Javascript свойство xmlhttprequest.responsetype
Содержание:
Основы
XMLHttpRequest имеет два режима работы: синхронный и асинхронный.
Сначала рассмотрим асинхронный, так как в большинстве случаев используется именно он.
Чтобы сделать запрос, нам нужно выполнить три шага:
-
Создать .
-
Инициализировать его.
Этот метод обычно вызывается сразу после . В него передаются основные параметры запроса:
- – HTTP-метод. Обычно это или .
- – URL, куда отправляется запрос: строка, может быть и объект URL.
- – если указать , тогда запрос будет выполнен синхронно, это мы рассмотрим чуть позже.
- , – логин и пароль для базовой HTTP-авторизации (если требуется).
Заметим, что вызов , вопреки своему названию, не открывает соединение. Он лишь конфигурирует запрос, но непосредственно отсылается запрос только лишь после вызова .
-
Послать запрос.
Этот метод устанавливает соединение и отсылает запрос к серверу. Необязательный параметр содержит тело запроса.
Некоторые типы запросов, такие как , не имеют тела. А некоторые, как, например, , используют , чтобы отправлять данные на сервер. Мы позже увидим примеры.
-
Слушать события на , чтобы получить ответ.
Три наиболее используемых события:
- – происходит, когда получен какой-либо ответ, включая ответы с HTTP-ошибкой, например 404.
- – когда запрос не может быть выполнен, например, нет соединения или невалидный URL.
- – происходит периодически во время загрузки ответа, сообщает о прогрессе.
Вот полный пример. Код ниже загружает с сервера и сообщает о прогрессе:
После ответа сервера мы можем получить результат запроса в следующих свойствах :
- Код состояния HTTP (число): , , и так далее, может быть в случае, если ошибка не связана с HTTP.
- Сообщение о состоянии ответа HTTP (строка): обычно для , для , для , и так далее.
- (в старом коде может встречаться как )
- Тело ответа сервера.
Мы можем также указать таймаут – промежуток времени, который мы готовы ждать ответ:
Если запрос не успевает выполниться в установленное время, то он прерывается, и происходит событие .
URL с параметрами
Чтобы добавить к URL параметры, вида , и корректно закодировать их, можно использовать объект URL:
Как это устроено
Если мы хотим хранить данные на сервере и отправлять их туда в любой момент, нам нужно действовать так:
- Собрать данные в JSON-формат.
- Упаковать их в специальный запрос.
- Встроенными средствами JavaScript отправить этот запрос на сервер по нужному адресу.
- Чтобы наш запрос был принят, по этому адресу на сервере должен находиться скрипт, который умеет работать с такими запросами.
- А чтобы сервер в принципе отвечал на какие-то запросы, нам нужно его этому обучить.
Первые три пункта сделаем на клиенте — нашей HTML-странице, а скрипт и настройки — на сервере. Скрипт будем писать на PHP, поэтому, если не знаете, что это и как с этим работать, — почитайте.
Чтобы было проще, мы отправим и обработаем на сервере совсем маленький JSON — в нём всего две пары «имя: значение», но даже со сложным запросом всё будет работать так же.
Контроль безопасности
Кросс-доменные запросы проходят специальный контроль безопасности, цель которого – не дать злым хакерам завоевать интернет.
Серьёзно. Разработчики стандарта предусмотрели все заслоны, чтобы «злой хакер» не смог, воспользовавшись новым стандартом, сделать что-то принципиально отличное от того, что и так мог раньше и, таким образом, «сломать» какой-нибудь сервер, работающий по-старому стандарту и не ожидающий ничего принципиально нового.
Давайте, на минуточку, вообразим, что появился стандарт, который даёт, без ограничений, возможность делать любой странице HTTP-запросы куда угодно, какие угодно.
Как сможет этим воспользоваться злой хакер?
Он сделает свой сайт, например и заманит туда посетителя (а может посетитель попадёт на «злонамеренную» страницу и по ошибке – не так важно). Когда посетитель зайдёт на , он автоматически запустит JS-скрипт на странице
Этот скрипт сделает HTTP-запрос на почтовый сервер, к примеру,. А ведь обычно HTTP-запросы идут с куками посетителя и другими авторизующими заголовками
Когда посетитель зайдёт на , он автоматически запустит JS-скрипт на странице. Этот скрипт сделает HTTP-запрос на почтовый сервер, к примеру, . А ведь обычно HTTP-запросы идут с куками посетителя и другими авторизующими заголовками.
