Яндекс вордстат: что это и для чего он нужен
Содержание:
Дополнительные возможности
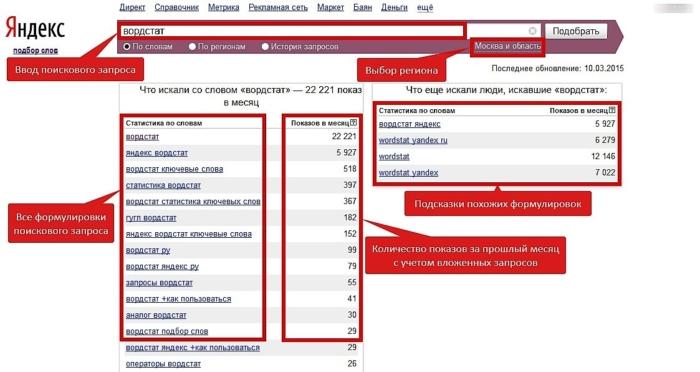
На иллюстрации выше, цифрами отмечены: 1 — сам запрос, 2 — дата обновления статистики Яндекса по данным фразам, 3 — суммарное число показов по фразам которые соответствуют запросу, 4 — общее число показов по фразе.
Здесь очень важно не путать общее число показов из колонки 4 и число точных запросов по фразе, которое можно получить с использованием операторов «Кавычки», «Восклицательный знак» и «Квадратные скобки». К дополнительным возможностям WordStat отнесем изучение истории (сезонности) спроса в тематике, получение частоты в заданном регионе и анализ популярности фраз в мобильном поиске (планшеты, мобильные телефоны)
К дополнительным возможностям WordStat отнесем изучение истории (сезонности) спроса в тематике, получение частоты в заданном регионе и анализ популярности фраз в мобильном поиске (планшеты, мобильные телефоны).
Данные функции часто оказываются полезны при планировании рекламных кампаний.
История запроса
Можно быстро понять, как меняется интерес к выходу новой модели «IPhone 6S». К сожалению, в текущий момент история запросов не поддерживает операторы («ИЛИ», «Группировка», «Квадратные скобки»).

Изучение динамики по запросу . Хорошо видны резкие сезонные всплески и провалы после наступления января.

Частота в заданном регионе
Отдельного упоминания заслуживает получение частоты запроса в заданном регионе. С помощью разделения общей частоты запроса по регионам можно оценить как частоту заданного запроса в интересующей нас регионе (Москва, Москва и область, Санкт-Петербург и т.д.), так и относительную популярность того или иного запроса в регионе.
Из примера приведенного ниже видно, что запросы со словами «купить» и «Казань» преимущественно задают жители г. Казань, что весьма очевидно. Использование данной функции на практике иногда открывает и более неожиданные закономерности.

Сбор (парсинг) запросов заданной длинны
На практике бывает полезным использовать приём парсинга запросов заданной длинны (из 2, 3, 4 слов и так далее) с вхождением ключевого слова. Данная возможность оказывается особенно актуальной, если вы работаете в популярной тематике и сбор первых 41 страниц не позволяет получить все поисковые фразы.

Для сбора всех фраз с длиной в 3 слова используется конструкция вида:
«IPhone IPhone IPhone»
Данный запрос позволяет собрать уже не просто 41 страницу поисковых фраз произвольной длины, а 41 страницу фраз из трёх слов с вхождением «IPhone». Последовательный анализ запросов с длиной от 2 до 7 слов позволяет существенно увеличить охват целевой аудитории.

Для ускорения сбора частот, быстрого парсинга Яндекс.Вордстат и хранения целевых ядер, рекомендуется использовать программы и онлайн-сервисы автоматизации, к числу которых можно отнести «Пиксель Тулс». После быстрой настройки параметров сбора, можно получить широкое семантического ядро в рамках тематики.
 Анализ проведён с помощью инструментов в сервисе Пиксель Тулс.
Анализ проведён с помощью инструментов в сервисе Пиксель Тулс.
Детальный анализ словоформ для ВЧ-запросов
Для ВЧ-запросов длиной в 2 и более слов может пригодиться анализ частоты встречаемости словоформ. Для этого требуется ввести исходную фразу, скажем, «продвижение сайтов» и далее последовательно исключать точные популярные написания с помощью комбинации операторов вида — -«», что приводит к исключению наиболее частотной формы написания из статистики и появлению второй по популярности версии. Далее процедуру можно повторить.

