Примеры применения регулярных выражений в python
Содержание:
«Петя любит Дашу».replace(/Дашу|Машу|Сашу/, «Катю») ¶
Не трудно догадаться, что результатом работы js-выражения выше будет текст . Даже, если Петя неровно дышит к Маше или Саше, то результат всё равно не изменится.
Рассмотрим базовые спец. символы, которые можно использовать в шаблонах:
| Символ | Описание | Пример использования | Результат |
|---|---|---|---|
| \ | Символ экранирования или начала мета-символа | /путь\/к\/папке/ | Надёт текст |
| ^ | Признак начала строки | /^Дом/ | Найдёт все строки, которые начинаются на |
| $ | Признак конца строки | /родной$/ | Найдёт все строки, которые заканчиваются на |
| . | Точка означает любой символ, кроме перевода строки | /Петя ..бит Машу/ | Найдёт как , так и |
| | | Означает ИЛИ | /Вася|Петя/ | Найдёт как Васю, так и Петю |
| ? | Означает НОЛЬ или ОДИН раз | /Вжу?х/ | Найдёт и |
| * | Означает НОЛЬ или МНОГО раз | /Вжу*х/ | Найдёт , , , и т.д. |
| + | Означает ОДИН или МНОГО раз | /Вжу+х/ | Найдёт , , и т.д. |
Помимо базовых спец. символов есть мета-символы (или мета-последовательности), которые заменяют группы символов:
| Символ | Описание | Пример использования | Результат |
|---|---|---|---|
| \w | Буква, цифра или _ (подчёркивание) | /^\w+$/ | Соответствует целому слову без пробелов, например |
| \W | НЕ буква, цифра или _ (подчёркивание) | /\W\w+\W/ | Найдёт полное слово, которое обрамлено любыми символами, например |
| \d | Любая цифра | /^\d+$/ | Соответствует целому числу без знака, например |
| \D | Любой символ НЕ цифра | /^\D+$/ | Соответствует любому выражению, где нет цифр, например |
| \s | Пробел или табуляция (кроме перевода строки) | /\s+/ | Найдёт последовательность пробелов от одного и до бесконечности |
| \S | Любой символ, кроме пробела или табуляции | /\s+\S/ | Найдёт последовательность пробелов, после которой есть хотя бы один другой символ |
| \b | Граница слова | /\bдом\b/ | Найдёт только отдельные слова , но проигнорирует |
| \B | НЕ граница слова | /\Bдом\b/ | Найдёт только окночние слов, которые заканчиваются на |
| \R | Любой перевод строки (Unix, Mac, Windows) | /.*\R/ | Найдёт строки, которые заканчиваются переводом строки |
Нужно отметить, что спец. символы \w, \W, \b и \B не работают по умолчанию с юникодом (включая кириллицу). Для их правильной работы нужно указывать модификатор . К сожалению, на окончание 2019 года JavaScript не поддерживает регулярные выражения для юникода даже с модификатором, поэтому в js эти мета-символы работают только для латиницы.