Поэтому хакер сможет написать на код, который, сделав GET-запрос на , получит информацию из почтового ящика посетителя. Проанализирует её, сделает ещё пачку POST-запросов для отправки писем от имени посетителя. Затем настанет очередь онлайн-банка и так далее.
Спецификация CORS налагает специальные ограничения на запросы, которые призваны не допустить подобного апокалипсиса.
Запросы в ней делятся на два вида.
считаются запросы, если они удовлетворяют следующим двум условиям:
- : GET, POST или HEAD
- – только из списка:
- со значением , или .
«Непростыми» считаются все остальные, например, запрос с методом или с заголовком не подходит под ограничения выше.
Принципиальная разница между ними заключается в том, что «простой» запрос можно сформировать и отправить на сервер и без XMLHttpRequest, например при помощи HTML-формы.
То есть, злой хакер на странице и до появления CORS мог отправить произвольный GET-запрос куда угодно. Например, если создать и добавить в документ элемент , то браузер сделает GET-запрос на этот URL.
Аналогично, злой хакер и ранее мог на своей странице объявить и, при помощи JavaScript, отправить HTML-форму с методом GET/POST и кодировкой . А значит, даже старый сервер наверняка предусматривает возможность таких атак и умеет от них защищаться.
А вот запросы с нестандартными заголовками или с методом таким образом не создать. Поэтому старый сервер может быть к ним не готов. Или, к примеру, он может полагать, что такие запросы веб-страница в принципе не умеет присылать, значит они пришли из привилегированного приложения, и дать им слишком много прав.
Поэтому при посылке «непростых» запросов нужно специальным образом спросить у сервера, согласен ли он в принципе на подобные кросс-доменные запросы или нет? И, если сервер не ответит, что согласен – значит, нет.
В спецификации CORS, как мы увидим далее, есть много деталей, но все они объединены единым принципом: новые возможности доступны только с явного согласия сервера (по умолчанию – нет).
Кодировка multipart/form-data
Кодировка urlencoded за счёт замены символов на может сильно «раздуть» общий объём пересылаемых данных. Поэтому для пересылки файлов используется другая кодировка: multipart/form-data.
В этой кодировке поля пересылаются одно за другим, через строку-разделитель.
Чтобы использовать этот способ, нужно указать его в атрибуте и метод должен быть POST:
Форма при такой кодировке будет выглядеть примерно так:
…То есть, поля передаются одно за другим, значения не кодируются, а чтобы было чётко понятно, какое значение где – поля разделены случайно сгенерированной строкой, которую называют «boundary» (англ. граница), в примере выше это :
Сервер видит заголовок , читает из него границу и раскодирует поля формы.
Такой способ используется в первую очередь при пересылке файлов, так перекодировка мегабайтов через urlencoded существенно загрузила бы браузер. Да и объём данных после неё сильно вырос бы.
Однако, никто не мешает использовать эту кодировку всегда для POST запросов. Для GET доступна только urlencoded.
HTTP-headers
allows both to send custom headers and read headers from the response.
There are 3 methods for HTTP-headers:
-
Sets the request header with the given and .
For instance:
Headers limitations
Several headers are managed exclusively by the browser, e.g. and .
The full list is .is not allowed to change them, for the sake of user safety and correctness of the request.
Can’t remove a header
Another peculiarity of is that one can’t undo .
Once the header is set, it’s set. Additional calls add information to the header, don’t overwrite it.
For instance:
-
Gets the response header with the given (except and ).
For instance:
-
Returns all response headers, except and .
Headers are returned as a single line, e.g.:
The line break between headers is always (doesn’t depend on OS), so we can easily split it into individual headers. The separator between the name and the value is always a colon followed by a space . That’s fixed in the specification.
So, if we want to get an object with name/value pairs, we need to throw in a bit JS.
Like this (assuming that if two headers have the same name, then the latter one overwrites the former one):
Заголовки ответа
Чтобы JavaScript мог прочитать HTTP-заголовок ответа, сервер должен указать его имя в Access-Control-Expose-Headers.
