Sql «для чайников»: что нужно знать начинающим?
Содержание:
Practical skills of SQL language
This site will help everyone to gain or improve skills in building
SQL Data Manipulation Language statements. To train You will have to build yourself
the SQL statements for retrieval or modification of specific data required in the exercises.
When Your query is incorrect, You will be able to see rows returned by the correct
query along with that returned by Your query. Furthermore, you may execute arbitrary
DML statements on available databases by setting the «Without checking» option. There are
five levels of difficulty (from 1 to 5), You may see it in second column of
exercises list. We propose the exercises on retrieving data (SELECT statement) and
the exercises on modifying data (INSERT, UPDATE, DELETE, and MERGE statements). Your success in the solving the exercises are shown by a rating of participants.
As this takes place, there are three stages:
the first one (first 5 exercises) is performed without time control for an individual
exercise, the second one (begins with the exercise #6) controls time for completion of each
task. At the third stage which refers to optimizing and begins with exercise #139, it is required not only to solve an exercise correctly, but also time of execution of inquiry should be commensurable with time of execution of the author’s solution.
Exercises of the first stage are available without registration and may be solved
in any order You like. The solution of the rest of exercises requires registration.
REGISTRATION IS FREE as this for all other services of the site. In the third column of exercises list You
will be able to see («OK») notes with the numbers of done exercises, but that
is available only to the registered users. In fact, that is the main reason for registration.
If You would like to visit our web site again, You won’t have to recollect which
exercises You have done already and which You haven’t. If You don’t want to register,
You may enter as a guest, but in that case Your results won’t
be traced by the system. Registered users also may discuss the solutions to exercises in our forum.
NOTE: The query stated incorrectly may return the «correct» data on a current state of database.
For this reason You should not be surprised if the results of incorrect query are
coincide with the results of right one with Your query is estimated as incorrect by the Verifying system.
NOTE: Your browser should support Cookies and Javascript to provide correct usage of this site. If you use content filter, it should allow opening child windows to explore help pages.
Распределенная обработка SQL
Архитектура распределенной реляционной базы данных (DRDA) была разработана рабочей группой в IBM в период с 1988 по 1994 год. DRDA позволяет связанным с сетью реляционным базам данных взаимодействовать для выполнения запросов SQL.
Интерактивный пользователь или программа может выдавать SQL-запросы локальному RDB и получать таблицы данных и индикаторы состояния в ответ от удаленных RDB. Операторы SQL также могут быть скомпилированы и сохранены в удаленных RDB как пакеты, а затем вызваны именем этого пакета
Это важно для эффективной работы прикладных программ, которые вызывают сложные высокочастотные запросы. Это особенно важно, когда доступ к таблицам находится в удаленных системах.
Сообщения, протоколы и структурные компоненты DRDA определяются архитектурой распределенного управления данными.
Примеры простых запросов SQL к базам данных.
Рассмотрим основные запросы SQL.
SELECT
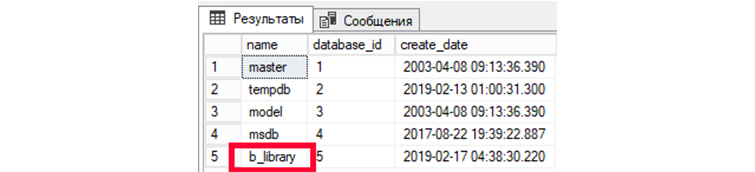
1) Выведем все имеющиеся у нас БД:
SELECT name, database_id, create_date FROM sys.databases;
2) Выведем все таблицы в созданной нами ранее БД «b_library»:
SELECT * FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_TYPE=’BASE TABLE’