Ещё регулярные выражения поддерживают разные виды скобочек:
| Выражение | Описание | Пример использования | Результат |
|---|---|---|---|
| (…) | Круглые скобки означают под-шаблон, который идёт в результат поиска | /(Петя|Вася|Саша) любит Машу/ | Найдёт всю строку и запишет воздыхателя Маши в результат поиска под номером 1 |
| (?:…) | Круглые скобки с вопросом и двоеточием означают под-шаблон, который НЕ идёт в результат поиска | /(?:Петя|Вася|Саша) любит Машу/ | Найдёт только полную строку, воздыхатель останется инкогнито |
| (?P<name>…) | Задаёт имя под-шаблона | /(?P<воздыхатель>Петя|Вася|Саша) любит Машу/ | Найдёт полную строку, а воздыхателя запишет в результат под индексом 1 и ‘воздыхатель’ |
| Квадратные скобки задают ЛЮБОЙ СИМВОЛ из последовательности (включая спец. символы \w, \d, \s и т.д.) | /^+$/ | Соответствует любому выражению , но не | |
| Если внутри квадратных скобок указать минус, то это считается диапазоном | /+/ | Аналог /\w/ui для JavaScript | |
| Если минус является первым или последним символом диапазона, то это просто минус | /+/ | Найдёт любое целое числое с плюсом или минусом (причём не обязательно, чтобы минус или плюс были спереди) | |
| Квадратные скобки с «крышечекой» означают любой символ НЕ входящий в диапазон | //i | Найдёт любой символ, который не является буквой, числом или пробелом | |
| ] | Квадратные скобки в квадратных скобках задают класс символов (alnum, alpha, ascii, digit, print, space, punct и другие) | /]+/ | Найдёт последовательность непечатаемых символов |
| {n} | Фигурные скобки с одним числом задают точное количество символов | /\w+н{2}\w+/u | Найдёт слово, в котором две буквы н |
| {n,k} | Фигурные скобки с двумя числами задают количество символов от n до k | /\w+н{1,2}\w+/u | Найдёт слово, в котором есть одна или две буквы н |
| {n,} | Фигурные скобки с одним числом и запятой задают количество символов от n до бесконечности | /\w+н{3,}\w+/u | Найдёт слово, в котором н встречается от трёх и более раз подряд |
Text Patterns and Matches
A regular expression, or regex for short, is a pattern describing a certain amount of text. On this website, regular expressions are highlighted in red as regex. This is actually a perfectly valid regex. It is the most basic pattern, simply matching the literal text regex. Matches are highlighted in blue on this site. We use the term “string” to indicate the text that the regular expression is applied to. Strings are highlighted in green.
Characters with special meanings in regular expressions are highlighted in various different colors. The regex (?x)(Rregexp?)\? shows meta tokens in purple, grouping in green, character classes in orange, quantifiers and other special tokens in blue, and escaped characters in gray.
Метасимволы
В регулярных выражениях используются два типа символов: обычные символы и метасимволы. Обычные символы — это те символы, которые имеют «буквальное» значение, а метасимволы — это те символы, которые имеют «особое» значение в регулярном выражении.
Преимуществом регулярных выражений является возможность использовать условия и повторения в шаблоне. Выражения записываются при помощи метасимволов, которые специальным образом интерпретируются. Метасимвол отличается от любого другого символа тем, что имеет специальное значение.
Одним из основных метасимволов является обратный слэш (\), который меняет тип символа, следующего за ним, на противоположный. Таким образом обычный символ можно превратить в метасимвол, а если это был метасимвол, то он теряет свое специальное значение и становится обычным символом. Этот приём нужен для того, чтобы вставлять в текст специальные символы как обычные. Например, символ в обычном режиме не имеет никаких специальных значений, но — это уже метасимвол, который обозначает: «любая цифра». Символ точка в обычном режиме значит — «любой единичный символ», а экранированная точка (\.) означает просто точку.
| Метасимвол | Описание | пример |
|---|---|---|
| . | Соответствует любому одиночному символу, кроме новой строки. | /./ соответствует строке, состоящей из одного символа. |
| ^ | Соответствует началу строки. | /^cars/ соответствует любой строке, которая начинается с cars. |
| $ | Соответствует шаблону в конце строки. | /com$/ соответствует строке, заканчивающейся на com, например gmail.com |
| * | Соответствует 0 или более вхождений. | /com*/ соответствует commute, computer, compromise и т.д. |
| + | Соответствующий предыдущему символу появляется как минимум один раз. | Например, /z+oom/ соответствует zoom. |
| \ | Используется для удаления метасимволов в регулярном выражении. | /google\.com/ будет рассматривать точку как буквальное значение, а не как метасимвол. |
| a-z | Соответствует строчным буквам. | cars |
| A-Z | Соответствует буквам в верхнем регистре. | CARS |
| 0-9 | Соответствует любому числу от 0 до 9. | /0-5/ соответствует 0, 1, 2, 3, 4, 5 |
| Соответствует классу символов. | // соответствует pqr | |
| | | Разделяет перечисление альтернативных вариантов. | /(cat|dog|fish)/ соответствует cat или dog или fish |
| \d | Любая цифра. | /(\d)/ соответствует цифре |
| \s | Найти пробельный символ (в т.ч. табуляция). | /(\s)/ соответствует пробелу |
| \b | Граница слова (начало или конец). | /\bWORD/ найти совпадение в начале слова |
Границы слова
Сопоставитель границ \ b соответствует границе слова, что означает местоположение во входной строке, где слово либо начинается, либо заканчивается:
String text = "Mary had a little lamb";
Pattern pattern = Pattern.compile("\\b");
Matcher matcher = pattern.matcher(text);
while(matcher.find()){
System.out.println("Found match at: " + matcher.start() + " to " + matcher.end());
}
Этот пример соответствует всем границам слов, найденным во входной строке.