Например:
HTTP/1.1 200 OK Content-Type:text/html; charset=utf-8 Access-Control-Allow-Origin: http://site.ru X-Uid: 123 X-Authorization: 2c9de507f2c54aa1 Access-Control-Expose-Headers: X-Uid, X-Authentication
По умолчанию скрипт может прочитать из ответа только «простые» заголовки:
Cache-Control Content-Language Content-Type Expires Last-Modified Pragma
То есть, Content-Type получить всегда можно, а доступ к специфическим заголовкам нужно открывать явно.
Пример использования
<!DOCTYPE html>
<html>
<head>
<title>Использование JavaScript методов open() и send() объекта XMLHttpRequest</title>
</head>
<body>
<button onclick = "getPhone()">Запросить телефон</button> <!-- добавляем атрибут событий onclick -->
<div id = "demo"></div>
<script>
function getPhone() {
let xhr = new XMLHttpRequest(); // инициализируем переменную новым объектом XMLHttpRequest
xhr.open("GET", "user.json"); // определяем параметры для запроса
xhr.send(); // отправляем запрос на сервер
xhr.onreadystatechange = function() {
// проверяем состояние запроса и числовой код состояния HTTP ответа
if (this.readyState == 4 && this.status == 200) {
const data = JSON.parse(this.responseText); // анализируем строку в формате JSON и инициализируем переменную значением, полученным в ходе анализа
document.getElementById("demo").innerHTML = "Телефон пользователя: " + data.phone; // находим элемент по id и изменяем его содержимое значением ключа объекта, содержащегося в переменной
}
};
}
</script>
</body>
</html>
В этом примере с использованием атрибута событий onclick при нажатии на кнопку (HTML элемент <button>) вызываем функцию getPhone, которая:
Вызывает конструктор объекта XMLHttpRequest и инициализирует переменную новым объектом этого типа.
С помощью метода open() объекта XMLHttpRequest определяем параметры для запроса — указываем, что HTTP запрос будет осуществлен методом «GET», а в качестве URL адреса на который будет отправлен запрос мы задаем файл формата json
Обратите внимание, что файл размещен на том же сервере и в том же каталоге, что и документ с которого выполняется скрипт. Файл имеет следующий вид:
{
«firstName»: «Василий»,
«lastName»: «Джейсонов»,
«age»: 25,
«phone»: 88005553535
}
С помощью метода send() объекта XMLHttpRequest отправляем запрос на сервер.
С использованием обработчика событий onreadystatechange, вызываемого при запуске события readystatechange, то есть при каждом изменении свойства readyState объекта XMLHttpRequest мы вызываем функцию, которая проверяет состояние запроса, оно должно соответствовать значению 4 (операция полностью завершена) и числовой код состояния HTTP ответа (свойство status) должен соответствовать значению 200 (успешный запрос)
Если условия выполнены, то с использованием метода JSON.parse() анализируем строку в формате JSON и инициализируем переменную значением, полученным в ходе анализа. После этого с помощью метода getElementById() находим элемент с определенным глобальным атрибутом id и изменяем его содержимое значением ключа объекта, содержащегося в инициализированной ранее переменной.
Результат нашего примера:
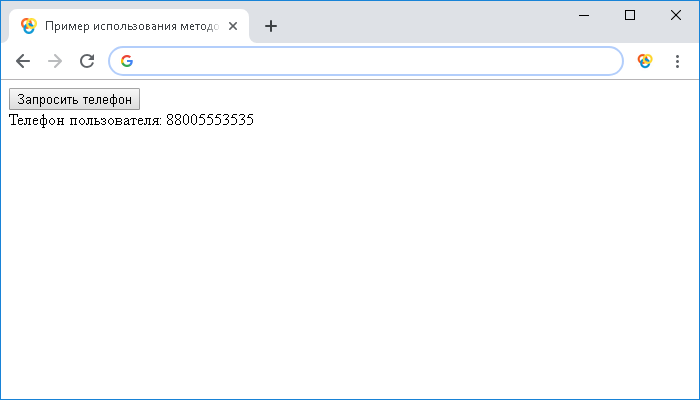
Пример использования методов open() и send() объекта XMLHttpRequestJavaScript XMLHttpRequest
Old Browsers (IE5 and IE6)
Old versions of Internet Explorer (IE5 and IE6) do not support the
XMLHttpRequest object.