2. Способ ввода ключевых слов, синтаксис запроса
Яндекс
В поле ввода можно указывать только один запрос, минус-слова вводятся со знаком «-» через пробел (ноутбук выбрать -драйвера -ремонт -скачать). Число символов в строке ограничено, то есть широкие запросы не всегда удается хорошо «почистить» с помощью статистики ключевых слов на Яндексе.
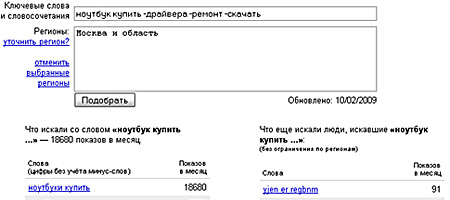
Рамблер
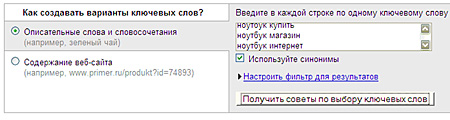
Есть возможность запрашивать статистику по нескольким фразам, каждая фраза размещается в отдельной строке, минус-слова вводятся со знаком «!» через пробел. Общие минус-слова для всех ключевых фраз можно ввести в самом конце со знаком «!»:
ноутбук купить !сумка
или
ноутбук купить
ноутбук магазин
ноутбук интернет
!сумка
Система запрещает употребление в запросах запятых, поэтому статистика по запросам типа, «yjen,er» (ноутбук в неверной раскладке), содержащих этот символ, не выдается.
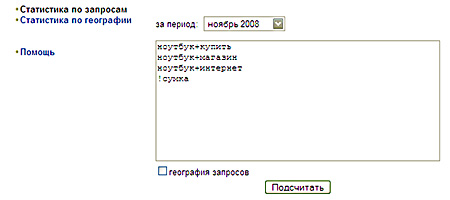
Бегун
В поле ввода можно ввести несколько запросов через Enter. Система не распознает минус-слова, игнорируются любые символы. То есть, к примеру, запрос «ноутбук -ремонт» тождественен запросу «ноутбук ремонт».
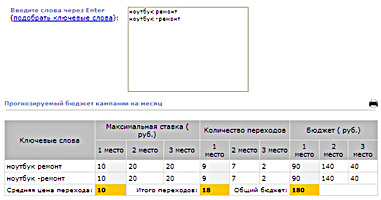
Предлагается 2 варианта подсказки ключевых слов: на основе введенных пользователем описательныхслов и словосочетаний или на основе содержания веб-сайта. В первом случае в поле ввода можно ввести несколько запросов через Enter, минус-слова вводятся со знаком «-» так же через Enter. Во втором случае надо ввести либо URL страницы, либо текст с сайта или из маркетинговых материалов, объем текста должен быть не слишком маленьким, чтобы система могла его проанализировать и выдать результаты.
Статистика поисковых запросов Яндекса
На сегодняшний день поисковая система Яндекс занимает лидирующие позиции в российском сегменте интернета. Для вебмастеров и оптимизаторов данная поисковая система создала специальный сервис – Яндекс Wordstat. Научившись правильно пользоваться данным сервисом, вы с легкостью сможете составить семантическое ядро вашего сайта, а также подобрать ключевые слова индивидуально для каждой новой статьи, публикуемой на вашем интернет-проекте.
К примеру, возьмем следующий запрос – «продвижение сайт».
Система выдала нам две колонки. Первая (левая) – это словарные наборы, в состав которых входит часть исходного ключевого слова, ну а вторая (правая) – это ассоциативные запросы. Во вторую колонку входят те слова, которые чаще всего вводили пользователи Яндекса до или после исходного запроса во время одной сессии. Используя эту информацию, можно значительно расширить свое семантическое ядро.
Для чего же нужен Яндекс Wordstat?
- Подбор ключевых слов для создания семантического ядра и продвижения сайта в целом.
- Анализ и аудит конкурентоспособности той или иной тематики потенциального интернет-проекта.