 3) Выводим еще раз имеющиеся у нас записи по авторам книг из созданной выше «tAuthors»:
3) Выводим еще раз имеющиеся у нас записи по авторам книг из созданной выше «tAuthors»:
SELECT * FROM tAuthors;
 4) Выведем информацию о том, сколько у нас имеется записей строк в «tAuthors»:
4) Выведем информацию о том, сколько у нас имеется записей строк в «tAuthors»:
SELECT count(*) FROM tAuthors;
 5) Выведем из «tAuthors» две записи, начиная с четвертой. Используя ключевое слово OFFSET, пропустим первые три записи, а благодаря использованию ключевого слова FETCH – обозначим выборку только следующих 2 строк (ONLY):
5) Выведем из «tAuthors» две записи, начиная с четвертой. Используя ключевое слово OFFSET, пропустим первые три записи, а благодаря использованию ключевого слова FETCH – обозначим выборку только следующих 2 строк (ONLY):
SELECT * FROM tAuthors ORDER BY AuthorId OFFSET 3 ROWS FETCH NEXT 2 ROWS ONLY;
 6) Выведем из «tAuthors» все записи с сортировкой в алфавитном порядке по первой букве имени автора:
6) Выведем из «tAuthors» все записи с сортировкой в алфавитном порядке по первой букве имени автора:
SELECT * FROM tAuthors ORDER BY AuthorFirstName;
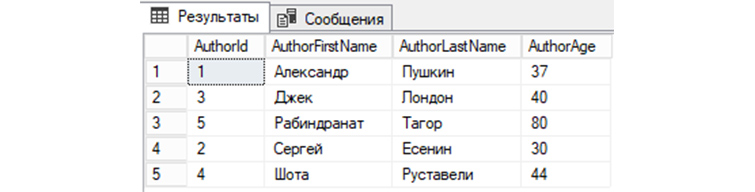 7) Выведем из «tAuthors данные, предварительно по AuthorId отсортировав их по убыванию:
7) Выведем из «tAuthors данные, предварительно по AuthorId отсортировав их по убыванию:
SELECT * FROM tAuthors ORDER BY AuthorId DESC;
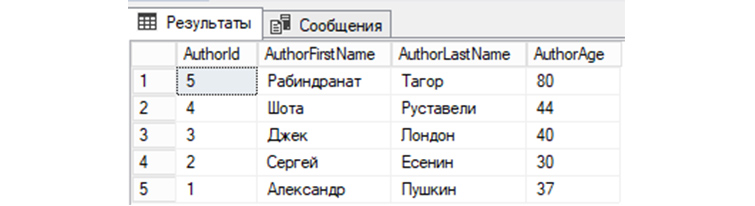 8) Выберем записи из «tAuthors», значение AuthorFirstName у которых соответствует имени «Александр»:
8) Выберем записи из «tAuthors», значение AuthorFirstName у которых соответствует имени «Александр»:
SELECT * FROM tAuthors WHERE AuthorFirstName=’Александр’;
 9) Выберем из «tAuthors» записи, где имя автора AuthorFirstName начинается с «се»:
9) Выберем из «tAuthors» записи, где имя автора AuthorFirstName начинается с «се»:
SELECT * FROM tAuthors WHERE AuthorFirstName LIKE ‘се%’;
 10) Выберем из «tAuthors» записи, в которых имя автора (AuthorFirstName) заканчивается на «ат»:
10) Выберем из «tAuthors» записи, в которых имя автора (AuthorFirstName) заканчивается на «ат»:
SELECT * FROM tAuthors WHERE AuthorFirstName LIKE ‘%ат’ ORDER BY AuthorId;
 11) Сделаем выборку всех строк из «tAuthors», значение AuthorId в которых равняется 2 или 4:
11) Сделаем выборку всех строк из «tAuthors», значение AuthorId в которых равняется 2 или 4:
SELECT * FROM tAuthors WHERE AuthorId IN (2,4);
 12) Выберем в «tAuthors» такую запись AuthorAge, значение которой — наибольшее:
12) Выберем в «tAuthors» такую запись AuthorAge, значение которой — наибольшее:
SELECT max(AuthorAge) FROM tAuthors;
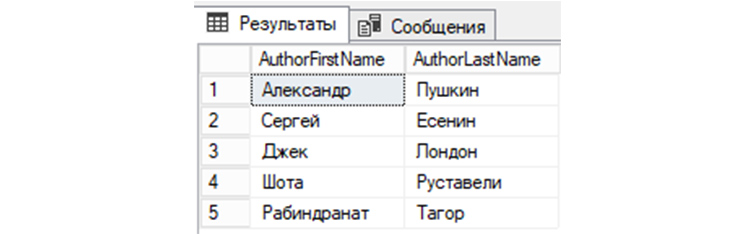
 13) Проведем выборку из «tAuthors» по столбцам AuthorFirstName и AuthorLastName:
13) Проведем выборку из «tAuthors» по столбцам AuthorFirstName и AuthorLastName:
SELECT AuthorFirstName, AuthorLastName FROM tAuthors;
 14) Получим из «tAuthors» все строки, у которых AuthorId не равняется трем:
14) Получим из «tAuthors» все строки, у которых AuthorId не равняется трем:
SELECT AuthorId, AuthorFirstName, AuthorLastName FROM tAuthors WHERE AuthorId!=’3′;
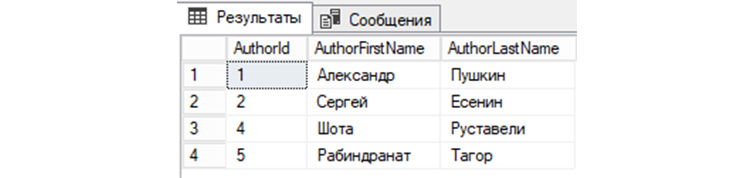
INSERT
INSERT – это вид запроса SQL, при применении которого СУБД выполняет добавление новых записей в БД. Добавим в «tAuthors» нового автора – Уильяма Шекспира, 51 год. Соответственно в поле AuthorFirstName добавится Уильям, в AuthorLastName добавится Шекспир, в AuthorAge – 51. В AuthorId, в нашем случае, автоматически добавится значение, инкрементированное от предыдущего на 1.
INSERT INTO tAuthors VALUES (‘Уильям’, ‘Шекспир’, ’51’);
Проверим:
SELECT * FROM tAuthors;
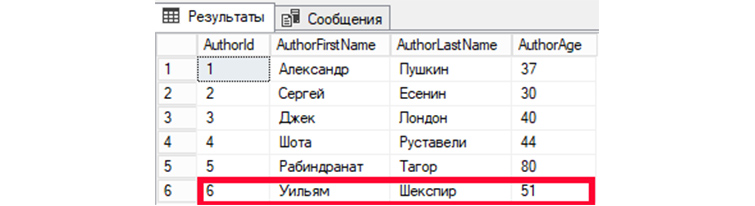
UPDATE
UPDATE – SQL запрос, позволяющий внести изменения или дописывать новую информацию в те записи, которые уже существуют.