To handle IE5 and IE6,
check if the browser supports the XMLHttpRequest object, or else create an ActiveXObject:
Example
if (window.XMLHttpRequest) { // code for modern browsers
xmlhttp = new XMLHttpRequest();
}
else { // code for old IE browsers
xmlhttp = new ActiveXObject(«Microsoft.XMLHTTP»);
}
Old versions of Internet Explorer (IE5 and IE6) do not support the DOMParser object.
To handle IE5 and IE6,
check if the browser supports the DOMParser object, or else create an ActiveXObject:
Example
if (window.DOMParser) { // code for modern browsers
parser = new DOMParser();
xmlDoc = parser.parseFromString(text,»text/xml»);
}
else {
// code for old IE browsersxmlDoc = new ActiveXObject(«Microsoft.XMLDOM»);
xmlDoc.async = false;
xmlDoc.loadXML(text);
}
Методы интерфейса
| Метод | Описание | Chrome | Firefox | Opera | Safari | IExplorer | Edge |
|---|---|---|---|---|---|---|---|
| abort() | Позволяет прервать запрос, если он уже был отправлен. | Да | Да | Да | Да | Да | Да |
| getAllResponseHeaders() | Возвращает все заголовки ответа, разделенные разрывом строки (CRLF) в виде строки или null, если ответ не был получен. | Да | Да | Да | Да | Да | Да |
| getResponseHeader() | Возвращает строку, содержащую текст указанного заголовка, или null, если ответ еще не был получен, или заголовок не существует в ответе. | Да | Да | Да | Да | Да | Да |
| open() | Позволяет инициализировать только что созданный запрос, или повторно инициализировать существующий запрос. | Да | Да | Да | Да | Да | Да |
| overrideMimeType() | Позволяет переопределить MIME тип, возвращаемый сервером (задает тип MIME, отличный от того, который предоставляется сервером для использования при интерпретации данных, передаваемых в запросе). | Да | Да | Да | Да | 11.0* | Да |
| send() | Позволяет отправить запрос на сервер. | Да | Да | Да | Да | Да | Да |
| setRequestHeader() | Задает значение заголовка HTTP запроса. | Да | Да | Да | Да | Да | Да |
Интерфейсы веб API
Использование XMLHTTPRequest
Различают два использования XmlHttpRequest. Первое — самое простое, синхронное.
Синхронный XMLHttpRequest
В этом примере через XMLHTTPRequest с сервера запрашивается страница http://example.org/, и текст ответа сервера показывается через alert().
var xmlhttp = getXmlHttp()
xmlhttp.open('GET', '/xhr/test.html', false);
xmlhttp.send(null);
if(xmlhttp.status == 200) {
alert(xmlhttp.responseText);
}
Здесь сначала создается запрос, задается открытие () синхронного соединение с адресом /xhr/test.html и запрос отсылается с null,
т.е без данных.
При синхронном запросе браузер «подвисает» и ждет на строчке 3, пока сервер не ответит на запрос. Когда ответ получен — выполняется строка 4, код ответа сравнивается с 200 (ОК), и при помощи alert
печатается текст ответа сервера. Все максимально просто.
Свойство responseText получит такой же текст страницы, как браузер, если бы Вы в перешли на /xhr/test.html. Для сервера
GET-запрос через XmlHttpRequest ничем не отличается от обычного перехода на страницу.
Асинхронный XMLHttpRequest
Этот пример делает то же самое, но асинхронно, т.е браузер не ждет выполнения запроса для продолжения скрипта. Вместо этого к свойству onreadystatechange подвешивается
функция, которую запрос вызовет сам, когда получит ответ с сервера.
var xmlhttp = getXmlHttp()
xmlhttp.open('GET', '/xhr/test.html', true);
xmlhttp.onreadystatechange = function() {
if (xmlhttp.readyState == 4) {
if(xmlhttp.status == 200) {
alert(xmlhttp.responseText);
}
}
};
xmlhttp.send(null);
Асинхронность включается третьим параметром функции open. В отличие от синхронного запроса, функция send() не останавливает
выполнение скрипта, а просто отправляет запрос.
Запрос xmlhttp регулярно отчитывается о своем состоянии через вызов функции xmlhttp.onreadystatechange. Состояние под номером 4 означает конец выполнения, поэтому функция-обработчик
при каждом вызове проверяет — не настало ли это состояние.
Вообще, список состояний readyState такой:
- 0 — Unitialized
- 1 —
- 2 — Loaded
- 3 — Interactive
- 4 — Complete
Состояния 0-2 вообще не используются.
