals as .
You also create a method called , where you put all the required code to perform your long-running task. In this example, you simulate a long-running task using a loop that iterates times, with a one-second delay in each iteration. The loop also emits the signal, which indicates the operation’s progress. Finally, emits the signal to point out that the processing has finished.
In steps 2 to 4, you create an instance of , which will provide the space for running this task, as well as an instance of . You move your worker object to the thread by calling on , using as an argument.
In step 5, you connect the following signals and slots:
-
The thread’s signal to the worker’s slot to ensure that when you start the thread, will be called automatically
-
The worker’s signal to the thread’s slot to quit when finishes its work
-
The signal to the slot in both objects to delete the worker and the thread objects when the work is done
Finally, in step 6, you start the thread using .
Once you have the thread running, you do some resets to make the application behave coherently. You disable the Long-Running Task! button to prevent the user from clicking it while the task is running. You also connect the thread’s signal with a function that enables the Long-Running Task! button when the thread finishes. Your final connection resets the text of the Long-Running Step label.
If you run this application, then you’ll get the following window on your screen:

Since you offloaded the long-running task to a worker thread, your application is now fully responsive. That’s it! You’ve successfully used PyQt’s to solve the frozen GUI issue that you saw in previous sections.
Python Threading Tutorial Theory
Before we can dive into parallelism, we should cover some theory. In fact, this section will explain why you need parallelism. After that, it will cover the basic jargon you need to know.
Why do we need parallelism?
Parallelism is a simple concept. It means that your program runs some of its parts at the same time. They might be different parts or even multiple instances of the same part. However, each is running independently from the other.
This, of course, adds a little bit of complexity, so why would we do that? Couldn’t we just use a monolithic program that does everything in sequence? We could, but the performance will be far lower. In fact, parallelism has two main benefits.
- Horizontal scalability: you can distribute tasks among cores on your PC, or even among different computers. This means you can access more power, and you can have more just by adding computers in the cluster. This is the opposite of vertical scalability, where you need to upgrade the hardware of the same computer.
- Efficiency: imagine that parts of your script need to wait for something, but some parts do not. You can have only the parts that really need to wait do the waiting, while the others move forward.
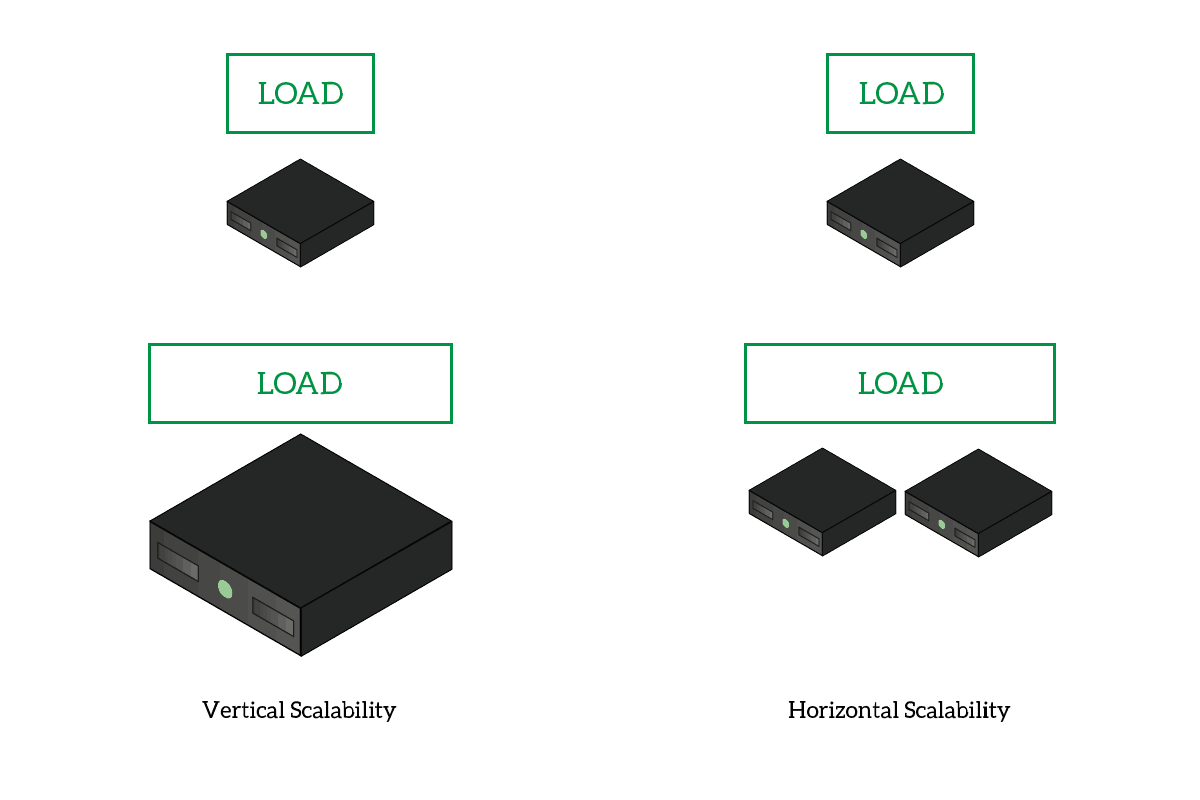 With vertical scalability, you need to enhance the power of your PC. With horizontal scalability, you can add more PCs.
With vertical scalability, you need to enhance the power of your PC. With horizontal scalability, you can add more PCs.
We have different ways of implementing parallelism in Python. Since this is a python threading tutorial, we are going to cover multithreading. However, you should know that other options exist.
Multithreading and Multiprocessing
When it comes to parallelism, we have two main ways to go: multithreading and multiprocessing. The two can achieve similar results in two different ways.