- Подбор и анализ релевантных ключевых слов.
Читатели часто путают два совершенно разных термина: ключевые слова и запросы. Проясним, в чем же различия.
- Запрос – это слово или словосочетание, которое пользователь поисковой системы вписывает в строку поиска. Различаются по типам и видам.
- Ключевое слово – это определенное слово или словосочетание, которое используется владельцами интернет-ресурсов или оптимизаторами для продвижения той или иной страницы и/или сайта. Ключевые слова имеют строгие правила вхождения, а если их не придерживаться, то поисковые системы могут применить к вам санкции (понижение позиций в поисковой выдаче или вовсе его вылет).
Чтобы узнать самые частые поисковые запросы по заданной тематике нужно выполнить следующий алгоритм:
- Зарегистрировать единый для всех сервисов поисковой системы Яндекса аккаунт и перейти на страницу сервиса Яндекс Wordstat.
- В специально отведенном поле ввести тематическое словосочетание и кликнуть кнопку «Подобрать».
Обратите внимание, что все полученные данные предоставляются вам за последний месяц (30 дней) и являются сезонными. Во время подбора наиболее популярных запросов вы также можете пользоваться специальными «операторами», которые поддерживаются Яндексом
Во время подбора наиболее популярных запросов вы также можете пользоваться специальными «операторами», которые поддерживаются Яндексом.
- Оператор кавычки («») – отвечает за частотность по определенному запросу.
- Оператор восклицательный знак (!) – предотвращает использование словоформ и выдает четкое ключевое слово.
- Оператор минус-слово (-) – позволяет убрать определенное слово из запроса. К примеру, указав запрос «книга по психологии -скачать» вы можете убрать слово «скачать».
- Оператор плюс-слово (+) – обратное действие предыдущего оператора, т.е. вы добавляете слово.
Чтобы работать с Вордстатом было удобнее, настоятельно рекомендуем установить плагин Yandex Wordstat Assistant.
Еще один способ значительно упростить работу со статистикой Яндекса – это использование бесплатной программы Словоёб и платной программы Key Colleсtor.
Для чего нужен парсинг частотности
Оценка объема трафика по определенным ключевым словам
Частотность в Яндекс.Вордстат отображает количество показов по выбранному ключевому слову за месяц в определенном регионе. С помощью этих данных можно примерно рассчитать потенциальный объем трафика, который можно получать в поисковой выдаче на разных позициях.
Сделать это можно так:
1. Соберите целевую семантику (список ключевиков, по которым вам нужно получать поисковой трафик). Собрать семантику можно с помощью медиапланера от Click.ru.
2. Спарсите частотность ключевых слов. Для примера мы возьмем ключевик «купить Samsung Galaxy в Москве» и проверим его частотность непосредственно в Вордстате. Итого, по данному запросу – 11757 показов в месяц.