Found match at: 0 to 0 Found match at: 4 to 4 Found match at: 5 to 5 Found match at: 8 to 8 Found match at: 9 to 9 Found match at: 10 to 10 Found match at: 11 to 11 Found match at: 17 to 17 Found match at: 18 to 18 Found match at: 22 to 22
В выводе перечислены все места, где слово либо начинается, либо заканчивается во входной строке. Как видите, индексы начала слова указывают на первый символ слова, тогда как окончания слова указывают на первый символ после слова.
String text = "Mary had a little lamb";
Pattern pattern = Pattern.compile("\\bl");
Matcher matcher = pattern.matcher(text);
while(matcher.find()){
System.out.println("Found match at: " + matcher.start() + " to " + matcher.end());
}
В этом примере будут найдены все места, где слово начинается с буквы l (строчные буквы). Фактически он также найдет концы этих совпадений, что означает последний символ шаблона, который является строчной буквой l.
Несловесные границы
String text = "Mary had a little lamb";
Pattern pattern = Pattern.compile("\\B");
Matcher matcher = pattern.matcher(text);
while(matcher.find()){
System.out.println("Found match at: " + matcher.start() + " to " + matcher.end());
}
Found match at: 1 to 1 Found match at: 2 to 2 Found match at: 3 to 3 Found match at: 6 to 6 Found match at: 7 to 7 Found match at: 12 to 12 Found match at: 13 to 13 Found match at: 14 to 14 Found match at: 15 to 15 Found match at: 16 to 16 Found match at: 19 to 19 Found match at: 20 to 20 Found match at: 21 to 21
Строковые методы, поиск и замена
Следующие методы работают с регулярными выражениями из строк.
Все методы, кроме replace, можно вызывать как с объектами типа regexp в аргументах, так и со строками, которые автоматом преобразуются в объекты RegExp.
Так что вызовы эквивалентны:
var i = str.search(/\s/)
var i = str.search("\\s")
При использовании кавычек нужно дублировать \ и нет возможности указать флаги. Если регулярное выражение уже задано строкой, то бывает удобна и полная форма
var regText = "\\s" var i = str.search(new RegExp(regText, "g"))
Возвращает индекс регулярного выражения в строке, или -1.
Если Вы хотите знать, подходит ли строка под регулярное выражение, используйте метод (аналогично RegExp-методы ). Чтобы получить больше информации, используйте более медленный метод (аналогичный методу ).
Этот пример выводит сообщение, в зависимости от того, подходит ли строка под регулярное выражение.
function testinput(re, str){
if (str.search(re) != -1)
midstring = " contains ";
else
midstring = " does not contain ";
document.write (str + midstring + re.source);
}
Если в regexp нет флага , то возвращает тот же результат, что .
Если в regexp есть флаг , то возвращает массив со всеми совпадениями.
Чтобы просто узнать, подходит ли строка под регулярное выражение , используйте .
Если Вы хотите получить первый результат — попробуйте r.
