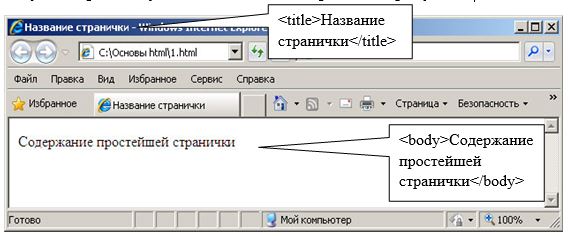
«вкалывают роботы»: что такое robots.txt и как его настроить
Содержание:
Когда не стоит прибегать к robots.txt
При грамотном использовании данный файл несёт пользу, но есть ситуации, в которых его применение в целях блокировки краулинга только мешает.
Блокировка Javascript/CSS
Поисковым системам необходим доступ ко всем ресурсам, чтобы корректно рендерить страницы — это необходимая часть ранжирования. Если же, к примеру, Javascript, оказывающий подчас определяющее влияние на функционал страницы и пользовательский опыт отключен, это может привести к плохим результатам вплоть до понижения в выдаче.
Например, если ваша страница содержит редиректы с помощью Javascript, а тот, в свою очередь, закрыт от индексации, робот распознает в таком перенаправлении клоакинг — подмену страницы.
Блокировка по URL
Robots.txt можно использовать для блокировки URL со специфическими параметрами, но это далеко не всегда верное решение. Правильная настройка robots,txt предполагает использование Google Search Console — такой способ будет приемлем с точки зрения поисковых систем.
Можно разместить информацию в самом URL — /items#filter=date, так как краулеры не считывают это. Если URL-параметр должен быть использован обязательно, ссылка может содержать rel=nofollow во избежание индексации.
Блокировка URL с обратными ссылками
Если обратные ссылки запрещены robots.txt, поисковый робот не сможет перейти по ссылкам с других сайтов на ваш ресурс. Из-за этого ваш сайт не получит баллов ранжирования и опустится в выдаче.
Установка правил против краулеров соцсетей
Даже если вы не хотите, чтобы поисковые системы читали ваши страницы, возможно, доступ роботов соцсетей не помешает. Ведь они формируют сниппеты в случае репоста ваших страниц в соцсети. Например, Facebook будет пытаться зайти на каждую страницу, которую постят в нём, чтобы отображать релевантный сниппет.
Блокировка доступа к сайтам в процессе разработки
Использование robots.txt для блокировки всего сайта в процессе разработки хорошо работает. В то же время, Google рекомендует убирать из индексации страницы, но давать возможность роботу их читать. В целом же, следует делать такие сайты недоступными для посещения вообще.
Когда нечего блокировать
Некоторые сайты с весьма чистой архитектурой не испытывают потребности в блокировке каких-либо разделов. В такой ситуации вообще можно не создавать robots.txt, а возвращать страницу 404.
Эффективный маркетинг с Calltouch
- Анализируйте воронку продаж от показов рекламы до ROI от 990 рублей в месяц
- Отслеживайте звонки с сайте с точностью определения источника рекламы выше 96%
- Повышайте конверсию сайта на 30% с помощью умного обратного звонка
- Оптимизируйте свой маркетинг с помощью подробных отчетов: дашборды, графики, диаграммы
- Добавьте интеграцию c CRM и другими сервисами: более 50 готовых решений
- Контролируйте расходы на маркетинг до копейки
Узнать подробнее
Установка плагина WP Maintenance Mode

Данный плагин очень прост в настройке, имеет много различных возможностей и не нагружает ваш сайт.
Вы можете его активировать только тогда, когда он вам нужен, а если вы не используете данный плагин, то вы его просто деактивируете и он вообще не дает ни какой нагрузки на сайт.
- 1.Копируем его название и переходим в админку сайта.
- 2.Устанавливаем и активируем его как любой другой плагин.
- 3.И после его установки у вас в разделе «Настройки» появится пункт «Техническое обслуживание». Переходим в этот раздел, и мы видим, что все настройки данного плагина разбиты на несколько вкладок.