Вызов функции с состоянием Interactive в теории должен происходить каждый раз при получении очередной порции данных от сервера.
Это могло бы быть удобным для обработки ответа по частям, но Internet Explorer не дает доступа к уже полученной части ответа.
Firefox дает такой доступ, но для обработки запроса по частям состояние Interactive все равно неудобно из-за сложностей обнаружения ошибок соединения.
Поэтому Interactive тоже не используется.
На практике используется только последнее, Complete.
Если хотите углубиться в тонкости багов браузеров c readyState, отличными от 4, то многие из них рассмотрены в статье на.
Не используйте синхронные запросы
Синхронные запросы применяются только в крайнем случае, когда кровь из носу необходимо дождаться ответа сервера до продолжения скрипта. В 999 случаях из 1000
можно использовать асинхронные запросы. При этом общий алгоритм такой:
- Делаем асинхронный запрос
- Рисуем анимированную картинку или просто запись типа «Loading…»
- В onreadystatechange при достижении состояния 4 убираем Loading и, в зависимости от status вызываем обработку ответа или ошибки.
Кроме того, иногда полезно ставить ограничение на время запроса. Например, хочется генерировать ошибку, если запрос висит более 10 секунд.
Для этого сразу после send() через setTimeout ставится вызов обработчика ошибки, который очищается при получении ответа и обрывает запрос с генерацией ошибки,
если истекли 10 секунд.
Таймаут на синхронный запрос ставить нельзя, браузер может висеть долго-долго.. А вот на асинхронный — пожалуйста.
Этот пример демонстрирует такой таймаут.
var xmlhttp = getXmlHttp()
xmlhttp.open("POST", "/someurl", true);
xmlhttp.onreadystatechange=function(){
if (xmlhttp.readyState != 4) return
clearTimeout(timeout) // очистить таймаут при наступлении readyState 4
if (xmlhttp.status == 200) {
// Все ок
...
alert(xmlhttp.responseText);
...
} else {
handleError(xmlhttp.statusText) // вызвать обработчик ошибки с текстом ответа
}
}
xmlhttp.send("a=5&b=4");
// Таймаут 10 секунд
var timeout = setTimeout( function(){ xmlhttp.abort(); handleError("Time over") }, 10000);
function handleError(message) {
// обработчик ошибки
...
alert("Ошибка: "+message)
...
}
Синхронные запросы
Если в методе третий параметр установлен на , запрос выполняется синхронно.
Другими словами, выполнение JavaScript останавливается на и возобновляется после получения ответа. Так ведут себя, например, функции или .
Вот переписанный пример с параметром , равным :
Выглядит, может быть, и неплохо, но синхронные запросы используются редко, так как они блокируют выполнение JavaScript до тех пор, пока загрузка не завершена. В некоторых браузерах нельзя прокручивать страницу, пока идёт синхронный запрос. Ну а если же синхронный запрос по какой-то причине выполняется слишком долго, браузер предложит закрыть «зависшую» страницу.
Многие продвинутые возможности , такие как выполнение запроса на другой домен или установка таймаута, недоступны для синхронных запросов. Также, как вы могли заметить, ни о какой индикации прогресса речь тут не идёт.
Из-за всего этого синхронные запросы используют очень редко. Мы более не будем рассматривать их.
Стандарты
World Wide Web Consortium опубликовал Рабочий проект спецификации для XMLHttpRequest объекта 5 апреля 2006 года, отредактированный на Энн ван Кестерен из Opera Software и Дин Джексон из W3C. Его цель — «задокументировать минимальный набор функционально совместимых функций на основе существующих реализаций, позволяющий веб-разработчикам использовать эти функции без кода, специфичного для платформы».
W3C также опубликовал еще один рабочий проект спецификации для объекта XMLHttpRequest , «XMLHttpRequest Level 2», 25 февраля 2008 года. Уровень 2 состоит из расширенных функциональных возможностей объекта XMLHttpRequest , включая, помимо прочего, события выполнения, поддержку перекрестных запросов. запросы сайта и обработка байтовых потоков. В конце 2011 года спецификация уровня 2 была оставлена и включена в исходную спецификацию.
В конце 2012 года WHATWG взялась за разработку и поддержание уровня жизни с помощью Web IDL . Текущие проекты W3C основаны на снимках стандарта WHATWG .