В следующем примере используется, чтобы найти «Chapter», за которой следует 1 или более цифр, а затем цифры, разделенные точкой. В регулярном выражении есть флаг , так что регистр будет игнорироваться.
str = "For more information, see Chapter 3.4.5.1"; re = /chapter (\d+(\.\d)*)/i; found = str.match(re); alert(found);
Скрипт выдаст массив из совпадений:
- Chapter 3.4.5.1 — полностью совпавшая строка
- 3.4.5.1 — первая скобка
- .1 — внутренняя скобка
Следующий пример демонстрирует использование флагов глобального и регистронезависимого поиска с . Будут найдены все буквы от А до Е и от а до е, каждая — в отдельном элементе массива.
var str = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"; var regexp = //gi; var matches = str.match(regexp); document.write(matches); // matches =
Метод replace может заменять вхождения регулярного выражения не только на строку, но и на результат выполнения функции. Его полный синтаксис — такой:
var newString = str.replace(regexp/substr, newSubStr/function)
- Объект RegExp. Его вхождения будут заменены на значение, которое вернет параметр номер 2
- Строка, которая будет заменена на .
- Строка, которая заменяет подстроку из аргумента номер 1.
- Функция, которая может быть вызвана для генерации новой подстроки (чтобы подставить ее вместо подстроки, полученной из аргумента 1).
Метод не меняет строку, на которой вызван, а просто возвращает новую, измененную строку.
Чтобы осуществить глобальную замену, включите в регулярное выражение флаг .
Если первый аргумент — строка, то она не преобразуется в регулярное выражение, так что, например,
var ab = "a b".replace("\\s","..") // = "a b"
Вызов replace оставил строку без изменения, т.к искал не регулярное выражение , а строку «\s».
В строке замены могут быть такие спецсимволы:
| Pattern | Inserts |
| Вставляет «$». | |
| Вставляет найденную подстроку. | |
| Вставляет часть строки, которая предшествует найденному вхождению. | |
| Вставляет часть строки, которая идет после найденного вхождения. | |
| or | Где или — десятичные цифры, вставляет подстроку вхождения, запомненную -й вложенной скобкой, если первый аргумент — объект RegExp. |
Если Вы указываете вторым параметром функцию, то она выполняется при каждом совпадении.
В функции можно динамически генерировать и возвращать строку подстановки.
Первый параметр функции — найденная подстрока. Если первым аргументом является объект , то следующие параметров содержат совпадения из вложенных скобок. Последние два параметра — позиция в строке, на которой произошло совпадение и сама строка.
Например, следующий вызов возвратит XXzzzz — XX , zzzz.
function replacer(str, p1, p2, offset, s)
{
return str + " - " + p1 + " , " + p2;
}
var newString = "XXzzzz".replace(/(X*)(z*)/, replacer)
Как видите, тут две скобки в регулярном выражении, и потому в функции два параметра , .
Если бы были три скобки, то в функцию пришлось бы добавить параметр .
Следующая функция заменяет слова типа на :
function styleHyphenFormat(propertyName)
{
function upperToHyphenLower(match)
{
return '-' + match.toLowerCase();
}
return propertyName.replace(//, upperToHyphenLower);
}
str.replace(str|regexp, str|func)
This is a generic method for searching and replacing, one of most useful ones. The swiss army knife for searching and replacing.
We can use it without regexps, to search and replace a substring:
There’s a pitfall though.
When the first argument of is a string, it only replaces the first match.
You can see that in the example above: only the first is replaced by .
To find all hyphens, we need to use not the string , but a regexp , with the obligatory flag:
The second argument is a replacement string. We can use special characters in it:
| Symbols | Action in the replacement string |
|---|---|
| inserts the whole match | |
| inserts a part of the string before the match | |
| inserts a part of the string after the match | |
| if is a 1-2 digit number, inserts the contents of n-th capturing group, for details see Capturing groups | |
| inserts the contents of the parentheses with the given , for details see Capturing groups | |
| inserts character |
For instance:
For situations that require “smart” replacements, the second argument can be a function.