A process is a program running on a computer. The operating system will dedicate some RAM to that process, and allocate some meta-information that it needs to work with that process. You can literally see this as a whole program in execution. Instead, a thread is somehow a lightweight version of a process. It is not a program in execution, but part of it. It is part of a process and shares the memory with other threads in the same process. On top of that, the operating system doesn’t have to allocate the meta-information for the thread.
For a simple task, like running a function, working with multiple threads is the best way to go. In fact, this python threading tutorial will cover how to achieve parallelism with threads. You could apply the same concepts to multiprocessing as well.
Multithreading Jargon
This section of this python threading tutorial is important. If you get the jargon right, understanding the whole article will be a lot easier. Despite being a complex topic, the jargon of python threading is not complex at all.
Sync and Async
 With an async thread, some instructions may be executed concurrently.
With an async thread, some instructions may be executed concurrently.
Asynchronous is the buzzword here. A simple program is going to be synchronous, which means instructions will be executed in order. The program will run each instruction after another, in the order you prepared. However, with threading, you can run parts of the programs asynchronously. This means parts of the code may run before or after some other parts, as they are now unrelated.
This of course is the behavior we require, but we might need to have some thread waiting for the execution of another. In that case, we need to sync the threads. No worries, we will explain how to do it.
Running threads
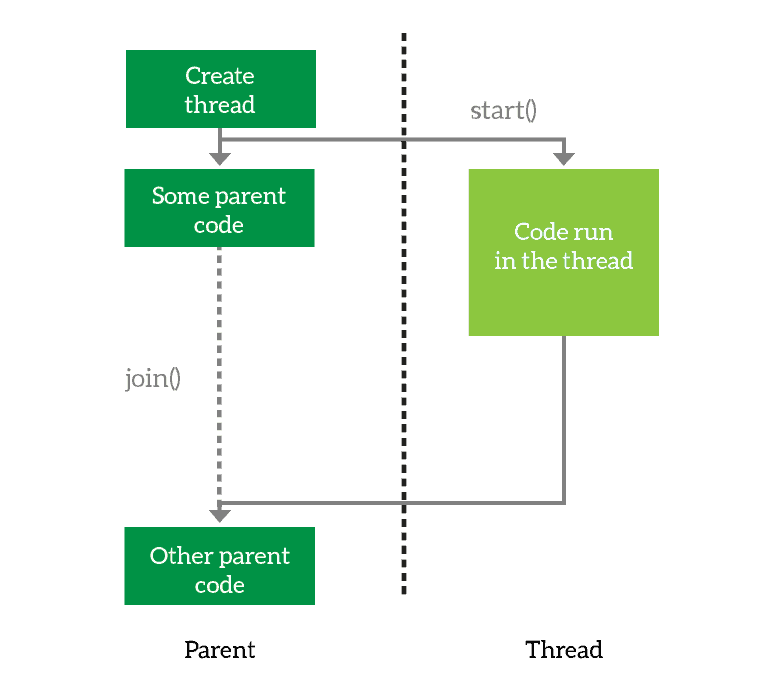 You create a thread, then you launch it. Optionally, you can join it, which means wait for it to finish.
You create a thread, then you launch it. Optionally, you can join it, which means wait for it to finish.
When working with threads, but also with processes, we need to know some common operations.
The first thing you need to do is to define the thread. You basically prepare it for execution and tell it what it will have to do. However, you are not executing the thread just yet. When you want the thread to start working, you simply start it. Then, the thread will run asynchronously from your main program. However, you may want your program to wait for the thread to finish. In that case, you join the thread. This tells your program to wait for its thread to terminate, and you can join multiple threads as well.
Looking at the above example, we create the thread and launch it. Then, we run some code in the parent and after that, we wait for the thread to finish.
Зачем нужен GIL?
Потоковый модуль использует потоки, многопроцессорный модуль использует процессы. Разница в том, что потоки выполняются в одном и том же пространстве памяти, а у процессов отдельная память. Это немного затрудняет совместное использование объектов процессами с многопроцессорной обработкой. В этом случае обычно выполняется сериализация объектов. Но потоки используют одну память, поэтому нужно быть осторожным, иначе два потока будут записывать данные в одну и ту же память одновременно. Именно для этого и существует глобальная блокировка интерпретатора.
Если бы мы запустили на Python скрипт, выполняющий простую задачу — спать (ну очень времязатратную!), он выглядел бы так:
Получаем результат, который и ожидали:

