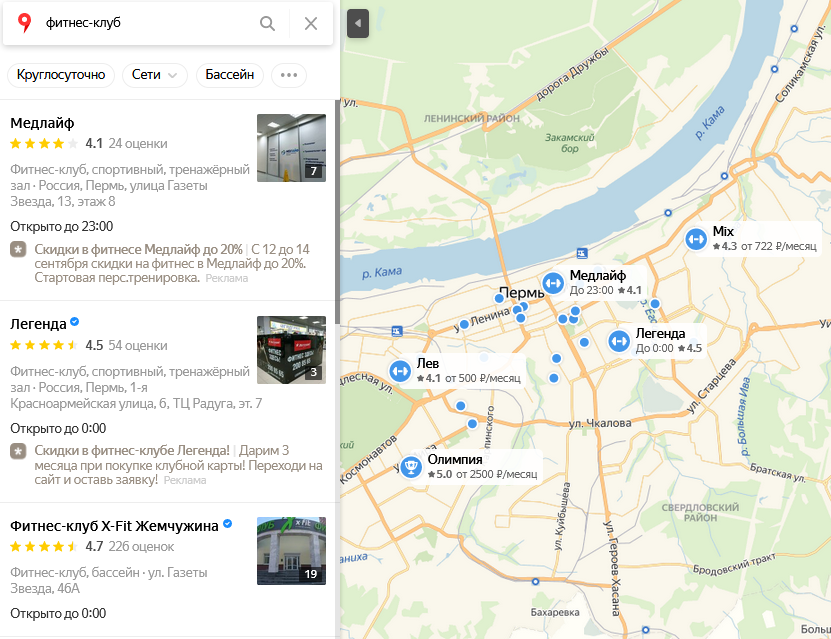
Как попасть в подсказки яндекса
Содержание:
Пошаговый алгоритм работы с сервисом:
- Создание задачи. Чтобы создать задачи, необходимо перейти во вкладку сбор подсказок и нажать «Создать новую задчу»
-
Шаг первый: Поисковая система и регион.
Здесь необходимо ввести название задач (обязательное поле). Можно ввести любое название, часто бывает удобно вводить название сайта, чтобы в будущем легко найти нужную задачу.
Далее мы указываем источник подсказок. Можно выбрать Яндекс и / или Google.
Если выбрать сбор подсказок только поисковой системы «Яндекс» — вы получите результаты в 10-15 раз быстрее. -
Шаг второй: Настройки сбора
Далее нажимаем кнопку «Следующий шаг» и переходим в «Настройки сбора».
Необходимо настроить правила сбора подсказок. Ключевое слово — система соберет подсказки по Вашему ключевому слову.Ключевое слово + пробел — система соберет подсказки по вашему ключевому слову, добавив перед ним пробел.Ключевое слово + -после подстановки пробела, система поочередно подставит все буквы английского алфавита и соберет все доступные подсказки.Ключевое слово + — после подстановки пробела, система поочередно подставит все буквы русского алфавита и соберет все доступные подсказки.Ключевое слово + — после подстановки пробела, система поочередно подставит все цифры и соберет все доступные подсказки.Глубина парсинга- если Вы выберите глубину парсинга 2 и более – после сбора всех подсказок по Вашим ключевым словам, система соберет подсказки по всем новым ключевым словам(подсказкам, полученным на первом уровне). -
Шаг третий: «Ключевые слова и цена».Загружаем списком либо файлом.
Поддерживаемые форматы: xls, xlsx. Необходимо указать столбец, из которого должны браться данные, а также учитывать или нет первую строку.Вводим стоп-слова
Рекомендуем ознакомиться с материалом о том: Как составить список стоп-слов для сбора семантики?
Если в процессе сбора система встретит подсказки, содержащие стоп-слова — такие подсказки будут исключены из списка, а дальнейший сбор подсказок по этой ветке производиться не будет. Функционал стоп слов помогает сэкономить бюджет на сбор данных и решает проблему ручной очистки мусора.
Мы подобрали для Вас большой список с гео запросами, а так же стоп слова по разным тематикам.
Очень важный функционал в стоп словах «Эксперт опции» — по умолчанию применяется символьное соответствие — т.е. стоп-слово «бу» удалит слова и фразы содержащие в себе сочетания букв «бу» — «бублик, бу холодильник, бумага» и т.д. Если выбрать фразовое соответствие стоп-слово «бу» удалит только слово / сочетания слов со словом «бу» — «бу холодильник, купить холодильник бу, бу», но не «бумага, бумеранг» и т.п.
Настоятельно рекомендуем использовать «Фразовое соответствие»
- Нажимаем «Создать новую задачу»!
На странице списка задач виден статус заявки.

Существует несколько статусов:
- Очередь – данные еще не собираются.