It will be called for each match, and the returned value will be inserted as a replacement.
The function is called with arguments :
- – the match,
- – contents of capturing groups (if there are any),
- – position of the match,
- – the source string,
- – an object with named groups.
If there are no parentheses in the regexp, then there are only 3 arguments: .
For example, let’s uppercase all matches:
Replace each match by its position in the string:
In the example below there are two parentheses, so the replacement function is called with 5 arguments: the first is the full match, then 2 parentheses, and after it (not used in the example) the match position and the source string:
If there are many groups, it’s convenient to use rest parameters to access them:
Or, if we’re using named groups, then object with them is always the last, so we can obtain it like this:
Using a function gives us the ultimate replacement power, because it gets all the information about the match, has access to outer variables and can do everything.
/Быть или не быть/ugi ¶
Синтаксис регулярных выражений прост и логичен. Он разделяется на символ-разделитель (он идёт в начале и конце выражения, обычно это /), шаблон поиска и необязательные модификаторы.
Формальный синтаксис такой:
Разделителем может быть любой символ, но обычно это или
Важно лишь то, чтобы шаблон начинался и заканчивался одним и тем же разделителем. В самом конце регулярных выражений идут модификаторы, которые нужны, чтобы менять логику работы шаблонов (например делать регистронезависимый поиск)
Давайте разберём выражение :
Данное регулярное выражение будет искать текст не зависимо от регистра по всему тексту неограниченное количество раз. Модификатор нужен для того, чтобы явно указать, что текст у нас в юникоде, то есть содержит символы, отличные от латиницы. Модификатор включает регистронезависимый поиск. Модификатор указывает поисковику идти до победного конца, иначе он остановится после первого удачного совпадения.
Give Regexes a First Try
You can easily try the following yourself in a text editor that supports regular expressions, such as EditPad Pro. If you do not have such an editor, you can download the free evaluation version of EditPad Pro to try this out. EditPad Pro’s regex engine is fully functional in the demo version.

As a quick test, copy and paste the text of this page into EditPad Pro. Then select Search|Multiline Search Panel in the menu. In the search panel that appears near the bottom, type in regex in the box labeled “Search Text”. Mark the “Regular expression” checkbox, and click the Find First button. This is the leftmost button on the search panel. See how EditPad Pro’s regex engine finds the first match. Click the Find Next button, which sits next to the Find First button, to find further matches. When there are no further matches, the Find Next button’s icon flashes briefly.
Now try to search using the regex reg(ular expressions?|ex(p|es)?). This regex finds all names, singular and plural, I have used on this page to say “regex”. If we only had plain text search, we would have needed 5 searches. With regexes, we need just one search. Regexes save you time when using a tool like EditPad Pro. Select Count Matches in the Search menu to see how many times this regular expression can match the file you have open in EditPad Pro.
Основы основ
Для начала нужно понять что в Regex есть специальные символы (например символ начала строки — ), если вы хотите просто найти данный символ, то нужно ввести обратный слеш перед символом для того, чтобы символ не работал как команда.