-
4.Прежде всего, что бы включить режим техобслуживания и закрыть ваш сайт для посетителей необходимо выставить здесь «Включено»
- 5.На этой же вкладке вы можете выбрать закрывать ли ваш сайт от индексации
-
6.Так же вы можете выбрать, пользователи с какими правами, а точнее ролями, могут иметь доступ к административной части вашего сайта.
Когда вы создаете нового пользователя или редактируете уже существующего, WordPress позволяет назначать этому пользователю определенную роль. Это может быть подписчик, участник, автор, редактор и администратор.
Так вот, в настройках данного плагина вы можете задать определенные группы пользователей с определенными ролями для доступа к панели управления сайтом и к фронт-энду сайта.
Если вам нужно просто временно закрыть ваш сайт для внесения определенных правок, то выставлять здесь ни чего не нужно.
Так же, здесь можно выставить мета тэг для роботов, но, опять таки, если вы кратковременно закрываете сайт, то все эти настройки вам не понадобятся.
Ещё у данного плагина есть возможность перенаправлять всех посетителей, зашедших по адресу вашего сайта на какую-то определенную страницу, или на какой-то другой сайт.

Здесь же можно добавить определенные исключения, то есть, что бы у посетителя был доступ к новостной ленте, архивам сайта, страницам, и так далее.
7.После того, как вы включаете режим технического обслуживания у вас, в административной части сайта, при редактировании каких-то страниц и установке плагинов, постоянно высвечивается предупреждение о том, что у вас включен режим технического обслуживания.
Это делается для того, что бы вы ни забыли его отключить после того, как внесете все необходимые правки. На вкладке «Общие» вы можете выбрать, высвечивать это предупреждение, или нет. Я рекомендую вам оставить здесь «Да».
8.Так же, при желании, на странице технического обслуживания вы можете добавить, либо не добавлять, ссылку для входа в панель управления.
9.После того, как все настройки заданы нажимаем на кнопку «Сохранить настройки».

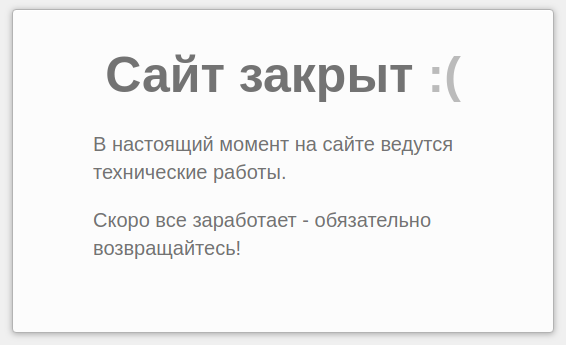
Если я сейчас из админки перейду на страницу данного сайта, то для меня как для администратора, данный сайт будет, по-прежнему, доступен. Однако, если я, например, выйду из административной части сайта, или зайду на сайт через другой браузер, то я увижу вот такую картину:

Текст данного сообщения вы так же можете менять в настройках плагина.
Как увидеть http — https проблему индексации?
1 Набираем в строке поиска Google.com и Google.ru ( так как результаты могут быть разные ! ) site: и затем: сразу, без пробелов url вашего сайта, например, site:moisait.ru
2 Смотрим результат.
3 Если чужих страниц нет, то это хорошо, но рано радоваться … ваши https страницы могут появиться на чужих http сайтах на этом же хостинге, т.е. дубли всё же будут!
4 Если чужие страницы есть в поиске по вашему сайту, то нужно решать эту проблему!
Решение 1
Закрыть https версию сайта в robots.txt
Замечание Перечисленные ниже варианты предназначены для серверов Linux.
