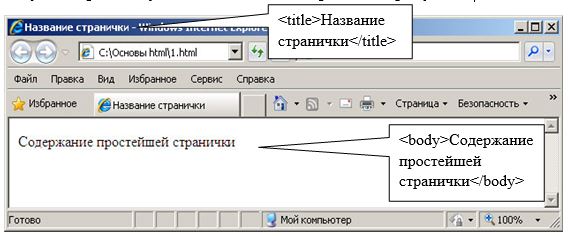
Как создать файл robots.txt для wordpress. 4 способа
Содержание:
Проверка файла robots txt
После закачки файла robots txt, нужно проверить его наличие и работу. Для этого можем посмотреть файл с браузера, как показано выше в разделе «Где находится robots txt, как увидеть». А проверить работу файла можно с помощью Яндекс вебмастера и Google webmaster. Помним, что для этого должны быть подтверждены права на управление сайтом, как в Яндексе, так и в Google.
Для проверки в Яндексе заходим в наш аккаунт Яндекс вебмастера, выбираем сайт, если у Вас их несколько. Выбираем «Настройка индексирования», «Анализ robots.txt», а дальше следуем инструкциям.

В Google вебмастер делаем аналогично, заходим в наш аккаунт, выбираем нужный сайт (если их несколько), нажимаем кнопку «Сканирование» и выбираем «Инструмент проверки файла robots.txt». Откроется файл robots txt, Вы можете его исправить или проверить.