Для того чтобы найти текст, нужно собственно просто ввести этот текст:
Якори
— символ который обозначает начало строки
— символ который обозначает конец строки
Найдем строки которые начинаются с The Beginning:
Найдем строки, которые заканчиваются на The End:
Найдем строки, которые начинаются и заканчиваются на The Beginning and The End:
Найдем пустые строки:
Квантификаторы
— символ, который указывает на то, что выражение до него должно встретиться 0 или 1 раз
— символ, который указывает на то, что выражение до него должно встретиться один или больше раз
— символ, который указывает на то, что выражение до него должно встретиться 0 или неопределённое количество раз
— скобки с одним аргументом указывают сколько раз выражение до них должно встретиться
— скобки с двумя аргументами указывают на то, от скольки до скольки раз выражение до них должно встретиться
— скобки объединяют какое-то предложение в выражение. Обычно используется в связке с квантификаторами
Давайте попробуем найти текст, в котором будут искаться все слова, содержащие ext или ex:
Давайте попробуем найти текст, в котором слова будут содержать ext или e:
Найти все размеры одежды (XL, XXL, XXXL):
Найти все слова, у которых есть неограниченное число символов c, после которых идёт haracter:
Найти выражение, в котором слово word повторяется от одного до неограниченного количества раз:
Найти выражение, в котором выражение ch повторяется от 3 до неограниченного количества раз:
Выражение «или»
— символ, который обозначает оператор «или»
— выражение в квадратных скобках ставит или между каждым подвыражением
Найти все слова, в которых есть буквы a,e,c,h,p:
Найти все выражения в которых есть ch или pa:
Escape-последовательности
— отмечает один символ, который является цифрой (digit)\
— отмечает символ, который не является цифрой
— отмечает любой символ (число или букву (или подчёркивание)) (word)
— отмечает любой пробельный символ (space character)
— отмечает любой символ (один)
Выражения в квадратных скобках
Кроме того, что квадратные скобки служат оператором «или» между каждым символом, который в них заключён, они также могут служить и для некоторых перечислений:
— один символ от 0 до 9
— любой символ от a до z
— любой символ от A до Z
— любой символ кроме a — z
Найти все выражения, в которых есть английские буквы в нижнем регистре или цифры:
Флаги
Флаги — символы (набор символов), которые отвечают за то, каким именно образом будет происходить поиск.
Форма условия поиска в Regex выглядит вот так:
— флаг, который будет отмечать все выражения, которые соответствуют условиям поиска (по умолчанию поиск возвращает только первое выражение, которое подходит по условию) (global)
— флаг, который заставляет искать выражения вне зависимости от региста (case insensitive)
Теперь вы знаете базовые знания по Regex и можете использовать их в языках программирования, консольных утилитах или в программируемых редакторах (привет, Vim). Если вам интересен данный материал, а также интересны темы веб-разработки и администрирования Unix-подобных систем, то вы можете подписаться на мой телеграм-канал, там много всякого разного и полезного.
What Regular Expressions Are Exactly — Terminology
Basically, a regular expression is a pattern describing a certain amount of text. Their name comes from the mathematical theory on which they are based. But we will not dig into that. You will usually find the name abbreviated to «regex» or «regexp». This tutorial uses «regex», because it is easy to pronounce the plural «regexes». On this website, regular expressions are highlighted in red as regex.
This first example is actually a perfectly valid regex. It is the most basic pattern, simply matching the literal text regex. A “match” is the piece of text, or sequence of bytes or characters that pattern was found to correspond to by the regex processing software. Matches are highlighted in blue on this site.
Пять способов протестировать свои знания о регулярных выражениях
При изучении регулярных выражений очень важна практика. Чем больше практикуешься, тем быстрее начинаешь строить нужные конструкции и решать поставленные задачи.
1. Изучаем регулярные выражения в текстовом редакторе
Почти всем новичкам я сразу рекомендую ставить текстовый редактор NotePad++ и начинать тренироваться в нём. Почему именно в этом текстовом редакторе:
- в большинстве случаев спецсимволы не нужно экранировать;
- Notepad++ сохраняет конструкции предыдущих запросов;
- функция «Пометки» наглядно показывает результат поиска по заданной конструкции и позволяет быстро внести правки:

2. Проверяем знания регулярных выражений в Regex
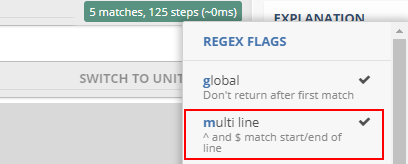
Онлайн-сервис regex101.com позволяет ввести набор данных и регулярное выражение. После этого в наборе данных подсветятся строки, соответствующие выражению. В специальном окне Explanation регулярное выражение разбирается по частям:

Давайте потренируемся: задача — подсветить всю строку полностью. Нужно поставить галочку напротив «multi line».