5 Создаём, кроме robots.txt в корне сайта и новый файл, например:https.txt, в нём будем запрещать индексирование https страниц стандартным способом:
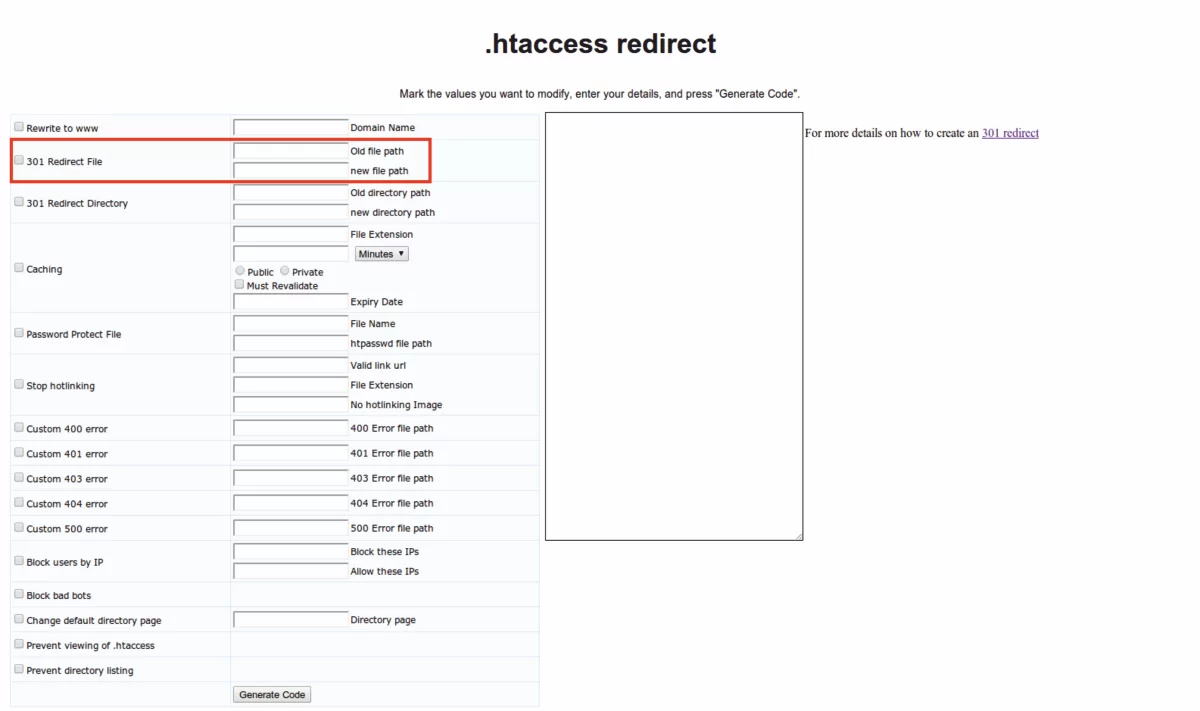
6 Теперь, пробуем сделать вариант переадресации для https на https.txt, который работает в 50% случаев. Открываем в корне сайта файл .htaccess и сразу же после строки RewriteEngine on добавляем:
7 Проверяем работает переадресация или нет
Набираем в строке http://moisait.ru/robots.txt https://moisait.ru/robots.txt и вы должны увидеть РАЗНЫЕ файлы robots.txt, если не забыли заменить moisait.ru на реальный URL вашего сайта.
Если Решение 1 не работает?
Решение 1.1
8 Внимательно смотрим и сравниваем содержимое файлов robots.txt http://moisait.ru/robots.txt https://moisait.ru/robots.txt если они отличаются, — это или хорошо или очень плохо
нужно выяснить откуда ( с какого URL ) https тянет файл роботс.
Если есть строка Host: — хорошо — вы узнали, какой это сайт ( назовём его, для удобства drygoy-sait.ru) , ещё один простой вариант узнать «где собака зарыта» вместо http://moisait.ru/ открываем https://moisait.ru/, и если это совсем другой сайт (drygoy-sait.ru), то именно в нём и будем проводить правки! Если и это не помогло — … нужно искать поиском или перебором!
Итак, мы нашли https сайт (drygoy-sait.ru)!
И если мы применим в файле .htaccess в корне сайта drygoy-sait.ru стандарное правило из пункта 6, то мы закроем по протоколу https от индексации, как требуется, не только все сайты типа http://moisait.ru/, но и все https сайты, в том числе и нужный нам, или кому-то https://drygoy-sait.ru!!!
Следовательно: вариант 6 не применяем! Что делать ? … и кто виноват? 🙂
9 Задача: разрешить индексацию robots всем https сайтам и запретить индексацию страниц сайта всем сайтам, имеющим http протокол.