3. Найдите в интернете средние значения CTR для каждой из позиций первой страницы поисковой выдачи.
Если ваш сайт добавлен в Яндекс.Вебмастер и работает как минимум несколько месяцев, данные по CTR будут доступны в отчете «Поисковые запросы» → «Все запросы и группы».

К примеру, CTR для второй позиции – 18%. Теперь мы можем посчитать примерный уровень трафика, который можем получить. Формула для расчета:
(Частотность * CTR)/100
Подставляем в формулу наши данные: (11 757 * 18)/100 = 2116.
Конечно, нет гарантии, что мы получим точно такое количество посещений, но для примерной оценки потенциала запроса такие расчеты будут очень полезными.
Еще одна причина для сбора частотности ключей – фильтрация запросов с околонулевой частотностью
Фразы, по которым нет показов (или показов совсем мало – от 1 до 10), лучше убрать из семантического ядра и не тратить время на оптимизацию страниц под такие запросы.
По ним практически не будет трафика, а если запускать контекстную рекламу, объявления получат статус «мало показов» и не будут показываться.
Обратите внимание! Иногда семантику с низкой частотностью не нужно исключать из ядра. Это касается узкоспециализированных тематик, например дорогого медицинского или производственного оборудования
Там ключевые запросы с указанием точной спецификации оборудования могут иметь всего пару запросов в месяц, но приводить максимально целевую и горячую аудиторию.
На что ориентироваться
В зависимости от ниши и типа сайта нижний порог частотности, по которому нужно отсекать бесперспективные запросы, отличается. Для ориентира можете использовать следующие данные:
|
Ниша |
Отсеиваем запросы с частотностью |
|
Узкие тематики |
|
|
Масс-маркет |
до 5 |
|
Информационные ресурсы |
до 30–35 |
При удалении низкочастотных фраз будьте внимательны: НЧ-запросы приводят качественный трафик, поэтому удаляйте фразы аккуратно, оставляя целевые.
Бесплатные парсеры
В Сети можно найти бесплатные версии парсеров, которые по заверениям разработчиков ничем не уступают вышеописанным программам и сервисам. Однако в большинстве случаев это «сырой» продукт с рядом недостатков – отсутствие обновлений, неудобный интерфейс, ограниченные функции. Низкая точность выборки, часто возникают ошибки. Причина – Яндекс.Вордстат постоянно изменяется, за этим нужно следить и вносить корректировки в ПО.
Если бесплатное использование является обязательным условием, можно скачать актуальные версии «Словоёб» или «Магадан». Альтернатива – воспользоваться возможностями «Букварикса» после регистрации.
Выбор парсеров зависит от поставленной задачи – объема ключевых фраз, точности выборки и дальнейшей обработки результатов. Для больших проектов рекомендуются платные версии, для ознакомления с возможностями и для составления СЯ для 1-3 сайтов – бесплатные.
Как работать с Вордстатом
Сервис подбора слов помогает просматривать обобщенную статистику по запросам, а также оценивать частотность в зависимости от различных факторов. В Wordstat также есть набор операторов, с помощью которых можно узнать реальное число запросов для определенной формы слова или фразы.
Фильтры
Чтобы посмотреть статистику в срезе по устройствам, используйте фильтр. Он доступен в каждом разделе. Wordstat разделяет мобильные устройства на телефоны и планшеты.

Для просмотра данных по разным регионам, нажмите «Все регионы». Откроется окно, где можно уточнить регион показов.

Переключитесь на вкладку «По регионам», чтобы узнать число показов страниц по запросам из конкретного города, страны или региона, а также по все регионам вместе. Здесь можно посмотреть статистику на карте, если удобно. Также можно применить фильтры по устройствам, чтобы сузить поиск.

Здесь доступны два столбца с цифрами:
- «показов в месяц» — количество показов из региона за месяц;
- «региональная популярность» — доля, которую занимает регион в показах по данному слову, деленная на долю всех показов результатов поиска в этом регионе.
100% — это среднее значение. Если оно меньше 100%, то интерес пользователей к этому слову понижен, и наоборот.
Яндекс уточняет, что региональная популярность — это affinity index в отчетах Яндекс.Метрики.
Следующий раздел в интерфейсе — «История запросов». В первую очередь он помогает подобрать слова для бизнесов, где ярко выражена сезонность и не получается собрать семантику на основе статистики за месяц. В «Истории запросов» показывается динамика показов за два года.
Статистику можно смотреть в абсолютных или относительных значениях. Для получения относительного значения абсолютная цифра нормируется на количество показов результатов поиска Яндекса за соответствующий месяц.

Операторы
Операторы в Wordstat помогают уточнить запросы и получить более детальную статистику по ним. Их можно применить только во вкладках «По словам» и «По регионам». Рассмотрим основные операторы, которые пригодятся специалисту на начальном этапе работе.
-
Кавычки фиксируют количество слов в запросе. Это помогает посмотреть, сколько раз пользователи вводили эту фразу. Система учитывает разный порядок слов и разные окончания. Повторяющиеся слова считаются за одно слово.
- Восклицательный знак нужен, чтобы посмотреть статистику по конкретной форме слова. Он ставится перед словом, которое не должно видоизменяться.
- С помощью оператора «Плюс» можно включать в запрос предлоги или другие служебные слова.
- «Минус» исключает слова из запроса.
- Если заключить ключевую фразу в квадратные скобки, система выдаст число запросов для фразы с сохранением порядка слов. При этом учитываются разные словоформы и предлоги.
Посмотрим на примеры использования. Если нужно узнать точное количество запросов исключительно по заданной фразе без дополнительных слов и без учета словоформ, нужно использовать два оператора: кавычки и восклицательный знак.