- Сбор данных – счетчик показывает, сколько ключевых слов обработано.
- Готов – и рядом появляется возможность скачать файл.
- На паузе – вы можете вручную поставить задачу на паузу, если не уверены, что хотите его собирать. Или же, задача может сам встать на паузу т.к. у вас кончились деньги на балансе.
Результирующий файл имеет следующие листы:
- Подсказки без дубликатов — собранные системой поисковые подсказки на всех уровнях без дубликатов в один столбец.
- Все подсказки — все подсказки по всем словам, по каждому уровню сбора отдельными столбцами.
- Настройки задачи — указаны настройки вашей задачи.
Далее удобнее всего действовать по следующей схеме:
А) проверить все запросы на частотность в yandex.wordstat;
Б) отправить запросы на кластеризацию.
Обзор парсера YouTube Suggest#
Парсер поисковых подсказок по ключевым словам в YouTube. Парсер Ютуб подсказок решает одну из главных задач SEO, а именно быстрое автоматизированное получение расширенного семанического ядра. Благодаря парсеру SE::YouTube::Suggest вы сможете автоматически собирать базы ключей из подсказок поисковой системы YouTube по запросу. Используя парсер SE::YouTube::Suggest можно легко и быстро спарсить подсказки Ютуб по запросу исходя из выбранной страны, языка или домена.
Благодаря многопоточной работе A-Parser’a, скорость обработки запросов может достигать 6000 запросов в минуту, что в среднем позволяет получать до 13500 результатов в минуту.

Вы можете использовать автоматическое размножение запросов, подстановку подзапросов из файлов, перебор цифро-буквенных комбинаций и списков для получения максимально возможного количества результатов. Используя фильтрацию результатов вы можете сразу почистить результат, удалив весь не нужный мусор (использовав минус-слова).
Функционал A-Parser позволяет сохранять настройки парсинга парсера SE::YouTube::Suggest для дальнейшего использования (пресеты), задавать расписание парсинга и многое другое.
Сохранение результатов возможно в том виде и структуре которая вам необходима, благодаря встроенному мощному шаблонизатору Template Toolkit который позволяет применять дополнительную логику к результатам и выводить данные в различных форматах, включая JSON, SQL и CSV.
Исключаем из парсинга отдельные группы товаров/услуг
Ассортимент товаров или услуг конкурентов не всегда совпадает с вашим. Например, конкуренты могут предлагать дополнительные услуги, которых нет у вас. Или охватывают более широкий ассортимент.
Соответственно, в рекламных кампаниях таких конкурентов будут ключевые слова и объявления, которые не подойдут вам.
Исключите нерелевантные ключи и объявления при парсинге, чтобы получить «чистые» результаты.
Перед запуском парсинга добавьте в поле «Минус-слова» перечень товаров или услуг, которые необходимо исключить из результатов. Также исключите сущности, которые не подходят для рекламы ваших товаров: «бесплатно», «подарок», «бу» и т. д.
Снимите галочку с пункта «Точное вхождение без учета морфологии».
В нашем примере система спарсит релевантные ключевые слова, исключив фразы типа «кухни на заказ», «офисная мебель недорого», «ремонт мебели» и т. д.
Этапы работы с семантическим ядром
Теперь когда мы знаем, что такое семядро и для чего оно нужно, а также знакомы с основными классификациями запросов, давайте вкратце разберём основные этапы работы с ядром.
Сбор семантики
Подробные способы сбора семантики будут даны в части «», здесь же мы остановимся на основных моментах.
На этом этапе вы должны найти и выписать общие запросы (их ещё называют маркерными), которые характеризуют деятельность вашего бизнеса: как общие направления, так и отдельные услуги и товары.
Например, вы продаёте мотоциклы определённой компании. Вашими маркерными запросами могут являться «мотоциклы», «мотоциклы + бренд» , «как выбрать мотоцикл», «запчасти для мотоцикла + бренд», «как ухаживать за мотоциклом», «классические/спортивные/круизёры и другие типы мотоциклов», «ремонт мотоциклов + бренд» и т.д. То есть в зависимости от оказываемых услуг или имеющихся товаров выбираются соответствующие маркеры.
После определения маркерных запросов проверяйте собранные ключевые слова в основных сервисах статистики запросов: Яндекс.Вордстат или Google Ads Планировщик ключевых слов. В них вы найдёте как частотность запросов, так и варианты других ключевых слов по вашей тематике. Собирайте всё, что как-то связано с вашим бизнесом.
Принципиальная разница между обозначенными сервисами заключается в следующем:
- Статистика в каждом актуальна только для родной поисковой системы. То есть если запрос «юридические услуги» смотреть в Вордстате, то показов будет более 100 000 именно в Яндекс. В Планировщике ключевых слов значения соответственно будут отличаться в Google.