Кросс-доменные запросы
Давайте рассмотрим кросс-доменные запросы на примере кода:
// (1)
var XHR = ("onload" in new XMLHttpRequest()) ? XMLHttpRequest : XDomainRequest;
var xhr = new XHR();
// (2) запрос на другой домен :)
xhr.open('GET', 'http://anywhere.com/request', true);
xhr.onload = function() { alert( this.responseText ); }
xhr.onerror = function() { alert( 'Ошибка ' + this.status ); }
xhr.send();
- Мы создаём XMLHttpRequest и проверяем, поддерживает ли он событие onload. Если нет, то это старый XMLHttpRequest, значит это IE8,9, и надо использовать XDomainRequest.
- Запрос на другой домен отсылается просто указанием соответствующего URL в open. Он обязательно должен быть асинхронным, в остальном – никаких особенностей.
Пример 3. Передача синхронного AJAX запроса на сервер с помощью метода POST
В этом примере данные на сервер будем передавать с помощью метода POST (в теле HTTP-запроса). В методе POST данные (параметры) передаются не в составе URL (метод GET), а в теле, которое мы посылаем серверу через . Т.е. для того чтобы передать данные с помощью POST, мы их должны поместить в качестве параметра методу . Кроме того, при отправке данных с помощью POST необходимо также указать заголовок Content-Type, содержащий кодировку с помощью которой мы зашифровали данные. Это необходимо сделать для того чтобы сервер знал как обработать (расшифровать), пришедшие к нему данные (запрос).
<html lang="ru">
<head>
<meta charset="utf-8">
<title>JavaScript AJAX</title>
<style>
span {
font-weight: bold;
color: red;
}
</style>
</head>
<body>
<p>Введите имя и нажмите на кнопку "Получить...".</p>
<input id="nameUser" type="text" placeholder="Введите имя">
<input id="button" type="button" value="Получить ответ с сервера">
<p>Ответ (AJAX): <span id="answer"></span></p>
<script src="script.js"></script>
</body>
</html>
// получить элемент, имеющий id="button"
var button = document.getElementById("button");
// подпишемся на событие click элемента
button.addEventListener("click",function() {
// создадим объект XMLHttpRequest
var request = new XMLHttpRequest();
// параметры запроса
var params = 'name=' + encodeURIComponent(document.getElementById("nameUser").value);
// настраиваем запрос: POST - метод, ajaxpost.php - URL-адрес, по которому посылается запрос, false - синхронный запрос
request.open('POST','ajaxpost.php',false);
// указываем заголовок Content-Type, содержащий кодировку
request.setRequestHeader('Content-Type', 'application/x-www-form-urlencoded')
// отправляем данные на сервер с помощью метода send
request.send(params);
// если статус ответа 200 (OK) то
if (request.status==200) {
// выведем в элемент, имеющий id="answer", ответ сервера
document.getElementById("answer").innerHTML = request.responseText;
}
})
<?php
// если в ассоциативном массиве $_POST существует ключ name
if (isset($_POST)) {
// присвоим переменной $name значение из ассоциативного массива POST соответсвующее ключу name
$name = $_POST;
// выведем строку (ответ сервера)
echo "Привет, ".$name."!";
}
?>
Ограничения безопасности. Кросс-доменный XMLHttpRequest¶
Для ограничения XmlHttpRequest используется философия «Same Origin Policy». Она очень проста — каждый сайт в своей песочнице. Запрос можно делать только на адреса с тем же протоколом, доменом, портом, что и текущая страница.
Т. е., со страницы на адресе нельзя сделать XmlHttpRequest на адрес , или
Это создает проблему, если хочется взять контент с другого сайта. Как правило, в этом случае вместо XmlHttpRequest используются другие средства, например, загрузка через динамически создаваемый тег . Но, конечно, XmlHttpRequest удобнее.
Проксирование
Самый простой способ обойти это ограничение — проксирование. Допустим, мы хотим сделать запрос с на . Вместо указания в методе , там ставится URL вида . Запрос приходит на наш веб-сервер, проксирует его на сервер на , который уже обрабатывает этот запрос, как нужно.
Если находится на другом сервере, то серверу придется проксировать посетителю как запрос, так и ответ. При этом, разумеется, никак не будут задействованы куки , так что не получится отдельной авторизации, учета пользователей или что-то в этом роде с отдельными куками.