Тестовые данные:
Регулярные выражения для проверки знаний:
- выбрать все страницы;
(.*) — любое количество любых символов;
- выбрать все страницы с https;
^https.* — все URL, начинающиеся с https;
- все страницы на украинском языке;
.*/ua/.* — все страницы, в URL которых содержится /ua/. Если использовать просто ua, в выборку попадет http://www.site.com/duals/index.html, это лишнее;
- все индексные страницы;
.*index\.(php|html) — аналогично прошлому выражению, нельзя просто использовать index;
- все карточки товаров (для русской и украинской версий);
.*product(s|y).* или .*product.* — оба варианта подходят.
3. Тестируем регулярные выражения с помощью Jsfiddle
Jsfiddle — инструмент для экспериментов с JavaScript. В нем можно проверить условия для запуска функции или демонстрации нужных результатов.
В этом примере видно, как на основании регулярных выражений сначала определяется, является ли нажатый элемент ссылкой на файл .pdf или .jpg. После этого для элементов, которые не являются ссылками на файлы, определяются название и цена товара. Все это выясняется, исходя из текстового содержимого элементов.
4. Проверяем ошибки в регулярных выражениях с помощью Google Analytics
Самый быстрый способ проверить знания о регулярных выражениях в Google Analytics — фильтры в стандартных отчетах. Зайдите в свой аккаунт и в любом отчете, где доступны фильтры, попробуйте отобрать какой-либо набор данных.
Символьные классы — \d \w \s и .
\d соответствует одному символу, который является цифрой -> тест\w соответствует слову (может состоять из букв, цифр и подчёркивания) -> тест\s соответствует символу пробела (включая табуляцию и прерывание строки). соответствует любому символу -> тест
Используйте оператор с осторожностью, так как зачастую класс или отрицаемый класс символов (который мы рассмотрим далее) быстрее и точнее. У операторов , и также есть отрицания ― исоответственно
У операторов , и также есть отрицания ― исоответственно.
Например, оператор будет искать соответствия противоположенные .
\D соответствует одному символу, который не является цифрой -> тест
Некоторые символы, например , необходимо выделять обратным слешем .
\$\d соответствует строке, в которой после символа $ следует одна цифра -> тест
Непечатаемые символы также можно искать, например табуляцию , новую строку , возврат каретки .
Методы класса PatternSyntaxException
PatternSyntaxException — это непроверенное исключение, которое указывает на синтаксическую ошибку в шаблоне. Класс PatternSyntaxException предоставляет следующие методы, чтобы помочь вам определить, что пошло не так:
| № | метод и описание |
|---|---|
| 1 | public String getDescription()
Получает описание ошибки. |
| 2 | public int getIndex()
Получает индекс ошибки. |
| 3 | public String getPattern()
Извлекает ошибочный шаблон регулярного выражения. |
| 4 | public String getMessage()
Возвращает многострочную строку, содержащую описание синтаксической ошибки и ее индекс, ошибочный шаблон регулярного выражения и визуальную индикацию индекса ошибки в шаблоне. |
Примеры
Напишите регулярное выражение, которое соответствует любому номеру телефона.
Телефонный номер в этом примере состоит либо из 7 номеров подряд, либо из 3 номеров, пробела или тире, а затем из 4 номеров.
package regex.phonenumber;
import org.junit.Test;
import static org.junit.Assert.assertFalse;
import static org.junit.Assert.assertTrue;
public class CheckPhone {
@Test
public void testSimpleTrue() {
String pattern = "\\d\\d\\d()?\\d\\d\\d\\d";
String s= "1233323322";
assertFalse(s.matches(pattern));
s = "1233323";
assertTrue(s.matches(pattern));
s = "123 3323";
assertTrue(s.matches(pattern));
}
}
В следующем примере проверяется, содержит ли текст число из 3 цифр.