Чтобы исключить запросы, не совпадающие с тематикой продвижения, используйте оператор минус вместе с восклицательным знаком. Как в известном примере, вы не будете показывать рекламу бильярдного кия пользователям, которые интересуются покупкой машины Kia и ошиблись в правописании.

Как использовать Яндекс.Вордстат
Для начала разберемся с интерфейсом Яндекс.Вордстат, куда смотреть и на что тыкать.
Запросы: точные и похожие
В этом примере мы посмотрим, сколько человек ищут информацию про арбитраж трафика в Яндексе с помощью сервиса “Вордстат”, и что они набирают в поиске. Наш запрос будет таким → “Арбитраж трафика”.

Большая цифра в самом верху показывает, сколько человек искали информацию по теме арбитража
Первая колонка отображает все запросы в которых встречается словосочетание “Арбитраж трафика” в обычном или измененном виде. А вторая колонка предлагает похожие вопросы. Например, Яндекс.Вордстат на нашем скриншоте выше показал, что “арбитраж трафика” похож на “радиатор тепловоз”. Здесь должна быть шутка про завод, да?
На самом деле, когда вебмастер работает с более частотными запросами, вторая колоночка действительно выручает: показывает, что еще ищут вместе с объектом нашего исследования.
Сбор частот
Сбор частот позволяет оценить популярность запросов.

Сервис выдает кол-во показов запроса за последние 30 дней.
Статистика обновляется не ежедневно, поэтому не воспринимайте этот период буквально.

Сервис поддерживает различные операторы поиска, поэтому программа способна получать несколько видов частот.
Программа автоматически добавляет нужные операторы при сборе того или иного вида частот (добавлять операторы вручную к текст запросов не требуется).
Базовая частота
Базовая частота соответствует широкому типу вхождения слов. Для выполнения запроса достаточно отправить сам запрос в исходном виде:
- свежий хлеб
- условная вероятность
- теорема Байеса
В результатах могут быть учтены и другие фразы, косвенно относящиеся к запросу «свежий хлеб» в широком соответствии: купить свежий хлеб, свежий ржаной хлеб, рецепт хлеба, свежая выпечка и др.
Фразовая частота
Фразовая частота фиксирует состав слов в искомом запросе, и показы считаются для словосочетания целиком. Для выполнения запроса необходимо добавить двойные кавычки:
- «свежий хлеб»
- «теорема Байеса»
- «плотность распределения»
В результатах к запросу «свежий хлеб» будут учтены только фразы с тем же набором слов:: свежий хлеб, хлеба свежего и др.
Точная фразовая частота
Точная фразовая частота фиксирует не только состав, но и словоформы слов в искомом запросе. Для выполнения запроса необходимо добавить оператор ! перед каждым словом в запросе и взять его в двойные кавычки:
- «!свежий !хлеб»
- «!теорема !Байеса»
- «!плотность !распределения»
В результатах к запросу «!свежий хлеб!» будут учтены только фразы с тем же набором слов в той же словоформе: свежий хлеб, хлеб свежий (порядок не фиксируется).
Точная фразовая частота с порядком
Точная фразовая с порядком частота фиксирует состав, словоформы и порядок следования слов в искомом запросе. Для выполнения запроса необходимо добавить оператор ! перед каждым словом в запросе, взять его в и двойные кавычки:
- «!свежий !хлеб»
- «!теорема !Байеса»
- «!плотность !распределения»
В результатах к запросу «!свежий хлеб!» будут учтены только фразы с тем же набором слов в той же словоформе и том же порядке следования: свежий хлеб.
Частота по маске
Вы можете самостоятельно определить маску запроса, используя поддерживаемые сервисом операторы.
Маска запроса должна содержать фрагмент QUERY, который при сборе частот будет заменяться на текст исследуемого запроса.
Как узнать о самых популярных запросах в Яндексе
В одном из примеров выше, я намеренно продемонстрировал пример с порядком слов, чтобы лучше разобраться – как формируются популярные фразы. То есть, получается – есть длинные фразы, есть короткие. При этом, разный порядок слов в ключе – имеет свою частоту запросов. И не имеет значения – короткая фраза или длинная. Её популярность на поиске, может быть абсолютно разной.