На этой же странице находятся отличные инструкции по работе с файлом robots txt, можете с ними ознакомиться. В заключении привожу видео, где показано что представляет собой файл robots txt, как его найти, как его посмотреть и скачать, как работать с генератором файла, как составить robots txt и адаптировать под себя, показана другая информация:
Блоки в robots.txt
Директива Disallow в robots.txt может использоваться по-разному для многих агентов. Покажем, каким образом могут быть представлены разные комбинации блоков.
Важно помнить, что robots.txt — это всего-навсего набор рекомендаций. Вредоносные краулеры проигнорируют этот файл, прочитав то, что захотят, поэтому бессмысленно использовать robots.txt в качестве меры защиты
Несколько блоков User-Agent
Вы можете назначить правило сразу нескольким роботам, указав их в начале. Например, следующая директива Disallow будет работать как для Яндекса, так и для Google.
Пустые строки между блоками
Поисковые системы игнорируют пустые строки между директивами. Даже если одна директива будет отделена таким образом от предыдущей, робот всё равно её прочитает.
В следующем примере сразу два робота будут руководствоваться одним правилом.
Комбинация отдельных блоков
Разные блоки, в которых указан один и тот же агент, будут учитываться. Таким образом, Google не станет читать оба раздела, указанных в файле.
Робот-курьер от «Яндекса» тестируется на улицах
«Яндекс» начал тестировать беспилотную доставку из кафе и ресторанов в Москве и Иннополисе. Заказы блюд, оформленные клиентом через приложение «Яндекс.еда», привозит робот-доставщик «Яндекс.ровер». Об этом представители «Яндекса» сообщили CNews.
«Яндекс» полагает, что в будущем робот возьмет на себя часть заказов, которые сейчас развозят курьеры.
«Яндекс.ровер» — полуметровый робот-курьер для перевозки небольших грузов. Робот вмещает в себя до 20 кг. Компания начала его разработку летом 2019 г., а затем тестировала робота в своей штаб-квартире. Робот полностью автономен: сам планирует свой маршрут, оценивает ситуацию вокруг, объезжает препятствия и пропускает пешеходов и животных. Он способен ездить по городским тротуарам со скоростью около 5 км/ч, может работать и летом, и зимой, выполняя заказы в разных погодных условиях.
На местности дрон ориентируется при помощи комплекта камер и датчиков и размещенного на его «крыше» лидара. За счет его «ровер» может обходить препятствия, притом даже в темноте.
Как сообщили CNews в пресс-службе «Яндекса», во время движения робот определяет свое местоположение, идентифицирует и классифицирует объекты вокруг, прогнозирует, как будут действовать эти объекты в следующие несколько секунд, и планирует свои действия: «Робот может преодолевать невысокие бордюры и искусственные неровности дороги. Мы также тестируем сейчас новые конструкции шасси, которые позволят ему справляться с более сложным рельефом».
Для того чтобы выбрать доставку роботом, нужно оформить заказ в приложении «Яндекс.еда», причем дополнительно доплачивать за вызов именно робота не нужно. «Ровер» заберет заказ из ресторана и привезёт к указанному подъезду. В приложении можно посмотреть статус заказа и местоположение «ровера». Для получения заказа получателю достаточно с помощью своего смартфона открыть крышку грузового отсека робота. Пока число роботов ограничено, если свободного робота не окажется, заказ привезёт курьер — они продолжат доставлять еду в этом районе.
 Робот-доставщик «Яндекс.Ровер»
Робот-доставщик «Яндекс.Ровер»
В Москве компания тестирует необычного курьера в районе делового квартала «Белая площадь» у метро «Белорусская». Там расположены крупные офисы российских и иностранных компаний, а также кафе и рестораны. «Ровер» возит заказы из ресторанов и кафе «Марукамэ», Steak it Easy, Boston Seafood & Bar, Prime, Paul и Cheese Connection. С подключением новых точек общественного питания зона беспилотной доставки будет расширяться.
Еще одно место обитания роботов-доставщиков — Иннополис под Казанью. Жители могут сделать заказ в ресторане и выбрать беспилотную доставку в приложении «Яндекс.еда» или в городском Telegram-боте. В дальнейшем, как планируют разработчики, они будут подключаться к другим задачам и помогать жителям с повседневными делами.
В ответ на вопрос CNews, как компания уберегает роботов от вандалов, представители «Яндекса» ответили, что местоположение каждого из роботов известно в компании, плюс, сам «ровер» может подать сигнал оператору, «если поймет, что что-то идет не так».
В Москве количество роботов может варьироваться в зависимости от динамики заказов в районе. В Иннополисе сейчас работает пять роботов, и в ближайшее время к ним присоединятся еще роботы для новых сценариев доставки, уточнили в пресс-службе.
Директивы robots.txt
Директивы robots.txt помогают снизить затраты ресурсов на краулинг. Вы упредительно добавляете правила в robots.txt вместо того, чтобы ждать, пока поисковые системы считают все страницы, а затем предпринимать меры. Такой подход гораздо быстрее и проще.
Следующие директивы работают аналогично Allow и Disallow, используя символы * и .
Noindex
Директива Noindex полезна для повышения точности индексирования. Disallow никак не избавляет от необходимости индексации указанную страницу, в то время как Noindex позволяет убрать страницу из индекса.
Но тот же Google официально не поддерживает директиву Noindex — ситуация может измениться со дня на день. В подобной неопределённости лучше использовать данный инструмент для решения краткосрочных задач, как дополнительную меру, но не основное решение.
Помимо Noindex Google негласно поддерживает и ряд других директив, размещаемых в robots.txt
Важно помнить, что не все краулеры поддерживают эти директивы, и однажды они могут перестать работать. Не стоит на них полагаться
Как создать файл robots txt: подробная инструкция
Для создания такого файла можете использовать фактически любой редактор текста, например:
- Notepad;
- Блокнот;
- Sublime и др.
В этом «документе» описывается инструкция User-agent, а также указывается правило Disallow, но есть и прочие, не такие важные, но необходимые правила/инструкции для поисковых роботов.
User-agent: кому можно, а кому нет
Наиболее важная часть «документа» — User-agent. В ней указывается, каким именно поисковым роботам следует «посмотреть» инструкцию, описанную в самом файле.
В настоящее время существует 302 робота. Чтобы в документе не прописывать каждого отдельного робота персонально, необходимо указать в файле запись:
User-agent: *

Такая пометка указывает на то, что правила в файле ориентированы на всех поисковых роботов.
У поисковой системы Google основной поисковый робот Googlebot. Чтобы правила были рассчитаны только на него, необходимо в файле прописать:
User-agent: Googlebot_

При наличии такой записи в файле прочие поисковые роботы будут оценивать материалы сайта по своим основным директивам, предусматривающим обработку пустого robots.txt.
У Яндекс основной поисковый робот Yandex и для него запись в файле будет выглядеть следующим образом:
User-agent: Yandex