- Плюс Вордстата в том, что он показывает точное значение показов запроса. Если у вас новый аккаунт в Google Ads, вместо точных значений запроса вы получите диапазоны типа 10–100, 100–1000 и т.д.
- Плюс Планировщика ключевых слов в том, что он даёт множество вариантов ключей сразу, чтобы учесть все варианты запросов для вашего сайта в продвижении и рекламе.
Если денег на платные инструменты нет, советуем использовать сразу 2 сервиса при сборе семантики. Но всё же рекомендуем купить Key Collector. Его основная задача — это автоматический сбор (парсинг) ключевых слов не только с Вордстата и Планировщика, но и с других сервисов и баз. Это не реклама данного инструмента, но уточним, что, кроме парсинга, сервис удобен для чистки и кластеризации ядра. Для многих SEO-специалистов Key Collector как швейцарский нож.
Интерфейс KeyCollector
Очистка
Когда все варианты запросов пользователей собраны в одной таблице, наступает время чистки от лишнего.
Лишними являются запросы, которые:
- слишком общие,
- не относятся к деятельности вашего сайта,
- не подходят по географии,
- включают в себя неактуальные цифры и даты,
- имеют брендовые составляющие конкурентов,
- состоят из 8 слов и более,
- затруднительно использовать на одной странице.
В качестве примера приведём подобранные ключи для одной из компаний, которая занимается продажей электрических каминов в Санкт-Петербурге:
Кластеризация и выбор страниц
Кластеризация — это группировка запросов по общности их смысловых значений в иерархическом порядке. То есть в одном кластере, или группе, должны быть запросы, описывающие одну сущность в глазах пользователя и поисковой системы. Делается это либо вручную, либо с помощью специальных сервисов.
Вернёмся к нашим каминам и возьмём следующие запросы:
- камин электрический с эффектом пламени;
- камины электрические с эффектом живого пламени;
- камины электрические фото;
- купить камин электрический;
- камин электрический купить в спб;
- угловой камин электрический;
- угловые камины электрические купить.
Первые два запроса можно объединить в один кластер и продвигать на одной странице. 3-й предполагает галерею или каталог, 4 и 5-й маркерные и достаточно общие, поэтому для них подойдёт главная страница или каталог. 6 и 7-й описывают категорию электрокаминов и под них стоит создать отдельную страницу на сайте.
Это пример ручной кластеризации, но мы указали, что запросы должны описывать одну сущность и в глазах пользователя, и поисковика. И вот тут начинаются проблемы, потому что часто можно столкнуться с тем, что схожие на первый взгляд запросы формируют разную поисковую выдачу. Чтобы избежать таких ошибок, используются специальные сервисы кластеризации, которые сравнивают выдачу и группируют кластеры.
Мониторинг
Важно не просто собрать ключевые слова и использовать их в создании контента для сайта, но и отслеживать рост позиций и трафика по этим запросам. О том, как это делать и какие сервисы можно использовать, читайте в нашей статье про проверку позиций
Виды подсказок
Пословные
Работают в мобильных приложениях и в «Яндекс.Браузере». Люди вбивают запрос из одного слова, затем им предлагается список, из которого нужно выбрать одно слово. По такой цепочке можно сформировать длинный запрос, корректируя каждое отдельное слово.
Полнотекстовые
Десктоп подразумевает использование полнотекстовых подсказок, так как пользователи гораздо быстрее вбивают запрос на ПК. Удобнее сразу напечатать основную часть запроса, а затем выбрать подходящий «хвост».
Подсказки-фактоиды
Для пользователей мобильных гаджетов при вводе таких запросов как «погода», «факты», «пробки» автоматически отображаются подсказки в виде информации.
Например, если вы вбиваете в мобильном поиске запрос «погода Санкт-Петербург», то под поисковой строкой отобразится текущая температура.
Реализованы подобные подсказки и в сервисе «Яндекс.Видео», где пользователям выводятся номера сезонов и серий. В первую очередь вы выбираете сезон, затем серию. При поиске по названию фильма, система предлагает прямую ссылку на него в виде подсказки.
Длинные
В последние годы отмечается тенденция увеличения длины поисковых запросов. Учитывая это, поисковые системы начали использовать и длинные поисковые подсказки. Они выводятся в основной поисковой выдаче, а также при поиске видео и картинок.
Исторические
Поисковые системы «следят» за пользователями, поэтому знают какие поисковые запросы они вводили в прошлом. На основе этой информации подсвечивают сайты, на которых они ранее искали информацию. Ранее это применялось только в десктопе, но сейчас они стали доступны для пользователей мобильных гаджетов и внедрены в поисковые сервисы «Яндекс».
Yandex Wordstat Assistant
Расширение устанавливается в 3 простых шага:
1) Скачайте актуальную версию расширения для браузера, в котором работаете с Яндекс Wordstat: Google Chrome, Mozilla Firefox, Opera или Яндекс Браузер.