В зависимости от региона, выдача может и более правильную выдачу по популярным направлениям, обычно смотрят по региону Москва и Московская область. Регион можно указать через расширенный поиск на главной странице Яндекса, или кликнув по элементу настройки поиска:

Чтобы лучше понять правильную словоформу слова (которая чаще всего запрашивается), начните вводить запрос в поисковой строке. Уже при вводе первых букв, будут появляться первые подсказки. Рекомендую закончить слово, и нажать пробел. Отобразятся разные по длине поисковые подсказки.
Ориентируясь на длинные поисковые фразы в трафиковом сегменте, Ваша работа может стать более эффективной. Не просто “сырники рецепт”, а “сырники из творога рецепт классический на сковороде”

Мы изначально понимаем, что сырники – это очень популярное направление, среди рецептов. По-общему число показов, цифра внушительная.

Далее, ориентируясь только на поисковые подсказки из Яндекса, мы можем проверить любую из фраз.

Выдача нам подсказывает, что уточняющее слово более частотное, чем запрос в одно слово.

Простыми словами, подсказки уже имеют правильное расположение слов в запросе, тем самым подсказывая нам о популярности того или иного запроса
Я бы рекомендовал обращать внимание на уточняющие фразы, состоящие от 4 и более слов

С технической точки зрения запросов, и простоты продвижения под них, эффективнее будет выбрать более длинный запрос вида: “сырники из творога рецепт классический на сковороде”, нежели который стоит выше (сырники из творога рецепт), и имеет большую частоту по спросу, но меньшее число слов в запросе.

Всё дело в том, что такие запросы – более направленные, и под них можно сделать более релевантную статью. Более того, длинные запросы в популярных темах, имеют большой хвост запросов, нежели ограничиваться короткой частотной фразой, с ограниченной длиной
На практике часто случается обратное – когда мы берем во внимание длинные фразы, то по ним проще выйти в топ Яндекса. А уже от полезности статьи, и других её внешних и внутренних факторов, она может приводить трафик по другим, более частотным запросам в этой теме
Простыми словами – длинные фразы, в темах со спросом – более эффективны, чем короткие фразы. В примере выше, это первая выдача. Есть ещё вторая и третья.
“Кулинария – Рецепты – Узнаем самые популярные рецепты – Смотрим выдачу – Выбираем топовые ключи”
И такой принцип, можно применять для любой темы. Есть популярное общее направление, и нужно двигаться к конкретике. Есть “сырники”, а есть “пышные сырники из творога на сковороде”. Публикация статей в конкретных направлениях – более эффективна, нежели работать на общие одиночные, или даже общие длинные фразы. Даже длинные фразы, также рекомендуется группировать, чтобы дать более точный ответ, на собранную группу фраз посетителя. При этом, это не значит, что нужно углубляться во вторую и третью выдачу, в поисках длинных фраз.
В мануале из Школы Блогеров, показал технику, по которой можно находить эффективные темы и ключевые слова для кулинарных блогов + как составлять эффективные заголовки. Принципы подходят для других тематик. Доступно внутри.