При наличии такой записи в файле прочие поисковые роботы будут оценивать материалы сайта по своим основным директивам, предусматривающим обработку пустого robots.txt.
Прочие специальные поисковые роботы
- Googlebot-News — используется для сканирования новостных записей;
- Mediapartners-Google — специально разработан для сервиса Google AdSense;
- AdsBot-Google — оценивает общее качество конкретной целевой страницы;
- YandexImages — проводит индексацию картинок Яндекс;
- Googlebot-Image — для сканирования изображений;
- YandexMetrika — робот сервиса Яндекс Метрика;
- YandexMedia — робот, индексирующий мультимедиа;
- YaDirectFetcher — робот Яндекс Директ;
- Googlebot-Video — для индексирования видео;
- Googlebot-Mobile — создан специально для мобильной версии сайтов;
- YandexDirectDyn — робот генерации динамических баннеров;
- YandexBlogs — робот поиск по блогам, он проводит сканирование не только постов, но даже комментарие;
- YandexDirect — разработан для того, чтобы анализировать наполнение партнерский сайтов Рекламной сети. Это позволяет определить тематику каждого сайта и более эффективно подбирать релевантную рекламу;
- YandexPagechecker — валидатор микроразметки.
Перечислять прочих роботов не будем, но их, повторимся, всего насчитывается более 300-т. Каждый из них ориентирован на те или иные параметры.
Синтаксис robots.txt
Как настроить robots.txt? Примерно так может выглядеть блок robots.txt, ориентированный на Google.