Решение: создаем правила типа условное выражение в htaccess такого вида:
10 Подводим Итог
Другими словами, для того, чтобы запретить индексацию на https://moisait.ru вам потребуется открыть drygoy-sait.ru, создать там https.txt с запретом: и там же в файле htacces ( в корне сайта) прописать правила из пункта 9 для каждого вашего сайта: moisait 1, 2, 3.ru
Вот такие пирожки с ….
https://moisait.ru
Решение 1.2
Решение 2
Замечание Предлагаемое решение работает на серверах с Nginx.
Если у вас сервер с NginX делаем подмену файла robots на https.txt
1
пролистываем все location после закрывающей скобки } вставляем :
# редиректим robots.txt для https на https.txt
location = /robots.txt {
if ($server_port = 443) {
rewrite ^ /https.txt last;
}
}
Решение 3
Закрываем от индексации поисковиков
Перед тем как рассказать о способе с применением robots.txt, мы покажем, как на WordPress закрыть от индексации сайт через админку. В настройках (раздел чтение), есть удобная функция:

Можно убрать видимость сайта, но обратите внимание на подсказку. В ней говорится, что поисковые системы всё же могут индексировать ресурс, поэтому лучше воспользоваться проверенным способом и добавить нужный код в robots.txt
Текстовый файл robots находится в корне сайта, а если его там нет, создайте его через блокнот.
Закрыть сайт от индексации поможет следующий код:
User-agent: *
Disallow: /
Просто добавьте его на первую строчку (замените уже имеющиеся строчки). Если нужно закрыть сайт только от Яндекса, вместо звездочки указывайте Yandex, если закрываете ресурс от Google, вставляйте Googlebot.
Когда проделаете эти действия, сайт больше не будет индексироваться, это самый лучший способ для закрытия ресурса от поисковых роботов.
Способ 1. Создать файл Site Closed
Способ подразумевает кастомизацию стандартной заглушки, которая включается в главном модуле, кнопкой “Закрыть публичную часть сайта”.
Стандартная заглушка заменяется посредством создания файла site_closed.php в «/bitrix/php_interface/include» или «/local/php_interface/include».
Такая заглушка — обычная страница, поэтому размещенные на ней компоненты тоже будут работать. В то же время страница может быть собрана в
и никак не связана с дизайном сайта.

А такую заглушку мы используем на наших проектах. Если вам понравилась эта заглушка, то не пропустите — в конце статьи будет ссылка на скачивание.
Использование метатега robots для блокирования доступа к сайту
Данный метод запрета индексации страниц сайта встречается гораздо реже в повседневной жизни. Как следствие происходит это из-за что разработчики большинства CMS просто не обращают на это внимания/забывают/забивают. И тогда ответственность за поведение роботов на сайте полностью ложится на плечи вебмастеров, которые в свою очередь обходятся простейшим вариантом – robots.txt.
Но продвинутые вебмастера, которые в теме особенностей индексации сайтов и поведения роботов, используют метатег robots.
И снова небольшая выдержка из руководства от Google:
Внушает оптимизм, не правда ли? И еще:
Следовательно, все страницы, которые мы хотим запретить к индексации, а так же исключить их из индекса, если они уже проиндексированы (насколько я понял, это касается и доп. индекса Гугла), необходимо на всех таких страницах поместить метатег
Что еще более важно, эти самые страницы не должны быть закрыты через robots.txt!
Немного побуду кэпом и расскажу, какие еще значения (content=»…») может принимать мататег robots:
- noindex – запрещает индексацию страницы
- nofollow – запрещает роботу следовать по ссылкам на странице
- index, follow – разрешает роботу индексацию страницы и переход по ссылкам на этой странице
- all – аналогично предыдущему пункту. По большому счету, бесполезная директива, эквивалентна отсутствию самого метатега robots
- none – запрет на индексацию и следование по ссылкам, эквивалентно сочетанию noindex,nofollow
- noarchive – запрет поисковику выводить ссылку на кеш страницы (для Яндекса это «копия», для Google это «сохраненная копия»)
Так как в справке Яндекса нижеследующие параметры не описаны, то они, скорее всего, там и не сработают. Так что эти параметры только для Google:
- noimageindex – запрет на индексацию изображений на странице
- nosnippet – запрет на вывод сниппета в результатах поиска (при этом так же удаляется и сохраненная копия!)