Кстати! Если Вас ещё нет в моём Телеграм канале – Хочу в Блогеры, добро пожаловать: https://t.me/foodblogerpro (это бесплатная группа ожидания, среди желающих записаться в Школу Блогеров Дениса Повага)
5. Особенности инструментов, плюсы и минусы
Яндекс
Плюсы. Неотъемлемым плюсом является учет морфологии слов
Это важное отличие данного инструмента от других подобных. Это сокращает время на дальнейшую обработку полученных данных, мы сразу получаем необходимый нам результат
Плюсом следует назвать возможность выбора гео прежде, чем приступить к подбору слов. Полученные данные выдаются уже с учетом выбранных регионов. Полезным является и колонка справа, которую можно использовать как подсказку, а также возможность просмотра статистики по месяцам. Отслеживание тенденций спроса очень важно при прогнозе.
Минусы. После многократного использования инструмента выдается сообщение о том, что исчерпан лимит запросов, и при каждом последующем обращении требуется вводить символы с картинки. Этого можно избежать, авторизовавшись на Яндексе. Хочется также отметить, что иногда встречаются ошибки: не отображается кол-во показов или показы отображаются без учета гео. Недостатком можно назвать ограничение по символам в строке ввода запроса, часто это усложняет и замедляет процесс подбора слов. То же самое можно сказать и про отсутствие возможности автоматического добавления минус-слов в строку ввода из предлагаемого списка запросов. Кроме того отсутствует возможность выгружать полученные данные в файл.
Рамблер
Плюсы. Возможность посмотреть статистику по показам на первой странице поиска и на всех страницах. Благодаря этому мы можем узнать, сколько раз было показано объявление при переходе пользователя по страницам выдачи в поисковике. Это в большей степени интересно для анализа поведения пользователей.
Минусы. Нет возможности предварительно настроить гео и не учитывается морфология слов. Следует отметить, что без авторизации в системе срабатывает ограничение на кол-во вводимых запросов, кроме того не доступна статистика по географии. Хотелось бы, чтобы в ответ на запрос предлагались не только фразы, содержащие ключевое слово, но и схожие по смыслу, синонимы, неверные написания и т.п. В этом инструменте тоже нет возможности выгружать полученные данные в файл.
Бегун
Плюсы. Плюсом является возможность выбора регионов прежде, чем приступить к подбору слов. Полезно и то, что инструмент выдает информацию о ставках, что может помочь при планировании бюджета. Наличие подсказок по ключевым словам и их быстрое добавления в поле ввода для расчета.
Минусы. Следует отметить тот факт, что доступ к инструменту можно получить только войдя под агентским логином. Инструмент не распознает минус-слова, не учитывает морфологию слов, не предлагает список словосочетаний, содержащих введенные нами запросы, не предоставляет информацию о показах по ключевым словам. Ещё один минус в том, что нет возможности выгружать полученные данные в файл.
Плюсы. Есть возможность выбора регионов и языков прежде, чем приступить к подбору слов. Особенностью инструмента можно назвать возможность подбора слов на основе статьи или сайта. Есть данные по средней цене за клик. Есть настройка фильтров для результатов: использовать синонимы при формировании выдаваемого списка слов, показывать данные только по введенным ключевым словам без добавления новых и интригующий пункт «Включить содержание для взрослых в результаты поиска по моему ключевому слову». Отличительная особенность этого инструмента ещё и в том, что все данные из таблицы можно выгрузить в файл. Google позаботился о своих пользователях и разместил подробную инструкцию к использованию:
- https://adwords.google.com/support/bin/answer.py?answer=25918
- https://adwords.google.com/support/bin/answer.py?answer=25148
Минусы. Инструмент плохо адаптирован под русский язык, для полноты информации недостаточно накопленной статистики. Большое множество ответов «Нет данных» или «Недостаточно данных» возникает при указании русского языка и таргетинга на РФ. При нацеливании на западные страны или выборе других языков картина резко меняется, информации становится гораздо больше. Инструмент обладает широким набором статистических данных и функций, но, к сожалению, недоработан и плохо адаптирован для русскоязычного использования, хотелось бы изменений в этом направлении.
Проверка частотности: 80 lvl
Переходим к более сложным тонкостям сбора статистики по запросам из Яндекса.
Пример #1
Начнем с оператора » » и сформулируем одно правило его использования: если во фразе, заключенной в кавычки, присутствуют одинаковые предлоги или слова, то одно из них заменяется на существующее слово во вложенном запросе. Для примера рассмотрим запрос «автомобиль в кредит москва».

Если добавить в данное ключевое слово еще один предлог «в» перед словом «москва», то получим следующие данные.