Комментарии
Комментарии — это строки, которые полностью игнорируются поисковыми системами. Они начинаются со знака #. Они нужны для заметок о том, какие действия выполняют строки файла. Рекомендуется документировать каждую директиву в robots.txt, чтобы она могла быть удалена за ненадобностью или отредактирована.
Указания User-agent
Это блок, который даёт указания поисковым системам и роботам, используя директиву User-agent. Например, если вы хотите установить правила отдельно для Яндекса и Google. Тем не менее, он не применим для Facebook и рекламный сетей — на них можно повлиять только через специальный токен с применением особых правил.
Каждый робот предусматривает собственный user-agent токен.
Краулеры сперва учитывают наиболее точные директивы, разделённые дефисом, а затем переходят к объемлющим. Так, Googlebot News сначала выполнит указания для User-agent «googlebot-news», а потом уже «googlebot» и впоследствии «*».
Наиболее распространённые роботы в российском сегменте — это:
Конечно, этот список далеко не исчерпывающий. Чтобы ознакомиться с полным перечнем используемых поисковиками и другими системами роботов, лучше прочитайте их документацию.
Наименования роботов в robots.txt нечувствительны к регистру. «Googlebot» и «googlebot» вполне взаимозаменяемы.
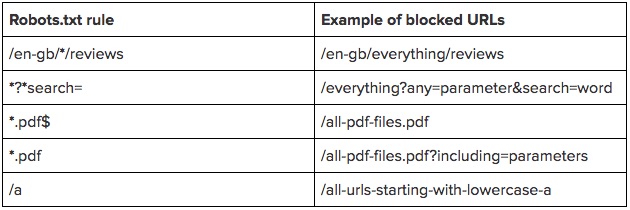
Шаблоны адресов
Вместо того, чтобы прописывать большой перечень конечных URL для блокировки, достаточно указать только шаблоны адресов.
Для эффективного использования такой функции понадобится два знака:
* — данный символ группировки обозначает любое количество символов. Его лучше располагать в начале или внутри адреса, но не в конце. Можно использовать сразу несколько групповых символов — например, «Disallow: */notebooks?*filter=». Правила с полными адресами не должны начинаться с данного символа.
$ — знак доллара означает конец адреса. Так, «Disallow: */item$» будет соответствовать URL, заканчивающемуся на «/item», но не «/item?filter» или подобным.
Обратите внимание, что эти правила уже чувствительны к регистру. Если вы запрещаете адреса с параметром «search», роботы всё ещё будут просматривать адреса, содержащие «Search»
Директивы работают только с телом адреса и не включают протокол или сам домен. Слэш в начале адреса означает, что данная директория располагается сразу после основного каталога. Например, «Disallow: /start» будет соответствовать «www.site.ru/start
Пока вы не добавите * или в начало директивы, она не будет ничему соответствовать. «Disallow: start» не будет иметь смысла — роботы её не поймут.
Чтобы наглядно продемонстрировать правило, приведём таблицу примеров:
Sitemap.xml
Директива Sitemap в robots.txt говорит поисковикам, где найти карту сайта в формате XML. Это поможет им лучше ориентироваться в структуре страниц.
Для Sitemap вы должны указать полный путь, как это сделано у нас: «Sitemap: https://www.calltouch.ru/sitemap.xml». Также следует отметить, что Sitemap не всегда располагается на том же домене, что и весь сайт.
Поисковые роботы прочитают указанные в robots.txt карты сайтов, но они не появятся в том же Google Search Console, пока вы не дадите на это разрешение.
Host
Этот элемент раньше работал исключительно как инструкция для Яндекса, другим поисковым системам она была непонятна. Он указывал роботу Яндекса на главное зеркало сайта, и система рассматривала его в приоритетном порядке.
Директива Host уже не поддерживается Яндексом, решение об этом было принято еще в 2018 году. Теперь вместо нее схожий функционал выполняет раздел «Переезд сайта», доступный в Яндекс.Вебмастере.
Для чего нужна проверка robots.txt
Иногда в результаты поиска система включает ненужные страницы вашего Интернет-ресурса, в чем нет необходимости. Может показаться, что ничего плохого в большом количестве страниц в индексе поисковой системы нет, но это не так:
- На лишних страницах пользователь не найдет никакой полезной информации для себя. С большей долей вероятности он и вовсе не посетит эти страницы либо задержится на них недолго;
- В выдаче поисковика присутствуют одни и те же страницы, адреса которых различны (то есть контент дублируется);
- Поисковым роботам приходится тратить много времени, чтобы проиндексировать совершенно ненужные страницы. Вместо индексации полезного контента они будут бесполезно блуждать по сайту. Поскольку индексировать полностью весь ресурс робот не может и делает это постранично (так как сайтов очень много), то нужная информация, которую вы бы хотели получить после ведения запроса, возможно, будет найдена не очень быстро;
- Очень сильно нагружается сервер.
В связи с этим является целесообразным закрытие доступа поисковым роботам к некоторым страницам веб-ресурсов.