- noodp – запрет для Google на вывод в качестве сниппета описания из каталога DMOZ
Вроде все, осталось только сказать, что количество пробелов, положение запятой и регистр внутри content=»…» здесь не играет никакой роли, но все же для красоты лучше писать как положено (с маленькой буквы, без пробелов и разделяя атрибуты запятой).
Короче говоря, чтобы полностью запретить индексацию ненужных страниц и появление их в поиске необходимо на всех этих страницах разместить метатег .
Так что если вам известны все страницы (наборы страниц, категории и т.д.), которые не должны попасть в индекс и есть доступ к редактированию их содержания (конкретно, содержания внутри тега ), то можно обойтись без запрещающих директив в файле robots.txt, но разместив на страницах метатег robots. Данный вариант, как вы понимаете, является эффективным и предпочтительным.
Рекомендую к прочтению:
- Мануал Google «Блокировка индексирования при помощи атрибута noindex»
- Мануал Яндекса «Как удалить страницы из поиска»
Итак, у нас остался последний нераскрытый вопрос, и он о внутренних ссылках.
Почему важно ограничивать индексацию страниц
Заинтересованность в индексации есть не только у собственника веб-ресурса, но и у поисковой системы – ей необходимо предоставить релевантную и, главное, ценную информацию для пользователя. Чтобы удовлетворить обе стороны, требуется проиндексировать только те страницы, которые будут интересны и целевой аудитории, и поисковику.
Прежде чем переходить к списку ненужных страниц для индексации, давайте рассмотрим причины, из-за которых стоит запрещать их выдачу. Вот некоторые из них:
Уникальность контента – важно, чтобы вся информация, передаваемая поисковой системе, была неповторима. При соблюдении данного критерия выдача может заметно вырасти
В противном случае поисковик будет сначала искать первоисточник – только он сможет получить доверие.
Краулинговый бюджет – лимит, выделяемый сайту на сканирование. Другими словами, это количество страниц, которое выделяется каждому ресурсу для индексации. Такое число обычно определяется для каждого сайта индивидуально. Для лучшей выдачи рекомендуется избавиться от ненужных страниц.
В краулинговый бюджет входят: взломанные страницы, файлы CSS и JS, дубли, цепочки редиректов, страницы со спамом и прочее.
Как навсегда заблокировать доступ к сайту чтобы он не открывался
https://youtube.com/watch?v=koX6MHrUAzA
Необходимость заблокировать сайт, чтобы он не открывался, может возникнуть по разным причинам
Работодатели могут хотеть перекрыть доступ для сотрудников к соцсетям и развлекательным порталам, родителям важно защитить детей от «недетских» сайтов
Как установить защиту, рассмотрим в этой статье.
Способы блокировки
Для блокировки можно использовать как специализированные программы или сервисы, так и уже встроенные в систему инструменты.
Итак, чем можно воспользоваться для защиты доступа к определенным сайтам? Вот список инструментов, которые помогают заблокировать на компьютере определенные адреса:
- Внесение URL-адреса в файл hosts;
- Добавление в черный список антивирусной программы;
- Яндекс DNS;
- Интернет-Цензор;
- Браузеры и расширения для них;
Итак, как заблокировать сайт чтобы он не открывался? Рассмотрим все способы отдельно.
Использование файла hosts
Самым простым и быстрым ответом на вопрос «Как запретить сайты на компьютере?» является обновление списка в файле hosts. Данный файл является системным инструментом Windows, с помощью которого можно заблокировать адрес на уровне операционной системы.
Для того чтобы запретить необходимую страницу в интернете, необходимо открыть рассматриваемый файл с помощью программы «Блокнот». Расположение hosts:
C:/Windows/System32/drivers/etc/hosts
Чтобы заблокировать открытие сайта, вы должны с новой строки написать ip-адрес 127.0.0.1 (именно этот), после чего ввести правильный URL-адрес. Это должно выглядеть следующим образом:
127.0.0.1 site.ru
127.0.0.1 www. site.ru
Также необходимо упомянуть о важной проблеме, которая может возникнуть при изменении и сохранении файла hosts. Если на компьютере в учетной записи, которую вы используете, недостаточно прав, вы не сможете изменить файл внутри его родной папки. Чтобы решить эту проблему, воспользуйтесь следующим алгоритмом:
Чтобы решить эту проблему, воспользуйтесь следующим алгоритмом:
- Скопируйте файл hosts, после чего вставьте его в другом месте. Например, на рабочий стол.