Внесем корректировки в шестую запись (AuthorId = 6). Значения изменим для полей имени, фамилии и возраста автора.
UPDATE tAuthors SET AuthorFirstName = ‘Лев’, AuthorLastName=’Толстой’, AuthorAge = ’82’ WHERE AuthorId = ‘6’;
Затем, обратимся к БД, чтобы вывести все имеющиеся записи:
SELECT * FROM tAuthors;
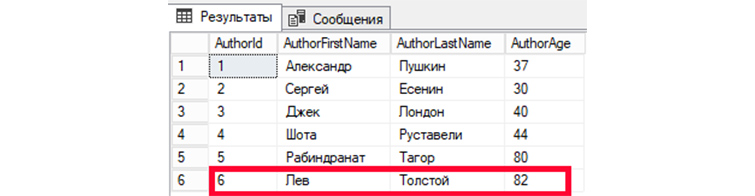
Мы видим изменения информации в записи автора под номером 6.
DELETE
DELETE – SQL запрос, выполняя который в СУБД производится операция удаления определенной строки из таблицы в БД.
Обратимся к «tAuthors» с командой на удаление строки, где AuthorId = 5:
DELETE FROM tAuthors WHERE AuthorId = ‘5’;
Чтобы увидеть изменения, снова обратимся к базе для вывода всех записей:
SELECT * FROM tAuthors;
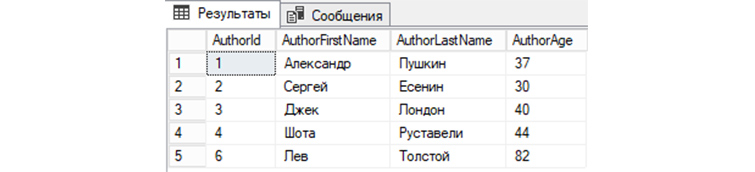
Мы видим, что запись автора под номером 5 теперь отсутствует в «tAuthors» и, соответственно, не выводится с другими записями.
DROP
DROP – ключевое слово в SQL, применяемое для удаления данных с помощью запроса. К примеру удаление некоторой таблицы из БД.
После рассмотрения ряда простых запросов к БД мы можем полностью удалить нашу таблицу «tAuthors целиком, выполнив простой SQL запрос:
DROP TABLE tAuthors;
Далее рассмотрим сложные запросы SQL.
Создание и настройка базы данных
Нам нужна будет для примеров БД MS SQL Server 2017 и MS SQL Server Management Studio 2017.
Рассмотрим последовательность действий того, как создать SQL запрос. Воспользовавшись Management Studio, для начала создадим новый редактор скриптов. Чтобы это сделать, на стандартной панели инструментов выберем «Создать запрос». Или воспользуемся клавиатурной комбинацией Ctrl+N.
Нажимая кнопку «Создать запрос» в Management Studio, мы открываем тестовый редактор, используя который можно производить написание SQL запросов, сохранять их и запускать.
Используем для начала простые запросы SQL, благодаря которым можно создать и настроить новую БД, чтобы получить возможность в дальнейшем с ней работать.
Создадим новую БД с именем «b_library для библиотеки книг. Чтобы это делать наберем в редакторе такой SQL запрос:
CREATE DATABASE b_library;
Далее выделим введенный текст и нажмем F5 или кнопку «Выполнить». У нас создастся БД «b_library.
Все дальнейшие манипуляции мы можем провести с этой созданной нами БД. Для этого сначала подключимся к этой базе:
USE b_library;
В БД «b_library создадим таблицу авторов «tAuthors» с такими столбцами: AuthorId, AuthorFirstName, AuthorLastName, AuthorAge:
CREATE TABLE tAuthors ( AuthorId INT IDENTITY (1, 1) NOT NULL, AuthorFirstName NVARCHAR (20) NOT NULL, AuthorLastName NVARCHAR (20) NOT NULL, AuthorAge INT NOT NULL );
Заполним нашу таблицу таким авторами: Александр Пушкин, Сергей Есенин, Джек Лондон, Шота Руставели и Рабиндранат Тагор. Для этого используем такой SQL запрос:
INSERT tAuthors VALUES (‘Александр’, ‘Пушкин’, ’37’), (‘Сергей’, ‘Есенин’, ’30’), (‘Джек’, ‘Лондон’, ’40’), (‘Шота’, ‘Руставели’, ’44’), (‘Рабиндранат’, ‘Тагор’, ’80’);
Мы можем посмотреть в «tAuthors» записи, путем отправления в СУБД простого SQL запроса:
SELECT * FROM tAuthors;
В нашей БД «b_library» мы создали первую таблицу «tAuthors», заполнили «tAuthors» авторами книг и теперь можем рассмотреть различные примеры SQL запросов, которыми мы сможем взаимодействовать с БД.