Для всех браузеров алгоритм одинаковый. Мы покажем, как устанавливать и пользоваться возможностями Wordstat Assistant, на примере Google Chrome.
2) Нажмите кнопку для установки:
3) Подтвердите, что собираетесь установить расширение:
На этом всё готово, остается проверить, установилось ли расширение.
Если всё корректно, вы увидите:
Значок с таким уведомлением – теперь он всегда будет отображаться в вашем браузере.
Если такого значка нет, попробуйте перезапустить браузер.
Панель управления Wordstat Assistant в левой области страницы Яндекс Wordstat – в неё будут попадать все ключевые фразы, которые вы добавите.
На случай, если панель не появится, обновите страницу или также перезапустите браузер.
Знак «+» напротив каждого результата и в левой, и в правой колонке – нужен, чтобы добавлять фразы в список.
Чтобы его увидеть, введите нужную фразу, как обычно в Вордстате, например:
Рассмотрим все функции по порядку.
1) Добавление и удаление фраз из списка
Можно добавить в список отдельную ключевую фразу, нажав на плюс, или все фразы из таблицы (именно с той страницы, на которой вы находитесь, а не из всей выдачи), нажав ссылку «Добавить все»:
Например, мы хотим добавить все похожие фразы из левой колонки с первой страницы. Жмем «Добавить все», в окне подтверждения – «Добавить»:
Выглядит это так, в скобках указана частотность для каждого запроса:
Над списком отображается общее количество фраз, которые вы добавили, и суммарная частотность по ним:
В результатах поиска Yandex Wordstat фразы, которые вы выбрали, становятся серого цвета, со знаком минус вместо плюса.
Эти опции при необходимости можно отключить здесь:
По знаку «–» фразу можно в любой момент удалить из результатов поиска Яндекс Wordstat (1). Либо можно удалить прямо её из панели управления: для этого наведите на фразу курсор и кликните по минусу рядом с ней (2). Чтобы очистить весь список, нажмите крестик вверху панели управления (3).
При попытке добавить такой же ключ, какой уже есть в списке, Wordstat Assistant выдает сообщение:
2) Добавление собственных ключей
Для этого нажмите плюс на панели управления, введите запрос или список запросов, как на скриншоте:
Для добавленных вручную фраз вместо частотности показывается знак вопроса:
Если ваша фраза совпадает с фразой из результатов поиска Wordstat, последняя выделяется серым цветом. Но частотность при этом остается неизвестной (?), а не перетягивается из данных Wordstat.
3) Сортировка списка ключевых фраз
Её можно выполнять с помощью этой кнопки:
Она меняет свой вид в зависимости от того, по какому признаку вы сортируете фразы:
По возрастанию и убыванию частотности:
По алфавиту:
По порядку добавления (вновь добавленные в конец / в начало списка):
4) Копирование данных из Вордстата
Можно скопировать просто список фраз (1), либо список фраз вместе с фразами значения частотности (2), чтобы работать с ними дальше в любом формате – например, txt или Excel:
Чтобы автоматически удалить знак «+» из всех фраз, задайте эту настройку:
Если вы закроете вкладку с Wordstat или браузер, ничего не потеряется. Список сохранится под тем аккаунтом, в котором вы его сформировали.
Очистка СЯ от «мусора»
Покажем, как это делать в Key Collector.
Ключевики, которые содержат ненужные слова
Нажимаем вкладку выбора условий фильтрации:

Задаем условие, как указано на скриншоте, и пишем слова:
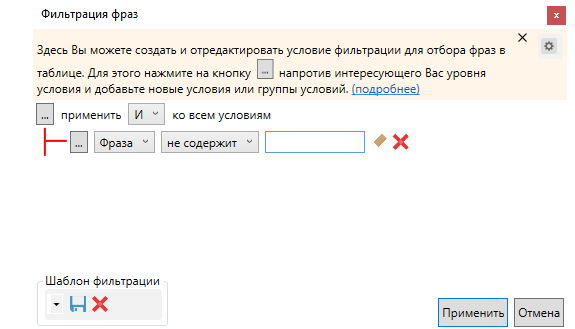
Отмечаем фразы и добавляем в корзину:
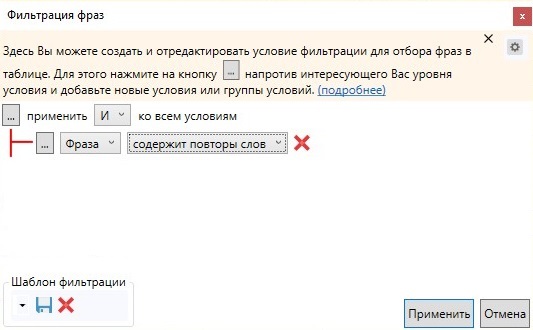
Повторы слов
Аналогично вызываем настройки фильтрации фраз и выбираем такой вариант:
Стоп-слова (информационные запросы, города, в которых не действует предложение, «бесплатно», «дешево», субъективные определения и т.д.)