Какие же файлы и папки можно запретить индексировать:
- Страницы поиска. Это спорный пункт. Иногда использование внутреннего поиска на сайте необходимо, для того чтобы создать релевантные страницы. Но делается это не всегда. Зачастую результатом поиска становится появление большого количества дублированных страниц. Поэтому рекомендуется закрыть страницы поиска для индексации.
- Корзина и страница, на которой оформляют/подтверждают заказ. Их закрытие рекомендовано для сайтов онлайн-торговли и других коммерческих ресурсов, использующих форму заказа. Попадание этих страниц в индекс поисковых систем крайне нежелательно.
- Страницы пагинации. Как правило, для них характерно автоматическое прописывание одинаковых мета-тегов. Кроме того, их используют для размещения динамического контента, поэтому в результатах выдачи появляются дубли. В связи с этим пагинация должна быть закрыта для индексации.
- Фильтры и сравнение товаров. Закрывать их нужно онлайн-магазинам и сайтам-каталогам.
- Страницы регистрации и авторизации. Закрывать их нужно в связи с конфиденциальностью вводимых пользователями при регистрации или авторизации данных. Недоступность этих страниц для индексации будет оценена Гуглом.
- Системные каталоги и файлы. Каждый ресурс в Интернете состоит из множества данных (скриптов, таблиц CSS, административной части), которые не должны просматриваться роботами.
Закрыть файлы и страницы для индексации поможет файл robots.txt.
Рекомендуемые статьи по данной теме:
- Проверка тИЦ сайта: 3 способа
- Внутренняя оптимизация сайта: пошаговый разбор
- Файл htaccess: применение, включение, настройка
robots.txt – это обычный текстовый файл, содержащий инструкции для поисковых роботов. Когда поисковый робот оказывается на сайте, то в первую очередь занимается поиском файла robots.txt. Если же он отсутствует (или пустой), то робот будет заходить на все страницы и каталоги ресурса (в том числе и системные), находящиеся в свободном доступе, и пытаться провести их индексацию. При этом нет гарантии, что будет проиндексирована нужная вам страница, поскольку он может и не попасть на нее.
robots.txt позволяет направлять поисковые роботы на нужные страницы и не пускать на те, которые индексировать не следует. Файл может инструктировать как всех роботов сразу, так и каждого в отдельности. Если страницу сайта закрыть от индексации, то она никогда не появится в выдаче поисковой системы. Создание файла robots.txt является крайне необходимым.
Местом нахождения файла robots.txt должен быть сервер, корень вашего ресурса. Файл robots.txt любого сайта доступен для просмотра в Сети. Чтобы увидеть его, нужно после адреса ресурса добавить /robots.txt.
Как правило, файлы robots.txt различных ресурсов отличаются друг от друга. Если бездумно скопировать файл чужого сайта, то при индексации вашего поисковыми роботами возникнут проблемы. Поэтому так необходимо знать, для чего нужен файл robots.txt и инструкции (директивы), используемые при его создании.
Оставить заявку
Вас также может заинтересовать: Что делать, если упала посещаемость сайта
Как редактировать и загружать robots.txt
Есть несколько способов создать файл robots.txt — либо сделать его вручную в текстовом редакторе и разместить в корневом каталоге (папка самого верхнего уровня на сервере), либо воспользоваться специальными плагинами для настройки файла.
Как создать robots.txt в Блокноте
Самый простой способ создать файл robots.txt — написать его в блокноте и загрузить на сервер в корневой каталог.
Лучше не использовать стандартное приложение — воспользуйтесь специальными редакторы текста, например, Notepad++ или Sublime Text, которые поддерживают сохранение файла в конкретной кодировке. Дело в том, что поисковые роботы, например, Яндекс и Google, читают только файлы в UTF-8 с определенными переносами строк — стандартный Блокнот Windows может добавлять ненужные символы или использовать неподдерживаемые переносы.
Говорят, что это давно не так, но чтобы быть уверенным на 100%, используйте специализированные приложения.
Рассмотрим создание robots.txt на примере Sublime Text. Откройте редактор и создайте новый файл. Внесите туда нужные настройки, например:
Где mysite.ru — домен вашего сайта.
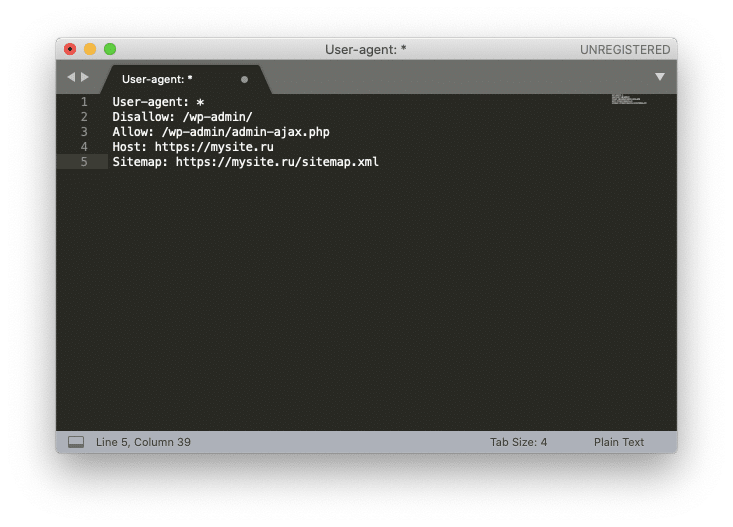
После того, как вы записали настройки, выберите в меню File ⟶ Save with Encoding… ⟶ UTF-8 (или Файл ⟶ Сохранить с кодировкой… ⟶ UTF-8).
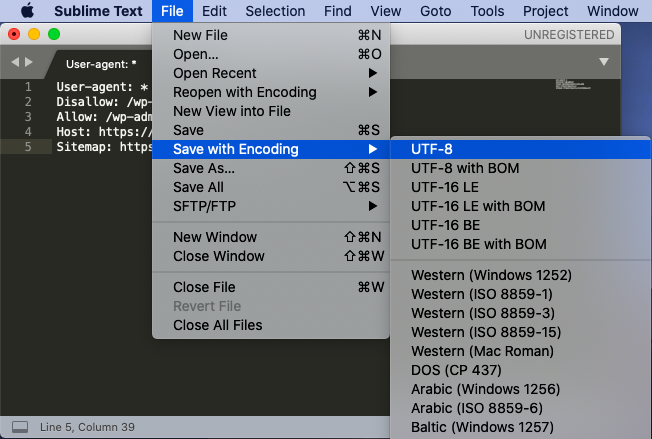
Назовите файл “robots.txt” (обязательно с маленькой буквы).
Файл готов к загрузке.
Загрузить robots.txt через FTP
Для того, чтобы загрузить созданный robots.txt на сервер через FTP, нужно для начала включить доступ через FTP в настройках хостинга.