Создание новой базы данных MySQL
Новая база данных создается с помощью оператора SQL CREATE DATABASE, за которым следует имя создаваемой базы данных. Для этой цели также используется оператор CREATE SCHEMA. Например, для создания новой базы данных под названием MySampleDB в командной строке mysql нужно ввести следующий запрос:
CREATE DATABASE MySampleDB;
Если все прошло нормально, команда сгенерирует следующий вывод:
Query OK, 1 row affected (0.00 sec)
Если указанное имя базы данных конфликтует с существующей базой данных MySQL, будет выведено сообщение об ошибке:
ERROR 1007 (HY000): Can't create database 'MySampleDB'; database exists
В этой ситуации следует выбрать другое имя базы данных или использовать опцию IF NOT EXISTS. Она создает базу данных только в том случае, если она еще не существует:
CREATE DATABASE IF NOT EXISTS MySampleDB;
Подключение к экземпляру SQL Server
-
Запустите среду SQL Server Management Studio. При первом запуске SSMS откроется окно Подключение к серверу. Если этого не происходит, вы можете открыть его вручную, последовательно выбрав Обозреватель объектов > Подключить > Ядро СУБД.
-
Откроется диалоговое окно Соединение с сервером . Введите следующие сведения:
Параметр Рекомендуемые значения Описание Тип сервера Ядро СУБД В поле Тип сервера выберите Ядро СУБД (обычно это параметр по умолчанию). Имя сервера Полное имя сервера В поле Имя сервера введите имя SQL Server (при локальном подключении в качестве имени сервера также можно использовать localhost). Если вы НЕ ИСПОЛЬЗУЕТЕ экземпляр по умолчанию — MSSQLSERVER — необходимо ввести имя сервера и имя экземпляра. Если вы не знаете, как определить имя экземпляра SQL Server, см. раздел . Аутентификация Проверка подлинности Windows Проверка подлинности SQL Server По умолчанию используется проверка подлинности Windows. Также для подключения можно использовать режим Проверка подлинности SQL Server. Если выбран режим Проверка подлинности SQL Server, необходимо ввести имя пользователя и пароль. Дополнительные сведения о типах проверки подлинности см. в разделе Подключение к серверу (ядро СУБД). Имя входа Идентификатор пользователя учетной записи сервера Идентификатор пользователя учетной записи сервера, используемой для входа на сервер. Имя для входа, используемое для проверки подлинности SQL Server. Пароль Пароль учетной записи сервера Пароль учетной записи сервера, используемой для входа на сервер. Пароль, используемый для проверки подлинности SQL Server. -
После заполнения всех полей выберите Подключить.
Вы также можете изменить дополнительные параметры подключения, выбрав Параметры. Примеры параметров подключения: база данных, к которой вы подключаетесь, время ожидания подключения и сетевой протокол. В этой статье во всех полях указываются значения по умолчанию.
-
Чтобы убедиться в успешном подключении к экземпляру SQL Server, разверните и изучите объекты в обозревателе объектов, для которых отображаются имя сервера, версия SQL Server и имя пользователя. Эти объекты могут различаться в зависимости от типа сервера.
FOR BROWSE
BROWSE
Активирует возможность обновления данных во время их просмотра с помощью курсора в режиме обзора DB-Library. Таблицу можно просмотреть внутри приложения, если в таблице содержится столбец timestamp, таблице присвоен уникальный индекс или в конце инструкции SELECT, отсылаемой экземпляру SQL Server, имеется параметр FOR BROWSE.
Примечание
Нельзя использовать синтаксис <lock_hint> HOLDLOCK для инструкции SELECT, включающей в себя параметр FOR BROWSE.
Параметр FOR BROWSE не может быть использован в инструкциях SELECT, соединенных оператором UNION.
Примечание
Если ключевые столбцы уникального индекса таблицы могут принимать неопределенные значения, а таблица находится внутри внешнего соединения, индексы в режиме обзора не поддерживаются.
Режим просмотра позволяет просматривать строки в таблице SQL Server и обновлять данные в таблице по одной строке одновременно. Чтобы получить доступ к таблице SQL Server в приложении в режиме просмотра, необходимо использовать один из следующих вариантов.
-
Инструкция SELECT, применяемая для получения доступа к данным таблицы SQL Server, должна оканчиваться ключевыми словами FOR BROWSE. Если для использования режима просмотра включен параметр FOR BROWSE, создаются временные таблицы.
-
Необходимо выполнить следующую инструкцию Transact-SQL, чтобы включить режим просмотра с параметром NO_BROWSETABLE:
После включения параметра NO_BROWSETABLE все инструкции SELECT действуют так, как если бы к инструкциям был добавлен параметр FOR BROWSE. Однако параметр NO_BROWSETABLE не создает временные таблицы, которые обычно используются параметром FOR BROWSE, чтобы передать результаты в приложение.
Если предпринимается попытка получить доступ к данным таблиц SQL Server в режиме просмотра с помощью запроса SELECT, содержащего инструкцию внешнего соединения, и если определен уникальный индекс в таблице, которая присутствует во внутренней части инструкции внешнего соединения, в режиме просмотра не поддерживается уникальный индекс. В режиме просмотра уникальный индекс поддерживается, только если все ключевые столбцы уникального индекса могут принимать значения NULL. Уникальный индекс не поддерживается в режиме просмотра, если следующие условия являются истинными.
-
Предпринимается попытка получить доступ к данным таблиц SQL Server в режиме просмотра с использованием запроса SELECT, содержащего инструкцию внешнего соединения.