Нажимаем этот значок в верхнем меню:

В окне настроек добавляем фразы (1) и разбиваем по группам (2):
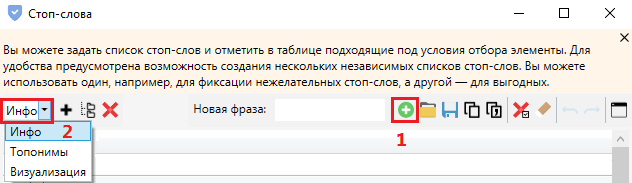
Далее — выделяем слова в таблице галочкой и добавляем в список стоп-слов.
Группы слов
Чтобы разбить запросы на группы, на вкладке «Данные» открываем «Анализ групп». В окне выбираем тип «По отдельным словам»:

Выбранные группы появятся в основном списке запросов, где можно отсеять все ненужные.
Запросы с нулевой частотностью
Выбираем следующее условие фильтрации:

Далее — требования по частоте:

Можно удалить нецелевые запросы и вручную: копируем ключевики в Word. Заменяем пробел на знак абзаца, чтобы представить все слова из словосочетаний в виде колонки. Переносим обратно в Excel на отдельный лист, сортируем и определяем минус-слова. Затем находим с помощью фильтра фразы с ними и удаляем.
На какие вопросы машинный интеллект не дает ответы
Сбор семантики быстрее и проще с помощью различных сервисов, баз, приложений — благо, выбор есть. Однако нельзя слепо полагаться на автоматизацию. Есть два случая, когда без ручного труда не обойтись.
Уже при подборе масок нужно «вытаскивать» синонимы и переформулировки из сайтов заказчика и конкурентов, правой колонки Wordstat, собственных идей и т.д. Мы увидели, что это всё предстоит делать специалисту по контекстной рекламе.
Самый трудозатратный и не автоматизируемый процесс — очистка СЯ от «мусора». Готовых минус-списков и данных об отказах из Яндекс.Метрики недостаточно для 100% точности. Приходится смотреть предварительные списки и выявлять смысловое соответствие результатов бизнесу.
Особенно это касается сложных продуктов. Например, подготовка сжатого воздуха, или осушка воздуха. Больше расширений можно насобирать по слову «осушка».
Но среди результатов в Wordstat в мы можем увидеть и «осушка газа», и «адсорбционная осушка», и «осушка компрессора». Не всегда семантическое соответствие гарантирует смысловое соответствие. Это разные продукты, а значит, разный спрос. Чаще всего выявить и исключить его можно только вручную.
Если вы не проверяете результаты парсинга, вы жертвуете полнотой СЯ и точностью будущих рекламных кампаний. Совет: выбирайте оптимальный баланс «трудозатраты — полнота» и делайте полный список минус-слов.
Возможные настройки#
important
| Название параметра | Значение по умолчанию | Описание |
|---|---|---|
| Device | Выбор типа выдачи(Modern desktop computer (Windows 10, Chrome 84) / Mobile device (iPhone X, iOS 11)) | |
| Pages count | Количество страниц для парсинга(от 1 до 25) | |
| Links per page | Количество ссылок в выдачи на каждую страницу(10 / 20 / 30 / 50) | |
| Sort serp by date | ☐ | Сортировка выдачи по дате |
| Yandex domain | Домен Яндекса для парсинга, поддерживаются все домены (.ru, .ua, .by, .kz, .com.tr, .com). Начиная с версии 1.1.345 выбирается автоматически в зависимости от выбранного региона. | |
| Region of serp (lr=) | Выбор региона поиска (параметр lr=) | |
| Search sites from (rstr=) | Выбор региональной привязки сайтов (параметр rstr=) | |
| Language | Язык результатов поиска(Russian, English, Belorussian, French, German, Indonesian, Kazakh, Tatar, Turkish, Ukrainian) | |
| Parse not found | Определяет парсить ли выдачу если по искомому запросу найдено ноль результатов и предложена выдача по другому запросу | |
| Not personalized | ☐ | Персонализация поиска. Детальнее тут |
| Filter pages | Фильтрация результатов от нежелательного контента(Family search / Moderate filter / Do not filter) | |
| Use Accounts | ☐ | Работа с существующими аккаунтами в файл files/SE-Yandex/accounts.txt. SE::Yandex::Register — Позволяет регистрировать аккаунты в Yandex |
| Remove bad accounts | Удаление невалидных аккаунтов | |
| AntiGate preset | Использование сервиса разгадывания капчи. Необходимо предварительно настроить парсер Util::AntiGate — указать свой ключ доступа и другие параметры, после чего выбрать созданный пресет здесь | |
| Disable HTTP2 | ☐ | Определяет поддержку HTTP2 |
Как поисковик формирует подсказки
У каждой системы – Яндекса, Google и даже YouTube, принадлежащего Google, – свои собственные уникальные алгоритмы. Тем не менее можно выделить несколько общих факторов, влияющих на появление определенных поисковых подсказок:
Региональность
Поисковики учитывают географию пользователей при формировании поисковых подсказок. Особенно это касается запросов, начинающихся со слов «купить», «заказать», «доставка», «где» и т. д.