Таким образом повторяющиеся предлоги «в» были объединены, и к запросам добавилось еще одно слово. Для разных запросов это слова «купить», «бу», «новый», «залог», подержанные». «оформить».
Этот прием — невероятный инструмент для информационный сайтов, основной целью которых является рост трафика. Он позволяет выбрать из тематики весь диапазон запросов, которые включают в себя заданное количество слов, например, все запросы по тематике из 5 слов. Как правило, очень расширенные запросы из 5-7 слов бывают менее конкурентными, соответственно привлечь трафик и занять высокие позиции по ним легче. А если эти запросы не уступают в показах высокочастотным запросам? Выборка наиболее высокочастотных и наименее конкурентных запросов позволит вам быстро добиться результата. Давайте рассмотрим пример.

В данном запросе мы просим WordStat показать диапазон запросов, который включает в себя 7 слов, обязательно содержащих слова «инструкция по применения». 5 слов «инструкция» объединяются, остается одно, 4 слова заменяются на новые вложенные запросы. Смотрим один из сотен вложенных запросов, частотность запроса из 7 слов — 8090 показов в месяц. Для сравнению запрос «купить автомобиль в москве» имеет 647 показов в месяц. Разрыв шаблона еще не произошел? Тогда идем дальше.

Пример #2
Сейчас пойдет в бой более сложный оператор () и |, с его помощью мы соберем пул запросов, из которого в дальнейшем сможем сделать теговые страницы. Возьмем для примера запрос «купить автомобиль bmw». Данную марку авто, ее серии могут искать по самым разным запросам: «купить машину бмв», «купить bmw икс 6», «купить автомобиль бмв 5» и т.п. Для того чтобы получить пул запросов без повторений, используем регулярное выражение:
купить (автомобиль|машина) (бмв|bmw) -пробегом -фото -не -заводится -скачать -бу -какая
Добавим в него сразу ряд нерелевантных минус-слов, которые не подходят для нашего бизнеса. Получаем следующие данные, которые впоследствие проще структурировать.

Данная выборка поможет вам проще собрать данные для теговых страниц и кластеризации данных.
Обратите внимание, нельзя в одном выражении использовать операторы » » и ( ) |. Логика работы одного оператора нарушает логику работы другого
Пример #3
рыбалка (+с|+на) -игра -бесплатная -скачать -русские -охота
Минус-слова, конечно же, нужно добавить, но в данном случае это просто пример. Получаем вот такой результат:

Пример #4
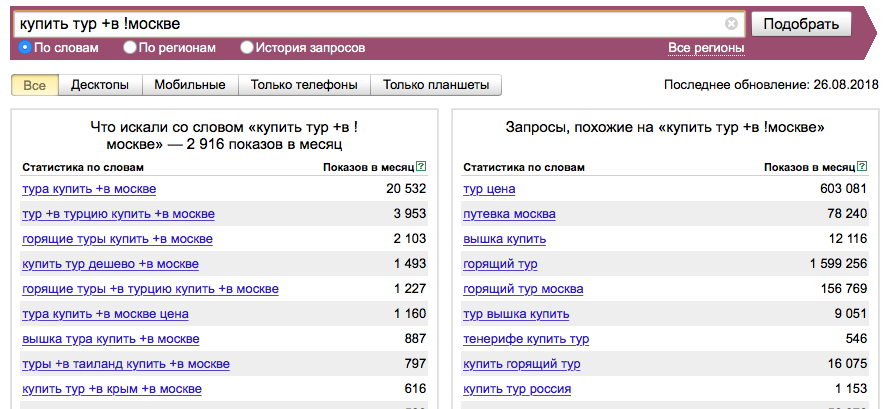
Совместное использование операторов поможет вам разграничить похожие по написанию, но разные по смыслу запросы. Например, запрос «купить тур в москвУ» подразумевает экскурсионную поезду в Москву.

Запрос «купить тур в москвЕ» подразумевает учет геопозиции пользователя для покупки тура из Москвы.
Пример #5
Еще один пример регулярного выражения, которое поможет вам собрать запросы для теговых страниц или фильтров каталога в нише купальников.

Даже если данные примеры не относятся к вашей нише, надеемся они помогут вам улучшить свои навыки работы с WordStat. Если у вас возникли вопросы, вы нашли ошибки, либо хотите дополнить статью, пожалуйста, пишите в комментарии, мы с радостью ответим вам!