-
Уникальный индекс определен на таблице, которая присутствует во внутренней части инструкции внешнего соединения.
Чтобы воспроизвести это поведение в режиме просмотра, выполните следующие шаги.
В среде SQL Server Management Studio создайте базу данных с именем SampleDB.
В базе данных SampleDB создайте таблицы tleft и tright так, чтобы каждая содержала один столбец с именем c1. Определите уникальный индекс на столбце c1 в таблице tleft и предусмотрите, чтобы этот столбец принимал значения NULL. Чтобы это сделать, выполните в соответствующем окне запроса следующие инструкции Transact-SQL:
Вставьте несколько значений в таблицу tleft и таблицу tright. Обязательно вставьте значение NULL в таблицу tleft. Чтобы это сделать, выполните в окне запроса следующие инструкции Transact-SQL:
Включите параметр NO_BROWSETABLE. Чтобы это сделать, выполните в окне запроса следующие инструкции Transact-SQL:
Получите доступ к данным в таблице tleft и таблице tright с помощью инструкции внешнего соединения в запросе SELECT. Убедитесь, что таблица tleft находится во внутренней части инструкции внешнего соединения
Чтобы это сделать, выполните в окне запроса следующие инструкции Transact-SQL:
Обратите внимание на следующие выходные данные на панели «Результаты»:
c1
—-
NULL
NULL
После выполнения запроса SELECT для получения доступа к таблицам в режиме просмотра результирующий набор запроса SELECT содержит два значения NULL для столбца c1 в таблице tleft, поскольку таково определение инструкции правого внешнего соединения. Поэтому в результирующем наборе невозможно различить значения NULL, полученные из таблицы, и значения NULL, добавленные инструкцией правого внешнего соединения. Могут быть получены неверные результаты, если необходимо пропустить значения NULL из результирующего набора.
Примечание
Если столбцы, которые включены в уникальный индекс, не допускают значения NULL, это значит, что все значения NULL в результирующем наборе были добавлены инструкцией правого внешнего соединения.
Совет 9: Решайте задачи на программированиеTip 9 — Practice With Coding Challenges
Еще один отличный способ попрактиковаться и использовать язык SQL в действии — это решение задач по программированию. Существует множество веб-сайтов, предлагающих сложные задачи, призванные заставить вас задуматься над кодом, который вы пишете. Большинство из этих задач начинаются с набора четких инструкций, с заранее определенной отправной точкой и конечной целью, которую вы должны достичь.
Вам придется разобраться с проблемой и написать код, который позволит вам достичь окончательного решения. На некоторых сайтах есть рейтинговая система, с помощью которой вы можете узнать, насколько хорошо вы знаете язык SQL.
HackerRank — один из моих любимых сайтов, посвященных задачам по программированию. Они предлагают широкий спектр различных задач SQL-программирования, которые можно выполнить в любое время. Я думаю, что они вам также понравятся. HackerRank также проводит регулярные соревнования по программированию. Эти соревнования позволяют писать код с другими программистами в реальном времени. Обычно решение задачи носит ограниченное время, а победители часто получали денежные призы!
Вернёмся к SQL
Если читателю показалось, что мы ушли в сторону от SQL, так оно и есть. Но очень трудно понять, что такое SQL, не зная, с чем он работает.
Выходит, что SQL — это язык программирования, необходимый для написания команд к БД, после выполнения которых она вернёт результат. Результат будет зависеть от команды, написанной на SQL. Как в любом другом языке программирования, в SQL есть операторы для работы с данными, из которых складываются команды. Операторы распределены по четырём языкам:
- DDL — Data Definition Language;
- DML — Data Manipulation Language;
- DCL — Data Control Language;
- TCL — Transaction Control Language.
Виды баз данных и их структура, примеры
Выделяют несколько видов баз данных. Основными из них являются:
- Фактографическая, с краткой информацией об объектах какой-то системы, формат которой строго фиксирован.
- Документальная, включает документы разного вида, в том числе текстовые, графические, звуковые, мультимедийные.
- Распределенная, является базой данных с разными частями, которые хранятся на различных компьютерах, объединенных в сеть.
- Централизованная, представляет собой базу данных, местом хранения которой является один компьютер.
- Реляционная, имеет табличную организацию данных.
- Неструктурированная (NoSQL), является базой данных, в которой делается попытка решить проблемы масштабируемости и доступности с помощью атомарности и согласованности данных без четкой структуры.
Базы данных разных систем обладают неодинаковой структурой. Для ПЭВМ характерно использование реляционных баз данных с файлами в виде таблиц, в которых столбцы являются полями, а строки – записями. В базе данных находятся данные определенного множества объектов. Для каждой записи характерна информация по одному объекту. Такую базу определяют:
- имя файла;
- список полей;
- ширина полей.
В качестве примера можно привести школьную базу с данными «Ученик», «Класс», «Адрес». Также базой данных является расписание движения поездов или автобусов. В этом случае каждой строке соответствует запись с данными конкретного объекта. Возможные поля: номер рейса, маршрут, время отправления и прибытия. Классической базой данных является телефонный справочник.
Определение
Запрос к базе данных – предписание с указанием на данные, которые необходимы пользователю.