 Примеры подсказок по коммерческому запросу
Примеры подсказок по коммерческому запросу
Популярность и актуальность
Подсказки выдаются с учетом того, что сейчас в тренде, освещается в соцмедиа.
 Google не скрывает, что тренды определяют поисковые подсказки
Google не скрывает, что тренды определяют поисковые подсказки
Это легко проверить на практике. Просто возьмите пару недавних новостей из СМИ и начните вводить в поисковую строку имена героев, названия брендов или города, где произошли те или иные события. Подсказки реагируют быстро, в отличие от Яндекс.Вордстата и готовых баз ключевых слов.
Поисковое поведение
Поисковики учитывают интересы пользователей, часто посещаемые сайты, предыдущие запросы. Персонализация улучшает качество поиска.
 Если вы уже вбивали в Яндексе запросы, которые начинались точно также – таковые появятся в самом верху списка
Если вы уже вбивали в Яндексе запросы, которые начинались точно также – таковые появятся в самом верху списка
Парсинг вопросов-ответов в результатах поиска
Вопросы/ответы можно извлекать и вручную из результатов поиска. Но зачем, если есть шаблон от Hannah Rampton?
Это один из шаблонов, который мы используем при поиске идей для контента и постановке ТЗ копирайтерам. Анализ вопросов, связанных с основным запросом, позволяет углубиться в тему и создать интент-ориентированный контент (подробнее — в нашей статье об алгоритме Neural Matching).
Для выгрузки вопросов/ответов:
- создайте копию шаблона Google Q&A Extraction_v2;
- установите бесплатное расширение Scraper для Chrome (оно парсит данные с веб-страниц с помощью XPath);
- измените в настройках поисковика язык с русского на английский (это нужно для корректной работы формул в шаблоне).
Приступаем к парсингу вопросов/ответов:
в открывшемся окне в блоке «Selector» выбираем «XPath», вводим в поле запрос для парсинга раскрывающихся списков с вопросами/ответами: //g-accordion-expander (обратите внимание, чтобы блок Columns был заполнен так же, как на скриншоте);
нажимаем «Scrape»;
- после парсинга нажимаем «Copy to clipboard»;
- открываем шаблон, переходим на лист «Google Questions and Answers», наводим курсор на ячейку А10 и нажимаем Ctrl+Shift+V.
Если все сделано верно, то поля с вопросами, ответами и URL заполнятся автоматически.
На листе «Clean Data» та же информация представлена в юзабельном текстовом формате (кроме того, здесь исключены дубли).
На листе «Search by Keyword» вы можете найти вопросы по заданному ключевому слову (или его части).
Также вы можете выбрать вопросы по домену — для этого на листе «Search by Domain» введите полный URL или его часть.
Таким образом, вы быстро и бесплатно найдете релевантные вопросы по вашей тематике.
Зачем нужны парсеры
Парсер — это программа, сервис или скрипт, который собирает данные с указанных веб-ресурсов, анализирует их и выдает в нужном формате.
С помощью парсеров можно делать много полезных задач:
Для справки. Есть еще серый парсинг. Сюда относится скачивание контента конкурентов или сайтов целиком. Или сбор контактных данных с агрегаторов и сервисов по типу Яндекс.Карт или 2Гис (для спам-рассылок и звонков). Но мы будем говорить только о белом парсинге, из-за которого у вас не будет проблем.
Где взять парсер под свои задачи
Есть несколько вариантов:
- Оптимальный — если в штате есть программист (а еще лучше — несколько программистов). Поставьте задачу, опишите требования и получите готовый инструмент, заточенный конкретно под ваши задачи. Инструмент можно будет донастраивать и улучшать при необходимости.
- Воспользоваться готовыми облачными парсерами (есть как бесплатные, так и платные сервисы).
- Десктопные парсеры — как правило, программы с мощным функционалом и возможностью гибкой настройки. Но почти все — платные.
- Заказать разработку парсера «под себя» у компаний, специализирующихся на разработке (этот вариант явно не для желающих сэкономить).
Первый вариант подойдет далеко не всем, а последний вариант может оказаться слишком дорогим.