package regex.numbermatch;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.junit.Test;
import static org.junit.Assert.assertFalse;
import static org.junit.Assert.assertTrue;
public class CheckNumber {
@Test
public void testSimpleTrue() {
String s= "1233";
assertTrue(test(s));
s= "0";
assertFalse(test(s));
s = "29 Kasdkf 2300 Kdsdf";
assertTrue(test(s));
s = "99900234";
assertTrue(test(s));
}
public static boolean test (String s){
Pattern pattern = Pattern.compile("\\d{3}");
Matcher matcher = pattern.matcher(s);
if (matcher.find()){
return true;
}
return false;
}
}
В следующем примере показано как извлечь все действительные ссылки с веб-страницы. Не учитывает ссылки, начинающиеся с «javascript:» или «mailto:».
package regex.weblinks;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class LinkGetter {
private Pattern htmltag;
private Pattern link;
public LinkGetter() {
htmltag = Pattern.compile("<a\\b*href=\"*>(.*?)");
link = Pattern.compile("href=\"*\">");
}
public List getLinks(String url) {
List links = new ArrayList();
try {
BufferedReader bufferedReader = new BufferedReader(
new InputStreamReader(new URL(url).openStream()));
String s;
StringBuilder builder = new StringBuilder();
while ((s = bufferedReader.readLine()) != null) {
builder.append(s);
}
Matcher tagmatch = htmltag.matcher(builder.toString());
while (tagmatch.find()) {
Matcher matcher = link.matcher(tagmatch.group());
matcher.find();
String link = matcher.group().replaceFirst("href=\"", "")
.replaceFirst("\">", "")
.replaceFirst("\"?target=\"*", "");
if (valid(link)) {
links.add(makeAbsolute(url, link));
}
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return links;
}
private boolean valid(String s) {
if (s.matches("javascript:.*|mailto:.*")) {
return false;
}
return true;
}
private String makeAbsolute(String url, String link) {
if (link.matches("http://.*")) {
return link;
}
if (link.matches("/.*") && url.matches(".*$")) {
return url + "/" + link;
}
if (link.matches(".*") && url.matches(".*")) {
return url + "/" + link;
}
if (link.matches("/.*") && url.matches(".*[/]")) {
return url + link;
}
if (link.matches("/.*") && url.matches(".*")) {
return url + link;
}
throw new RuntimeException("Cannot make the link absolute. Url: " + url
+ " Link " + link);
}
}
Поиск дублированных слов. \b является границей слова и \1 ссылается на совпадение первой группы, то есть первого слова. (?!-in)\b(\w+) \1\b находит повторяющиеся слова, если они не начинаются с «-in». Добавьте (?S) для поиска по нескольким строкам.
Поиск элементов, которые начинаются с новой строки.
Также можете посмотреть официальную документацию тут.
Оцени статью
Оценить
Средняя оценка / 5. Количество голосов:
Видим, что вы не нашли ответ на свой вопрос.
Помогите улучшить статью.
Спасибо за ваши отзыв!
Inline Modifiers
(?s)(?m)
| Modifier | Legend | Example | Sample Match |
|---|---|---|---|
| (?i) |
(except JavaScript) |
(?i)Monday | monDAY |
| (?s) | (except JS and Ruby). The dot (.) matches new line characters (\r\n). Also known as «single-line mode» because the dot treats the entire input as a single line | (?s)From A.*to Z | From Ato Z |
| (?m) |
(except Ruby and JS) ^ and $ match at the beginning and end of every line |
(?m)1\r\n^2$\r\n^3$ | 123 |
| (?m) | : the same as (?s) in other engines, i.e. DOTALL mode, i.e. dot matches line breaks | (?m)From A.*to Z | From Ato Z |
| (?x) |
(except JavaScript). Also known as comment mode or whitespace mode |
(?x) # this is a# commentabc # write on multiple# linesd # spaces must be# in brackets | abc d |
| (?n) | Turns all (parentheses) into non-capture groups. To capture, use . | ||
| (?d) | The dot and the ^ and $ anchors are only affected by \n | ||
| (?^) | Unsets ismnx modifiers |