Примечание
В случае некоторых запросов требуется составление сложной программы. К примеру, для выполнения запроса к базе в виде автобусного расписания необходимо вычислить разницу в среднем интервале отправления транспорта из одного города во второй и из второго пункта в третий.
Существует три звена для создания приложения, с помощью которого можно просматривать и редактировать базы данных:
- набор данных;
- источник информации;
- визуальные компоненты управления.
В случае Access роль таких звеньев выполняют:
- Table.
- DataSource.
- DBGrid.
Приложения базы данных является нитью, которая связывает базу и пользователя:
БД => набор данных –=> источник данных => визуальные компоненты => пользователь
Набор данных:
- Table, в виде таблицы, навигационного доступа;
- Query, включая запрос, реляционный доступ.
Визуальными компонентами являются:
- Сетки DBGrid, DBCtrlGrid.
- Навигатор DBNavigator.
- Разные аналоги Lable, Edit.
- Компоненты подстановки.
Access характеризуется наличием следующих типов полей:
- текстовый, в виде текстовой строки с максимальной длиной до 255, заданной параметром «размер»;
- поле МЕМО, является текстом длиной до 65535 символов;
- числовой, в параметре «Размер поля» можно задать поле: байт, целое, действительное и другие;
- дата/время, необходимо для записи данных о времени;
- денежный, является специальным форматом для решения финансовых задач;
- счетчик, в виде автоинкрементного поля, который предназначен для ключевого поля, увеличивается на единицу после добавления новой записи и сохраняется в данное поле новой записи, что гарантирует разные значения для неодинаковых записей;
- логический, в виде «да или нет», «правда или ложь», «включен или выключен»;
- объект OLE, предназначен для хранения документов, картинок, звуков и другой информации, представляет собой частный случай BLOB, то есть полей (Binary Large Object), которые можно встретить в разных базах данных;
- гиперссылка, необходима для хранения ссылок на ресурсы в Интернете, характерна не для всех форматов баз данных, например, отсутствует в dBase и Paradox;
- подстановка.
Благодаря связи с обеспечением целостности таблиц осуществляется контроль удаления и модификации данных. С помощью монопольного доступа к базам данных в них производят фундаментальные изменения.
RDBMS
RDBMS stands for Relational Database Management System.
RDBMS is the basis for SQL, and for all modern database systems such as MS SQL Server, IBM DB2, Oracle, MySQL, and Microsoft Access.
The data in RDBMS is stored in database objects called tables. A table is a collection of related data entries and it consists of columns and rows.
Look at the «Customers» table:
Example
SELECT * FROM Customers;
Every table is broken up into smaller entities called fields. The fields in
the Customers table consist of CustomerID, CustomerName, ContactName, Address,
City, PostalCode and Country. A field is a column in a table that is designed to maintain
specific information about every record in the table.
A record, also called a row, is each individual entry that exists in a table.
For example, there are 91 records in the above Customers table. A record is a
horizontal entity in a table.
A column is a vertical entity in a table that contains all information
associated with a specific field in a table.
❮ Previous
Next ❯
AUTO_INCREMENT
Когда столбец определяется с помощью AUTO_INCREMENT, его значение автоматически увеличивается каждый раз, когда в таблицу добавляется новая запись. Это удобно при использовании столбца в качестве первичного ключа. Благодаря AUTO_INCREMENTне нужно писать инструкции SQL для вычисления уникального идентификатора для каждой строки.
AUTO_INCREMENT может быть присвоен только одному столбцу в таблице. И он должен быть проиндексирован (например, объявлен в качестве первичного ключа).
Значение AUTO_INCREMENT для столбца можно переопределить, указав новое при выполнении инструкции INSERT.
Можно запросить у MySQL самое последнее значение AUTO_INCREMENT, используя функцию last_insert_id() следующим образом:
SELECT last_insert_value();
Язык запросов SQL
База данных — централизованное хранилище данных, обеспечивающее хранение, доступ, первичную обработку и поиск информации.
Базы данных разделяются на:
- Иерархические
- Сетевые
- Реляционные
- Объектно-ориентированные
SQL (Structured Query Language) — представляет из себя структурированный язык запросов (перевод с английского). Язык ориентирован на работу с реляционными (табличными) базами данных. Язык прост и, по сути, состоит из команд (интерпретируемый), посредством которых можно работать с большими массивами данных (базами данных), удаляя, добавляя, изменяя информацию в них и осуществляя удобный поиск.
Для работы с SQL кодом необходима система управления базами данных (СУБД), которая предоставляет функционал для работы с базами данных.
Система управления базами данных (СУБД) — совокупность языковых и программных средств, предназначенных для создания, ведения и совместного использования БД многими пользователями.
Обычно, для обучения используется СУБД Microsoft Access, но мы будем использовать более распространенную в веб сфере систему — MySQL. Для удобства будет использовать веб-интерфейс или онлайн сервис для построения sql запросов , принцип работы с которыми описан ниже.
Важно: При работе с реляционными или табличными базами данных строки таблицы будем называть записями, а столбцы — полями.
Каждый столбец должен иметь свой тип данных, т.е. должен быть предназначен для внесения данных определенного типа. описаны в одном из уроков данного курса.