После этого скопируйте настройки доступа по FTP: сервер, порт, IP-адрес, логин и пароль (не совпадают с логином и паролем для доступа на хостинг, будьте внимательны!).
Чтобы загрузить файл robots.txt вы можете воспользоваться специальным файловым менеджером, например, FileZilla или WinSCP, или же сделать это просто в стандартном Проводнике Windows. Введите в поле поиска “ftp://адрес_FTP_сервера”.

После этого Проводник попросит вас ввести логин и пароль.

Введите данные, которые вы получили от хостинг-провайдера на странице настроек доступа FTP. После этого в Проводнике откроются файлы и папки, расположенные на сервере. Скопируйте файл robots.txt в корневую папку. Готово.
Загрузить или создать robots.txt на хостинге
Если у вас уже есть готовый файл robots.txt, вы можете просто загрузить его на хостинг. Зайдите в файловый менеджер панели управления вашим хостингом, нажмите на кнопку «Загрузить» и следуйте инструкциям (подробности можно узнать в поддержке у вашего хостера.

Многие хостинги позволяют создавать текстовые файлы прямо в панели управления хостингом. Для этого нажмите на кнопку «Создать файл» и назовите его “robots.txt” (с маленькой буквы).

После этого откройте его во встроенном текстовом редакторе хостера. Если вам предложит выбрать кодировку для открытия файла — выбирайте UTF-8.

Добавьте нужные директивы и сохраните изменения.