- Проведите все необходимые манипуляции над файлом в этом месте.
- Замените новой версией файла старую.
Таким образом, можно легко и быстро разобраться с тем, как заблокировать открытие сайта.
Блокировка с помощью антивируса
Если по какой-то причине первый способ не подходит, попробуйте воспользоваться антивирусом, в котором наверняка есть специальный блокировщик. В программе avast!, например, переход к данной функции происходит с помощью вкладки в левом окне главного меню. В Касперском это реализовано в виде родительского контроля.
Яндекс DNS
Как можно понять из названия, сервис Яндекс DNS — это бесплатная разработка компании Яндекс, которая позволяет установить качественную фильтрацию всего входящего и исходящего трафика при выходе компьютера пользователя во Всемирную паутину.
Сервис включает в себя несколько режимов, с помощью которой можно выставить необходимую для себя защиту. На официальной странице сервиса Яндекс ДНС можно найти подробную инструкцию от производителя, с помощью которой можно быстро и просто установить себе описанный фильтр.
Интернет-Цензор на страже безопасности
Многие школьники и студенты, которые не раз пользовались учебными устройствами в компьютерных аудиториях, не раз слышали о такой программе, как Интернет-Цензор. С помощью не можно навсегда заблокировать все сайты, которые содержат в себе антиучебный и другой контент.
Благодаря широкому спектру функций, программа Интернет-Цензор является лучшим способом блокировки сайта на компьютере. Здесь можно заблокировать
- Определенный страницы отдельно;
- абсолютно все сайты мировой паутины;
- целые разделы проектов по разным категориям.
А также существует возможность добавления сайтов в белый список.
Специальные расширения для браузеров
В отличие от других способов, описанных в данной статье, данный предназначен для какого-то конкретного браузера, которым вы пользуетесь. Он заключается в установке специального расширения, которое позволит сделать необходимое.
К таким расширениям можно отнести «Block site», «BlockSite», «WebFilter Pro» и так далее. Однако цель таких расширений не совсем понятна, ведь какой смысл блокировать сайт на одном браузере, если пользовать все так же сможет открыть его на другом.
Итак, существует немалое количество способов, с помощью которых можно заблокировать определенный сайт навсегда или на время. Все зависит от того, какую цель данная блокировка преследует. Например, если нужно контролировать своего ребенка, лучше воспользоваться специальным родительским контролем.
Используемые директивы
User-agent
Все блоки правил начинаются с директивы User-agent, в которой указывается название робота, для которого задается правило. Запись вида User-agent: * означает, что правило задается для всех поисковых роботов.
Например, при следующей записи правило будет применено только к основному индексирующему боту Яндекса:
User-agent: YandexBot
Правило будет применено ко всем роботам Яндекса и Google:
User-agent: Yandex User-agent: Googlebot
Правило будет применено вообще ко всем роботам:
User-agent: *
Disallow и Allow
Директивы используются, чтобы запретить и разрешить доступ к определенным разделам сайта.
Например, можно запретить индексацию всего сайта (Disallow: /), кроме определенного каталога (Allow: /catalog):
User-agent: имя_бота Disallow: / Allow: /catalog
Запретить индексацию страниц, начинающихся с /catalog, но разрешить для страниц, начинающихся с /catalog/auto и /catalog/new:
User-agent: имя_бота Disallow: /catalog Allow: /catalog/auto Allow: /catalog/new
В каждой строке указывается только одна директория. Для запрещения (или разрешения) доступа к нескольким каталогам, для каждого требуется отдельная запись.