Что касается готовых решений, их достаточно много, и если вы раньше не сталкивались с парсингом, может быть сложно выбрать. Чтобы упростить выбор, мы сделали подборку самых популярных и удобных парсеров.
Законно ли парсить данные?
В законодательстве РФ нет запрета на сбор открытой информации в интернете. Право свободно искать и распространять информацию любым законным способом закреплено в четвертом пункте 29 статьи Конституции.
Допустим, вам нужно спарсить цены с сайта конкурента. Эта информация есть в открытом доступе, вы можете сами зайти на сайт, посмотреть и вручную записать цену каждого товара. А с помощью парсинга вы делаете фактически то же самое, только автоматизированно.
Как получить список поисковых подсказок
Можно получить несколькими способами:
- Используя блок дополнительного поиска в системе Google «Вместе с … часто ищут». Для этого вводится запрос, и можно посмотреть, что ищут вместе с ним.
Такой вид не совсем удобен, поскольку, во-первых, показывает всего около десятка подсказок, что очень мало для создания семантического ядра сайта. Во-вторых, каждую фразу приходится набивать отдельно, что занимает много времени. Выгрузить результаты по нескольким запросам сразу нельзя.
2. Посредством инструментов для парсера подсказок поисковых систем:
Ubersuggest — позволяет увидеть информацию из поиска по новостям, изображениям и видео поисковой системы. Нужно ввести ключевое слово в строку поиска и задать язык.
Этот сервис подскажет, какие слова пользователи ищут вместе с заданными «ключевиками». Дополнительные слова при этом разделяются от заданного основного знаком «+». Сортировка по алфавиту делает работу с данными удобной для SEO-оптимизатора.
- Keyword Tool является бесплатным сервисом. Он основан на подсказках Google для разных регионов и языков данной поисковой системы. Также сервис позволяет увидеть семантику из Bing, AppStore и YouTube. Стандартно вводится слово в строку поиска, производится отбор по базе данных и языку.
- Словодер — программа, позволяющая работать сразу с несколькими поисковыми системами, поскольку работает через прокси-сервер. Для начала работы необходимо скачать программу, после ее запуска ввести слово для поиска и выбрать нужный поисковик — поисковые подсказки Яндекс , Google, Mail, Rambler, Yahoo, Nigma. Затем нужно нажать на кнопку «Парсить» и подождать вывода результатов.
- avtodreem, чаще всего можно встретить в поисковой выдаче по запросу «как попасть в подсказки».
Что умеет парсер Wordstat?
Возможности парсера:
- пакетная проверка частотностей;
- сбор частотностей по регионам;
- хранение отчетов в «облаке».
Также сервис позволяет учитывать тип соответствия запроса при парсинге (с применением операторов расширенного поиска).
Особенности и преимущества сервиса:
- нет ограничений по количеству фраз — за одну проверку можно спарсить частотности для нескольких тысяч или даже десятков тысяч запросов;
- сервис работает онлайн «в облаке» — не нужно скачивать и устанавливать программное обеспечение;
- быстрый и безопасный парсинг — не нужно обходить капчу или использовать прокси;
- отчет выгружается в формате XLSX.
- стоимость сервиса — в два-три раза ниже аналогов;
- первые 50 проверок — бесплатные.
P. S. Помните о сезонности
Вордстат – и, следовательно, парсер тоже – показывает статистику за последние 30 дней. Если запрос сезонный, можно сделать неправильные выводы, если смотреть только один месяц. Сезонные ключи нужно дополнительно проверять на wordstat.yandex.ru в разделе «История запросов»:

Зарегистрируйтесь в Click.ru сейчас и получите доступ к парсеру Wordstat, а также бесплатным инструментам по созданию и управлению контекстной рекламой – умному подборщику слов, генератору объявлений, медиапланеру, автобиддеру. По промокоду key вы в течение месяца сможете апробировать все возможности сервиса и получать максимальное вознаграждение 8 % вне зависимости от суммы расходов на контекстную рекламу.