Составляющие языка SQL
Язык SQL состоит из следующих составных частей:
- язык манипулирования данными (Data Manipulation Language, DML);
- язык определения данных (Data Definition Language, DDL);
- язык управления данными (Data Control Language, DCL).
1.Язык манипулирования данными состоит из 4 главных команд:
- выборка данных из БД — SELECT
- вставка данных в таблицу БД — INSERT
- обновление (изменение) данных в таблицах БД —
- удаление данных из БД — DELETE
2.
Язык определения данных используется для создания и изменения структуры базы данных и ее составных частей — таблиц, индексов, представлений (виртуальных таблиц), а также триггеров и сохраненных процедур.
Мы будем рассматривать лишь несколько из основных команд языка. Ими являются:
- создание базы данных — CREATE DATABASE
- создание таблицы — CREATE TABLE
- изменение таблицы (структуры) — ALTER TABLE
- удаление таблицы — DROP TABLE
3.
Язык управления данными используется для управления правами доступа к данным и выполнением процедур в многопользовательской среде.
Совет 5: Учитесь сообща
Изучать язык SQL может быть довольно скучно, если вы попытаетесь сделать это самостоятельно. К сожалению, не каждый человек достаточно мотивирован и дисциплинирован, чтобы сидеть часами и учить себя чему-то сложному, например, SQL. Однако, хорошая новость в том, что есть много других людей, которые находятся в той же позиции, что и вы. Общение с этими людьми может помочь вам сохранить мотивацию, может помочь вам справиться с трудными проблемами и даже может привести к новым знакомствам!
Есть два основных способа, которыми вы можете связаться со своими коллегами, изучающими SQL. Первое — присоединиться к онлайн-форумам. В таких местах вы сможете задавать вопросы о проблемах, на которых вы застряли, а также использовать свои знания, чтобы помочь менее опытным разработчикам учиться. Microsoft Developer Network — отличное место, чтобы найти помощь по SQL. Кроме того, отправляйтесь в Reddit или поищите в Google форум язык SQL.
Второй — и, на мой взгляд, лучший вариант — это присоединиться к местной группе изучения SQL, в которой регулярно происходят события в реальном мире. Мой любимый способ поиска местных групп — Facebook и Meetup.com. Присоединитесь к группе, начните работать в сети и познакомьтесь с другими людьми, которые заинтересованы в SQL и управлении базами данных. Вы обнаружите, что это облегчит учебу, поможет найти людей, которые будут поддерживать вас в трудную минуту, и даже может в конечном итоге помочь вам найти работу!
Разграничения доступа на примерах Access и MySQL
Защита базы данных на уровне пользователя аналогична способам разграничения прав пользователей локальных сетей. В Access создают несколько рабочих групп, разделенных по интересам. Работа доступна одновременно с одной из баз данных. Можно параллельно работать в разных системах Access, если открыть их в отдельных окнах.
Файл рабочей группы создается автоматически. Он содержит информацию об учетной записи каждой группы или отдельного пользователя. Сохранение данных о правах доступа ведется по каждой учетке отдельно.
Рабочая группа состоит из двух групп:
- администратор;
- пользователи.
В случае необходимости возможно создание более двух групп пользователей данных. Один и тот же человек может состоять одновременно в разных группах. Каждому из сотрудников можно присвоить разные пароли.
Администратор получает максимальное число привилегий, группа пользователей работает в соответствии с их уровнем доступа.
Формы и отчеты Access можно защитить двумя способами:
1. Чтобы исключить случайное повреждение пользователем приложения, исключается использование режима Конструктора.
2. Скрытие некоторых полей таблицы от пользователей.
Таким образом появляется возможность контролировать использование секретных данных сотрудниками и ограничить доступ к ним посторонних. Расширить права пользователя или группы могут лишь админ и владелец информации (создатель). Имеется возможность передачи базы данных и прав на нее другому владельцу.
Одним из вариантов внедрения безопасной системы авторизации и регистрации является MySQL. Управление сервером происходит через Интернет с помощью РhpMyAdmin. Первый уровень защиты – это вход в БД через логин и пароль. Далее СУБД MySQL разграничивает права доступа. Доступ ограничивается как к системе управления, так и к каждому компоненту БД (таблица, строка, запись и т.п.). Владельцы БД имеют возможность шифровать информацию.