С помощью Disallow можно ограничить доступ к сайту для нежелательных ботов, тем самым снизив создаваемую ими нагрузку. Например, чтобы запретить доступ ко всему сайту для MJ12bot и AhrefsBot — ботов сервиса majestic.com и ahrefs.com — используйте:
User-agent: MJ12bot User-agent: AhrefsBot Disallow: /
Аналогичным образом устанавливается блокировка и для других ботов (скажем, DotBot, SemrushBot и других).
Примечания:
- Пустая директива Disallow: равнозначна Allow: /, то есть «не запрещать ничего».
- В директивах может использоваться символ $ для обозначения точного соответствия указанному параметру. Например, запись Disallow: /catalog аналогична Disallow: /catalog * и запретит доступ ко всем страницам с /catalog (/catalog, /catalog1, /catalog-new, /catalog/clothes и др.).Использование $ это изменит. Disallow: /catalog$ запретит доступ к /catalog, но разрешит /catalog1, /catalog-new, /catalog/clothes и др.
Sitemap
При использовании файла sitemap.xml для описания структуры сайта, можно указать путь к нему с помощью соответствующей директивы:
User-agent: * Disallow: Sitemap: https://mydomain.com/путь_к_файлу/mysitemap.xml
Можно перечислить несколько файлов Sitemap, каждый в отдельной строке.
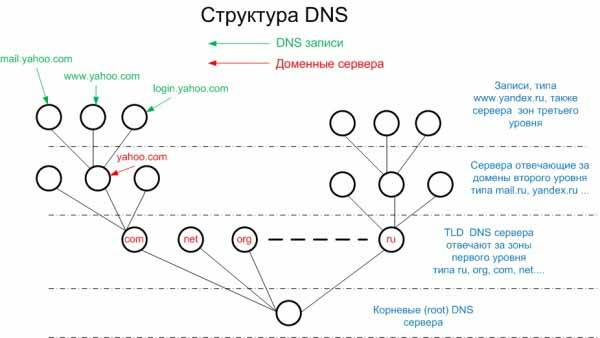
Host
Директива используется для указания роботам Яндекса основного зеркала сайта и полезна, когда сайт доступен по нескольким доменам.
User-agent: Yandex Disallow: /catalog1$ Host: https://mydomain.com
Примечания:
- Директива Host может быть только одна; если в файле указано несколько, роботом будет учтена только первая.
- Необходимо указывать протокол https, если он используется. Если вы используете http, зеркало можно записать в виде mydomain.com
- Для корректного прочтения директивы, ее нужно указывать в блоке правил User-agent после директив Disallow и Allow.
Crawl-delay
Директива устанавливает минимальный интервал в секундах между обращениями робота к сайту, что может быть полезно для снижения создаваемой роботами нагрузки. Чем выше указанное значение, тем меньше страниц робот загрузит за сессию.
Значения можно указывать целыми или дробными числами (разделитель — точка).
User-agent: Yandex Disallow: Crawl-delay: 0.5
Примечания:
- Для корректного прочтения директивы, ее нужно указывать в блоке правил User-agent после директив Disallow и Allow.
Clean-param
Директива используется для робота Яндекса. Она позволяет исключить из индексации страницы с динамическими параметрами в URL-адресах (это могут быть идентификаторы сессий, пользователей, рефереров), чтобы робот не индексировал одно и то же содержимое повторно, повышая тем самым нагрузку на сервер.
Например, на сайте есть страницы:
www.mydomain.ru/news.html?&parm1=1&parm2=2 www.mydomain.ru/news.html?&parm2=2&parm3=3
По факту по обоим адресам отдается одна и та же страница — www.mydomain.ru/news.html, при этом в URL присутствуют дополнительные динамические параметры.
Чтобы робот не индексировал каждую подобную страницу, можно использовать директиву:
User-agent: Yandex Disallow: Clean-param: parm1&parm2&parm3 /news.html
Через знак & указываются параметры, которые робот должен игнорировать. Далее указывается страница, для которой применяется данное правило
Как включить и отключить режим обслуживания в WordPress
Существует несколько способов активации режима обслуживания: с помощью кода, плагина либо через файл .htaccess. В данном разделе мы рассмотрим каждый из них, а в конце каждого метода разберем, как правильно деактивировать профилактический режим в зависимости от способа его подключения.