Рабочий процесс этого скрипта будет выглядеть примерно так:

Начнём с потокового модуля
Потоковый модуль
Рабочий процесс потоковой обработки можно представить в таком виде:

Сначала нужно импортировать потоковый модуль (это очевидно!).
Чтобы воспроизвести приведённый выше скрипт, используя потоки, потребуется создать несколько потоков. Это можно сделать многократным выполнением простого метода Thread (поток). Вот синтаксис этого метода:
После создания потоков нужно запустить их с помощью метода start:
Давайте сначала возьмём простой пример, создав всего 2 потока, а затем попробуем повторить приведённый выше скрипт:
Согласно рабочему процессу, этот фрагмент кода должен выполняться в течение примерно двух секунд. Теперь посмотрим, что он выведет на экран:

Результат не соответствует нашим ожиданиям. Такое поведение вызвано тем, что после запуска обоих потоков, в то время как потоки спали, наш скрипт работал в многопоточном режиме и продолжил выполнение с остальной частью скрипта. Это тут же привело к подсчёту времени до завершения.
Чтобы этого не допустить, надо задействовать метод join. При вызове метода join вызывающий поток (в нашем случае основной поток) блокируется до тех пор, пока не завершится объект потока (метод please_sleep), на котором он был вызван. Аналогично можно вызвать его в метод start:
Повторим основной скрипт, используя всё то, что мы сейчас делали:
Теперь выводится ожидаемый результат:

Примерно за четыре секунды успешно были выполнены четыре задачи, на которые первоначально уходило около десяти секунд.
Можно ли достигнуть тех же результатов с помощью модуля многопроцессорной обработки? Да, можно. Давайте в этом убедимся.
Поля
| Aborted | 256 |
Состояние потока включает в себя значение , и поток теперь не выполняет работу, но его состояние еще не изменилось на .The thread state includes and the thread is now dead, but its state has not yet changed to . |
| AbortRequested | 128 |
Метод был вызван для потока, но поток еще не получил исключение ThreadAbortException, которое попытается завершить его.The method has been invoked on the thread, but the thread has not yet received the pending ThreadAbortException that will attempt to terminate it. |
| Background | 4 |
Поток выполняется как фоновый поток, в противоположность потокам переднего плана.The thread is being executed as a background thread, as opposed to a foreground thread. Это состояние управляется заданием свойства .This state is controlled by setting the property. |
| Running |
Поток был запущен, но не останавливался.The thread has been started and not yet stopped. |
|
| Stopped | 16 |
Поток был остановлен.The thread has stopped. |
| StopRequested | 1 |
Поток получает запрос на остановку.The thread is being requested to stop. Предназначено только для внутреннего использования.This is for internal use only. |
| Suspended | 64 |
Поток был приостановлен.The thread has been suspended. |
| SuspendRequested | 2 |
Запрашивается приостановка работы потока.The thread is being requested to suspend. |
| Unstarted | 8 |
Метод не был вызван для потока.The method has not been invoked on the thread. |
| WaitSleepJoin | 32 |
Поток заблокирован.The thread is blocked. Это может произойти в результате вызова метода или метода , в результате запроса блокировки, например при вызове метода или или в результате ожидания объекта синхронизации потока, такого как ManualResetEvent.This could be the result of calling or , of requesting a lock — for example, by calling or — or of waiting on a thread synchronization object such as ManualResetEvent. |
Задачи с ограничением скорости вычислений и ввода-вывода
Время выполнения задач, ограниченных скоростью вычислений, полностью зависит от производительности процессора, тогда как в задачах I/O Bound скорость выполнения процесса ограничена скоростью системы ввода-вывода.
В задачах с ограничением скорости вычислений программа расходует большую часть времени на использование центрального процессора, то есть на выполнение вычислений. К таким задачам можно отнести программы, занимающиеся исключительно перемалыванием чисел и проведением расчётов.
В задачах, ограниченных скоростью ввода-вывода, программы обрабатывают большие объёмы данных с диска в сравнении с необходимым объёмом вычислений. К таким задачам можно отнести, например, подсчёт количества строк в файле.