Настройка директивов robots.txt
Директивы — это правила для роботов. И эти правила пишем мы.
User-agent
Главное правило называется User-agent. В нем мы создаем кодовое слово для роботов. Если робот видит такое слово, он понимает, что это правило для него.
Пример:
User-agent: Yandex
Данное правило смогут понять только те роботы, которые работают в Яндексе. В последнее время эту строчку я заполняю так:
User-agent: *
Правило понимает Яндекс и Гугл. Доля трафика с других поисковиков очень мала, и продвигаться в них не стоит затраченных усилий.
Disallow и Allow
С помощью Disallow мы скрываем каталоги от индексации, а, прописывая правило с директивой Allow, даем разрешение на индексацию.
Пример:
Allow: /category/
Даем рекомендацию, чтобы индексировались категории.
Disallow: /
А вот так от индексации будет закрыт весь сайт.
Также существуют операторы, которые помогают уточнить наши правила.
- * – звездочка означает любую последовательность символов (либо отсутствие символов).
- $ – знак доллара является своеобразной точкой, которая прерывает последовательность символов.
Disallow: /category/$ # закрываем только страницу категорий Disallow: /category/* # закрываем все страницы в папке категории
Sitemap
Данная директива нужна для того, чтобы сориентировать робота, если он заплутает. Мы показываем роботу дорогу к Sitemap.
Пример:
Sitemap: http://site.ru/sitemap.xml
Директива host уже устарела, поэтому о ней говорить не будем.
Crawl-delay
Если сайт небольшой, то директиву Crawl-delay заполнять нет необходимости. Эта директива нужна, чтобы задать периодичность скачивания документов с сайта.
Пример:
Crawl-delay: 10
Это правило означает, что документы с сайта будут скачиваться с интервалом в 10 секунд.
Clean-param
Директива Clean-param закрывает от индексации дубли страниц с разными адресами. Например, если вы продвигаетесь через контекстную рекламу, на сайте будут появляться страницы с utm-метками. Чтобы подобные страницы не плодили дубли, мы можем закрыть их с помощью данной директивы.
Пример:
Clean-Param: utm_source&utm_medium&utm_campaign
Настройка
Для грамотной настройки файла роботов нам нужно точно знать, какие из разделов сайта должны быть проиндексированы, а какие – нет. В случае с простым одностраничником на html + css нам достаточно прописать несколько основных директив, таких как:
User-agent: *
Allow: /
Sitemap: site.ru/sitemap.xml
Host: www.site.ru
Здесь мы указали правила и значения для всех поисковых систем. Но лучше добавить отдельные директивы для Гугла и Яндекса. Выглядеть это будет так:
User-agent: *
Allow: /
User-agent: Yandex
Allow: /
Disallow: /politika
User-agent: GoogleBot
Allow: /
Disallow: /tags/
Sitemap: site.ru/sitemap.xml
Host: site.ru
Теперь на нашем html-сайте будут индексироваться абсолютно все файлы. Если мы хотим исключить какую-то страницу или картинку, то нам необходимо указать относительную ссылку на этот фрагмент в Disallow.
Вы можете использовать сервисы автоматической генерации файлов роботс. Не гарантирую, что с их помощью вы создадите идеально правильный вариант, но в качестве ознакомления можно попробовать.
Среди таких сервисов можно выделить:
- PR-CY,
- htmlweb.
С их помощью вы сможете создать robots.txt в автоматическом режиме. Лично я крайне не рекомендую этот вариант, потому как намного проще сделать это вручную, настроив под свою платформу.
Говоря о платформах, я имею ввиду всевозможные CMS, фреймворки, SaaS-системы и многое другое. Далее мы поговорим о том, как настраивать файл роботов WordPress и Joomla.
Но перед этим выделим несколько универсальных правил, которыми можно будет руководствоваться при создании и настройке роботс почти для любого сайта:
Закрываем от индексирования (Disallow):
Открываем (Allow):
- картинки;
- JS и CSS-файлы;
- прочие элементы, которые должны учитываться поисковыми системами.
Помимо этого, в конце не забываем указать данные sitemap (путь к карте сайта) и host (главное зеркало).
Для чего нужен robots.txt?
Увеличение скорости обработки ресурса. Опираясь на изложенные рекомендации, поисковой бот работает с требуемыми для вас страницами, а не со всеми подряд
Соответственно, вам удаётся обратить его внимание на первоочередную информацию.
Повышение скорости индексации. В связи с тем, что за 1 визит робот обрабатывает определённое количество веб-страниц, возникает необходимость в быстрой индексации, особенно нового контента.
Так вы сможете защитить контент от кражи и проследить, как он повлиял на позиции сайта в поисковой выдаче.
Уменьшение нагрузки на сайт
Нежелательно, чтобы робот постоянно скачивал большой объём информации, потому что из-за этого работа ресурса может существенно замедлиться.
Сокрытие «поискового мусора». В файле прописываются не рекомендованные для обработки страницы — сайты-зеркала, панель администратора и тому подобное.
Заключение
Итак, в данной статье мы рассмотрели вопрос, что собой представляет файл robots txt, выяснили, что этот файл является очень важным для сайта. Узнали, как сделать правильный robots txt, как адаптировать файл robots txt с чужого сайта к себе, как закачать его на свой блог, как его проверить.
Из статьи стало понятно, что новичкам, на первых порах, лучше использовать готовый и правильный robots txt, но надо не забыть заменить в нем в директории Host домен на свой, а также прописать адрес своего блога в картах сайта. Скачать мой файл robots txt можно здесь. Теперь, после исправления, можете использовать файл на своем блоге.
Отдельно по файлу robots txt есть сайт Вы можете зайти на него и узнать более подробную информацию. Надеюсь, у Вас всё получится и блог будет хорошо индексироваться. Удачи Вам!
P.S. Для правильного продвижения блога надо правильно писать о оптимизировать статьи на блоге, тогда на нём будет высокая посещаемость и рейтинги. В этом Вам помогут мои инфопродукты, в которые вложен мой трёхлетний опыт. Можете получить следующие продукты:
- пошаговый алгоритм написания мощных статей для блога;
- платная книга Как написать статью для блога;
- интеллект карта Пошаговый алгоритм создания блога (сайта) для новичков;
- платный видео-курс «Как написать и оптимизировать статью для блога. Продвижение блога статьями«.
Просмотров: 12479