Способ 1: Через код
В данном случае нам потребуется открыть редактирование темы и внести в нее некоторые изменения. Для этого выполним следующее:
- Открываем административную панель WordPress и в левом меню выбираем «Внешний вид», затем переходим в раздел «Редактор тем».
- Следующим шагом в правой части отобразившегося окна нажимаем на «Функции темы».
Итак, мы попали в нужное нам окно – сюда и будем добавлять код. Выглядит он так:
// Activate WordPress Maintenance Mode
function wp_maintenance_mode(){
if(!current_user_can('edit_themes') || !is_user_logged_in()){
wp_die('<h1 style="color:red">Website under Maintenance</h1><br />We are performing scheduled maintenance. We will be back on-line shortly!');
}
}
add_action('get_header', 'wp_maintenance_mode');
Прописываем блок кода в конце файла и не забываем сохраниться кнопкой «Обновить файл».

Теперь пользователи будут уведомлены, что на сайт находится на техобслуживании. Вы не сможете увидеть объявление, так как зарегистрированы на сайте. Чтобы увидеть его, откройте сайт в другом браузере или выйдете из учетной записи WordPress.
Чтобы закрыть техобслуживание, просто удалите код, вставленный ранее – главное, не очистить ничего лишнего. После этого откройте сайт так, как его видит обычный пользователь, и убедитесь, что техническая информация была удалена.
Способ 2: Плагин WP Maintenance Mode
В ходе статьи мы рассмотрим еще много различных плагинов, но детально разберем лишь один – WP Maintenance Mode. Это одно из самых популярных расширений, используемое многими разработчиками для активации режима техобслуживания. Он поставляется с готовыми темами, которые можно легко персонализировать – то есть вы устанавливаете плагин, выбираете необходимый внешний вид технической страницы, подключаете ее и готово. Давайте рассмотрим, как все это сделать.
Открываем в админке WordPress раздел «Плагины» и выбираем «Добавить новый».
Вводим запрос WP Maintenance Mode и устанавливаем необходимый нам плагин.
После успешной установки активируем расширение.
Теперь нам нужно его немного подредактировать – для этого на отобразившейся странице выбираем «Настройки».
Первым делом активируем работу расширения, а также отключаем индексацию поисковыми роботами
Здесь же обратите внимание на блоки «Доступ к панели управления» и «Доступ к сайту» – в них вы можете настроить доступность сайта во время технического обслуживания.
Следующая вкладка «Дизайн» – здесь мы можем полностью настроить визуальную составляющую страницы. Тут уже на ваше усмотрение, не забудьте только сохранить внесенные изменения.
Во вкладке «Модули» мы можем добавить новые блоки, например, установить обратный отсчет – пользователи будут видеть, сколько времени осталось до окончания профилактических работ.
Здесь же мы можем добавить обратную связь и включить отображение социальных сетей.
Раздел «Управление ботом» – отличный способ не дать заскучать пользователям, пока ведутся технические работы над сайтом.
Вкладка GDPR предназначена для настройки сбора информации о пользователях.
Как видите, настройки плагина многообразны, и в нем гораздо больше возможностей, чем в нескольких строчках кода, рассмотренных нами ранее.
Способ 3: Файл .htaccess
Последний способ, с помощью которого можно закрыть сайт на обслуживание в WordPress, – добавить код в файл .htaccess. Этот файл находится в корневом каталоге сайта, добраться до него можно следующим образом:
- Открываем личный аккаунт хостинг-провайдера и переходим в файловый менеджер. Затем заходим в папку с названием CMS и переходим в раздел «public_html». Там находим нужный нам файл и заходим в него двойным кликом.
- Осталось добавить несколько строчек кода. Для вашего удобства он расположен под картинкой – просто скопируйте его и вставьте в файл.
RewriteEngine On
RewriteBase /
RewriteCond %{REMOTE_ADDR} !^123.456.789.123
RewriteCond %{REQUEST_URI} !^/maintenance.html$
RewriteRule ^(.*)$ https://example.com/maintenance.html
Эти команды перенаправляют всех посетителей на новую домашнюю страницу maintenance.html. Предварительно создайте ее и настройте – шаблоны можете поискать в интернете, их довольно много.