Например, при использовании web-сервера Apache, для проксирования нужны директивы , . Кроме того, доступны еще модули, которые по необходимости правят урлы, разархивируют контент и т. п.
Использование наддомена
Часто кроссбраузерные запросы — это
- Способ обойти ограничения в 2 одновременных соединения к одному домену-порту.
- Способ использовать два разных сервера в общении с посетителем. Например, на — чат-демон, на — веб-сервер.
Кросс-доменные запросы между наддоменами , (на общем ) допустимы при использовании свойства , которое надо установить в
Любые запросы допустимы между сайтами, находящимися в доверенной () зоне Internet Explorer. Так что, внутренний корпоративный портал может быть у всех пользователей в этой зоне, и он сможет делать запросы к любым сайтам.
XhrIframeProxy
Еще один хитрый подход называется XHRIframeProxy, и позволяет делать XmlHttpRequest к любым доменам при помощи хитрого iframe-хака. Он основан на том, что фреймы с разных доменов могут читать и менять друг у друга anchor, т.е часть адреса после решетки ». За счет этого организуется специальный протокол, по которому «проксируется» XmlHttpRequest.
Этот метод, в принципе, вполне жизнеспособен, особенно для небольшого объема данных.
Константы
Следующие константы объекта XMLHttpRequest определяют возможные значения свойства readyState:
| Значение | Константа | Описание |
|---|---|---|
| UNSENT | Объект XMLHttpRequest был создан, метод open() объекта не вызывался. | |
| 1 | OPENED | Метод open() объекта был вызван. Во время этого состояния заголовки запросов могут быть установлены с помощью метода setRequestHeader() и метод send() может быть вызван, который инициирует отправку запроса. |
| 2 | HEADERS_RECEIVED | Метод send() объекта был вызван, заголовки и статус доступны. |
| 3 | Происходит загрузка тела ответа сервера. Если значение свойства responseType соответствует значению «text» или пустой строке, то значение свойства responseText будет содержать частичные данные. | |
| 4 | DONE | Операция завершена. Это может означать, что передача данных была завершена успешно или не удалась. |
CORS для простых запросов
В кросс-доменный запрос браузер автоматически добавляет заголовок Origin, содержащий домен, с которого и был осуществлён запрос.
В случае запроса на http://anywhere.com/request с http://site.ru/page заголовки будут примерно такие:
GET /request Host:anywhere.com Origin:http://site.ru ...
Сервер должен, со своей стороны, ответить специальными заголовками, разрешает ли он такой запрос к себе.
Если сервер разрешает кросс-доменный запрос с этого домена – он должен добавить к ответу заголовок Access-Control-Allow-Origin, содержащий домен запроса (в данном случае «site.ru») или звёздочку *.
Только при наличии такого заголовка в ответе – браузер сочтёт запрос успешным, а иначе вернет ошибку.
То есть, ответ сервера может быть примерно таким:
HTTP/1.1 200 OK Content-Type:text/html; charset=utf-8 Access-Control-Allow-Origin: http://site.ru
Если Access-Control-Allow-Origin нет, то браузер считает, что разрешение не получено, и завершает запрос с ошибкой.
При таких запросах не передаются куки и заголовки HTTP-авторизации. Параметры user и password в методе open игнорируются. Мы рассмотрим, как разрешить их передачу, чуть далее.
Что может сделать хакер, используя такие запросы?
Описанные выше ограничения приводят к тому, что запрос полностью безопасен.
Действительно, страница может сформировать любой GET/POST-запрос и отправить его, но без разрешения сервера ответа она не получит.
А без ответа такой запрос, по сути, эквивалентен отправке формы GET/POST, причём без авторизации.
Итоги
- У форм есть 2 основные кодировки: application/x-www-form-urlencoded и multipart/form-data – для POST запросов, если она явно указана в enctype. Вторая кодировка обычно используется для передачи больших данных и только для тела запроса.
- Для составления запроса в application/x-www-form-urlencoded есть функция encodeURIComponent.
- Для отправки запроса в multipart/form-data – есть объект FormData.
- Для обмена данными клиент сервер можно использовать и просто JSON, желательно с указанием кодировки в заголовке Content-Type.
В XMLHttpRequest вы можете использовать и другие HTTP-методы, как PUT, DELETE, TRACE.
Поделиться
Твитнуть
Поделиться