SQL References
SQL Keywords
ADD
ADD CONSTRAINT
ALTER
ALTER COLUMN
ALTER TABLE
ALL
AND
ANY
AS
ASC
BACKUP DATABASE
BETWEEN
CASE
CHECK
COLUMN
CONSTRAINT
CREATE
CREATE DATABASE
CREATE INDEX
CREATE OR REPLACE VIEW
CREATE TABLE
CREATE PROCEDURE
CREATE UNIQUE INDEX
CREATE VIEW
DATABASE
DEFAULT
DELETE
DESC
DISTINCT
DROP
DROP COLUMN
DROP CONSTRAINT
DROP DATABASE
DROP DEFAULT
DROP INDEX
DROP TABLE
DROP VIEW
EXEC
EXISTS
FOREIGN KEY
FROM
FULL OUTER JOIN
GROUP BY
HAVING
IN
INDEX
INNER JOIN
INSERT INTO
INSERT INTO SELECT
IS NULL
IS NOT NULL
JOIN
LEFT JOIN
LIKE
LIMIT
NOT
NOT NULL
OR
ORDER BY
OUTER JOIN
PRIMARY KEY
PROCEDURE
RIGHT JOIN
ROWNUM
SELECT
SELECT DISTINCT
SELECT INTO
SELECT TOP
SET
TABLE
TOP
TRUNCATE TABLE
UNION
UNION ALL
UNIQUE
UPDATE
VALUES
VIEW
WHERE
MySQL Functions
String Functions
ASCII
CHAR_LENGTH
CHARACTER_LENGTH
CONCAT
CONCAT_WS
FIELD
FIND_IN_SET
FORMAT
INSERT
INSTR
LCASE
LEFT
LENGTH
LOCATE
LOWER
LPAD
LTRIM
MID
POSITION
REPEAT
REPLACE
REVERSE
RIGHT
RPAD
RTRIM
SPACE
STRCMP
SUBSTR
SUBSTRING
SUBSTRING_INDEX
TRIM
UCASE
UPPER
Numeric Functions
ABS
ACOS
ASIN
ATAN
ATAN2
AVG
CEIL
CEILING
COS
COT
COUNT
DEGREES
DIV
EXP
FLOOR
GREATEST
LEAST
LN
LOG
LOG10
LOG2
MAX
MIN
MOD
PI
POW
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SUM
TAN
TRUNCATE
Date Functions
ADDDATE
ADDTIME
CURDATE
CURRENT_DATE
CURRENT_TIME
CURRENT_TIMESTAMP
CURTIME
DATE
DATEDIFF
DATE_ADD
DATE_FORMAT
DATE_SUB
DAY
DAYNAME
DAYOFMONTH
DAYOFWEEK
DAYOFYEAR
EXTRACT
FROM_DAYS
HOUR
LAST_DAY
LOCALTIME
LOCALTIMESTAMP
MAKEDATE
MAKETIME
MICROSECOND
MINUTE
MONTH
MONTHNAME
NOW
PERIOD_ADD
PERIOD_DIFF
QUARTER
SECOND
SEC_TO_TIME
STR_TO_DATE
SUBDATE
SUBTIME
SYSDATE
TIME
TIME_FORMAT
TIME_TO_SEC
TIMEDIFF
TIMESTAMP
TO_DAYS
WEEK
WEEKDAY
WEEKOFYEAR
YEAR
YEARWEEK
Advanced Functions
BIN
BINARY
CASE
CAST
COALESCE
CONNECTION_ID
CONV
CONVERT
CURRENT_USER
DATABASE
IF
IFNULL
ISNULL
LAST_INSERT_ID
NULLIF
SESSION_USER
SYSTEM_USER
USER
VERSION
SQL Server Functions
String Functions
ASCII
CHAR
CHARINDEX
CONCAT
Concat with +
CONCAT_WS
DATALENGTH
DIFFERENCE
FORMAT
LEFT
LEN
LOWER
LTRIM
NCHAR
PATINDEX
QUOTENAME
REPLACE
REPLICATE
REVERSE
RIGHT
RTRIM
SOUNDEX
SPACE
STR
STUFF
SUBSTRING
TRANSLATE
TRIM
UNICODE
UPPER
Numeric Functions
ABS
ACOS
ASIN
ATAN
ATN2
AVG
CEILING
COUNT
COS
COT
DEGREES
EXP
FLOOR
LOG
LOG10
MAX
MIN
PI
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SQUARE
SUM
TAN
Date Functions
CURRENT_TIMESTAMP
DATEADD
DATEDIFF
DATEFROMPARTS
DATENAME
DATEPART
DAY
GETDATE
GETUTCDATE
ISDATE
MONTH
SYSDATETIME
YEAR
Advanced Functions
CAST
COALESCE
CONVERT
CURRENT_USER
IIF
ISNULL
ISNUMERIC
NULLIF
SESSION_USER
SESSIONPROPERTY
SYSTEM_USER
USER_NAME
MS Access Functions
String Functions
Asc
Chr
Concat with &
CurDir
Format
InStr
InstrRev
LCase
Left
Len
LTrim
Mid
Replace
Right
RTrim
Space
Split
Str
StrComp
StrConv
StrReverse
Trim
UCase
Numeric Functions
Abs
Atn
Avg
Cos
Count
Exp
Fix
Format
Int
Max
Min
Randomize
Rnd
Round
Sgn
Sqr
Sum
Val
Date Functions
Date
DateAdd
DateDiff
DatePart
DateSerial
DateValue
Day
Format
Hour
Minute
Month
MonthName
Now
Second
Time
TimeSerial
TimeValue
Weekday
WeekdayName
Year
Other Functions
CurrentUser
Environ
IsDate
IsNull
IsNumeric
SQL Quick Ref
Итоги
- Имеются логические требования к данным, которые могут быть определены заранее.
- Очень важна целостность данных.
- Нужна основанная на устоявшихся стандартах, хорошо зарекомендовавшая себя технология, используя которую можно рассчитывать на большой опыт разработчиков и техническую поддержку.
- Требования к данным нечёткие, неопределённые, или развивающиеся с развитием проекта.
- Цель проекта может корректироваться со временем, при этом важна возможность немедленного начала разработки.
- Одни из основных требований к базе данных — скорость обработки данных и масштабируемость.