Возможности и преимушества#
Многопоточность и производительность
- A-Parser работает на основе последних версий NodeJS и JavaScript движка V8
- AsyncHTTPX — собственная реализация HTTP движка с поддержкой HTTP/1.1 и HTTP/2, HTTPS/TLS, поддержка прокси HTTP/SOCKS4/SOCKS5 с опциональной авторизацией
- в зависимости от конфигурации компьютера и решаемой задачи
- Каждое задание(набор запросов) парсится в указанное число потоков
- При использовании нескольких парсеров в одном задании каждый запрос к разным парсерам выполняется в разных потоках одновременно
- Парсер умеет запускать несколько заданий параллельно
- также проходит в многопоточном режиме
Создание собственных парсеров
- Возможность создания парсеров без написания кода
- Использование регулярных выражений
- Поддержка многостраничного парсинга
- Вложенный парсинг — возможность
- Полноценная : разбор и формирование
- их для обработки полученных результатов прямо в парсере
Создание парсеров на языке JavaScript
- Богатое встроенное API на основе async/await
- Поддержка
- Возможность подключения любых NodeJS модулей
- Управление Chrome/Chromium через puppeteer с поддержкой раздельных прокси для каждой вкладки
Мощные инструменты для формирования запросов и результатов
- Конструктор запросов и результатов — позволяет видоизменять данные(поиск и замена, выделение домена из ссылки, преобразования по регулярным выражениям, XPath…)
- : из файла; перебор слов, символов и цифр, в том числе с заданным шагом
- Фильтрация результатов — по вхождению подстроки, равенству, больше\меньше
- Уникализация результатов — по строке, по домену, по главному домену(A-Parser знает все домены верхнего уровня, в т.ч. такие как co.uk, msk.ru)
- Мощный шаблонизатор результатов на основе — позволяет выводить результаты в любом удобном виде(текстом, csv, html, xml, произвольный формат)
- В парсере используется система пресетов — для каждого парсера можно создать множество предустановленных настроек для различных ситуаций
- Настроить можно все — никаких рамок и ограничений
- и настроек позволяет легко обмениваться опытом с другими пользователями
API
- Возможность интегрировать и управлять парсером из своих программ и скриптов
- Полная автоматизация бизнес-процессов
- Клиенты для PHP, NodeJs, Perl и Python
Обзор парсера Yandex#
Парсер поисковой выдачи Яндекса по праву входит в ТОП-5 самых востребованных парсеров. Одно из главных конкурентных преимуществ нашего парсера это его колоссальная производительность. Благодаря многопоточной работе A-Parser’a, скорость обработки запросов может достигать 3000-7000 запросов в минуту, что в среднем позволяет получать до 5000000 ссылок в минуту, при этом потребление ресурсов минимальное, для работы подойдет любой офисный или домашний компьютер, а также любой VDS начального уровня. Наш парсер поддерживает все поисковые операторы Яндекса, что позволяет значительно расширить возможности парсинга.
Стабильность и бесперебойность парсинга выдачи обеспечивается за счет распознавания капчи через AntiCaptcha или любой другогой поддерживающего их API (Anti-Captcha, RuCaptcha, CapMonster.cloud, 2captcha и другие).
Гибкость в настройках позволяет указывать тип выдачи (мобильная/десктоп), регион, язык, сортировку выдачи по дате и многое другое.
Функционал A-Parser позволяет сохранять настройки парсинга для дальнейшего использования (пресеты), задавать расписание парсинга и многое другое. Вы можете использовать автоматическое размножение запросов, подстановку подзапросов из файлов, перебор цифро-буквенных комбинаций и списков для получения максимально возможного количества результатов.
Сохранение результатов возможно в том виде и структуре которая вам необходима, благодаря встроенному мощному шаблонизатору Template Toolkit который позволяет применять дополнительную логику к результатам и выводить данные в различных форматах, включая JSON, SQL и CSV.
SUBSTITUTE — меняем/удаляем пробелы и спецсимволы
Универсальная функция замены/удаления символов в ячейках.
Синтаксис:
Номер соответствия — порядковый номер встреченного значения на замену, например, первое встреченное заменить, остальные оставить. Опциональный параметр.
Пример. У нас есть выгрузка ключевых фраз из Яндекс.Вордстат. Многие ключи содержат плюсики. Нам нужно их удалить.
Формула будет иметь вид:
Что мы сделали:
- где искать — указали ячейку с данными;
- «что искать» — указали плюсик, который нужно удалить;
- «на что менять» — поскольку символ нужно удалить, мы указали кавычки без символов внутри; если бы нам нужна была замена, здесь бы мы прописали текст, на который нужно заменить плюсик;
- номер соответствия — здесь мы ничего не указали, и функция удалит все плюсы в фразе; если бы мы указали 1, то функция удаляла бы только первый плюсик, если 2 — второй и т. д.
Формирование поисковых подсказок
За формирование подсказок отвечают сложные алгоритмы поисковых систем. Основные факторы, от которых зависит их создание:
- Частота поисковых фраз. «Яндекс» и Google предлагают пользователям самые популярные окончания, которые чаще всего вбивают в поисковую строку.
- Региональность. Принцип формирования подсказок зависит от того, в каком регионе пользователь вбивает запрос. Например, если он ищет пластиковые окна в Москве, то ему не выводятся подсказки с названием других городов.
- Актуальность. Алгоритмы учитывают и этот фактор. Прежде всего, касается тех поисковых запросов, которые связаны со свежими новостями.
- Персонализация. Построена на статистике поисковых запросов, истории поиска и прочей информацией, которая доступна поисковикам.